

马腾宇团队新出大模型预训练优化器,比Adam快2倍,成本减半
source link: https://www.51cto.com/article/755817.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
马腾宇团队新出大模型预训练优化器,比Adam快2倍,成本减半
鉴于语言模型预训练成本巨大,因而研究者一直在寻找减少训练时间和成本的新方向。Adam 及其变体多年来一直被奉为最先进的优化器,但其会产生过多的开销。本文提出了一种简单的可扩展的二阶优化器 Sophia,在与 Adam 比较中,Sophia 在减少了 50% step 数量的情况下实现了与 Adam 相同的验证预训练损失。
大语言模型(LLM)的能力随着其规模的增长而取得了显著的进展。然而,由于庞大的数据集和模型规模,预训练 LLM 非常耗时,需要进行数十万次的模型参数更新。例如,PaLM 在 6144 个 TPU 上进行了为期两个月的训练,总共耗费大约 1000 万美元。因此,提高预训练效率是扩展 LLM 规模的一个主要瓶颈。
本文来自斯坦福大学的研究者撰文《 Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training 》,文中提出了 Sophia(Second-order Clipped Stochastic Optimization)轻量级二阶优化器,旨在通过更快的优化器提高预训练效率,从而减少达到相同预训练损失所需的时间和成本,或者在相同预算下实现更好的预训练损失。

论文地址:https://arxiv.org/pdf/2305.14342.pdf
Sophia 优化器使用随机估计作为 Hessian 矩阵对角线的 pre-conditioner,并采用剪切(clipping)机制来控制最坏情况下的参数大小更新。在像 GPT-2 这样的预训练语言模型上,Sophia 与 Adam 相比,在减少了 50% step 数量的情况下实现了相同的验证预训练损失。
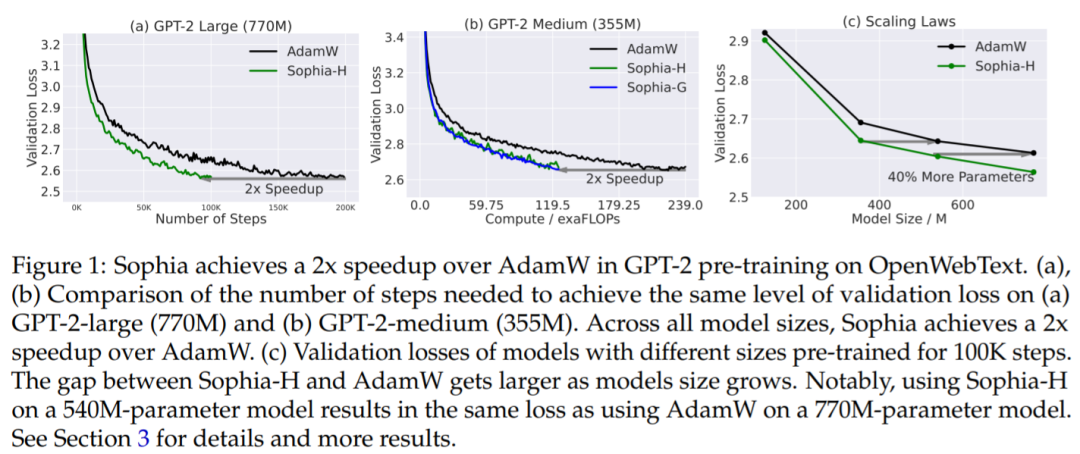
由于 Sophia 可以维持每个 step 内的的内存和所用时间,这相当于总计算量减少了 50%,wall-clock 时间减少了 50%(参见图 1 (a) 和 (b))。此外,根据扩展定律(从模型大小的角度),在 125M 到 770M 的模型上,Sophia 相对于 Adam 更具优势,并且随着模型大小的增加,Sophia 和 Adam 差距也在增加(在 100K step 内)(图 1(c))。特别的,在 540M 参数模型上(100K step),Sophia 和具有 770M 参数模型上的 Adam 实现了相同的验证损失。需要注意的是,后者需要多 达40%的训练时间和 40%的推理成本。
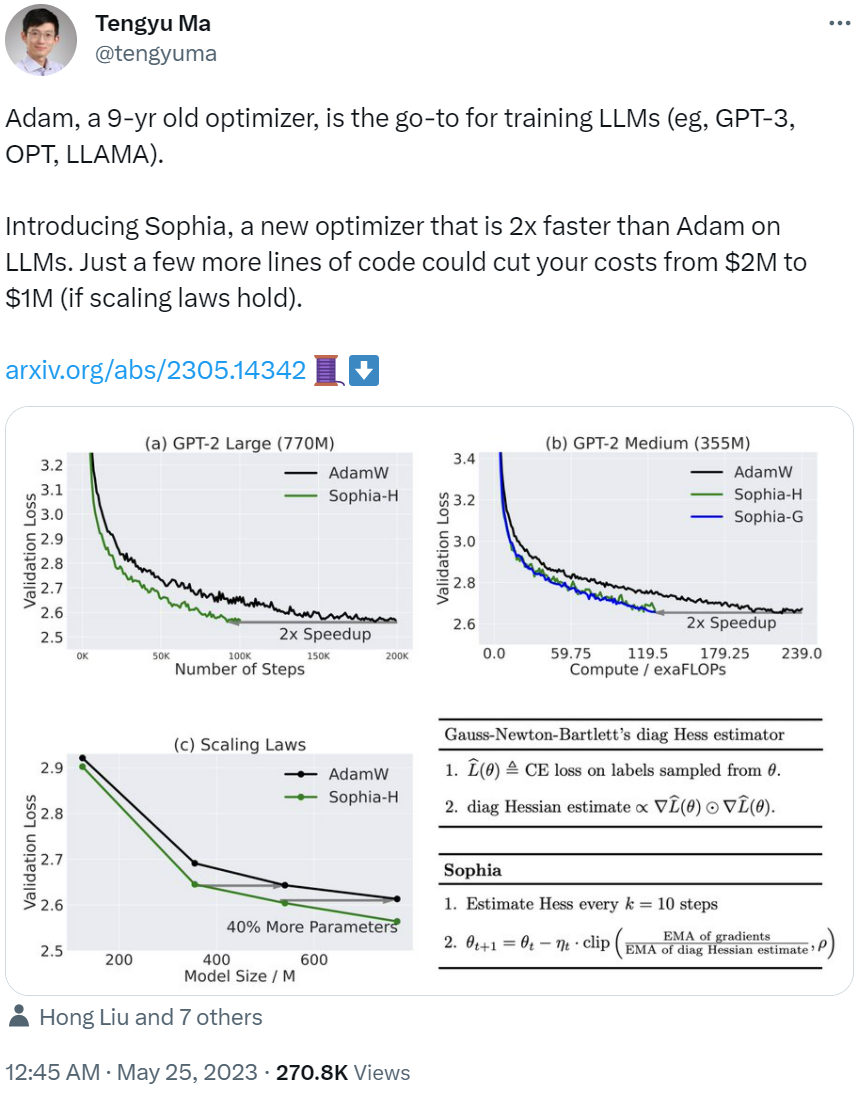
这项研究也得到了大家的认可。英伟达人工智能科学家 Jim Fan 表示:「多年来,有无数论文推翻了 Adam 优化器,不知道 Sophia 会不会是保留到最后的那个,这是一个可扩展的二阶优化器, 其伪代码只有 13 行,在 GPT-2 (预训练)上比 Adam 快了 2 倍,我很想试试这个优化器!」

论文作者之一、斯坦福大学助理教授马腾宇表示:「(从发布之初,)Adam 可以说是一个 9 岁的优化器,是训练 LLM 的首选,如 GPT-3、OPT、 LLAMA 等。而我们的新研究 Sophia 是一个崭新的优化器,在 LLM 上比 Adam 快了 2 倍。只需要你多写几行代码,你的成本就能从 200 万美元降至 100 万美元(如果扩展定律成立的话)。」
下面我们看看该优化器具体是如何实现的。
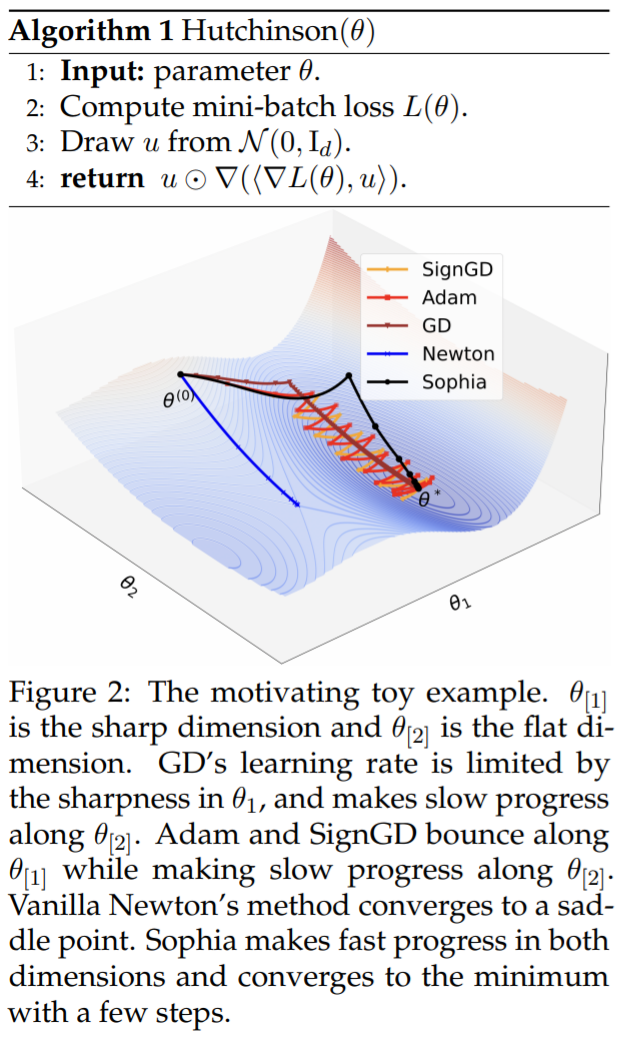
至于该研究的动机,作者表示 Adam 对于异构曲率(heterogeneous curvatures)的适应性不足。另一方面,vanilla Newton 方法在凸函数中具有最优的 pre-conditioner,但对于负曲率和 Hessian 的快速变化容易受到影响。基于这些见解,该研究设计了一种新的优化器 Sophia,它比 Adam 更适应异构曲率,比 Newton 方法更能抵抗非凸性和 Hessian 的快速变化,并且还使用了成本较低的 pre-conditioner。
方法理论方面,在时间步长 t 上,该研究用 θ_t 表示参数。在每个 step 上,该研究从数据分布中采样一个小批次,计算小批次损失,并用 L_t (θ_t) 表示。g_t 表示 L_t (θ_t) 的梯度,即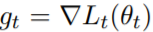 。设 m_t 为 EMA( exponential moving average )的梯度,则更新的分子为 m_t ← β_1m_t−1 + (1 − β_1) g_t 。
。设 m_t 为 EMA( exponential moving average )的梯度,则更新的分子为 m_t ← β_1m_t−1 + (1 − β_1) g_t 。
Sophia 使用基于对角 Hessian 的 pre-conditioner,根据参数维度的曲率直接调整更新的大小。为了减少开销,该研究仅在每 k 个step内(现实中 k = 10)估计一次 Hessian。在时间步 t 上,估计器返回小批次损失的 Hessian 对角线的估计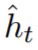 。每 k 个step更新一次 EMA,得到对角 Hessian 估计的以下更新规则:
。每 k 个step更新一次 EMA,得到对角 Hessian 估计的以下更新规则:
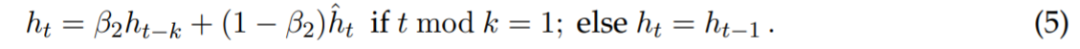
该研究只考虑对角 Hessian 的正项,并在更新中引入按坐标裁剪,更新规则改写为:
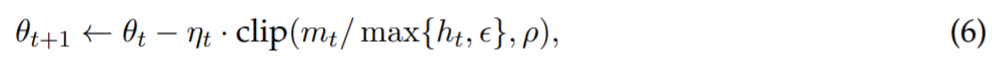
对角 Hessian 估计器
该研究引入了两个对角 Hessian 估计器,它们的内存和运行时间成本都与计算梯度相似。估计器分别为 Hutchinson 无偏估计器以及 GNB( Gauss-Newton-Bartlett ) 估计器。伪代码如下所示:

研究将使用 Hutchinson 估计器和 GNB 估计器的算法分别称为 Sophia-H 和 SophiaG。本文用 GPT-2 评估了 Sophia 的自回归语言建模,模型尺寸从 125M 到 770M 不等。结果表明,Sophia 在 step、总计算量和所有模型大小的 wall-clock 时间方面比 AdamW 和 Lion 快 2 倍。此外,扩展定律更有利于 Sophia 而不是 AdamW。
实验语言建模设置
该实验在 OpenWebText 上训练自回归模型。遵循 GPT-2 的标准协议,将上下文长度设置为 1024。使用只有解码器的 Transformer,模型参数量分别为 125M (小型)、355M (中型) 和 770M (大型)。
基线:研究主要比较 Sophia 和 Adam。Adam 采用解耦权重衰减 (AdamW),这是语言建模任务中主要使用的优化器,而 Lion 是通过符号搜索发现的一阶自适应优化器。所有优化器都进行了很好的调整。权重衰减被设置为 0.1,β_1 = 0.9, β_2 = 0.95。对于 Lion,使用 β_1 = 0.95 和 β_2 = 0.98。125M 和 355M 模型是在 10 个 A5000 GPU 上训练的,而 770M 模型是在 8 个 A100 GPU 上训练的。
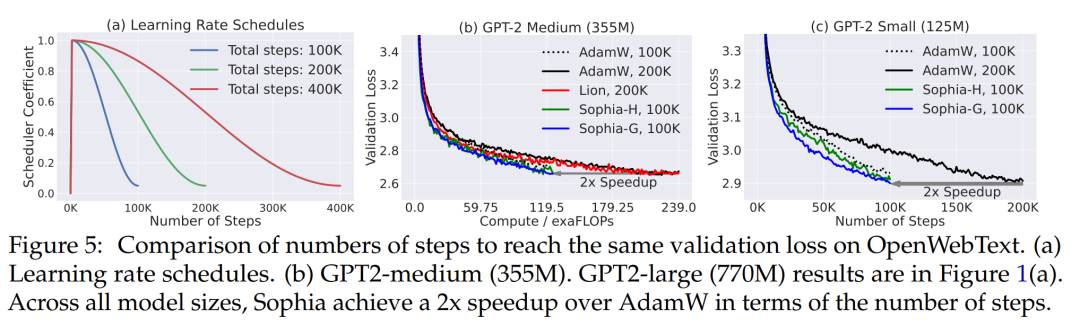
评估:研究人员使用每个优化器对模型进行 100K、200K 或 400K 个step的预训练评估,以比较速度。值得注意的是,与标准一样,LR 调度取决于预先指定的总目标step 数,如图 5 (a) 所示。这使得同一优化器的损失曲线在不同的 step 数下是不同的,因为总 step 数较少的 LR 调度会更早地衰减 LR。本文主要评估了这些模型在 OpenWebText 上的 log 困惑度,并绘制了损失曲线。此外,该研究还报告了 SuperGLUE 上的上下文学习结果,然后对 5 个提示的结果取平均值。
实验结果
图 4 展示了相同 step 数 (100K) 下 OpenWebText 上的验证损失曲线 (token 级 log 困惑度)。与 AdamW 和 Lion 方法相比,本文所提出来的方法获得了更好的验证损失。随着模型大小的增加,Sophia 和基线之间的差距也变得更大。Sophia-H 和 Sophia-G 在 355M 模型上的验证损失都小 0.04 (图 4 (b))。
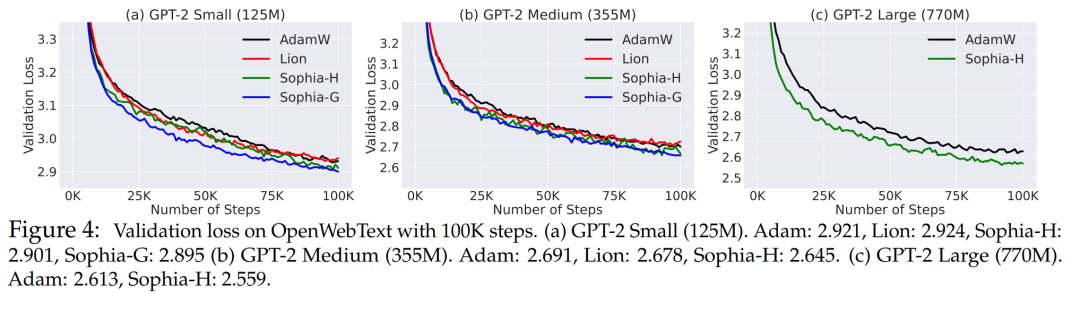
同样 100K step,Sophia-H 在 770M 模型上的验证损失小了 0.05 (图 4,(c))。可以看出,这是个明显的改进,因为根据该机制中的扩展定律和图 5 中的结果,损失 0.05 的改进相当于实现相同验证损失的 step 数或总计算量的改进的双倍。
Sophia 在 step 数、总计算时间和 wall-clock 时间方面快了两倍。Sophia 对验证损失的改进在于减少 step 数或总计算量。在图 1 (a) 和 (b) 和图 5 中,通过比较达到相同验证损失水平所需的 step 数或总计算量来评估优化器。从图 1 (a) 和 (b) 中可以看出,与 AdamW 和 Lion 相比,Sophia-H 和 Sophia-G 在不同的模型尺寸下实现了 2 倍的加速。
扩展定律更有利于 Sophia-H 而不是 AdamW。在图 1 (c) 中,该研究绘制了预训练 100K step 的不同大小模型的验证损失。Sophia 和 AdamW 之间的差距随着模型的扩大而增大。此外,Sophia-H 训练的 540M 模型比 AdamW 训练的 770M 模型的损失更小。Sophia-H 训练的 355M 模型与 AdamW 训练的 540M 模型的损失相当。
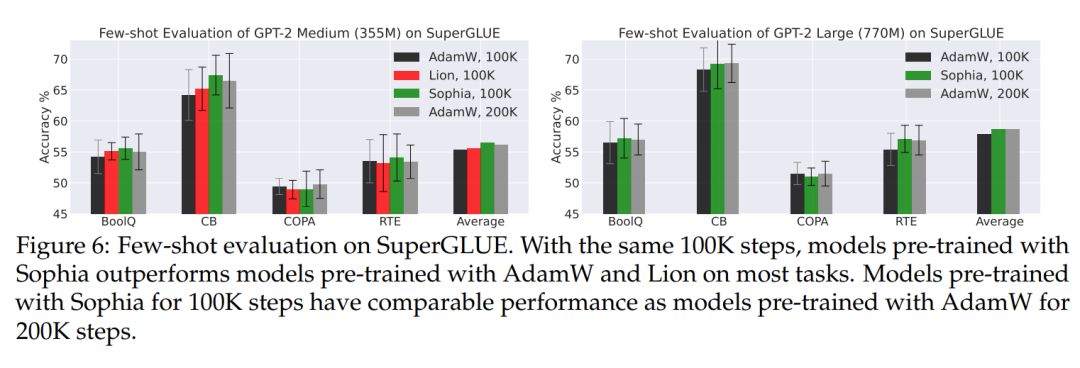
评估下游任务的小样本 (SuperGLUE)。如图 6 所示,验证损失的改善也使得下游任务准确率的提高。在预训练 step 数相同的情况下,使用 Sophia 预训练的 GPT-2 medium 和 GPT-2 large 在大多数子任务上具有更好的少样本准确率。此外,用 Sophia-H 预训练的模型与用 AdamW 预训练的模型具有相当的小样本准确率。
分析
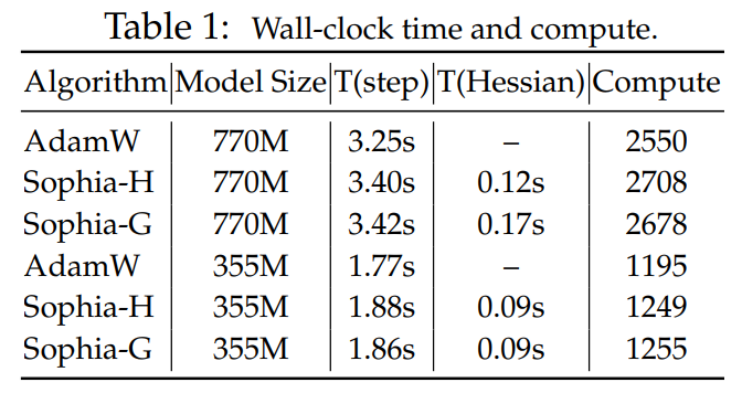
比较 wall-clock 时间与计算量。表 1 比较了每一个 step 的总计算量 (TFLOPs) 和 A100 GPU 上的 wall-clock 时间。本文报告了每个 step 的平均时间,Hessian 计算花费的时间的总计算。较小的批量大小,即每 10 个 step 以计算对角 Hessian 估计,Hessian 计算占总计算量的 6%,与 AdamW 相比,整体 wall-clock 时间开销小于 5%。在内存使用方面,优化器 m 和 h 两个状态,这导致了与 AdamW 相同的内存开销。
在 30M 模型上,执行网格搜索来测试 Sophia-H 对超参数的敏感性 (图 7 (c))。所有组合的性能相近,但 β_2 = 0.99 和 ρ = 0.1 的性能最好。此外,这种超参数选择可以跨模型大小迁移。对于 125M、355M 和 770M 的所有实验,都使用了 30M 模型上搜索超参数 ρ = 0.01, β_2 = 0.99。
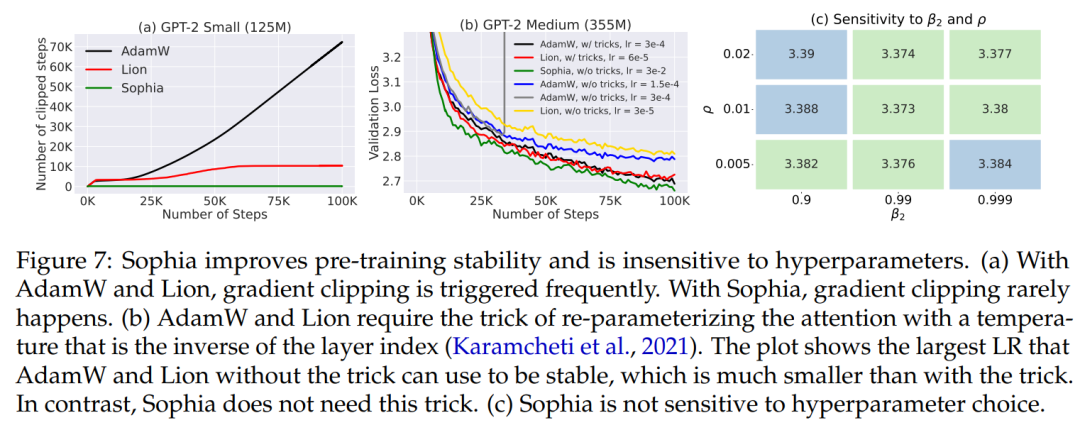
训练稳定性。与 AdamW 和 Lion 相比,Sophia-H 在预训练中具有更好的稳定性。梯度裁剪 (by norm) 是语言模型预训练中的一项重要技术。在实践中,梯度裁剪触发的频率与训练的稳定性有关 —— 如果梯度被频繁裁剪,迭代可能处于非常不稳定的状态。图 7 (a) 比较了 GPT-2 (125M) 触发梯度裁剪的 step 比例。尽管所有方法都使用相同的裁剪阈值 1.0,但 Sophia-H 很少触发梯度裁剪,而 AdamW 和 Lion 在超过 10% 的 step 中触发梯度裁剪。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK