

论文解读(AAD)《Knowledge distillation for BERT unsupervised domain adaptation...
source link: https://www.cnblogs.com/BlairGrowing/p/17610000.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文标题:Knowledge distillation for BERT unsupervised domain adaptation
论文作者:Minho Ryu、Geonseok Lee、Kichun Lee
论文来源:2022 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
出发点:域偏移导致的性能下降;
问题定义:UDA
比较有意思,这篇工作被抄袭了,但是抄袭的家伙还成功发论文了.............
2 相关工作
知识蒸馏 [7,8](KD)最初是一种模型压缩技术,旨在训练一个紧凑的模型(学生),以便将一个训练良好的更大的模型(教师)的知识转移到学生模型[28,29]。KD 可以通过最小化以下目标函数来表示:
LKD=t2∑k−softmax(pTk/t)×log(softmax(pSk/t))LKD=t2∑k−softmax(pkT/t)×log(softmax(pkS/t))
其中,pSpS 和 pTpT 分别为学生模型和教师模型的预测,温度值 tt 控制着知识转移的程度。
推导过程:
KL(p∥q)=∑ni=1p(xi)log(p(xi)q(xi))KL(p‖q)=∑i=1np(xi)log(p(xi)q(xi))
KL(p∥q)=∑ni=1p(xi)log(p(xi))−∑ni=1p(xi)log(q(xi))=H(p(x))−∑ni=1p(xi)log(q(xi))KL(p‖q)=∑i=1np(xi)log(p(xi))−∑i=1np(xi)log(q(xi))=H(p(x))−∑i=1np(xi)log(q(xi))
注意:PP 代表着真实分布, QQ 代表着模型分布;
注意:学生模型训练时,教师模型的参数是固定的,因此 H(p(x))H(p(x)) 为常数,可以去掉;
注意:标准的监督训练,由于使用的是硬标签做监督训练,所以在重复训练的时候容易造成过拟合。由于较大的 tt 值产生较软的概率分布,知识蒸馏在结合领域自适应方法可以缓解这一问题。
3.1 模型框架
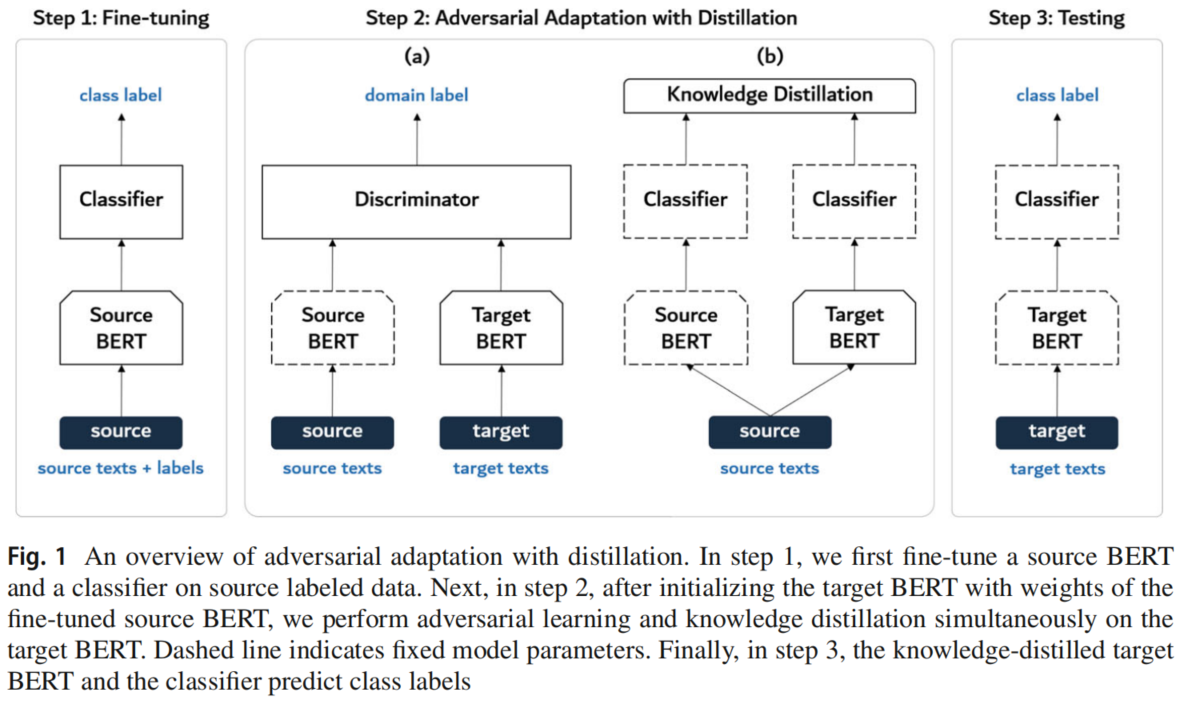
3.2 Adversarial adaptation with distillation
Step 1: fine-tune the source encoder and the classifier
使用源域数据进行标准的监督训练,训练 EsEs 和 CC:
minES,CLS(XS,yS)=E(xs,ys)∼(XS,YS)−∑Kk=11[k=ys]logC(ES(xS))minES,CLS(XS,yS)=E(xs,ys)∼(XS,YS)−∑k=1K1[k=ys]logC(ES(xS))
Step 2: adapt the target encoder via adversarial adaptation with distillation
固定 EsEs 的参数,并使用 EsEs 初始化 EtEt 的参数,接着进行对抗性训练:
minDLdis (XS,XT)=Exs∼XS−logD(ES(xs))+Ext∼XT−log(1−D(Et(xt)))minEtLgen(XT)=Ext∼XT−logD(Et(xt))minDLdis (XS,XT)=Exs∼XS−logD(ES(xs))+Ext∼XT−log(1−D(Et(xt)))minEtLgen(XT)=Ext∼XT−logD(Et(xt))
然而,由于无法使用类标签,该公式很容易导致灾难性的遗忘,从而导致分类性能下降。对于一个使用大的 tt 的知识蒸馏模型,它不仅可以使得对抗性训练稳定,还可以良好的保存类信息。因此,引入了知识蒸馏损失:
LKD(XS)=t2×Exs∼XS∑Kk=1−softmax(pSk/t)×log(softmax(pTk/t))LKD(XS)=t2×Exs∼XS∑k=1K−softmax(pkS/t)×log(softmax(pkT/t))
其中,pS=C(ES(xs))pS=C(ES(xs))、pT=C(Et(xs))pT=C(Et(xs));
因此,训练目标编码器 EtEt 的最终目标函数变为:
minEtLT(XS,XT)=Lgen (XT)+LKD(XS)minEtLT(XS,XT)=Lgen (XT)+LKD(XS)
Step 3: test the target encoder on the target data
使用训练好的目标编码器 $E_t$ 和分类器 $C$ 对用于测试的目标数据情绪极性标签预测如下:
y^t=argmaxC(Et(xt))y^t=argmaxC(Et(xt))
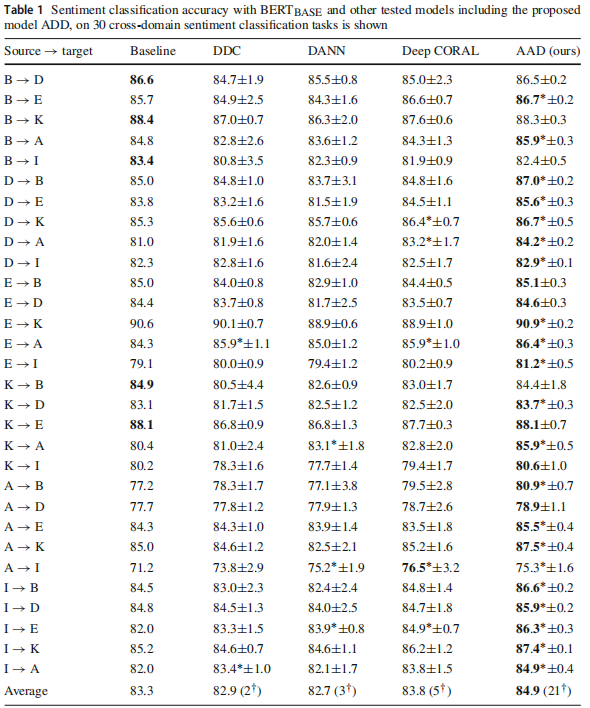
跨域情感分析
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK