

Kafka集群是如何选择Leader,你知道吗?
source link: https://www.51cto.com/article/756134.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
kafka集群是由多个broker节点组成,这里面包含了许多的知识点,以下的这些问题你都知道吗?
- 你知道topic的分区leader是怎么选举的吗?
- 你知道zookeeper中存储了kafka的什么信息吗?起到什么做呢?
- 你知道kafka消息文件是怎么存储的吗?
- 如果kafka中leader节点或者follower节点发生故障,消息会丢失吗?如何保证消息的一致性和可靠性呢?
如果你对这些问题比较模糊的话,那么很有必要看看本文,去了解以下kafka的核心设计,本文主要基于kafka3.x版本讲解。
kafka broker核心机制
kafka集群整体架构
kafka集群是由多个kafka broker通过连同一个zookeeper组成,那么他们是如何协同工作对外提供服务的呢?zookeeper中又存储了什么信息呢?
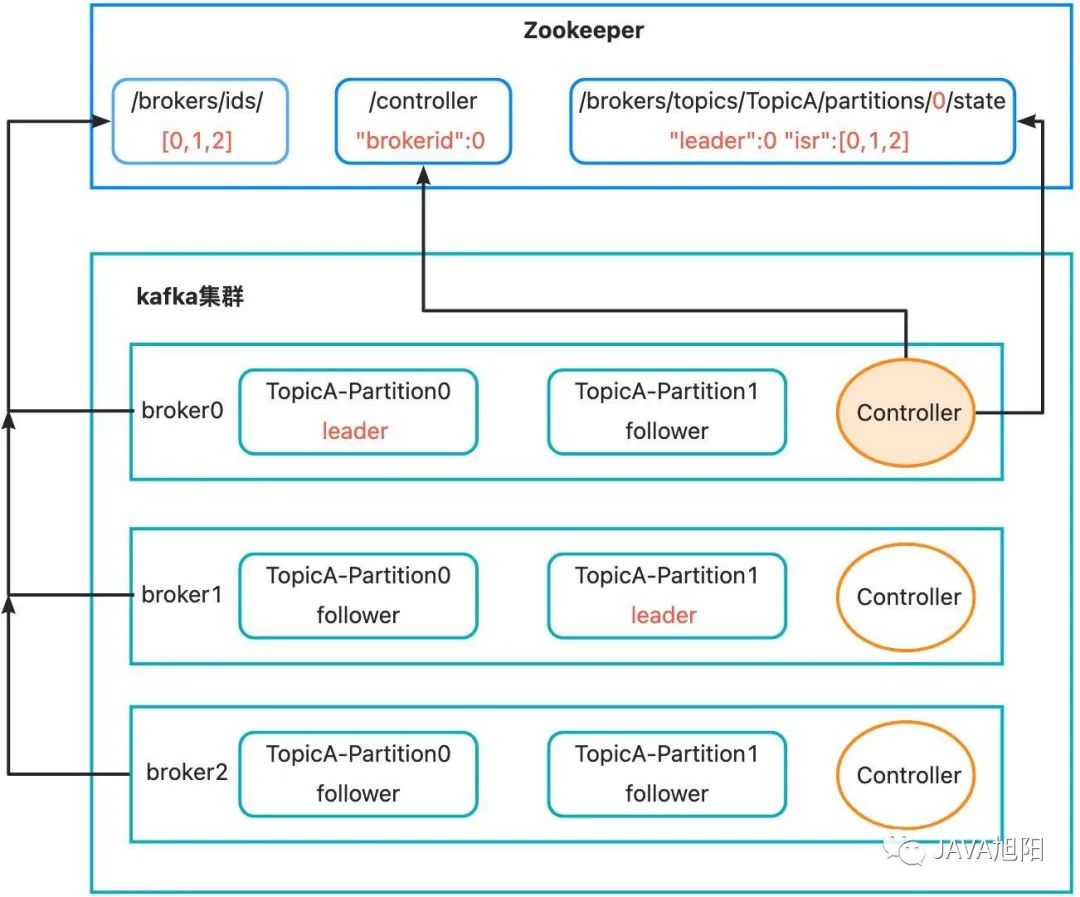
- kafka broker启动后,会在zookeeper的/brokers/ids路径下注册。
- 同时,其中一个broker会被选举为控制器(Kafka Controller)。选举规则也很简单,谁先注册到zookeeper中的/controller节点,谁就是控制器。Controller主要负责管理整个集群中所有分区和副本的状态。
- Kafka Controller会进行Leader选择,比如上图中针对TopicA中的0号分区,选择broker0作为Leader, 然后会将选择的节点信息注册到zookeeper的/brokers/topics路径下,记录谁是Leader,有哪些服务器可用。
- 被选举为Leader的topic分区提供对外的读写服务。为什么只有Leader节点提供读写服务,而不是设计成主从方式,Follower提供读服务呢?
- 为了保证数据的一致性,因为消息同步延迟,可能导致消费者从不同节点读取导致不一致。
- kafka设计目的是分布式日志系统,不是一个读多写少的场景,kafka的读写基本是对等的。
- 主从方式的话带来设计上的复杂度。
kafka leader选举机制
那么问题来了,kafka中topic分区是如何选择leader的呢?为了更好的阐述,我们先来理解下面3个概念。
- ****ISR:表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的Leader。
- ****OSR:表示 Follower 与 Leader 副本同步时,延迟过多的副本。
- ****AR: 指的是分区中的所有副本,所以AR = ISR + OSR。
Kafka Controller选举Leader的规则:在isr队列中存活为前提,按照AR中排在前面的优先。例如ar[1,0,2], isr [1,0,2],那么leader就会按照1,0,2的顺序轮询。而AR中的这个顺序kafka会进行打散,分摊kafka broker的压力。
当运行中的控制器突然宕机或意外终止时,Kafka 通过监听zookeeper能够快速地感知到,并立即启用备用控制器来代替之前失败的控制器。这个过程就被称为 Failover,该过程是自动完成的,无需你手动干预。
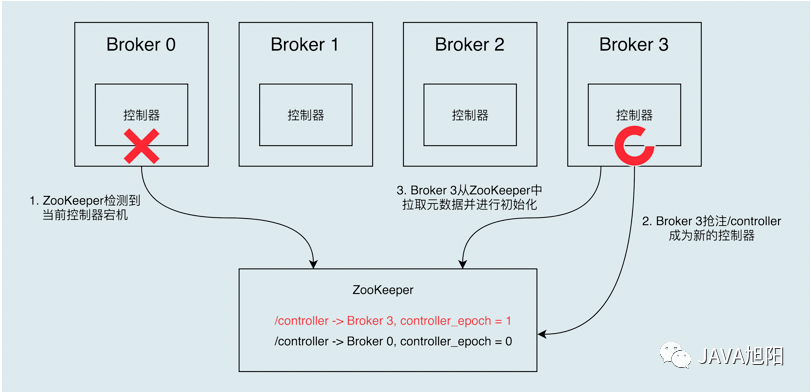
开始的时候,Broker 0 是控制器。当 Broker 0 宕机后,ZooKeeper 通过`` Watch 机制感知到并删除了 /controller 临时节点。之后,所有存活的 Broker 开始竞选新的控制器身份。Broker 3最终赢得了选举,成功地在 ZooKeeper 上重建了 /controller 节点。之后,Broker 3 会从 ZooKeeper 中读取集群元数据信息,并初始化到自己的缓存中,后面就有Broker 3来接管选择Leader的功能了。
Leader 和 Follower 故障处理机制
如果topic分区的leader和follower发生了故障,那么对于数据的一致性和可靠性会有什么样的影响呢?
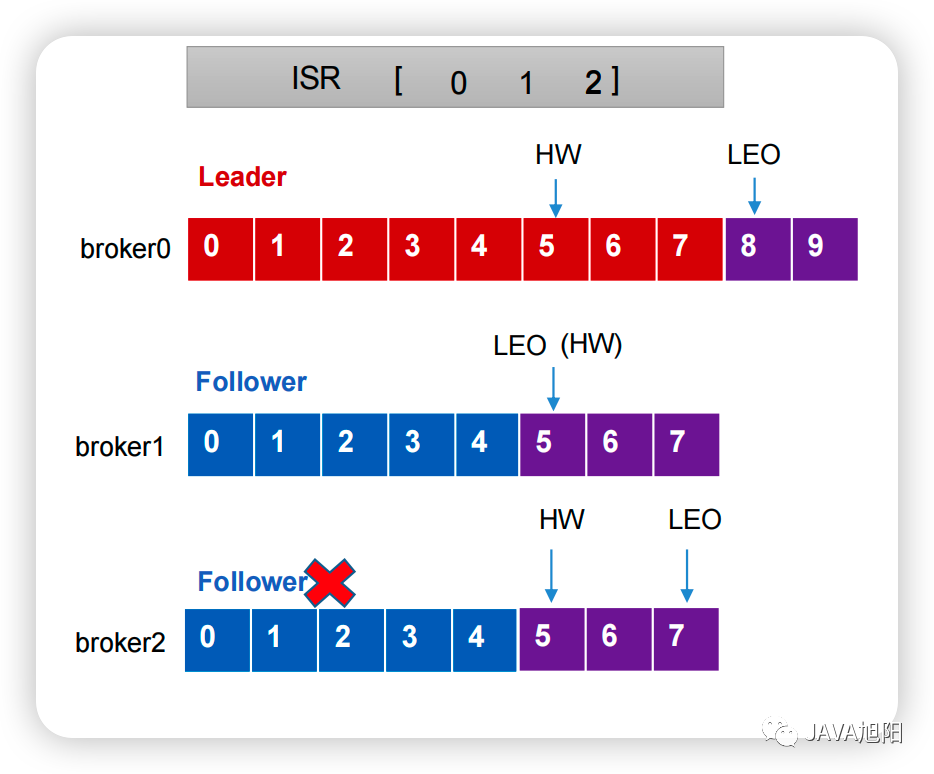
- LEO(Log End Offset):每个副本的最后一个offset,LEO就是最新的offset + 1。
- HW(High Watermark):水位线,所有副本中最小的LEO ,消费者只能看到这个水位线左边的消息,从而保证数据的一致性。
上图所示,如果follower发生故障怎么办?
- Follower发生故障后会被临时踢出ISR队列。
- 这个期间Leader和Follower继续接收数据。
- 待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
- 等该Follower的LEO大于等于该Partition的HW,即Follower追上Leader之后,就可以重新加入ISR了。
如果leader发生故障怎么办?
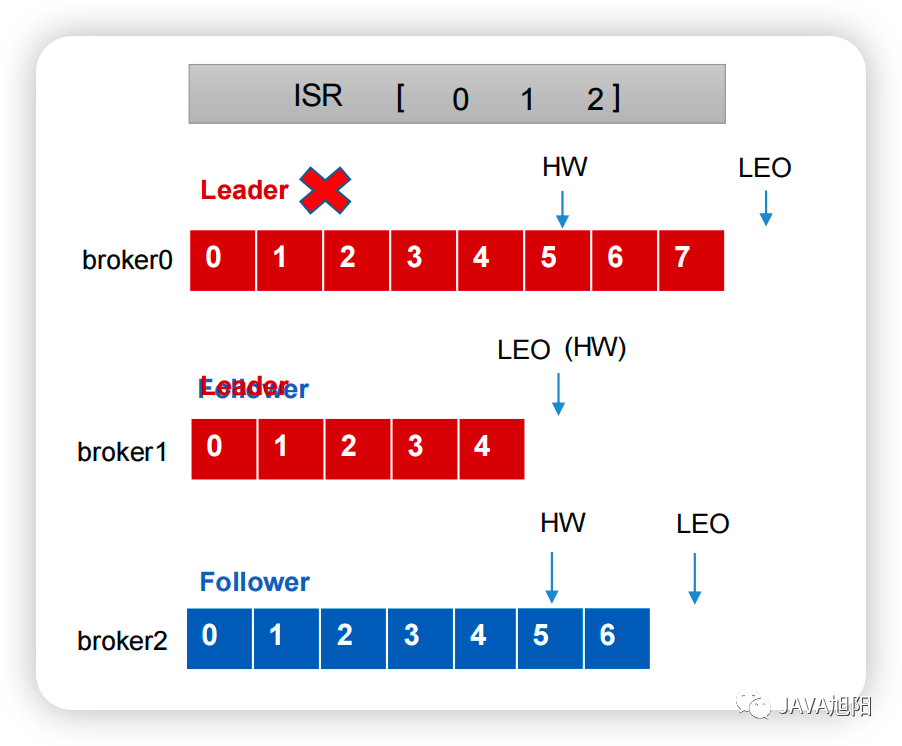
- Leader发生故障之后,会从ISR中选出一个新的Leader
- 为保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于HW的部分截掉,然后从新的Leader同步数据。
所以为了让kafka broker保证消息的可靠性和一致性,我们要做如下的配置:
- 设置 生产者producer 的配置acks=all或者-1。leader 在返回确认或错误响应之前,会等待所有副本收到悄息,需要配合min.insync.replicas配置使用。这样就意味着leader和follower的LEO对齐。
- 设置topic 的配置replication.factor>=3副本大于3个,并且 min.insync.replicas>=2表示至少两个副本应答。
- 设置broker配置unclean.leader.election.enable=false,默认也是false,表示不对落后leader很多的follower也就是非ISR队列中的副本选择为Leader, 这样可以避免数据丢失和数据 不一致,但是可用性会降低。
Leader Partition 负载平衡
正常情况下,Kafka本身会自动把Leader Partition均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某些broker宕机,会导致Leader Partition过于集中在其他少部分几台broker上,这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是follower partition,读写请求很低,造成集群负载不均衡。那么该如何负载平衡呢?
- 自动负载均衡
通过broker配置设置自动负载均衡。
- auto.leader.rebalance.enable:默认是 true。自动 Leader Partition 平衡。生产环境中,leader 重选举的代价比较大,可能会带来性能影响,建议设置为 false 关闭。
- leader.imbalance.per.broker.percentage:默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。
- leader.imbalance.check.interval.seconds:默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
- 手动负载均衡
- 对所有topic进行负载均衡
./bin/kafka-preferred-replica-election.sh --zookeeper hadoop16:2181,hadoop17:2181,hadoop18:2181/kafka08- 对指定topic负载均衡
cat topicPartitionList.json
{
"partitions":
[
{"topic":"test.example","partition": "0"}
]
}./bin/kafka-preferred-replica-election.sh --zookeeper hadoop16:2181,hadoop17:2181,hadoop18:2181/kafka08 --path-to-json-file topicPartitionList.jsonkafka的存储机制
kafka消息最终会存储到磁盘文件中,那么是如何存储的呢?清理策略是什么呢?
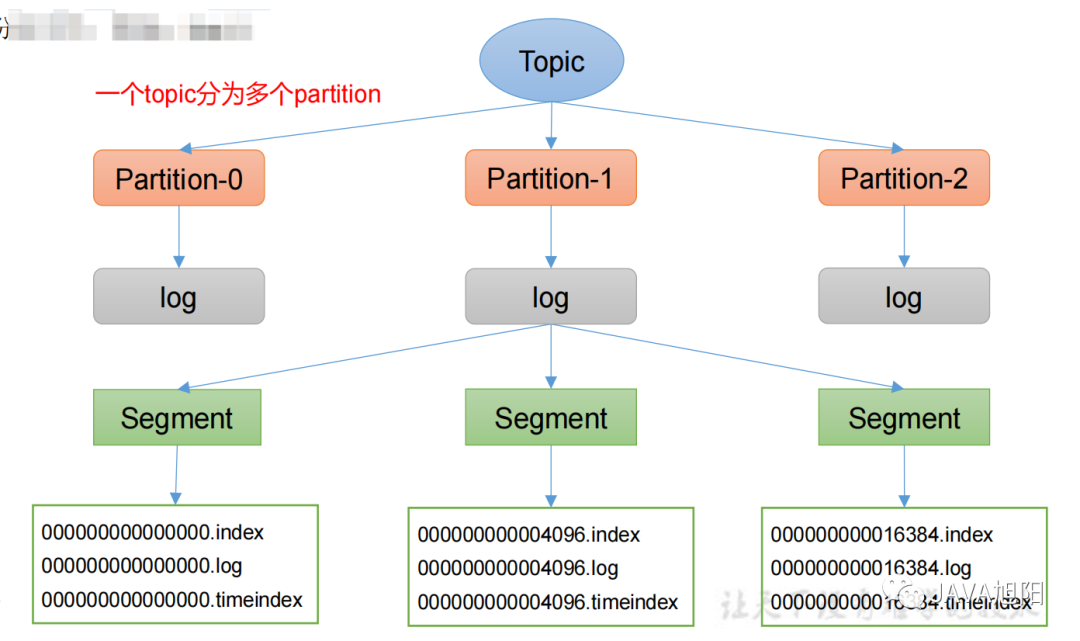
一个topic分为多个partition,每个partition对应于一个log文件,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,每个partition分为多个segment。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件,Producer生产的数据会被不断追加到该log文件末端。
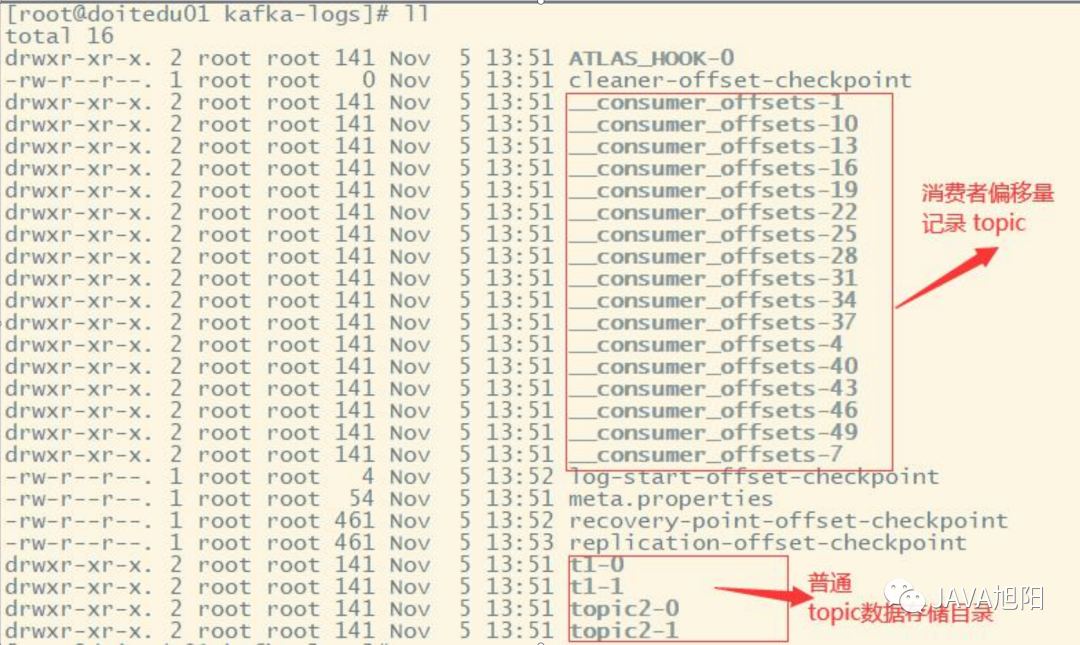
上图中t1即为一个topic的名称,而“t1-0/t1-1”则表明这个目录是t1这个topic的哪个partition。
kafka中的索引文件以稀疏索引(sparseindex)的方式构造消息的索引,如下图所示:

1.根据目标offset定位segment文件
2.找到小于等于目标offset的最大offset对应的索引项
3.定位到log文件
4.向下遍历找到目标Record
注意:index为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引。通过参数log.index.interval.bytes控制,默认4kb。
那kafka中磁盘文件保存多久呢?
kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
- log.retention.hours,最低优先级小时,默认 7 天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
kafka broker重要参数
前面讲解了kafka broker中的核心机制,我们再来看下重要的配置参数。
首先来说下kafka服务端配置属性Update Mode的作用:

- read-only。被标记为read-only 的参数和原来的参数行为一样,只有重启 Broker,才能令修改生效。
- per-broker。被标记为 per-broker 的参数属于动态参数,修改它之后,无需重启就会在对应的 broker 上生效。
- cluster-wide。被标记为 cluster-wide 的参数也属于动态参数,修改它之后,会在整个集群范围内生效,也就是说,对所有 broker 都生效。也可以为具体的 broker 修改cluster-wide 参数。
Broker重要参数
replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。 |
auto.leader.rebalance.enable | 默认是 true。自动 Leader Partition 平衡。 |
leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。 |
leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。 |
log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。 |
log.index.interval.bytes | 默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 |
log.retention.hours | Kafka 中数据保存的时间,默认 7 天。 |
log.retention.minutes | Kafka 中数据保存的时间,分钟级别,默认关闭。 |
log.retention.ms | Kafka 中数据保存的时间,毫秒级别,默认关闭。 |
log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是 5 分钟。 |
log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。 |
log.cleanup.policy | 默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。 |
num.io.threads | 默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。 |
num.replica.fetchers | 副本拉取线程数,这个参数占总核数的 50%的 1/3 |
num.network.threads | 默认是 3。数据传输线程数,这个参数占总核数的50%的 2/3 。 |
log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。 |
Kafka集群的分区多副本架构是 Kafka 可靠性保证的核心,把消息写入多个副本可以使 Kafka 在发生崩溃时仍能保证消息的持久性。本文围绕这样的核心架构讲解了其中的一些核心机制,包括Leader的选举、消息的存储机制等等。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK