

聊聊谷歌搜索算法的演进
source link: https://www.51cto.com/article/756130.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

聊聊谷歌搜索算法的演进
PageRank
PageRank算法时期:在谷歌创立初期,使用的主要是PageRank算法。这个算法基于网页之间的链接关系来计算网页的重要性,从而进行排名。简单来说,如果一个网页被其他网页链接得越多,那么它的PageRank值就越高,排名就越靠前。PageRank算法在谷歌搜索早期起到了非常重要的作用,但随着互联网的发展,其算法的局限性也逐渐显现出来,比如易受到人为操纵,对于新网页和孤立网页的处理不够准确等。
PageRank算法的基本思想是通过网页之间的链接关系来评估网页的重要性。具体来说,PageRank算法将互联网看作是一个有向图,其中每个网页是图中的一个节点,每个链接则表示节点之间的有向边。在这个图中,每个网页的PageRank值是根据其入度链接的数量和链接到的网页的PageRank值计算出来的。
具体来说,PageRank算法的计算过程分为两个步骤。首先,将每个网页的PageRank值初始化为一个固定的数值(通常是1)。然后,通过迭代计算,不断更新每个网页的PageRank值,直到收敛为止。在每次迭代中,每个网页的PageRank值都会根据其入度链接的数量以及链接到的网页的PageRank值进行更新。具体来说,每个网页的新的PageRank值等于其所有入度链接的PageRank值之和,加上一个阻尼因子(通常为0.85)乘以所有网页的PageRank值之和除以网页总数。
通过这样的迭代计算,PageRank算法可以得出每个网页的PageRank值,从而将网页按照其重要性进行排名。值得注意的是,PageRank算法并不是唯一的排名算法,但它在互联网搜索引擎中得到广泛应用,因为它能够很好地反映网页之间的链接关系,并且具有较好的可解释性和稳定性。
智能检索时期:在2001年左右,谷歌开始使用一些基于统计学和自然语言处理的算法,如Latent Semantic Indexing(LSI)和Term Frequency-Inverse Document Frequency(TF-IDF)等算法,来提高搜索结果的相关性和准确性。LSI算法是一种基于奇异值分解的算法,可以通过分析文本的语义结构来识别相关性,从而提高搜索结果的相关性。TF-IDF算法则是一种基于词频和文档频率的算法,可以评估一个词语在文本中的重要性,从而提高搜索结果的准确性。这些算法的应用,大大提高了谷歌搜索的质量和准确性。
TF-IDF算法是一种基于词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)的算法。在搜索引擎中,TF-IDF算法用于评估一个词语在文本中的重要性,从而提高搜索结果的准确性。
TF-IDF算法的主要思想是:如果一个词语在某个文档中出现的次数越多,那么它在文档中的重要性就越高;但如果这个词语在所有文档中都出现的很频繁,那么它的重要性就降低;反之,如果这个词语只在少数文档中出现,那么它的重要性就会提高。因此,TF-IDF算法的计算公式如下:
TF-IDF = TF * IDF
其中,TF表示词语在文档中出现的频率,计算公式为:
TF = (在文档中出现的次数) / (文档总词数)
IDF表示逆文档频率,计算公式为:
IDF = log(文档总数 / 包含该词语的文档数)
通过TF和IDF的乘积计算出每个词语在文档中的重要性,然后根据重要性对文档进行排序和排名。TF-IDF算法能够有效地评估每个词语的重要性,从而提高搜索结果的准确性。
LSI算法是一种基于奇异值分解(Singular Value Decomposition, SVD)的算法,用于提高搜索结果的相关性。LSI算法的主要思想是:通过分析文本的语义结构,识别出相关性,从而提高搜索结果的相关性。
LSI算法的计算流程包括以下几个步骤:
(1)将文本转化为矩阵表示。
(2)对矩阵进行奇异值分解。
(3)选择前k个奇异值对应的奇异向量,作为文本的新的表示。
(4)对用户的查询语句进行同样的转换和向量表示。
(5)计算查询向量和文本向量之间的余弦相似度,从而确定相关性。
通过LSI算法,搜索引擎能够更好地识别出文本之间的相关性,从而提高搜索结果的相关性和准确性。LSI算法在搜索引擎中的应用,能够提高搜索结果的质量和准确性,为用户提供更好的搜索体验。
机器学习时期:从2010年左右开始,谷歌开始采用机器学习算法来提高搜索结果的质量和准确性。这些算法包括基于神经网络的深度学习算法、支持向量机(SVM)算法、随机森林算法等。这些算法能够更好地处理海量的数据和复杂的问题,能够对用户的搜索意图和查询语句进行更加准确的识别和匹配,从而提供更加精准的搜索结果。
SVM(Support Vector Machine)算法是一种二分类模型,广泛应用于机器学习、数据挖掘和模式识别等领域。在谷歌搜索中,SVM算法被用于识别和过滤垃圾信息、识别和过滤恶意软件等方面。
SVM算法的主要思想是:将数据集映射到高维空间中,将不同类别的数据分隔开来,从而实现分类。SVM算法的核心是找到一个超平面,使得不同类别的数据被分隔开来,同时使得分类间隔最大化。如果数据集不是线性可分的,可以通过核函数将其映射到高维空间中来实现分类。
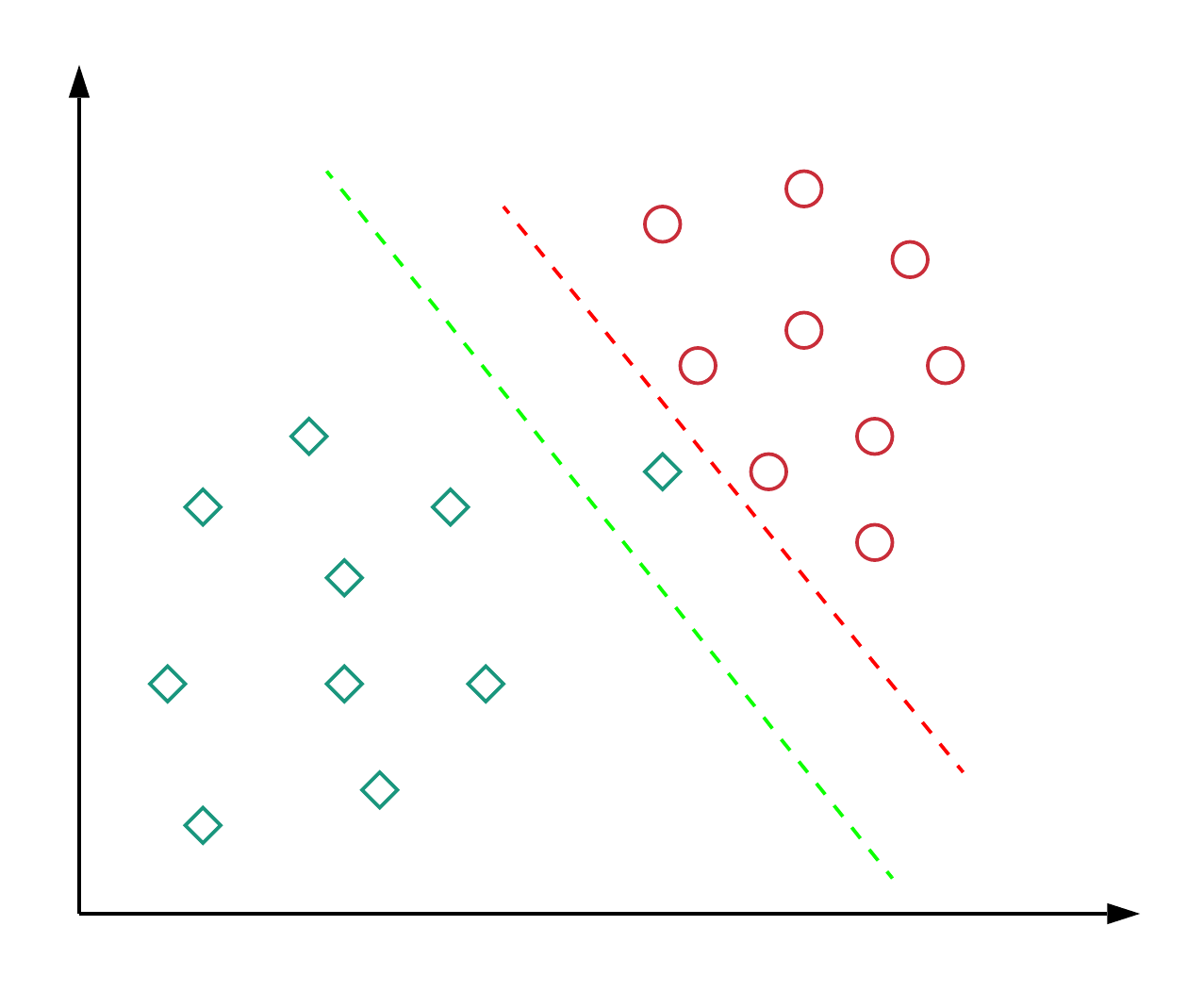
SVM算法的优点包括:对于小样本数据集具有较高的准确性和泛化能力、可以处理高维数据、对异常值的鲁棒性较好等。在谷歌搜索中,SVM算法被广泛应用于分类、回归和异常检测等方面,能够提高搜索结果的准确性和相关性。
随机森林算法是一种集成学习算法,通过结合多个决策树模型来提高分类和回归的准确性。在谷歌搜索中,随机森林算法被用于识别和过滤垃圾信息、识别和过滤恶意软件等方面。
随机森林算法的核心是:通过建立多个决策树模型,对数据进行分类或回归。每个决策树模型都是在随机选取的子集数据上进行训练的,从而降低了模型的方差和过拟合风险。在预测时,每个决策树模型都会输出一个分类结果或回归结果,然后通过投票或平均等方式得到最终的分类或回归结果。
随机森林算法的优点包括:可以处理高维数据、对异常值和噪声数据的鲁棒性较好、能够进行特征选择和特征重要性评估等。在谷歌搜索中,随机森林算法被广泛应用于分类、回归和异常检测等方面,能够提高搜索结果的准确性和相关性。o
人工智能时期:近年来,谷歌逐渐将人工智能技术应用到搜索算法中。这些技术包括自然语言处理、计算机视觉、语音识别等。通过这些技术,谷歌搜索能够更好地理解用户的查询意图、提高搜索结果的相关性和准确性,以及为用户提供更好的搜索体验。比如,谷歌搜索现在支持自然语言查询,用户可以用自然语言来表达查询意图,而不是单纯的关键词搜索。此外,谷歌搜索还支持图像搜索和语音搜索等功能,使得用户可以通过更加直观的方式来进行搜索。这些技术的应用,能够进一步提高谷歌搜索的质量和准确性,让搜索结果更加贴近用户的需求和兴趣。
最近谷歌推出的bard聊天搜索,更是将人工智能推上了巅峰,现在的搜索引擎已经可以识别自然语言了,这对于普通用户来说是非常大的便利,大大降低了搜索高质量信息的难度。
Recommend
-
131
Spring Cloud作为一套微服务治理的框架,几乎考虑到了微服务治理的方方面面,之前也写过一些关于Spring Cloud文章,主要偏重各组件的使用,本篇主要解答这两个问题:Spring Cloud在微服务的架构中都做了哪些事情?Spring Cloud提供的这些功能对微服务的架构提供了怎...
-
31
有赞搜索平台是一个面向公司内部各项搜索应用以及部分 NoSQL 存储应用的 PaaS 产品,帮助应用合理高效的支持检索和多维过滤功能,有赞搜索平台目前支持了大大小小一百多个检索业务,服务于近百亿数据。 在为传统的搜索应用提供高...
-
39
在最近的一次核心升级之后,谷歌(Google)向 加密货币 相关网站发送的流量明显少于其他站点,这导致一个圈内知名媒体CCN的站点永...
-
39
-
41
整理:谢县东 (Flink 社区志愿者) 1.PyFlink 的发展史 1.1、v1.8.x ...
-
13
说透算法稳定币:起源、发展、争议与未来演进 算法稳定币...
-
11
2021年05月13日 作者: 永波 季尚 艳伟 非凡 文章链接 13474字 27分钟阅读0. 写在前面AI可以说是目前互联网行业炙手可热的“明星”。无论是老牌巨头,还是...
-
27
ItemCF 的演进:狭义 VS 广义 (查看原文) CF在推荐系统的发展中扮演着举足轻重的角色,虽然已经被使用很长时间了,但依旧经久不衰...
-
6
分享嘉宾:王瑞欣 知乎 算法工程师编辑整理:郭真继出品平台:DataFunTalk 导读: 搜索,是用户获...
-
5
作者 | 侯瑜美搜索与推荐的区别1. 场景需...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK