

重训「羊驼」大模型并彻底开放商用,UC伯克利博士生:Meta不愿做就自己做
source link: https://www.qbitai.com/2023/06/62980.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

重训「羊驼」大模型并彻底开放商用,UC伯克利博士生:Meta不愿做就自己做

性能媲美原版
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
Meta“羊驼”(LLaMA)的开源可商用复现品OpenLLaMA发布重大更新:
在1T token上训练出来的130亿参数版本现已正式上线。
至此,这一训练量和原版羊驼已完全一致。

与此同时,之前发布的70亿以及30亿参数版本也完成了1T token的训练,并发布PyTorch和JAX权重。
可谓“一家人整整齐齐”。
性能测试显示,OpenLLaMA在多项任务中的表现都与原始LLaMA相当,并且不乏超越的情况。

一个彻底开源且供商用的LLaMA竞品家族就此诞生了。
目前,OpenLLaMA在GitHub上的标星数已近5k。
重训“羊驼”,最香替代品全面开放商用
OpenLLaMA是UC伯克利的博士生Hao Liu发起的项目(Xinyang Geng拥有同等贡献,也是该校博士生)。
它在Together公司发布的RedPajama数据集上训练,该数据集其实也是LLaMA训练集的复制品,一共包含1.2T token。
除了数据集不太一样之外,OpenLLaMA使用了与原始LLaMA完全相同的预处理步骤和训练超参数,包括模型架构、上下文长度、训练步骤、学习率时间表和优化器,可以说是“重训”了一把。
今年5月,该团队率先发布了70亿参数版本,不过当时训练token还是3000亿。
按照计划,如今和原LLaMA训练数据量一致的130亿参数版本和70亿、30亿版本一同发布。

据介绍,130亿版本是与Stability AI合作训练的,后者主要提供计算资源(当初Stable Diffusion也是这么与Stability AI合作)。
和另外两个版本一样,OpenLLaMA-13B也以两种格式发布权重:
一是用于Hugging Face transformer的PyTorch格式。
使用该格式时需要注意先避免使用Hugging Face快速分词器(tokenizer),因为它的自动转换功能有时会给出不正确的tokenization。
所以可以先直接使用LlamaTokenizer class来实现,或者用AutoTokenizer class,将use_fast赋为False。
二是用于EasyLM框架的EasyLM格式。
在此请注意,与原始LLaMA不同,该OpenLLaMA的分词器和权重是完全从头开始训练的,因此不再需要获取原始 LLaMA的这俩信息。
接下来,在训练量已达成一致的情况下,看OpenLLaMA各规模模型的性能表现如何。
在这里,作者使用EleutherAI发布的自回归语言模型few-shot评估框架(lm-evaluation-harness)对两只“羊驼”进行评估,以及还加入了“第三者”:
EleutherAI在Pile数据集上训练的60亿参数模型GPT-J,它的训练token数是5000亿。
需要注意的是,可能是因为不同的评估协议,作者跑出来的LLaMA结果与原始LLaMA略有不同。
以下是结果:
红色小方框为OpenLLaMA超过或者与原LLaMA表现一样的情况。
在红框之外,两者的差距也不大。
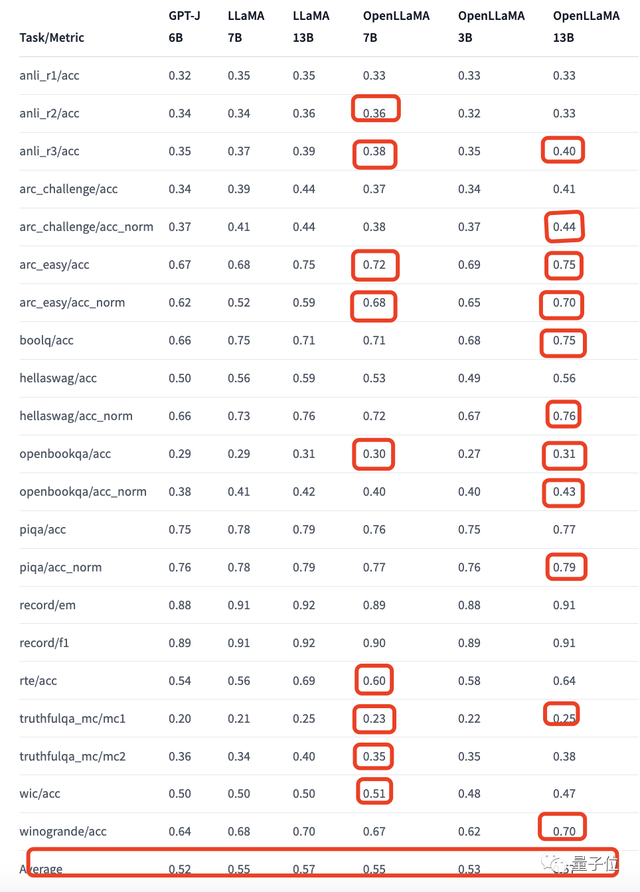
而从平均表现来看,OpenLLaMA-7B和LLaMA-7B得分都是0.55,OpenLLaMA-13B和LLaMA-13B也都一样,为0.57,主打一个势均力敌。
与此同时,只有30亿参数的OpenLLaMA平均性能超越60亿参数的GPT-J。
Meta也要发可商用大模型了
特斯拉前AI高级总监Andrej Karpathy在上个月的微软Build大会的演讲上,曾多次表达一个意思:
LLaMA-65b就是目前最好的开源基础模型,可惜没能商用。

现在,650亿的商用平替羊驼虽然还没出现,130亿和70亿是已经妥妥安排好了。
不过,也有一则好消息。
就在几天前,据The Information爆料,Meta AI正计划发布一个新的LLM,并且免费供大家商用。
有观点指出,在如今行业大佬如谷歌Bard和OpenAI ChatGPT都“紧闭大门”的情况下,Meta这一做法可能会引发连锁反应,并且开源模型和闭源模型的差距会越来越小。
就且拭目以待。
关于OpenLLaMA的所有相关链接:
https://github.com/openlm-research/open_llama
https://huggingface.co/openlm-research/open_llama_13b
本文参考链接还包括:
https://www.artisana.ai/articles/metas-plan-to-offer-free-commercial-ai-models-puts-pressure-on-google-and
Recommend
-
53
加密羊驼 - 羊驼主题区块链游戏,前 Facebook/Twitter/ 头条大牛倾力打造 - NEXT
-
73
来源:学术经纬由于长相喜人,羊驼在网络上曾一度被称为“神兽”。这当然有戏谑和调侃的成分在,但从科学的角度讲,羊驼的确是一种神奇的动物。最近,顶尖学术期刊《科学》上发表了一篇关于羊驼的论文——来自美国Scripps研究所的科学家们利用大羊驼的
-
9
抖音被发现审查羊驼 WinterIsComing (31822)发表于 2021年05月14日 17时30分 星期...
-
5
骆驼、羊驼超萌小动物在线寻主 京东拍卖618带你体验“拍万物” 拱北海关上拍京东拍卖的一批奢侈品服饰、包包首饰等以572.6万元成交,溢价率达到94.55%;厦门市中级人民...
-
7
首个大规模使用工具的大模型来了:伯克利发布Gorilla 作者:机器之心 2023-05-26 17:20:29 大型语言模型(LLM)近来出尽风头,在自然对话、数学推理和程序合成等任务上都取得了显著进展。
-
12
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品
-
3
一句话让AI训练AI!20分钟微调羊驼大模型,从数据收集到训练全包了
-
5
2023-10-16 08:46 加州大学伯克利分校推出 MemGPT,解决大模型输入限制 据品玩 10 月 16 日报道,Arxiv 页面显示,加州大学伯克利分校的研究者们推出了一款名为 MemGPT 的大语言模型系统。该研究团队通过借鉴传统操作系统中的层次...
-
6
7B羊驼战胜540B“谷歌版GPT”,MIT用博弈论调教大模型,无需训练就能完成量子位·2023-10-17 11:28把语言解码变成博弈过程
-
5
四行代码让大模型上下文暴增3倍,羊驼Mistral都适用
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK