

思维链如何释放语言模型的隐藏能力?最新理论研究揭示其背后奥秘
source link: https://www.51cto.com/article/756474.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
思维链如何释放语言模型的隐藏能力?最新理论研究揭示其背后奥秘
思维链提示(CoT)是大模型涌现中最神秘的现象之一,尤其在解决数学推理和决策问题中取得了惊艳效果。CoT到底有多重要呢?它背后成功的机制是什么?本文中,北大的几位研究者证明了CoT在实现大语言模型(LLM)推理中是不可或缺的,并从理论和实验角度揭示了CoT如何释放LLM的巨大潜力。
最近的研究发现,思维链提示(Chain of Thought prompting,简称为 CoT)可以显著提升大语言模型(LLM)的性能,尤其适用于处理涉及数学或推理的复杂任务。不过尽管取得了很大成功,但 CoT 背后的机制以及如何释放 LLM 的潜力仍然难以捉摸。
近日,北京大学的一项新研究从理论视角揭示了 CoT 背后的奥秘。

论文链接:https://arxiv.org/abs/2305.15408
基于 Transformer 的大语言模型已经成为自然语言处理中的通用模型,在各种任务上都获得了广泛的应用。主流的大模型通常基于自回归范式来实现,具体而言,各种不同的任务(如文本翻译、文本生成、问题回答等)都可以统一地视为序列生成问题,其中问题的输入和问题描述被一起被编码为一个单词(token)序列,称为提示(prompt);问题的答案便可以转化为基于提示来条件生成后续单词的任务。

在大模型领域中有大量的研究已经表明,精心设计的提示词对模型的表现起着至关重要的作用。特别是在涉及算术或推理相关的任务时, CoT 已被表明能够大大提高所生成答案的正确性。如下图所示,对于一个需要数学推理的任务,大模型直接生成的答案往往是错误的(下图 a,b)。但是如果通过修改提示使得大模型输出整个思维链(中间推导步骤),最终便能够得到正确答案(下图 c,d)。

在实践中,思维链提示有两种主流的实现方式:一种是在提示中添加特定短语,如 “Let’s think step by step” 来触发(如上图 c);另一种是通过提供少量的思维链演示的例子来让大模型模拟相应的推导过程(如上图 d)。
然而,尽管 CoT 在大量实验上都取得了显著的表现,但背后的理论机制却仍然是个谜。一方面,大模型在直接回答数学、推理等问题方面是否确实存在固有理论缺陷?另一方面,为什么 CoT 可以提升大模型在这些任务上的能力?这篇论文从理论角度对上述问题进行了回答。
具体而言,研究者从模型表达能力的角度来研究 CoT:对于数学任务和一般的决策任务,本文研究了基于自回归的 Transformer 模型在以下两个方面的表达能力:(1)直接生成答案,以及(2)采用 CoT 的方式生成完整的解决步骤。
CoT 是解决数学问题的关键
以 GPT-4 为代表的大模型已经展现出了令人震惊的数学能力。例如,它能够正确求解大部分高中数学题,甚至已经成为数学家们的研究助手。
为了研究大模型在数学方面的能力,本文选取了两个非常基础但核心的数学任务:算术和方程(下图给出了这两个任务的输入输出示例)。由于它们是解决复杂数学问题的基本组件,因此通过对这两个核心数学问题的研究,我们可以对大模型在一般数学问题上的能力有一个更深刻的理解。

研究者首先探究了 Transformer 是否能够输出上述问题的答案而不输出中间步骤。他们考虑了一种与实际非常吻合的假设 ——log 精度 Transformer,即 Transformer 的每个神经元只能表示有限精度的浮点数(精度为 log n 比特),其中 n 是句子的最大长度。这一假设与实际非常接近,例如在 GPT-3 中,机器精度(16 位或 32 位)通常要远小于最大输出句子长度(2048)。
在这一假设下,研究者证明了一个核心不可能结果:对于常数层、宽度为 d 的自回归 Transformer 模型,以直接输出答案的方式求解上述两个数学问题时,需要使用极大的模型宽度 d。具体而言,d 需要以超越多项式的增长速度随输入长度 n 的增长而变大。
造成这一结果的本质原因在于,上述两个问题不存在高效的并行算法,因此 Transformer 作为一种典型的并行模型无法对其进行求解。文章使用理论计算机科学中的电路复杂性理论对上述定理进行了严格证明。
那么,如果模型不直接输出答案,而是按照上图的形式输出中间推导步骤呢?研究者进一步通过构造证明了,当模型可以输出中间步骤时,一个固定大小(不依赖于输入长度 n)的自回归 Transformer 模型便可以解决上述两个数学问题。
对比之前的结果可以看出,加入 CoT 极大地提升了大模型的表达能力。研究者进一步对此给出了直观的理解:这是因为 CoT 的引入会将生成的输出单词不断回馈到输入层,这大大增加了模型的有效深度,使其正比于 CoT 的输出长度,从而极大地提升了 Transformer 的并行复杂度。
CoT 是解决一般决策问题的关键
除了数学问题,研究者进一步考虑了 CoT 在解决一般任务上的能力。他们从决策问题出发,考虑了一种解决决策问题的通用框架,称为动态规划。
动态规划(DP)的基本思想在于将复杂问题分解为一系列可以按顺序解决的小规模子问题。其中对问题的分解确保了各个子问题之间存在显著的相互关联(重叠),从而使得每个子问题可以利用之前的子问题上的答案来高效解决。
最长上升子序列(LIS)和求解编辑距离(ED)是《算法导论》一书中提出的两个著名的 DP 问题,下表列出了这两个问题的状态空间、转移函数的聚合函数。

研究者证明了,自回归 Transformer 模型可以按照解决子问题的顺序输出一个完整的动态规划思维链,从而对于所有能够用动态规划解决的任务都能输出正确答案。同样地,研究者进一步证明了生成思维链是必要的:对于很多困难的动态规划问题,一个常数层、多项式大小的 Transformer 模型无法直接输出正确答案。文章通过上下文无关文法成员测试这一问题给出了反例。
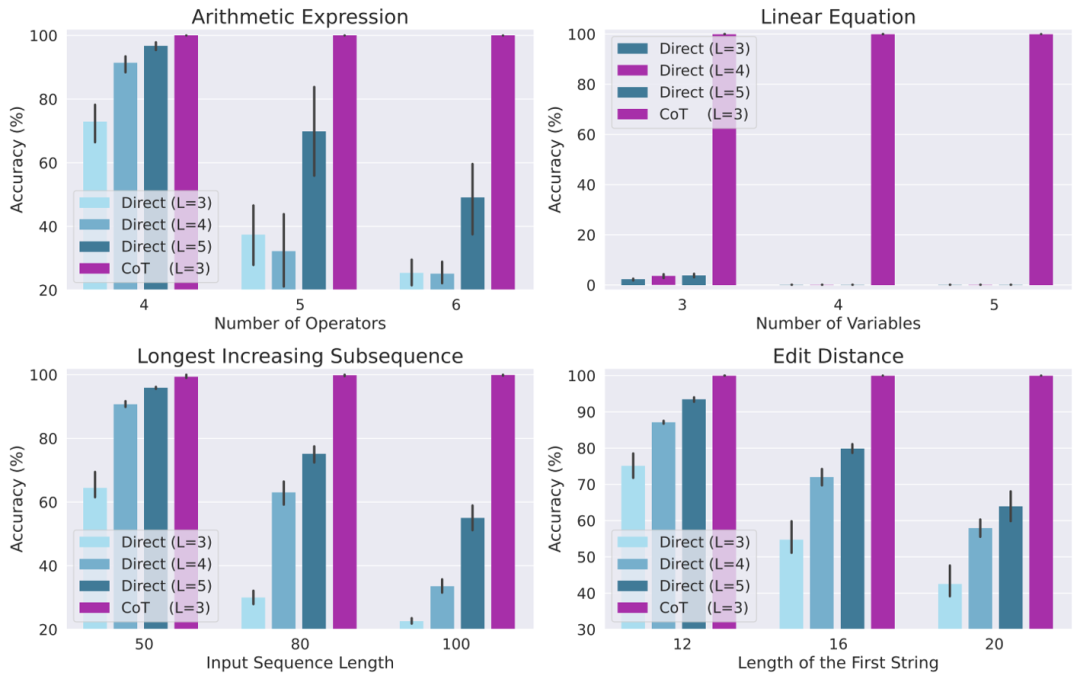
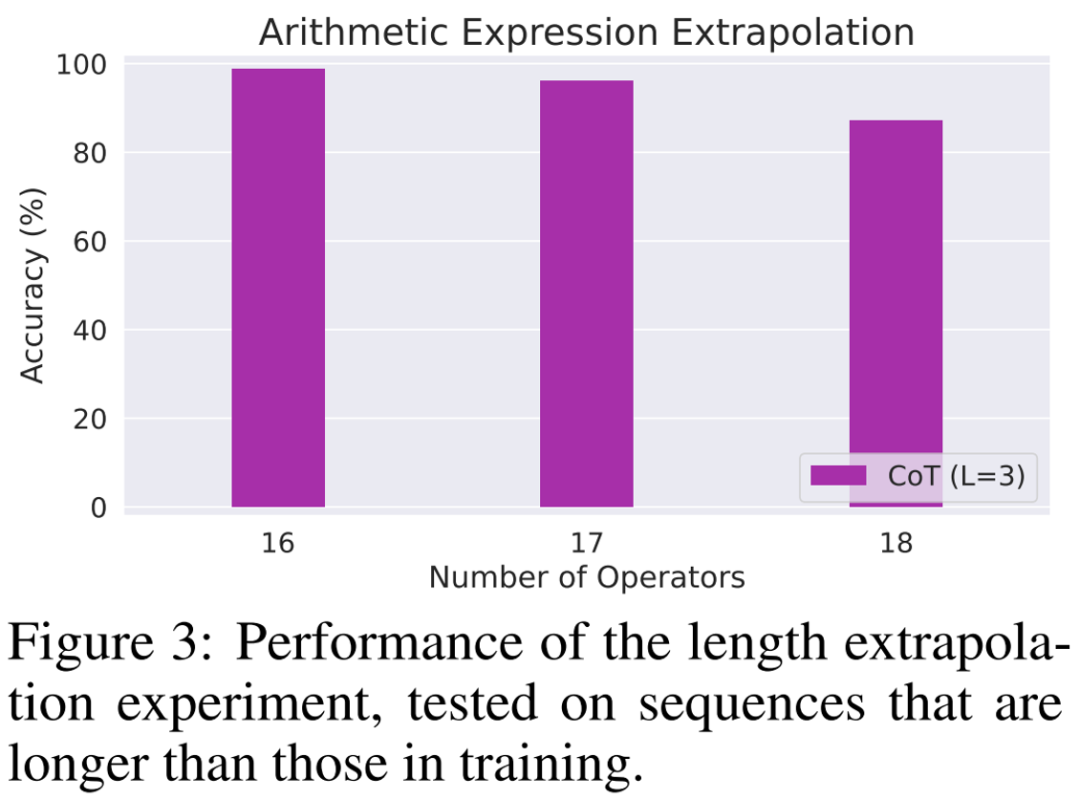
研究者最后设计了大量实验对上述理论进行了验证,考虑了四种不同的任务:算术表达式求值、解线性方程组、求解最长上升子序列以及求解编辑距离。
实验结果表明,当使用 CoT 数据进行训练时,一个 3 层的自回归 Transformer 模型已经能够在所有任务上均取得几乎完美的表现。然而,直接输出正确答案在所有任务上的表现都很差(即使使用更深的模型)。这一结果清楚地展示了自回归 Transformer 在解决各种复杂任务上的能力,并表明了 CoT 在解决这些任务中的重要性。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK