

Python_Selenium_Study | Charmersix's Blog
source link: https://charmersix.github.io/2023/03/08/Python_Selenium%E5%AD%A6%E4%B9%A0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在一切的开始,先感谢白月黑羽师傅
这是师傅的blog:https://www.byhy.net/
这是师傅的B站:https://space.bilibili.com/401981380
推荐大家去看白月黑羽师傅的原文和视频这篇只是个人笔记
selenium原理
selenium自动化程序+浏览器驱动(转发指令)控制浏览器
首先安装python, 这里不再赘述,然后安装selenium库
pip install selenium
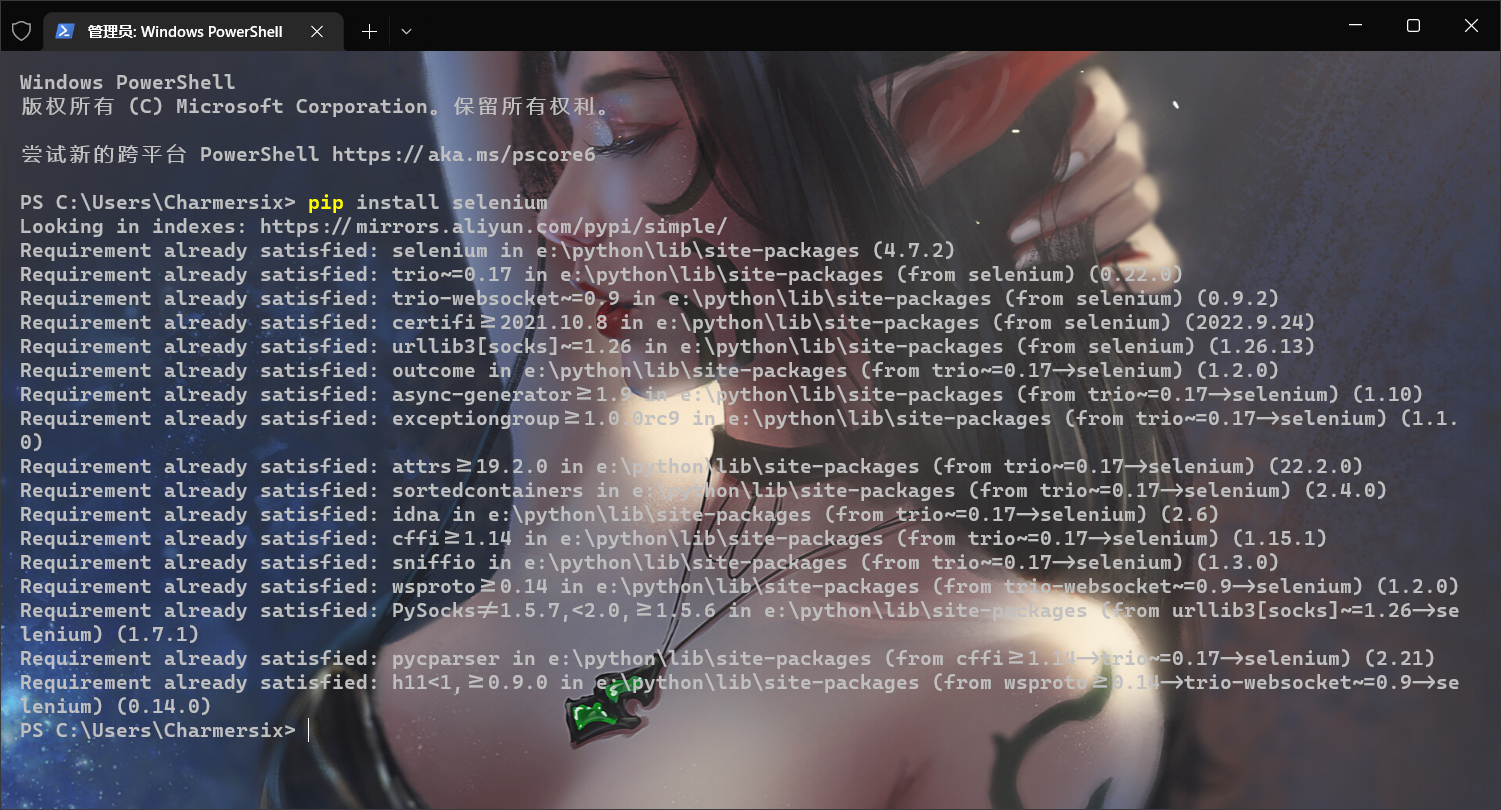
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome(service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://charmersix.icu')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
input()
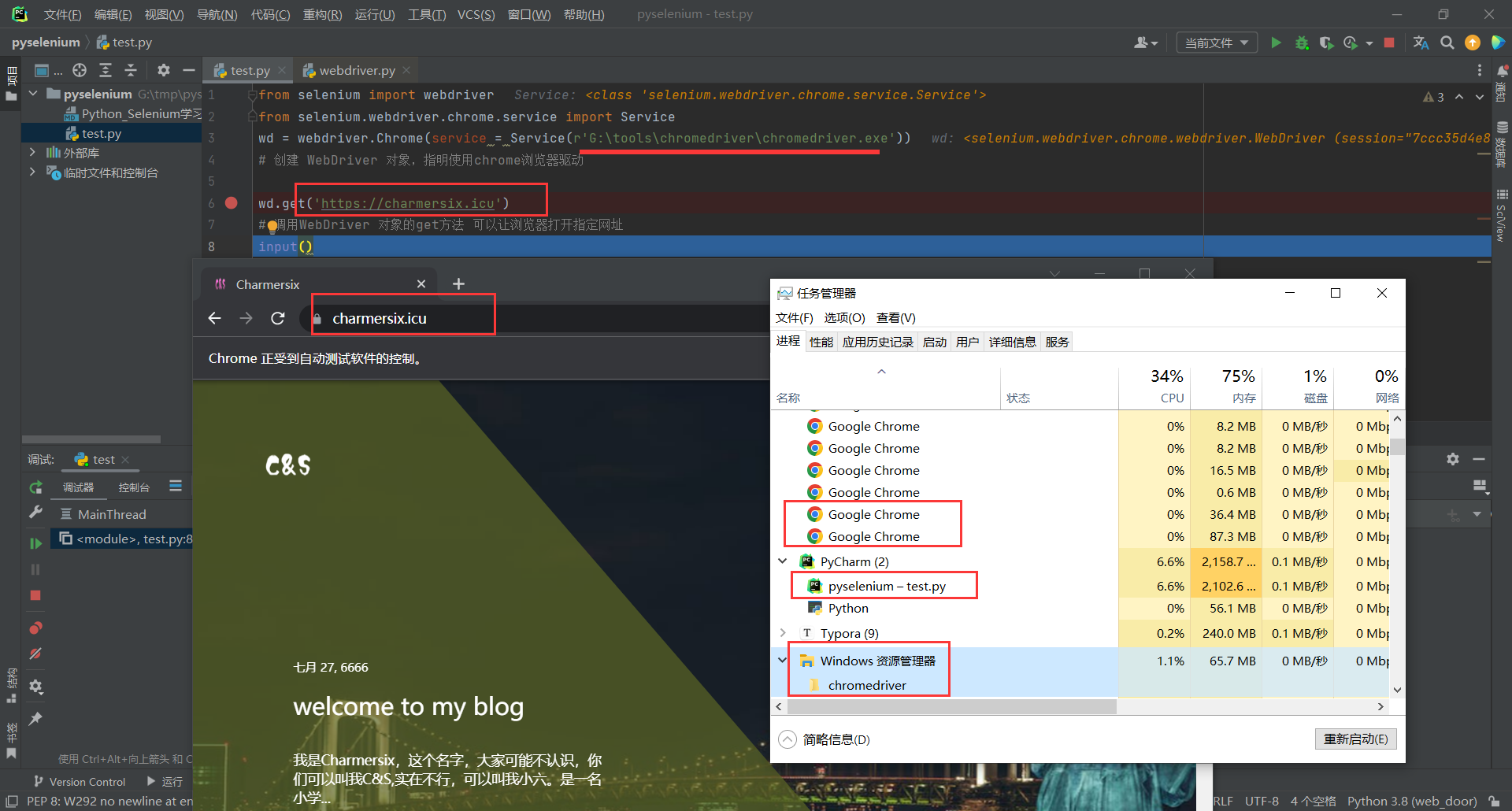
当然我们可以将chromedriver加一个环境变量,就可以不在代码里点明路径
like this
from selenium import webdriver
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://charmersix.icu')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
input()
选择元素的基本方法
可以通过元素的id选择,但是这个id必须是当前页面唯一的,如果不确定是否是唯一的,可以通过搜索功能试一下
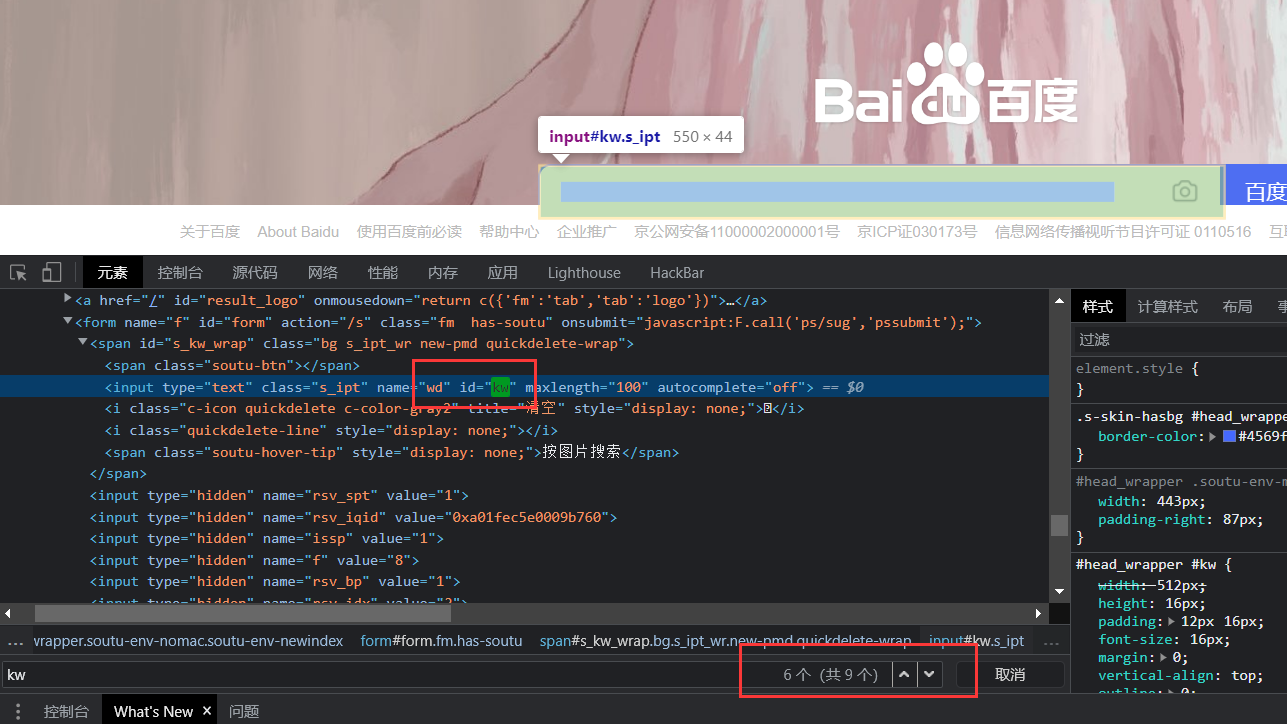
可以看一下这里虽然搜出来了九个,实际上id="kw"只有一个
我们就可以通过实例实现一下
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://baidu.com')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
element = wd.find_element(By.ID,'kw')
#根据id选择元素,返回的就是该元素对应的webelement对象
element.send_keys('Charmersix\n')
#在输入框中输入字符串,并且回车搜索
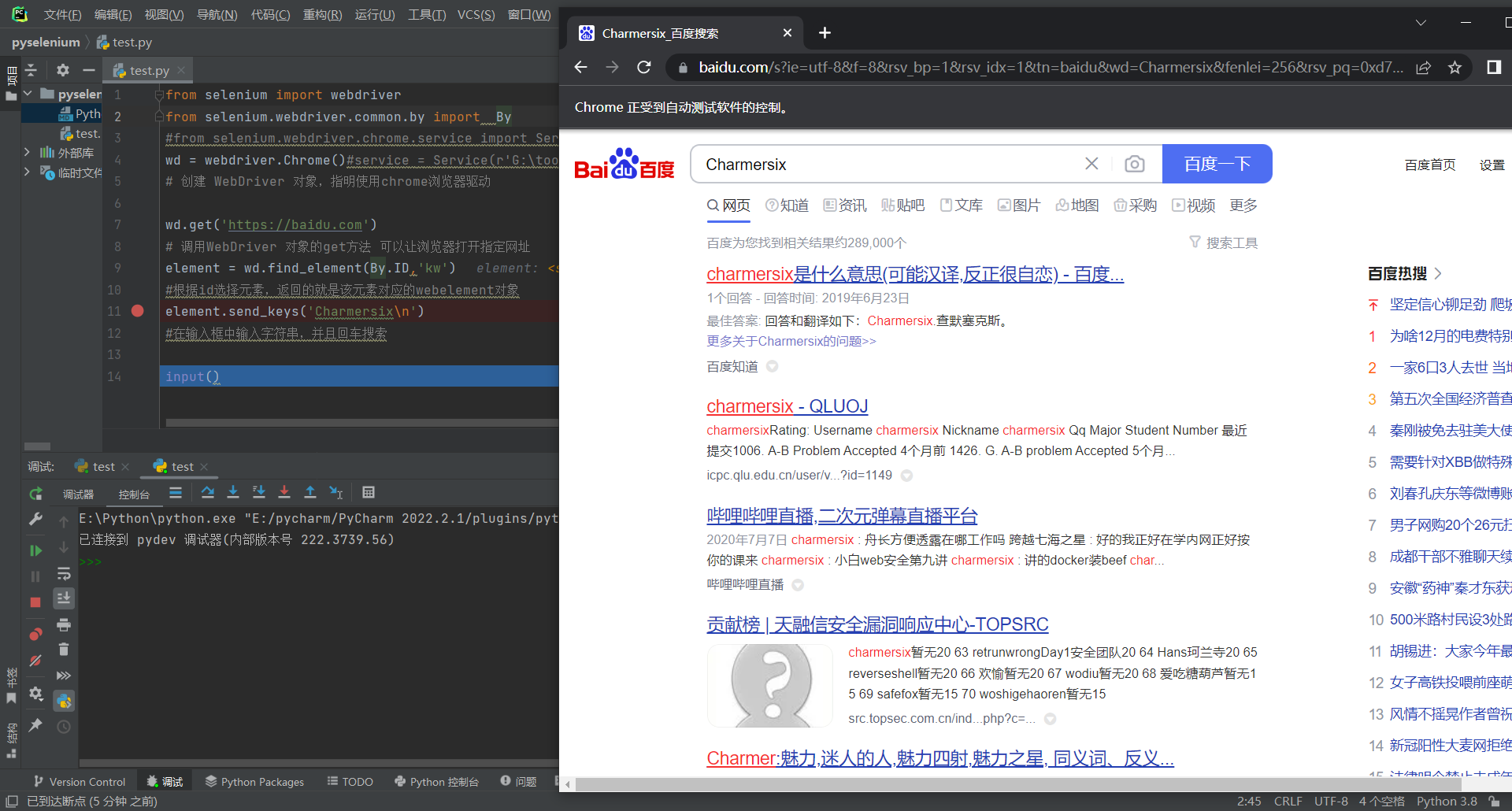
bing也是一样
上边栗子采用的回车搜索,如果我们回车无法搜索需要点击的话,我们可以用click方法,还是通过id筛选搜索元素去点击这个元素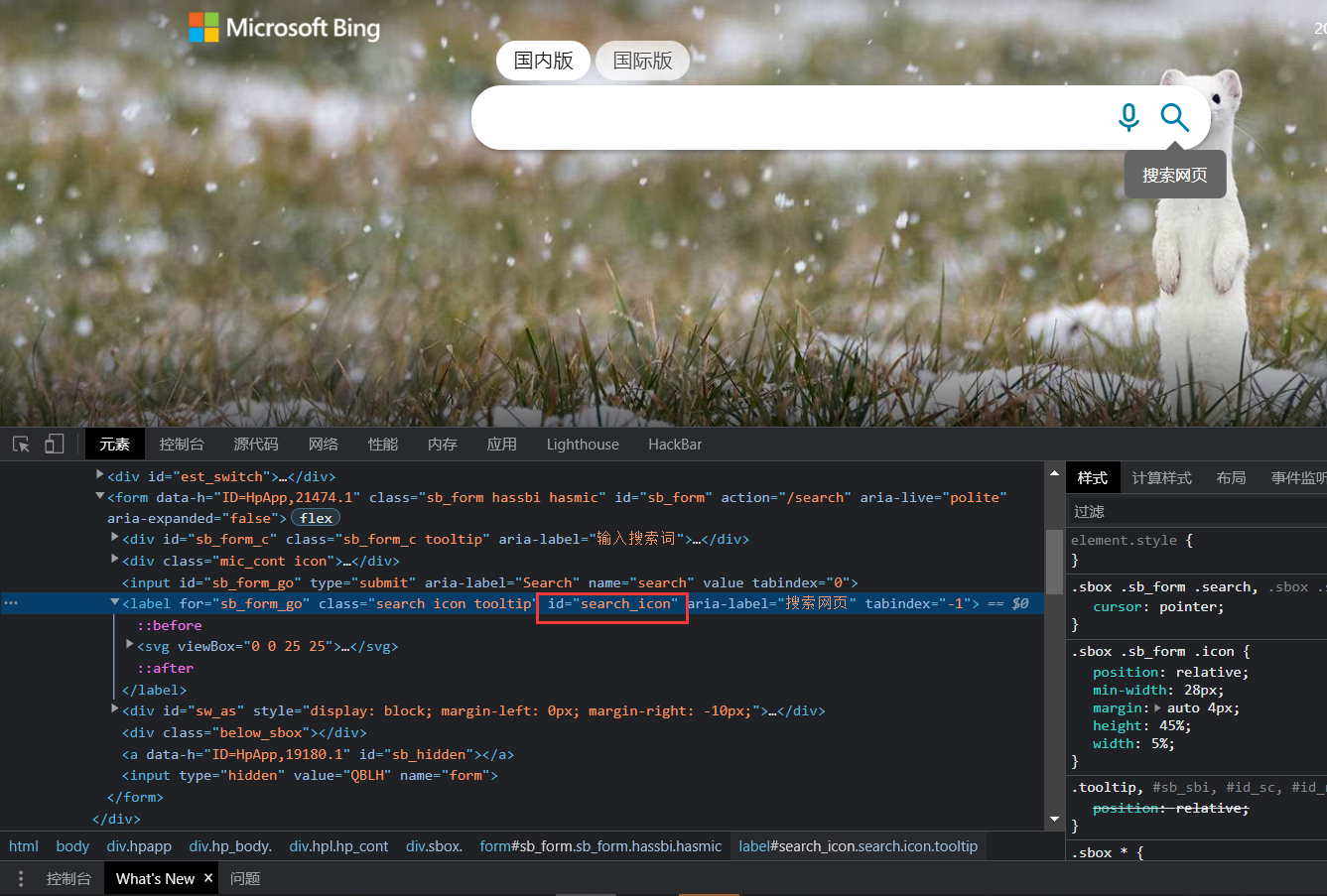
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cn.bing.com/')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
element = wd.find_element(By.ID,'sb_form_q')
#根据id选择元素,返回的就是该元素对应的webelement对象
element.send_keys('Charmersix')
#在输入框中输入字符串,并且回车搜索
search = wd.find_element(By.ID,'search_icon')
search.click()
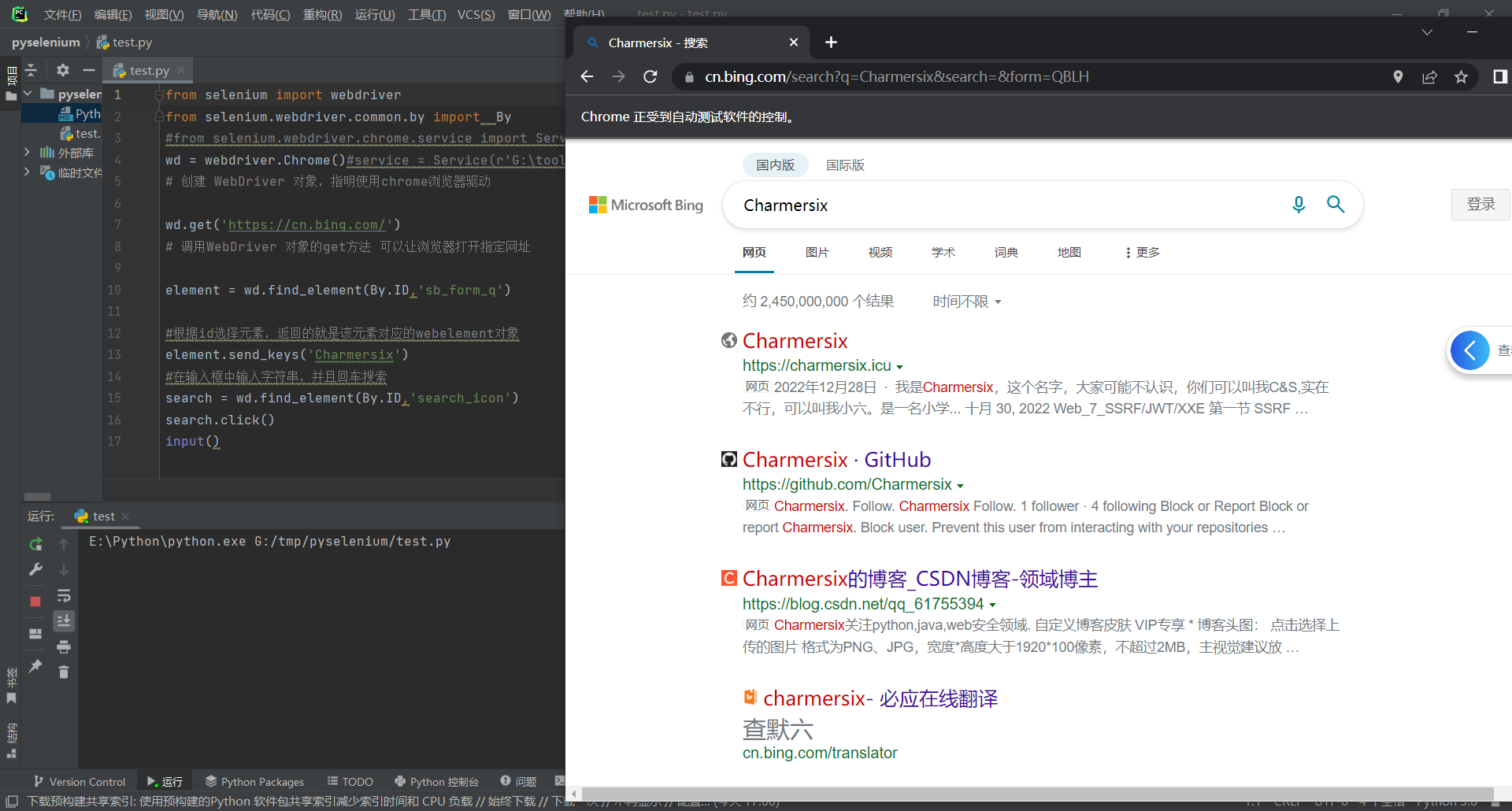
如果我们想要筛选的这个元素、标签里没有id,我们也是可以根据其他方法来选择的,比方说class属性或者是标签名
这里借用一下白月黑羽师傅的网站
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
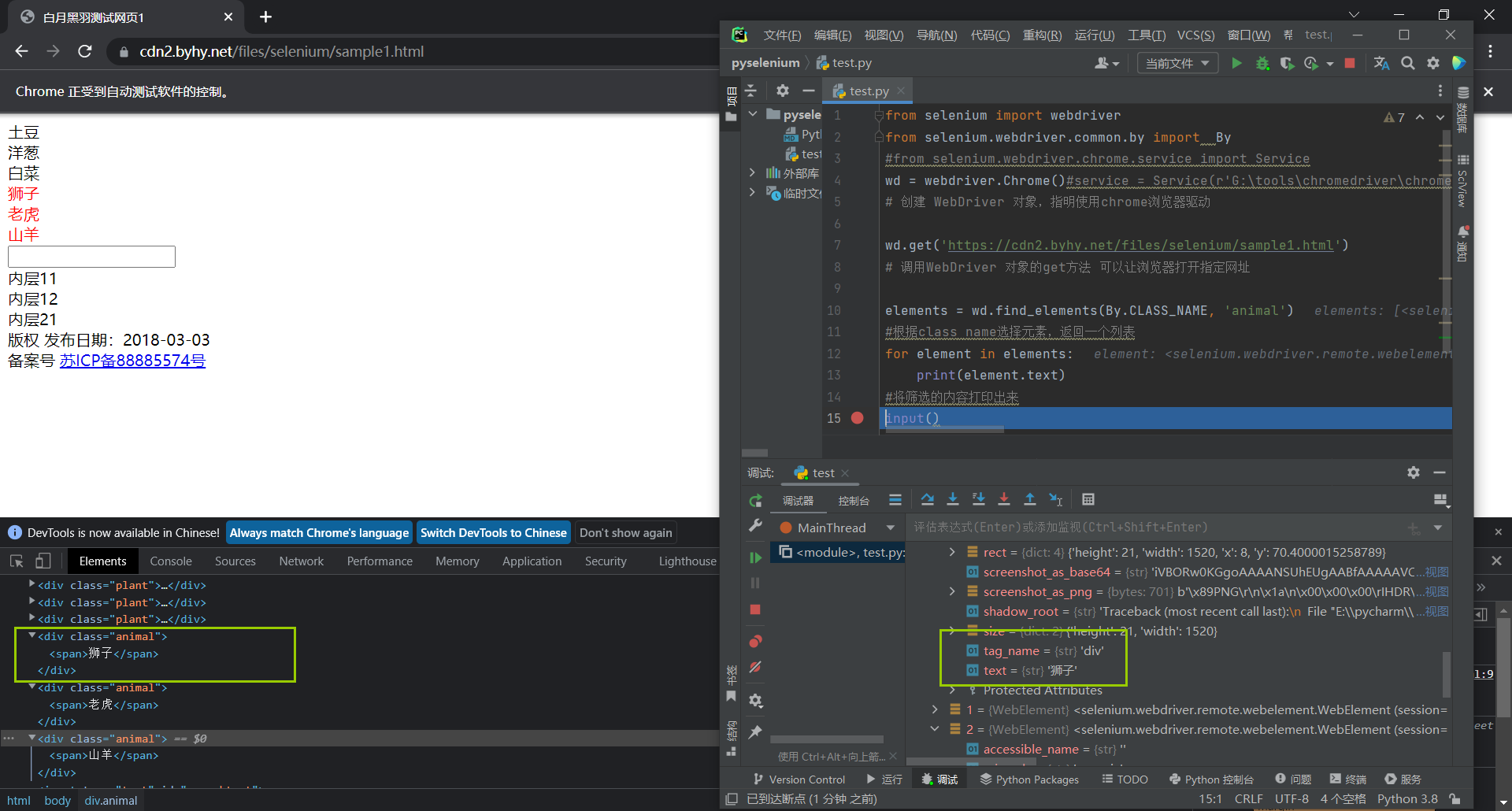
elements = wd.find_elements(By.CLASS_NAME, 'animal')
#这里换用了elements, 如果是element只能选择出第一个元素, 而elements可以将三个都选出来
#根据class name选择元素,返回一个列表
for element in elements:
print(element.text)
#将筛选的内容打印出来
根据标签名也是一样
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_elements(By.TAG_NAME, 'span')
#根据标签选择元素,返回一个列表
for element in elements:
print(element.text)
#将筛选的内容打印出来
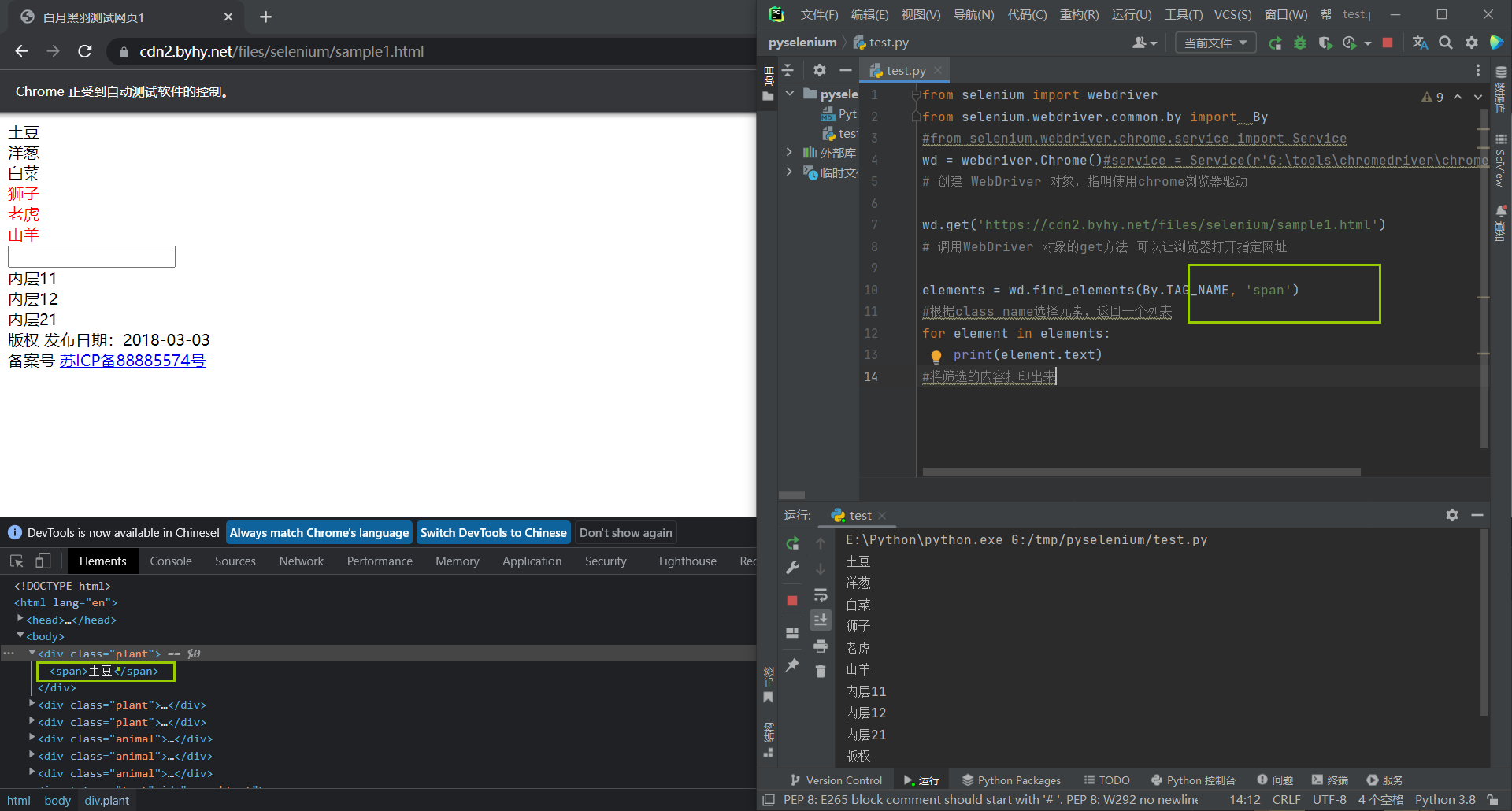
WebDriver对象选择元素的范围是整个web页面,而WebElement对象选择的范围是元素内部,简而言之就是我们可以通过套娃方法选择到更具体的、更精确的信息
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_element(By.ID, 'container')
#通过id选择特定元素
spans = elements.find_elements(By.TAG_NAME, 'span')
#根据标签选择元素,返回一个列表
for span in spans:
print(span.text)
#将筛选的内容打印出来
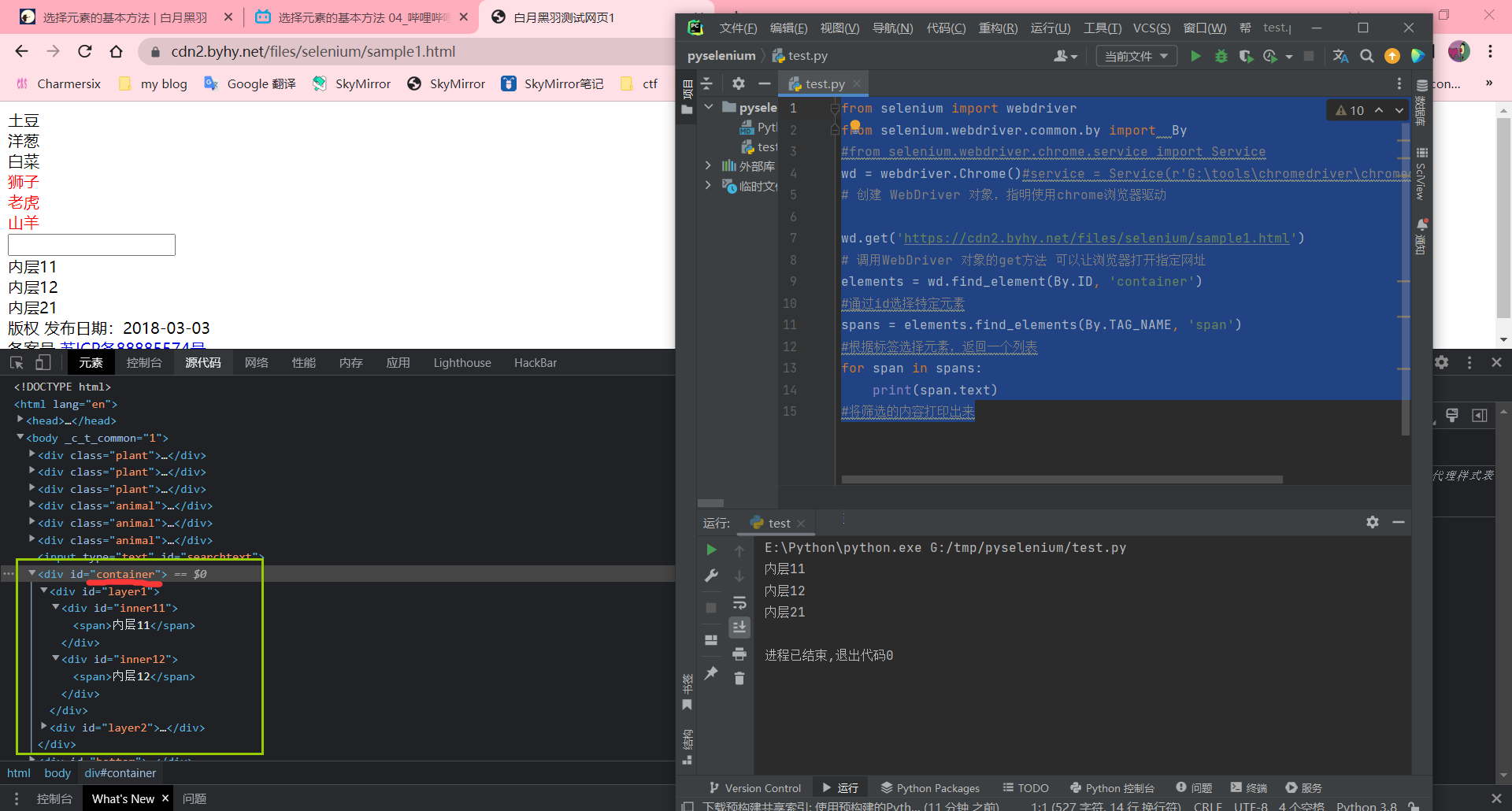
等待元素出现
这个模块主要是用于搜索功能后再查找提取内容利用sleep
例如,我这里要提取出我从bing中搜出的关于Charmersix的网站
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cn.bing.com/')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_element(By.ID, 'sb_form_q')
#通过id选择特定元素
elements.send_keys('Charmersix')
search = wd.find_element(By.ID, 'search_icon')
search.click()
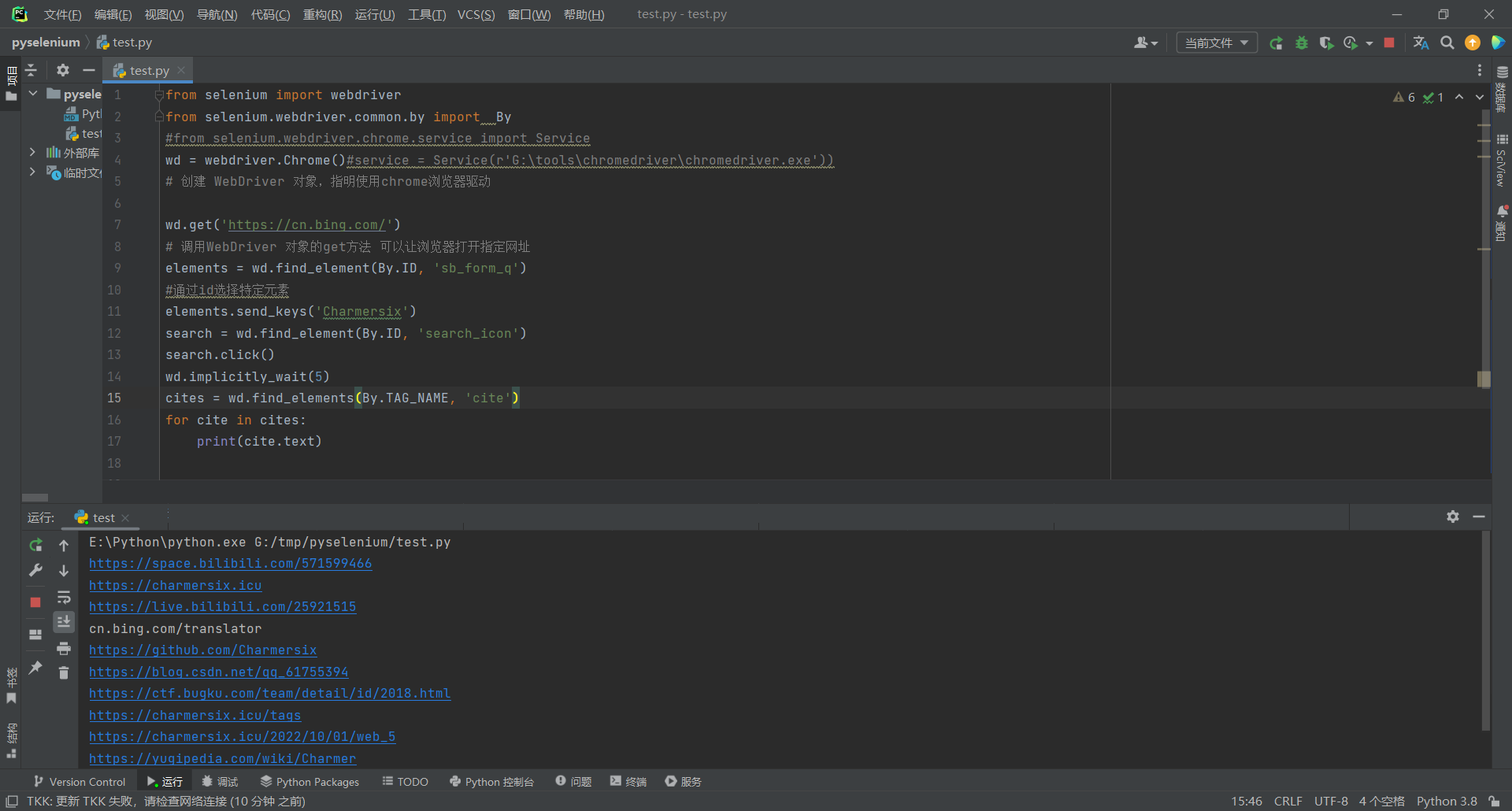
time.sleep(5)
#给网站一个反应的时间,然后继续提取想要的内容
cites = wd.find_elements(By.TAG_NAME, 'cite')
#根据标签选择元素,返回一个列表
for cite in cites:
print(cite.text)
#将筛选的内容打印出来
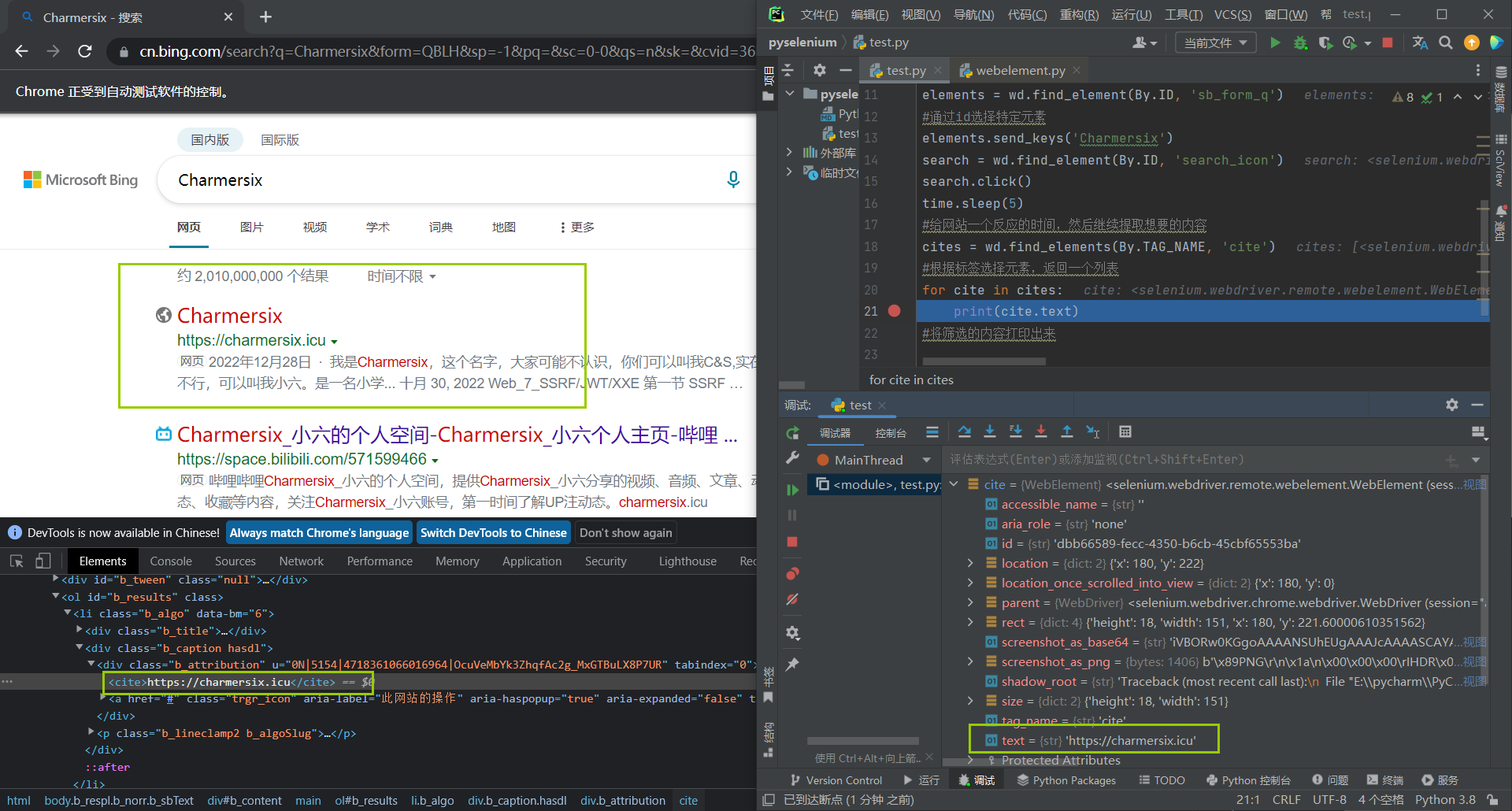
这里的sleep(5)比较长, 那么我们怎么确定具体的时间是多少, 睡多长时间最有效率呢, 我们可以使用selenium给我们提供的隐式等待也就是implicitly_wait()其原理是:当发现元素没有找到的时候,并不立即返回找不到的报错, 而是每隔半秒钟重新寻找, 在规定时间内直到找到该元素, 如果超出规定时间才会抛异常, ()填的数字就是我们所规定的最大等待时间.也可以用一串代码来解释这个implicitly_wait()
while True:
try:
cites = wd.find_elements(By.TAG_NAME, 'cite')
for cite in cites:
print(cite.text)
break
except:
time.sleep(0.5)
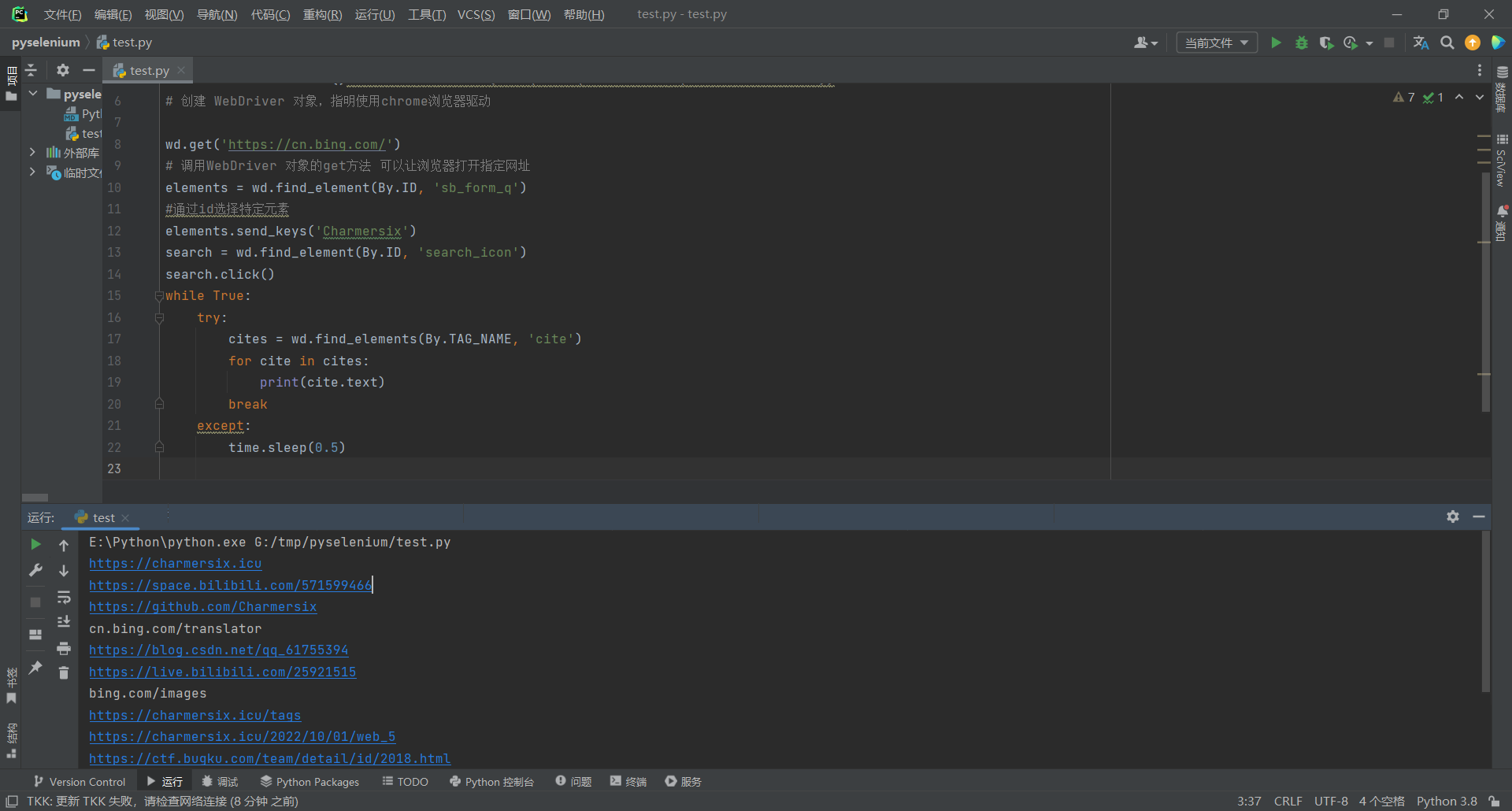
再来使用implicitly_wait()也可以达到同样的效果,但是代码会简化很多,这也就是python的强大之处
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cn.bing.com/')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_element(By.ID, 'sb_form_q')
#通过id选择特定元素
elements.send_keys('Charmersix')
search = wd.find_element(By.ID, 'search_icon')
search.click()
wd.implicitly_wait(5)
cites = wd.find_elements(By.TAG_NAME, 'cite')
for cite in cites:
print(cite.text)
点击元素前面已经讲过就是调用webelement对象的click方法
这里要补充的是, 当我们调用webelement对象的click方法去点击的元素的时候, 浏览器接收到自动化命令, 点击的是该元素的中心点位置
但是当一些按钮的有效点击区域不在中间的时候, 我们就需要重新定位到有效点击区域
前面也已经学过就是调用send_keys方法, 但是如果我们输入框中已经有内容了, 就需要先用一个clear方法, 将输入框中的内容清楚掉
我们试一下在原来的代码里加入两行
elements.clear()
elements.send_keys('SkyMirror')
我们会发现, 搜索框里的内容不再是Charmersix而是现在的SkyMirror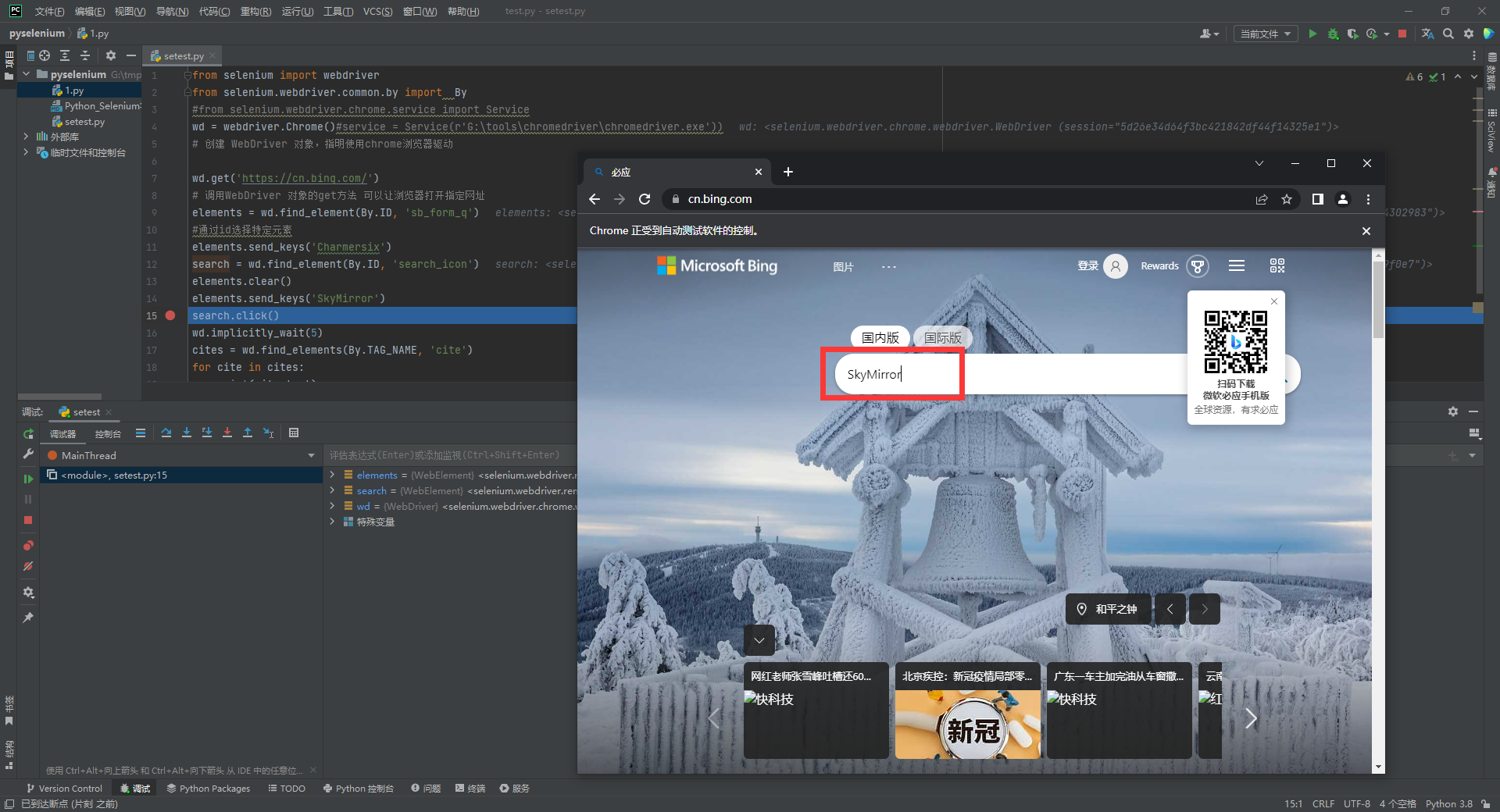
获取元素信息
获取元素属性
有一些关键信息可能不是文本形式, 有可能藏在元素的属性里, 比如说一些搜索框的提示语我们就可以使用get_attribute
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://charmersix.icu/search/')
elements = wd.find_element(By.TAG_NAME,'input')
text = elements.get_attribute('placeholder')
print(text)
像这样
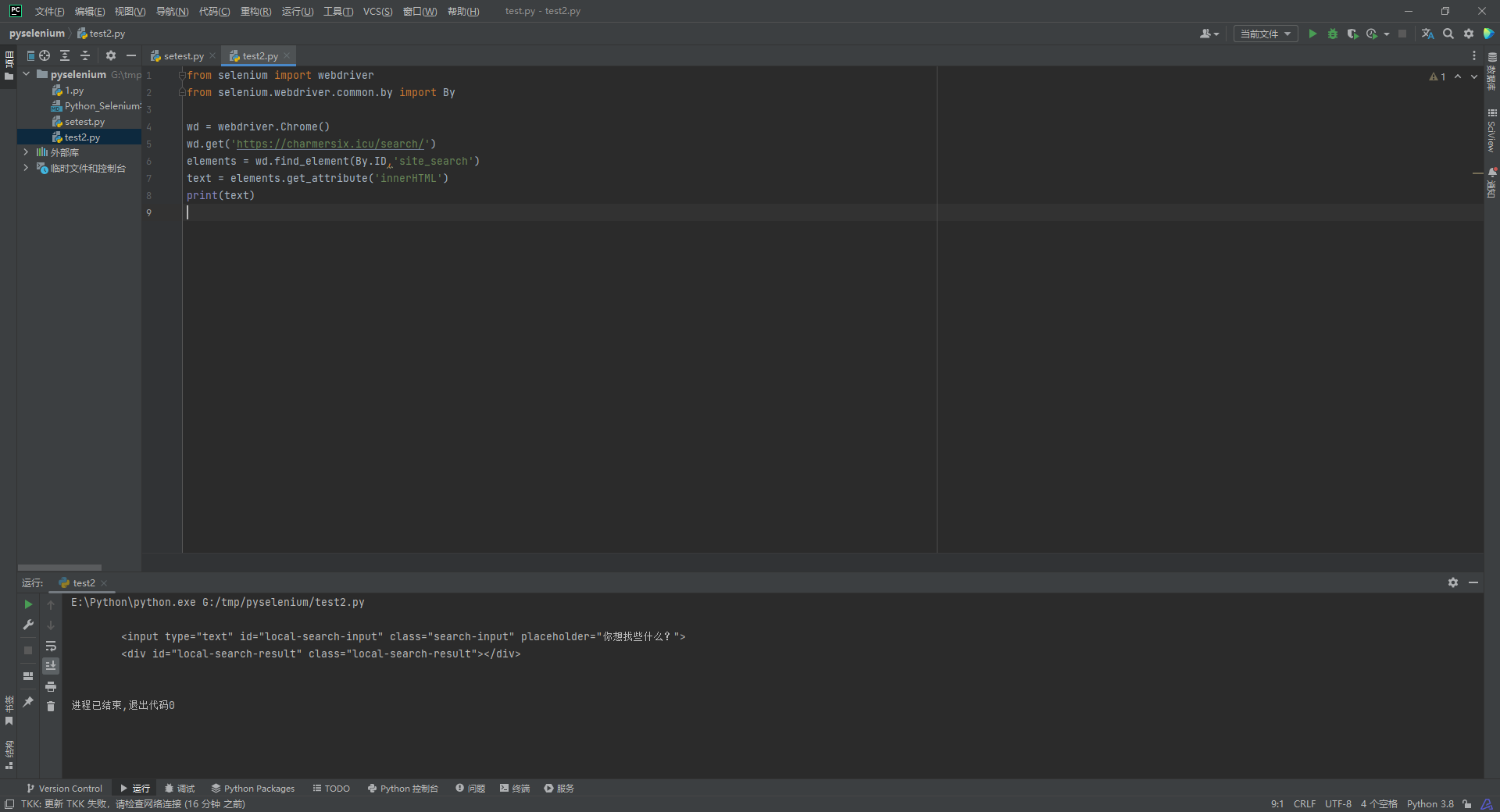
获取整个元素对应的HTML
假如我们要提取大段的HTML内容, 我们可以使用elements.get_attribute('innerHTML')获取整个元素的HTML内容和elements.get_attribute('outerHTML')获取某元素内部的HTML内容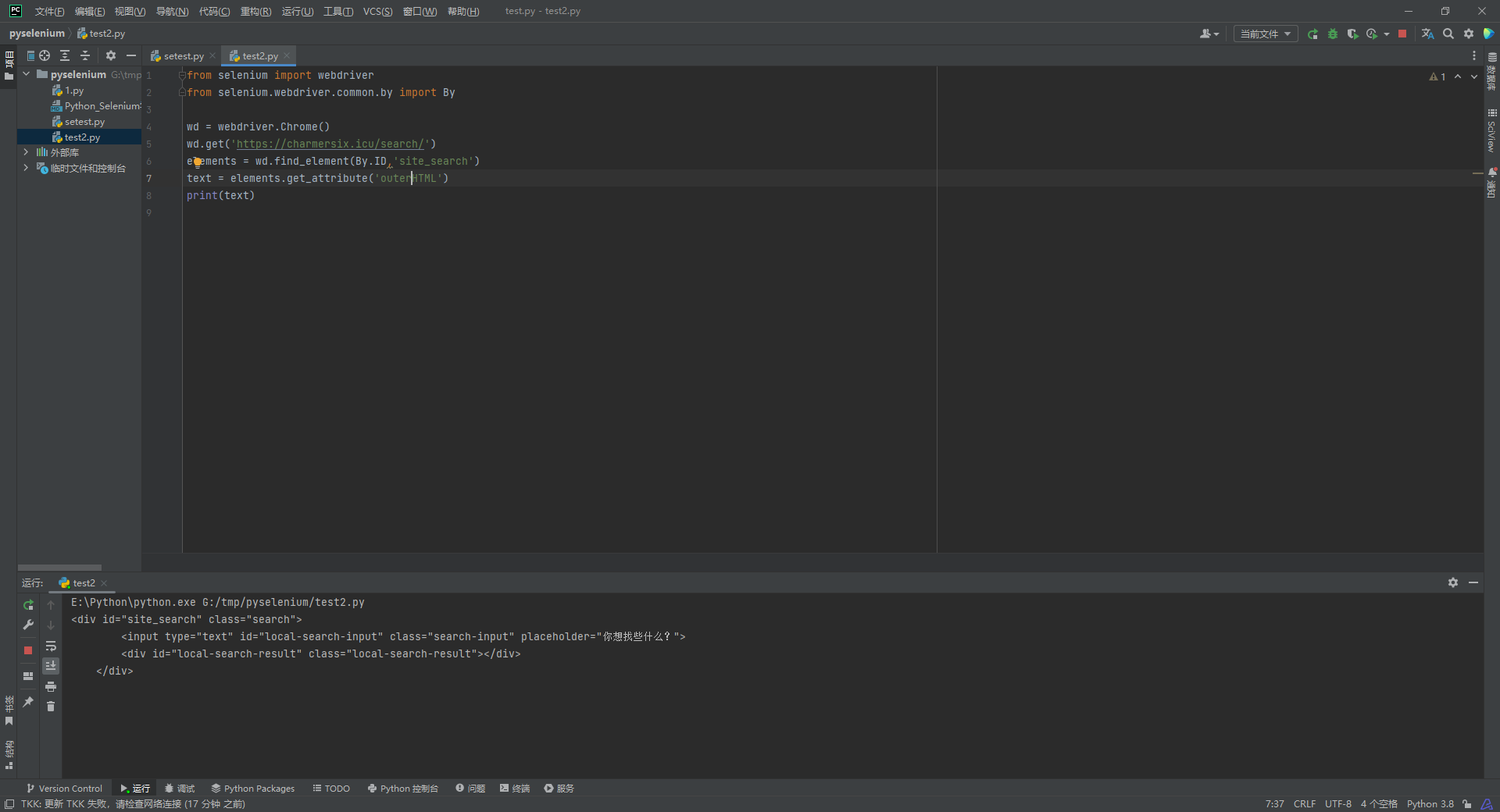
获取输入框里的文字
对于输入框里的文本内容,用text属性是不行的,这时候可以使用get_attribute('value')
比方说, 我们在上边代码里加入一行
print(elements.get_attribute('value'))
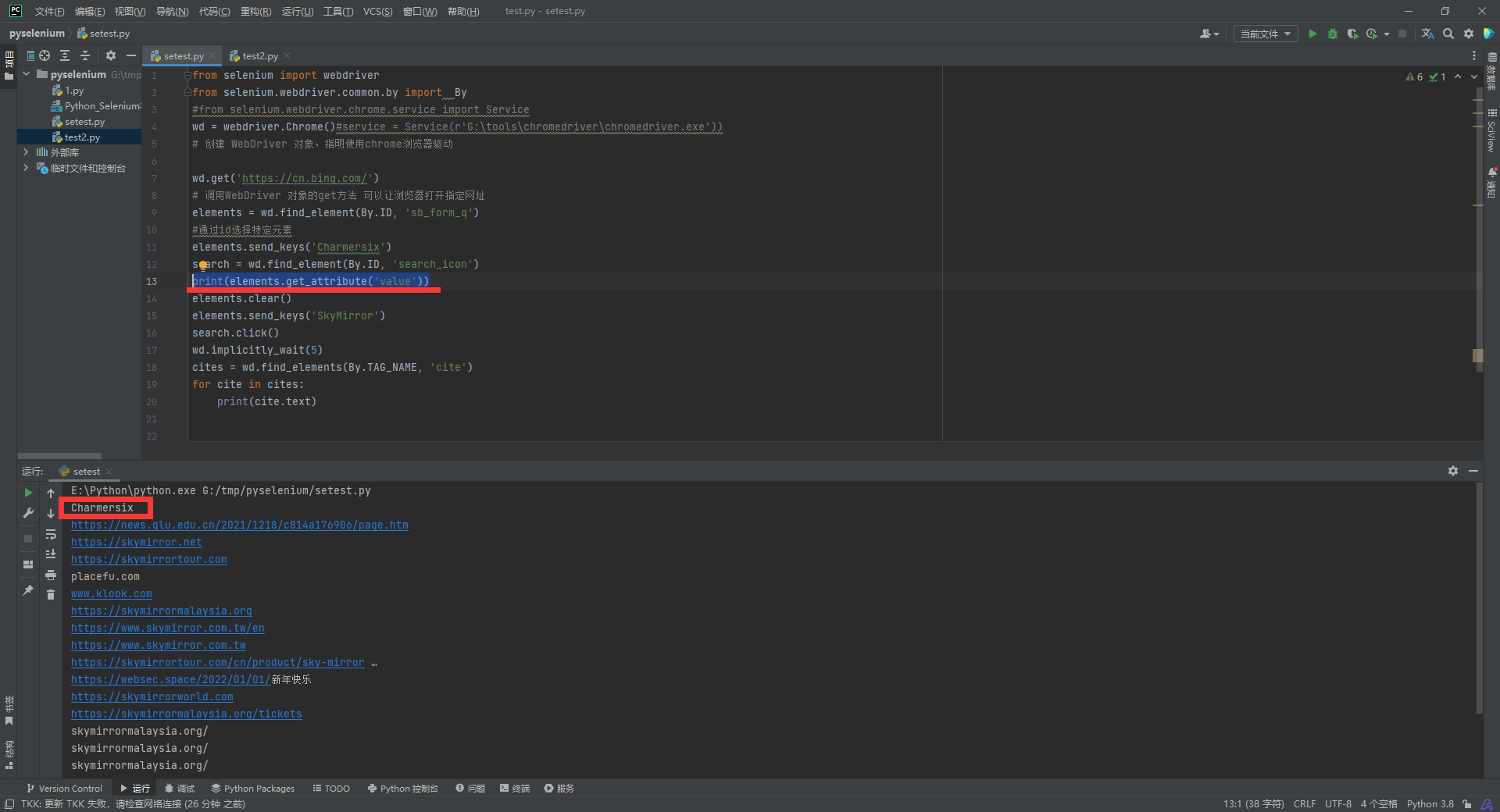
我们就能发现这里可以获取到我们输入的Charmersix内容
获取元素文本内容
通过webelement对象的text属性, 可以获取元素展示在界面上的文本内容, 但是有时候元素的文本内容没有显示在界面上或者没有完全展示在界面上. 这时候用text属性可能没办法正常获取文本内容, 出现这种问题尝试使用element.get_attribute('innerText')或者element.get_attribute('textContent')
使用 innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
如果您了解web前端开发,可以知晓一下:
get_attribute 调用本质上就是调用 HTMLElement 对像的属性
element.get_attribute(‘value’) 等价于js里面的 element.value
element.get_attribute(‘innerText’) 等价于js里面的 element.innerText
css表达式
CSS 选择器
在 CSS 中,选择器是选取需设置样式的元素的模式。
请使用我们的 CSS 选择器测试工具,它可为您演示不同的选择器。
| 选择器 | 例子 | 例子描述 |
|---|---|---|
| .class | .intro | 选择 class=”intro” 的所有元素。 |
| .class1.class2 | .name1.name2 | 选择 class 属性中同时有 name1 和 name2 的所有元素。 |
| .class1 .class2 | .name1 .name2 | 选择作为类名 name1 元素后代的所有类名 name2 元素。 |
| #id | #firstname | 选择 id=”firstname” 的元素。 |
| * | * | 选择所有元素。 |
| element | p | 选择所有 <p> 元素。 |
| element.class | p.intro | 选择 class=”intro” 的所有 <p> 元素。 |
| element,element | div, p | 选择所有 <div> 元素和所有 <p> 元素。 |
| element element | div p | 选择 <div> 元素内的所有 <p> 元素。 |
| element>element | div > p | 选择父元素是 <div> 的所有 <p> 元素。 |
| element+element | div + p | 选择紧跟 <div> 元素的首个 <p> 元素。 |
| element1~element2 | p ~ ul | 选择前面有 <p> 元素的每个 <ul> 元素。 |
| [attribute] | [target] | 选择带有 target 属性的所有元素。 |
| [attribute=value] | [target=_blank] | 选择带有 target=”_blank” 属性的所有元素。 |
| [attribute~=value] | [title~=flower] | 选择 title 属性包含单词 “flower” 的所有元素。 |
| [attribute|=value] | [lang|=en] | 选择 lang 属性值以 “en” 开头的所有元素。 |
| [attribute^=value] | a[href^=”https”] | 选择其 src 属性值以 “https” 开头的每个 <a> 元素。 |
| [attribute$=value] | a[href$=”.pdf”] | 选择其 src 属性以 “.pdf” 结尾的所有 <a> 元素。 |
| [attribute*=value] | a[href*=”w3schools”] | 选择其 href 属性值中包含 “abc” 子串的每个 <a> 元素。 |
| :active | a:active | 选择活动链接。 |
| ::after | p::after | 在每个 <p> 的内容之后插入内容。 |
| ::before | p::before | 在每个 <p> 的内容之前插入内容。 |
| :checked | input:checked | 选择每个被选中的 <input> 元素。 |
| :default | input:default | 选择默认的 <input> 元素。 |
| :disabled | input:disabled | 选择每个被禁用的 <input> 元素。 |
| :empty | p:empty | 选择没有子元素的每个 <p> 元素(包括文本节点)。 |
| :enabled | input:enabled | 选择每个启用的 <input> 元素。 |
| :first-child | p:first-child | 选择属于父元素的第一个子元素的每个 <p> 元素。 |
| ::first-letter | p::first-letter | 选择每个 <p> 元素的首字母。 |
| ::first-line | p::first-line | 选择每个 <p> 元素的首行。 |
| :first-of-type | p:first-of-type | 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 |
| :focus | input:focus | 选择获得焦点的 input 元素。 |
| :fullscreen | :fullscreen | 选择处于全屏模式的元素。 |
| :hover | a:hover | 选择鼠标指针位于其上的链接。 |
| :in-range | input:in-range | 选择其值在指定范围内的 input 元素。 |
| :indeterminate | input:indeterminate | 选择处于不确定状态的 input 元素。 |
| :invalid | input:invalid | 选择具有无效值的所有 input 元素。 |
| :lang(language) | p:lang(it) | 选择 lang 属性等于 “it”(意大利)的每个 <p> 元素。 |
| :last-child | p:last-child | 选择属于其父元素最后一个子元素每个 <p> 元素。 |
| :last-of-type | p:last-of-type | 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。 |
| :link | a:link | 选择所有未访问过的链接。 |
| :not(selector) | :not(p) | 选择非 <p> 元素的每个元素。 |
| :nth-child(n) | p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 <p> 元素。 |
| :nth-last-child(n) | p:nth-last-child(2) | 同上,从最后一个子元素开始计数。 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 同上,但是从最后一个子元素开始计数。 |
| :only-of-type | p:only-of-type | 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。 |
| :only-child | p:only-child | 选择属于其父元素的唯一子元素的每个 <p> 元素。 |
| :optional | input:optional | 选择不带 “required” 属性的 input 元素。 |
| :out-of-range | input:out-of-range | 选择值超出指定范围的 input 元素。 |
| ::placeholder | input::placeholder | 选择已规定 “placeholder” 属性的 input 元素。 |
| :read-only | input:read-only | 选择已规定 “readonly” 属性的 input 元素。 |
| :read-write | input:read-write | 选择未规定 “readonly” 属性的 input 元素。 |
| :required | input:required | 选择已规定 “required” 属性的 input 元素。 |
| :root | :root | 选择文档的根元素。 |
| ::selection | ::selection | 选择用户已选取的元素部分。 |
| :target | #news:target | 选择当前活动的 #news 元素。 |
| :valid | input:valid | 选择带有有效值的所有 input 元素。 |
| :visited | a:visited | 选择所有已访问的链接。 |
CSS_SELECTOR
HTML中经常要为某些元素指定显示效果,比如 前景文字颜色是红色, 背景颜色是黑色, 字体是微软雅黑等。
那么CSS必须告诉浏览器:要 选择哪些元素 , 来使用这样的显示风格。例如这个白月黑羽的测试页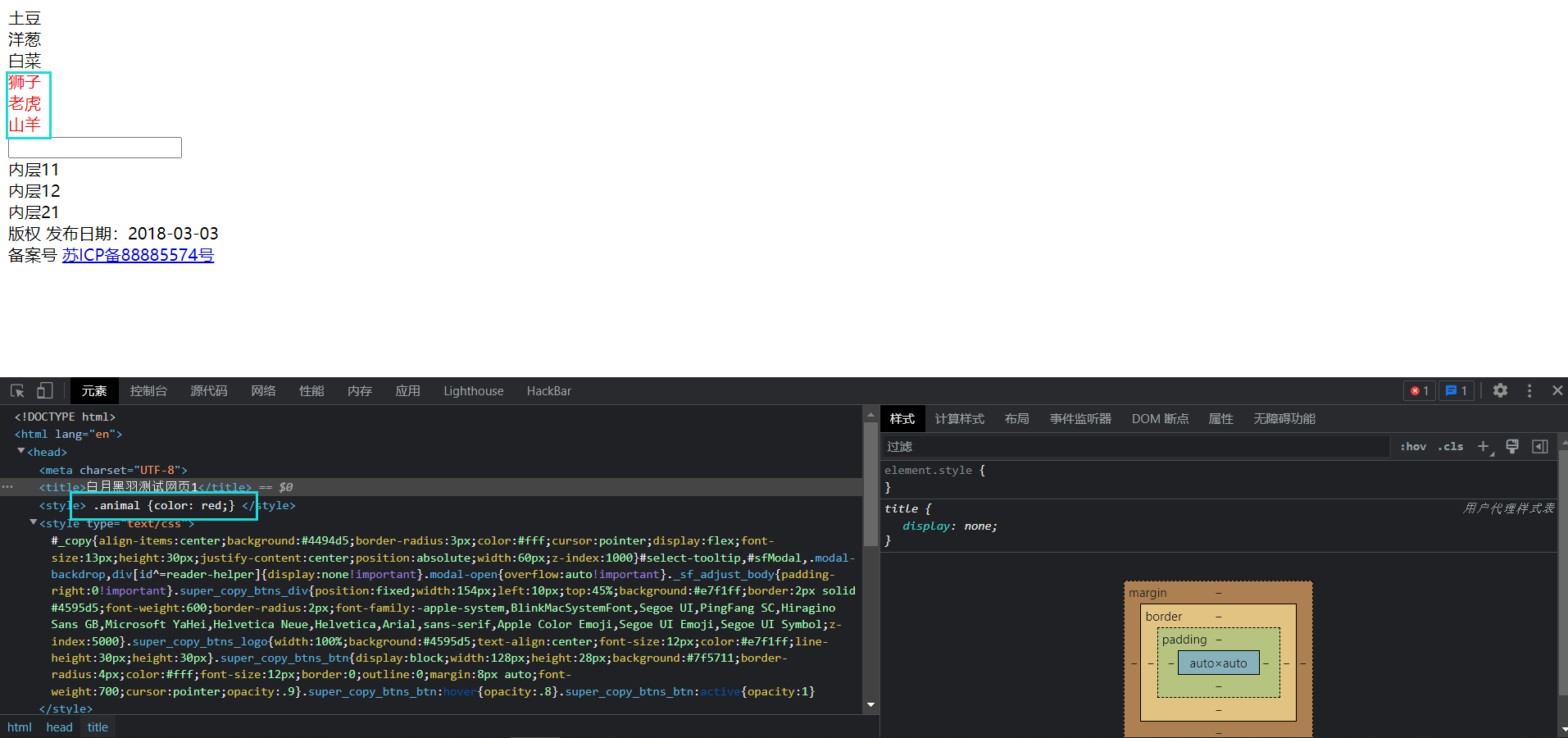
我们就可以使用By.CSS_SELECTOR来筛选元素
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
elements = wd.find_elements(By.CSS_SELECTOR, '.animal')
for i in elements:
print(i.get_attribute('outerHTML'))
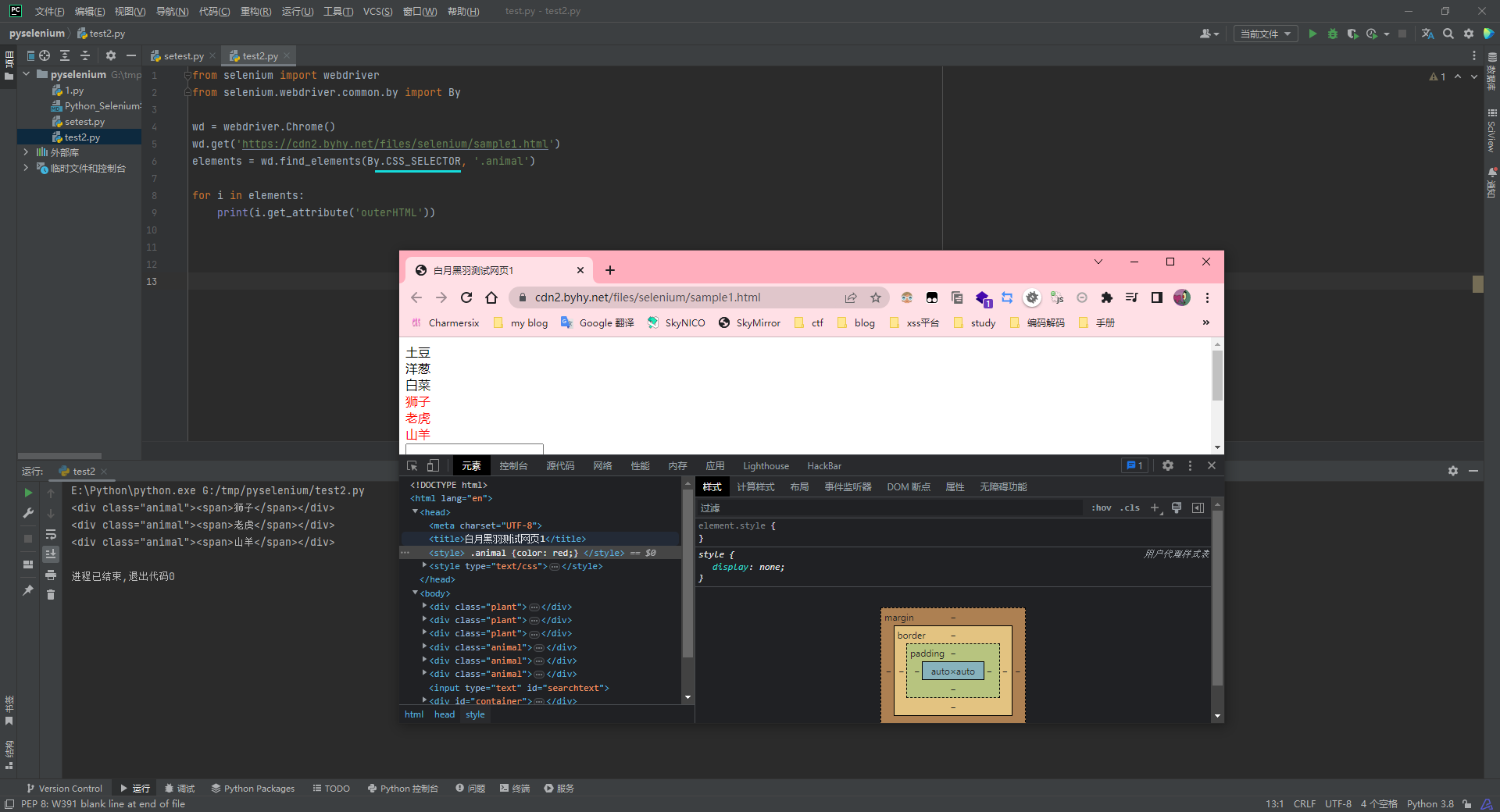
By.CSS_SELECTOR同样可以根据tag名、id 属性和 class属性 来 选择元素,
根据 tag名 选择元素的 CSS Selector 语法非常简单,直接写上tag名即可,
根据id属性 选择元素的语法是在id号前面加上一个井号: #id值
根据class属性 选择元素的语法是在 class 值 前面加上一个点: .class值
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cn.bing.com/')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_element(By.CSS_SELECTOR, '#sb_form_q')
#通过id选择特定元素
elements.send_keys('Charmersix')
search = wd.find_element(By.CSS_SELECTOR, '#search_icon')
# print(elements.get_attribute('value'))
# elements.clear()
# elements.send_keys('SkyMirror')
search.click()
wd.implicitly_wait(5)
clas = wd.find_element(By.CSS_SELECTOR, '.b_attribution')
#clas = wd.find_element(By.CLASS_NAME, '.b_attribution')
cites = wd.find_elements(By.CSS_SELECTOR, 'cite')
for cite in cites:
print(cite.text)
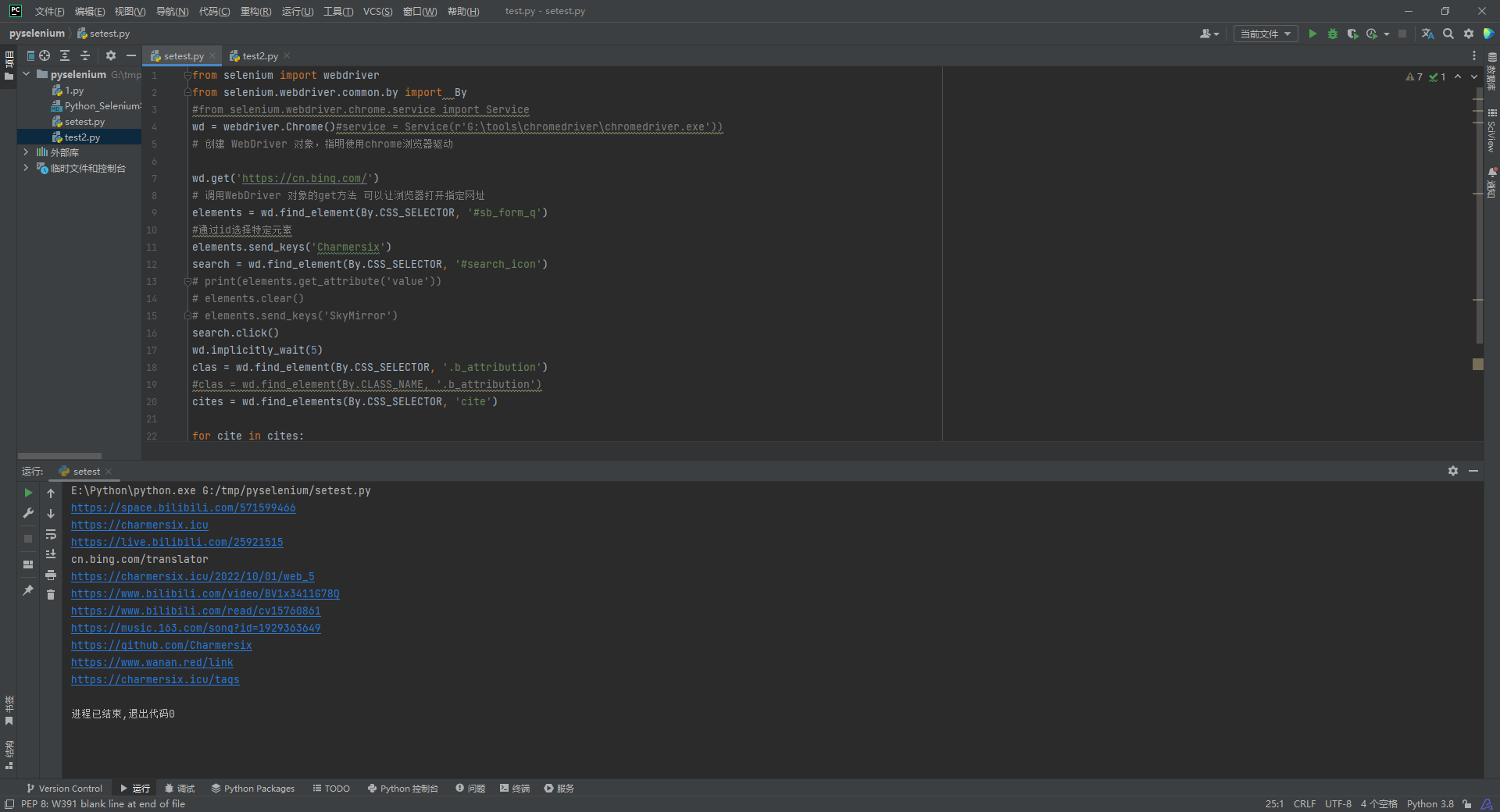
选择子元素和后代元素
HTML中, 元素内部可以包含元素其他元素, CSS_SELECTOR我们可以通过使用>来选择某个元素的子元素, 或者通过使用空格来选择某元素的后代元素
元素1>元素2>元素3
就可以更加精准的选择到元素三
当然我们也可以使用
元素1 元素3
也是可以选择到元素3的
比如说, 这里我们想精准定位到我的这个博客地址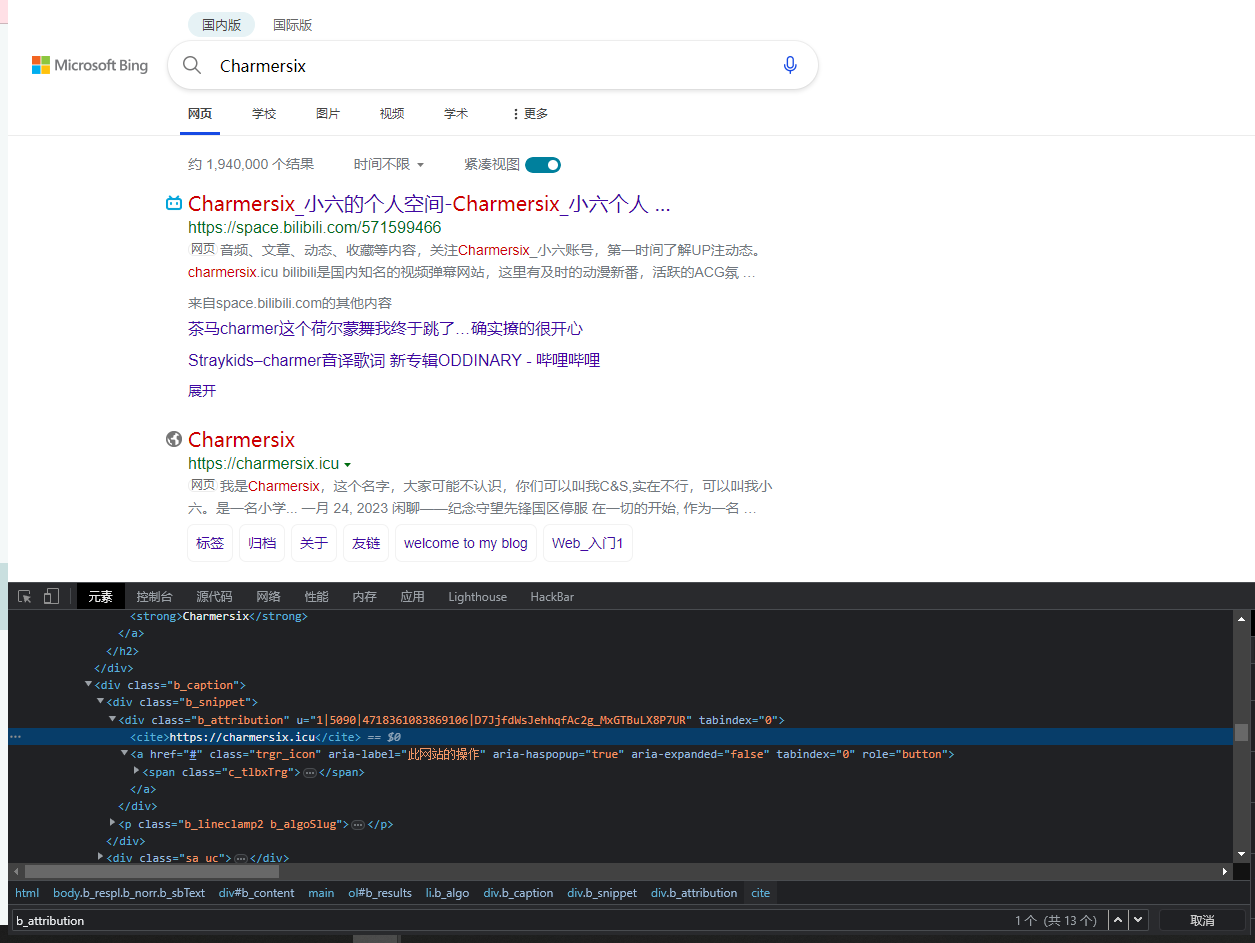
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cn.bing.com/')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_element(By.CSS_SELECTOR, '#sb_form_q')
#通过id选择特定元素
elements.send_keys('Charmersix')
search = wd.find_element(By.CSS_SELECTOR, '#search_icon')
# print(elements.get_attribute('value'))
# elements.clear()
# elements.send_keys('SkyMirror')
search.click()
wd.implicitly_wait(5)
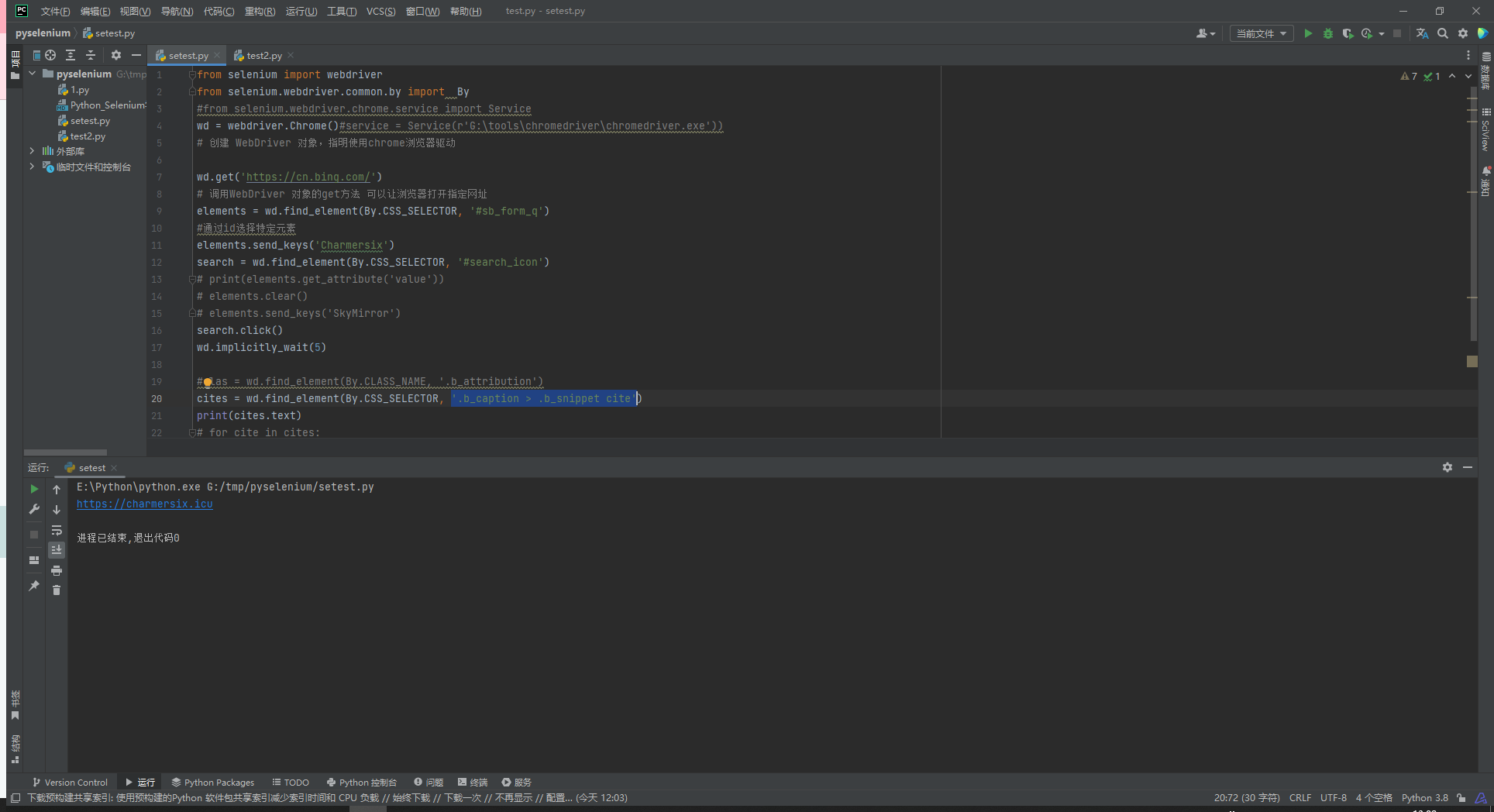
#clas = wd.find_element(By.CLASS_NAME, '.b_attribution')
cites = wd.find_element(By.CSS_SELECTOR, '.b_caption>.b_snippet cite')
print(cites.text)
# for cite in cites:
# print(cite.text)
根据属性选择
像我们这些id, class都是比较常见的, 所以selenium提供了固定的筛选方法, 但是网页中的属性其实是多种多样的, selenium不可能全部规定好, 所以, CSS_SELECTOR提供了可以自定义属性的方法, 就是用[属性名字=属性值]
比如还是上面的例子, 我们会发现, 这个网页里的u属性是比较唯一的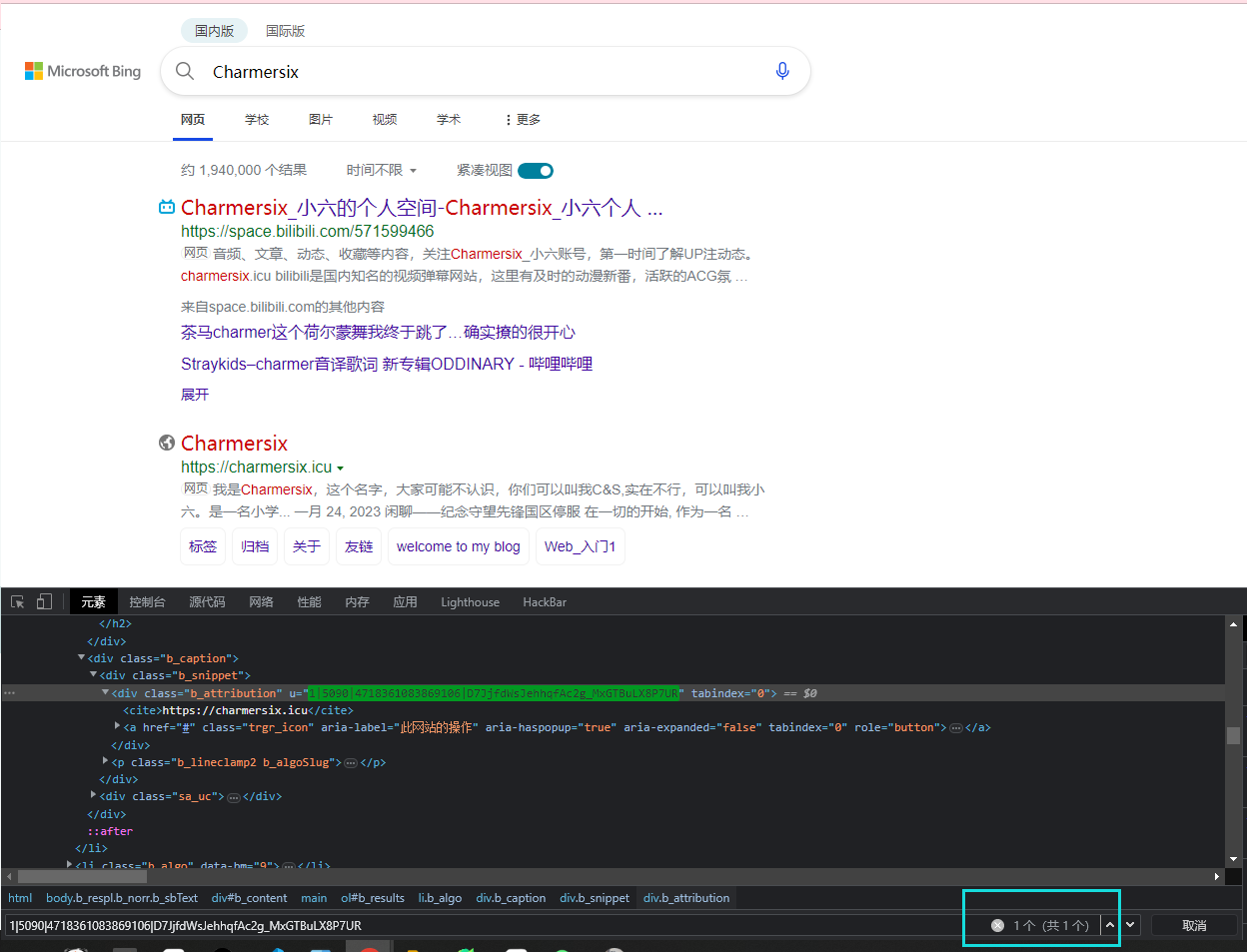
但是, 我们在测试的过程中又会发现u的值会变化, 但是我们会发现一个规律, u的前几位是一样的, 这时候我们就可以使用我们的正则表达式
比方说[u^="1|5090|"]表示属性值以1|5090|开头的, [u*="1|5090|"]表示属性中含有1|5090|的, [u$="1|5090|"]表示以1|5090|结尾的
如果一个元素具有多个属性, 我们可以直接并列这两个属性, 用来选择, 像这样'[u^="1|5090|"][tabindex="0"]'
我们就可以把代码修改为这样, 达到筛选出我博客地址的效果
cites = wd.find_element(By.CSS_SELECTOR, '[u^="1|5090|"][tabindex="0"]>cite')
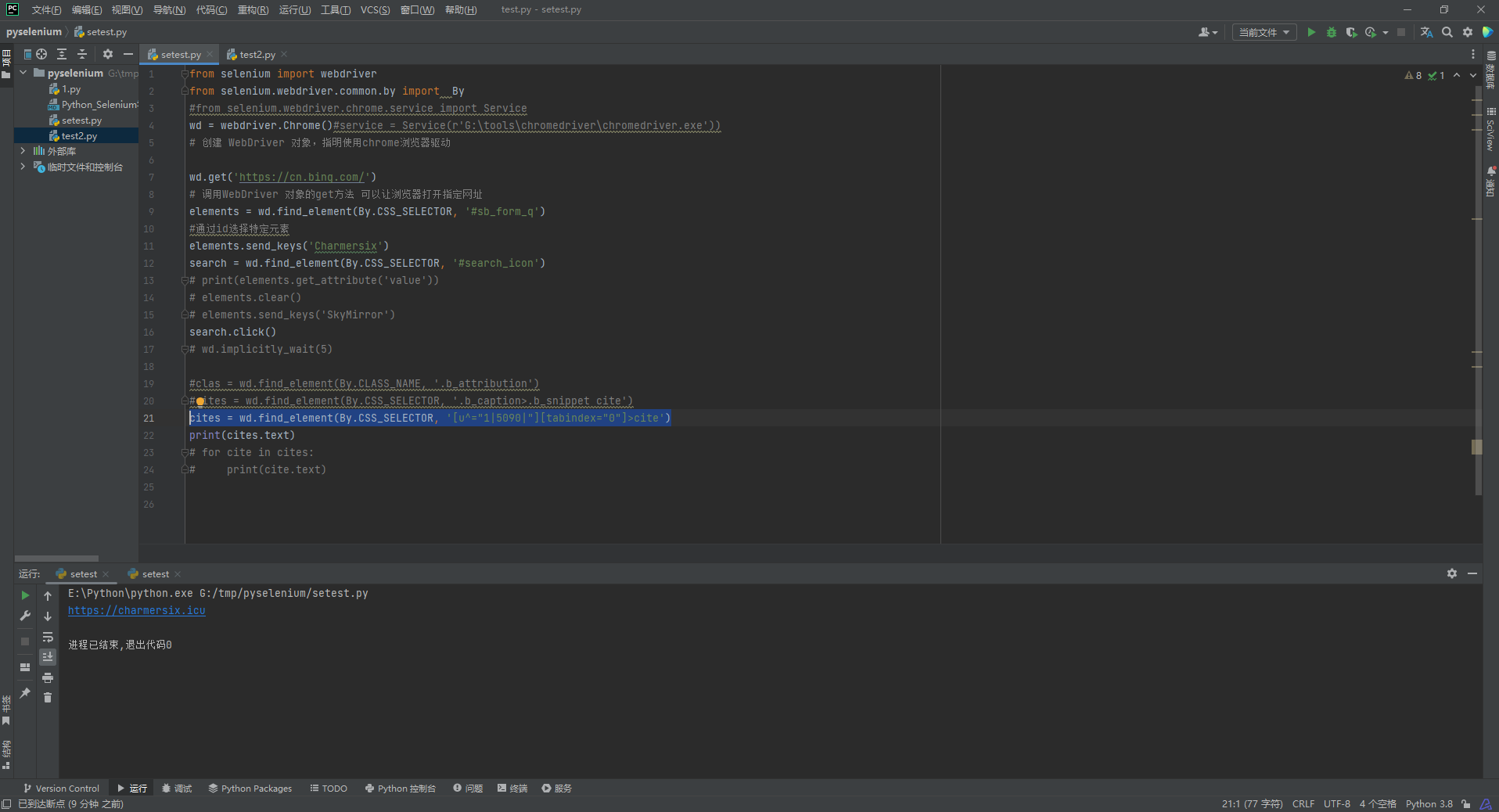
验证选择语法
众所周知, python+selenium运行速度是非常慢的, 如果我们程序每次都通过debug调试的话, 效率太低. 但是我们的浏览器F12的开发者工具也是支持我们的CSS_SELECTOR语法的like this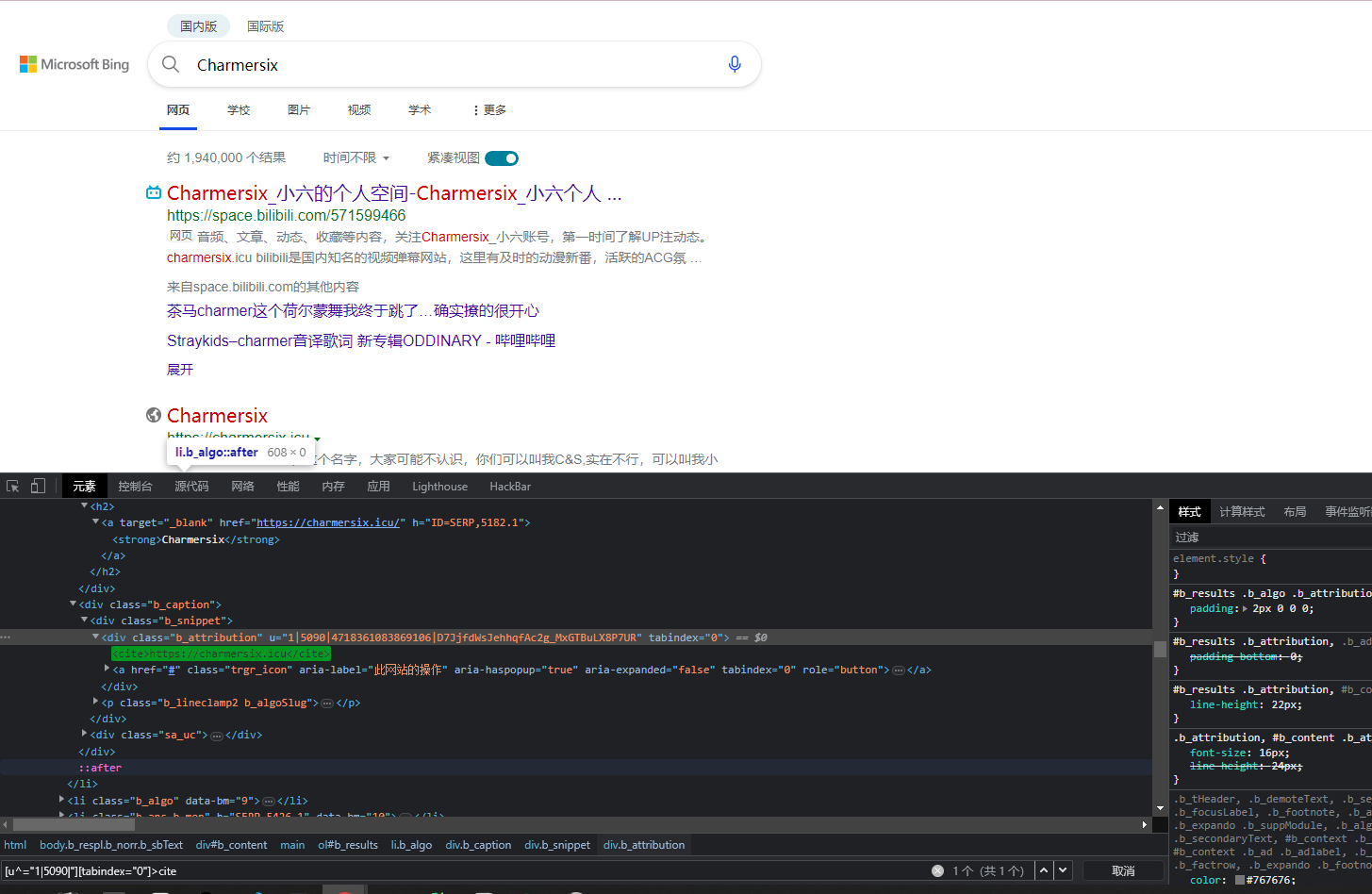
这里我们故意写错试一下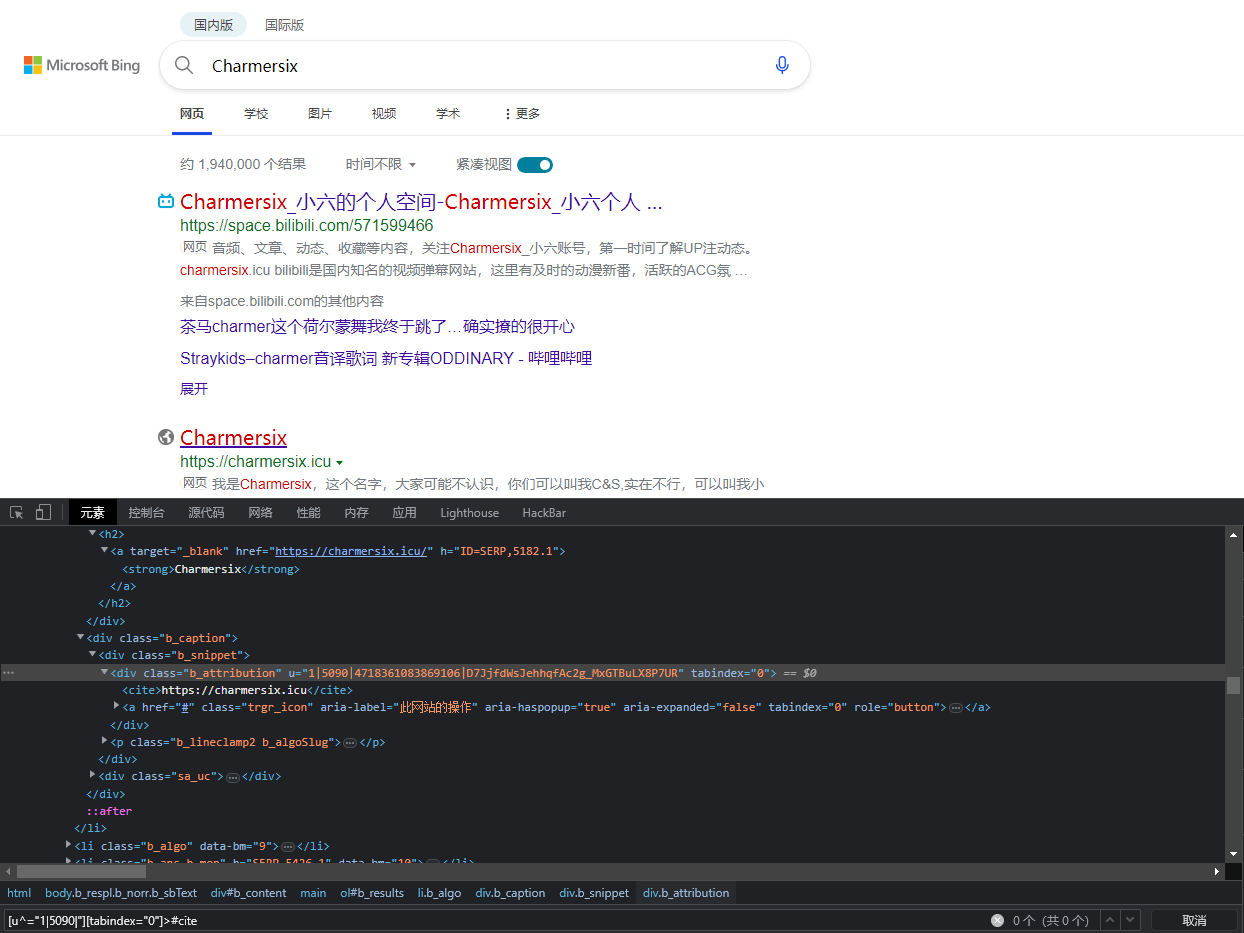
这里就会显示0, 那么我们就很容易发现, 语法不可行
选择语法组合使用
上面已经提到过, 我们需要同时用多个条件限制的时候, 直接两个条件贴在一起, 像上边已经提到过的
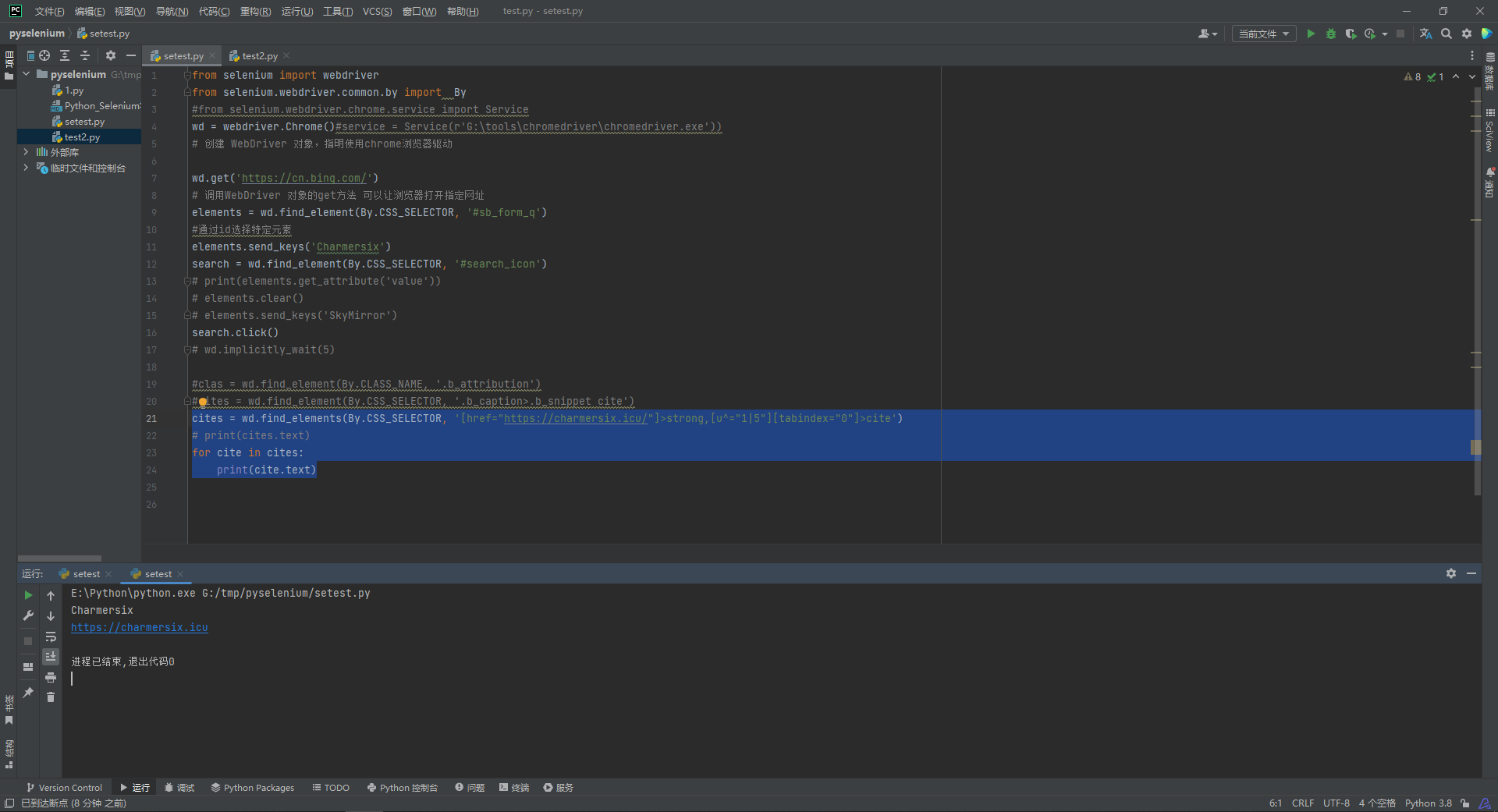
如果我们想要同时获得两个不相干的内容, 我们可以使用,来隔开两个条件, 比如说, 这里我想要同时获取我的名字和我的blog地址
cites = wd.find_elements(By.CSS_SELECTOR, '[href="https://charmersix.icu/"]>strong,[u^="1|5"][tabindex="0"]>cite')
# print(cites.text)
for cite in cites:
print(cite.text)
父元素的第n个子节点
我们可以指定选择的元素是父元素的第几个子节点
使用nth-child
比如说, 如果我们选择的是第二个子元素, 并且是span类型, 所以我们可以这样写
span:nth-child(2)
如果选择的是所有位置为第二个的所有元素, 不管是什么类型, 可以直接写
:nth-child(2)
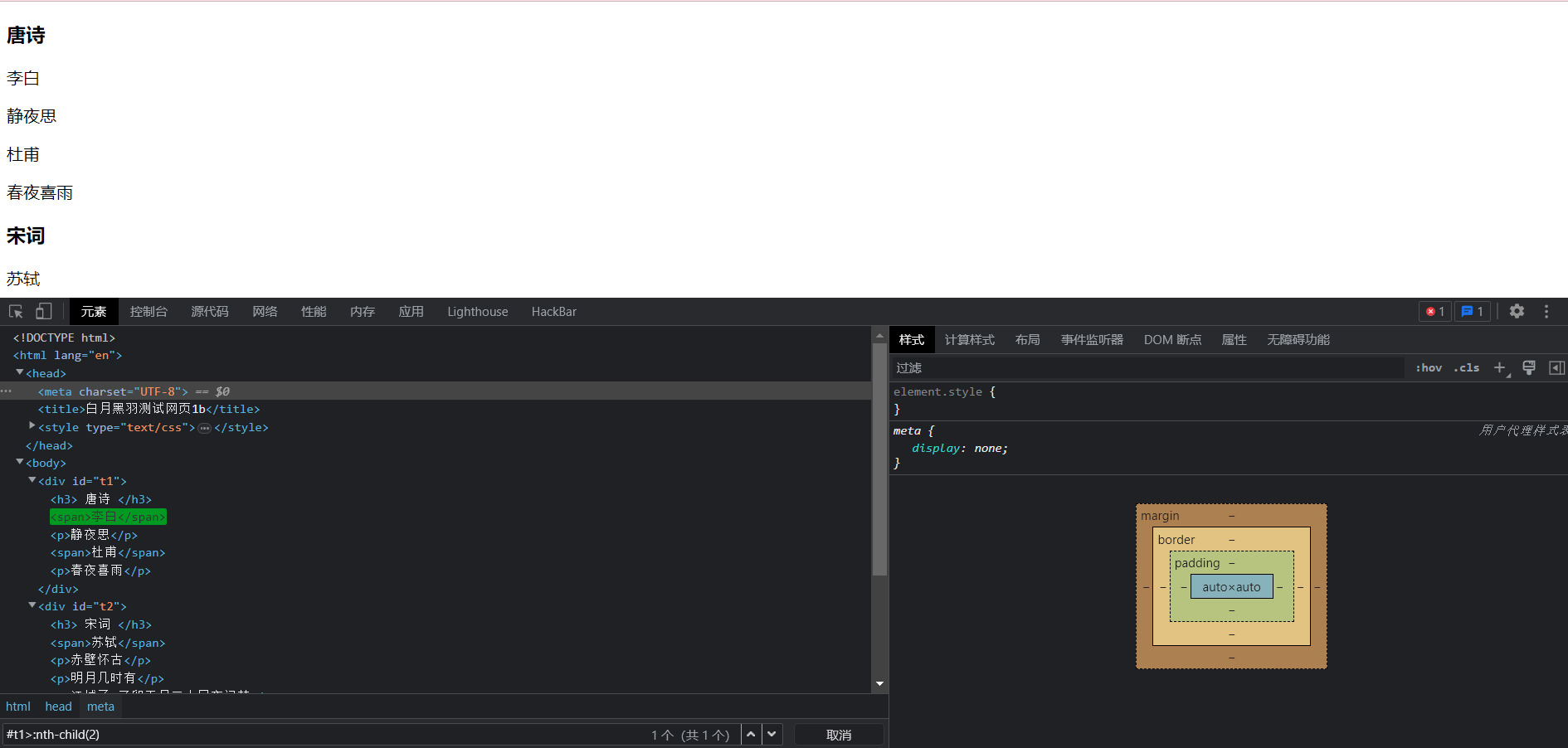
这里我们也可以指定父元素, 比如说我们可以通过父元素的id来指定, 这里借用一下白月黑羽测试页
#t1>:nth-child(2)
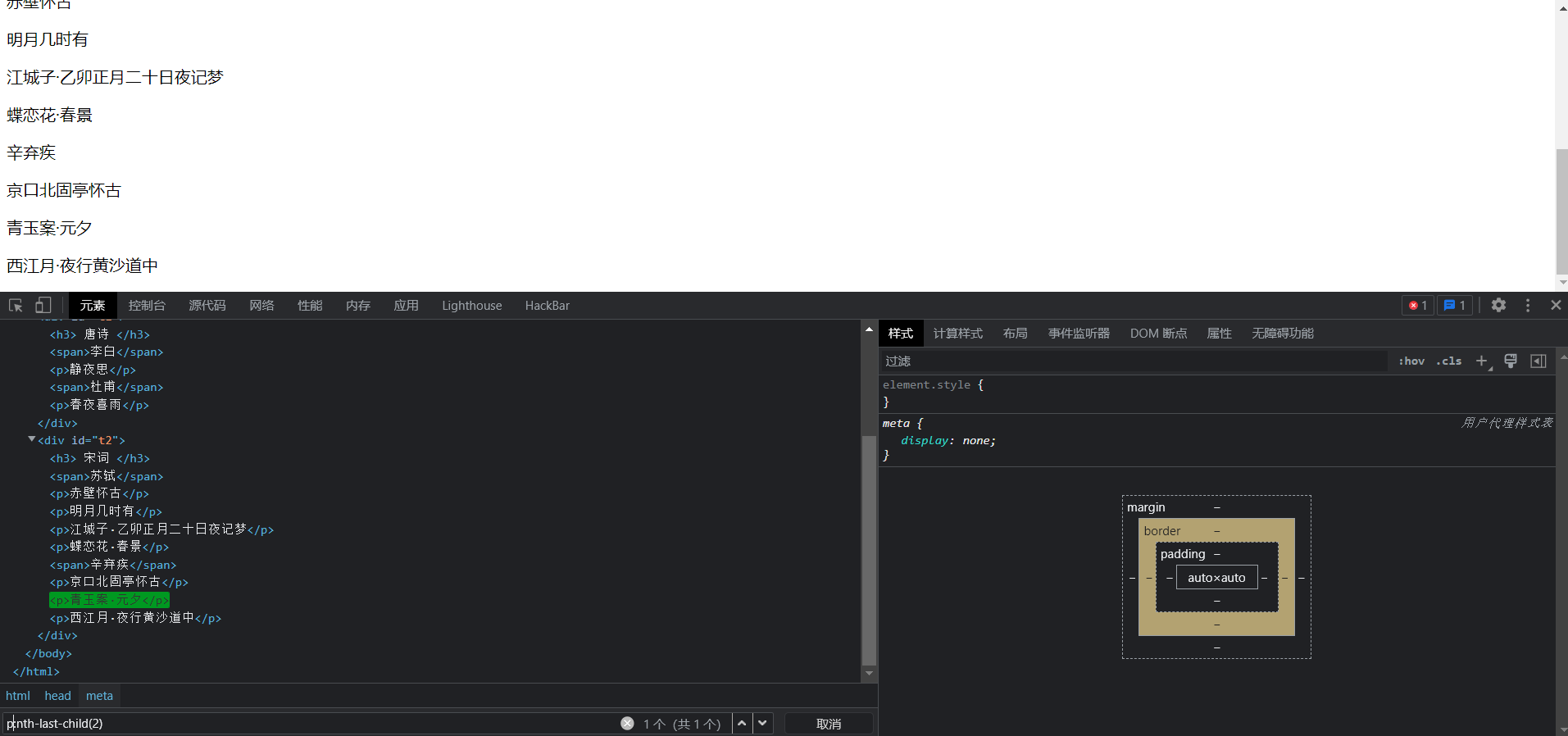
当然也可以通过倒数来选择, 通过nth-last-child
p:nth-last-child(2)
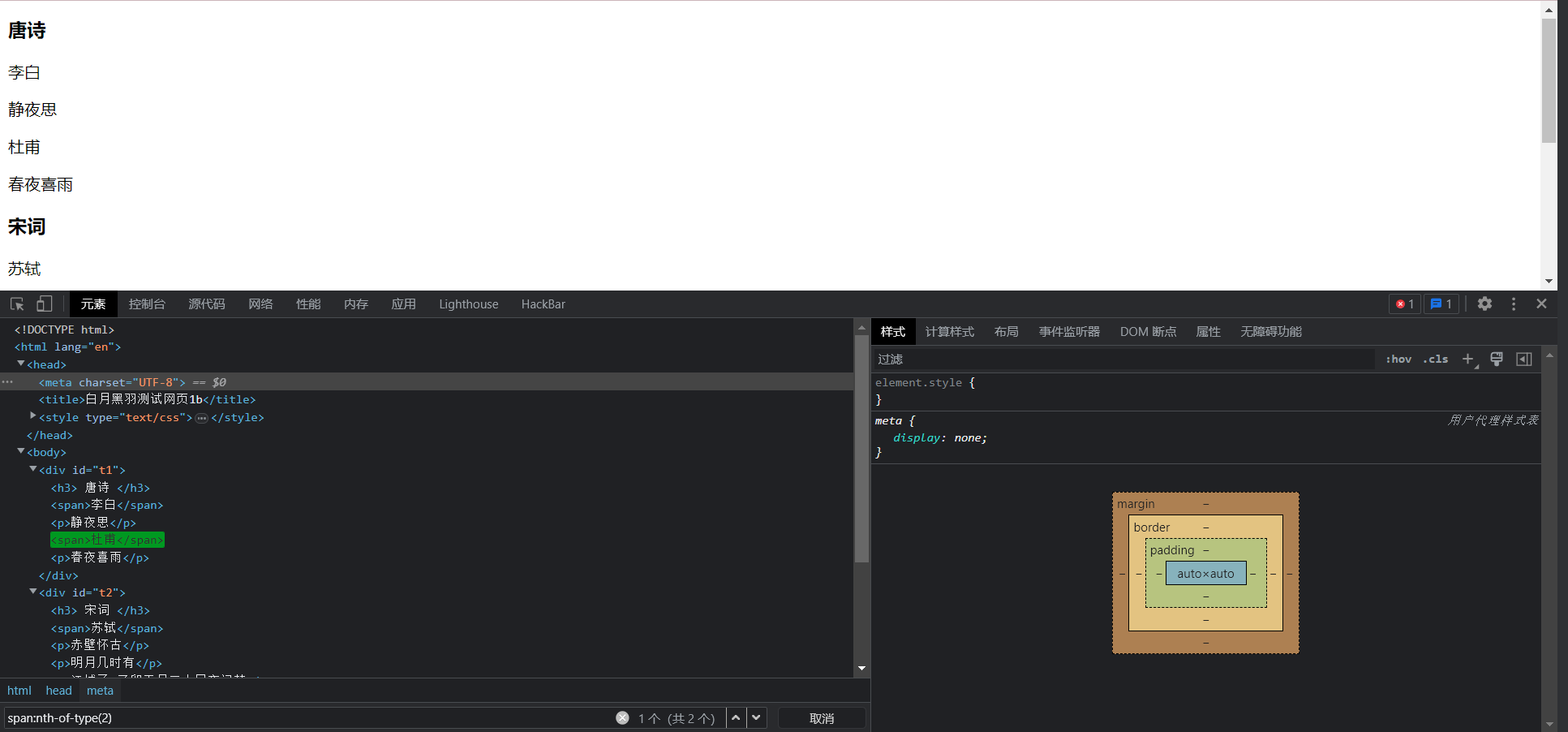
父元素的第几个某类型的子节点
这里我们使用:nth-of-type()
同样, 倒数的是:nth-last-of-type()
奇数节点和偶数节点
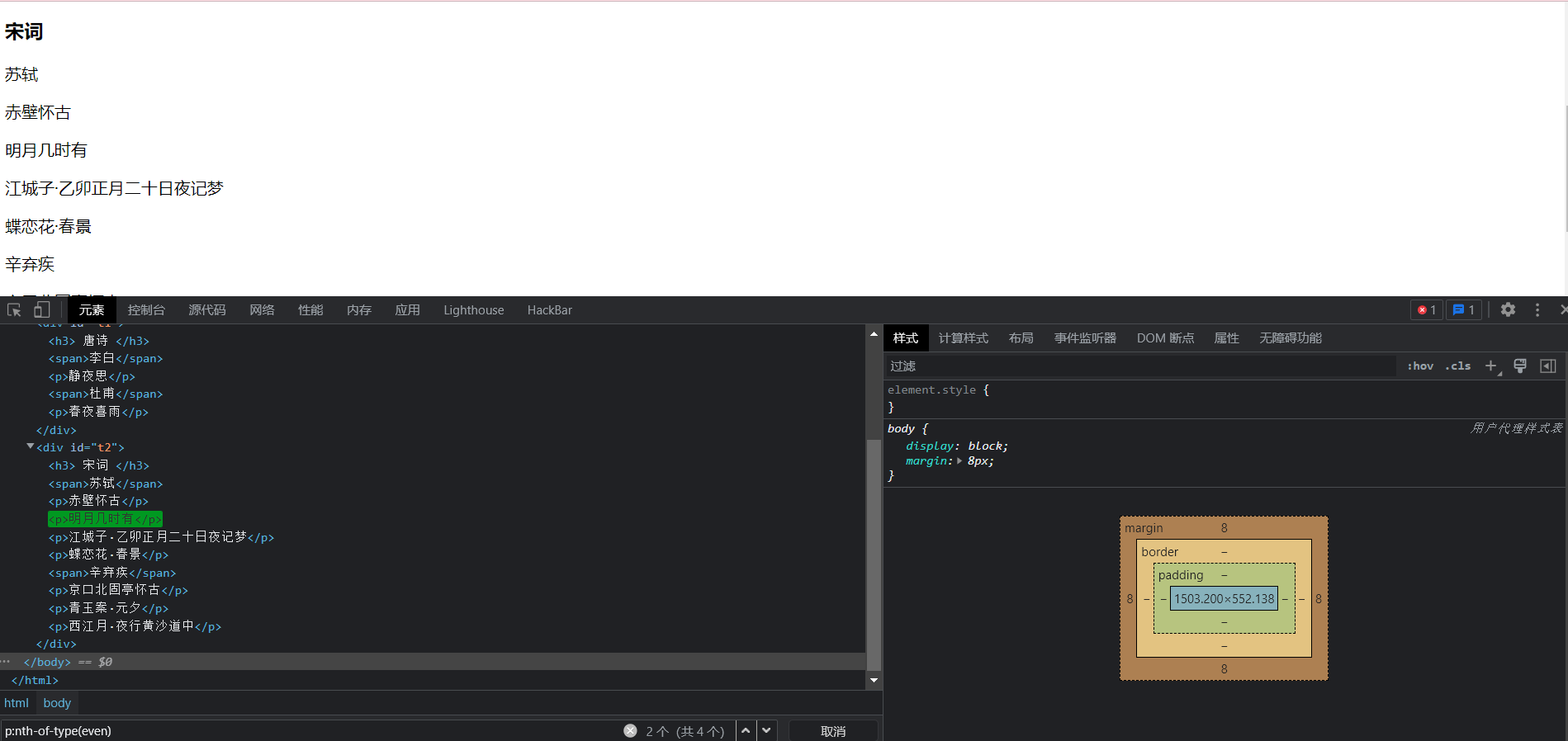
果要选择的是父元素的 偶数节点,使用 nth-child(even)
p:nth-child(even)
如果要选择的是父元素的 奇数节点,使用 nth-child(odd)
p:nth-child(odd)
如果要选择的是父元素的 某类型偶数节点,使用 :nth-of-type(even)
如果要选择的是父元素的 某类型奇数节点,使用 :nth-of-type(odd)
兄弟节点选择
相邻的兄弟关系我们可以用+来表示
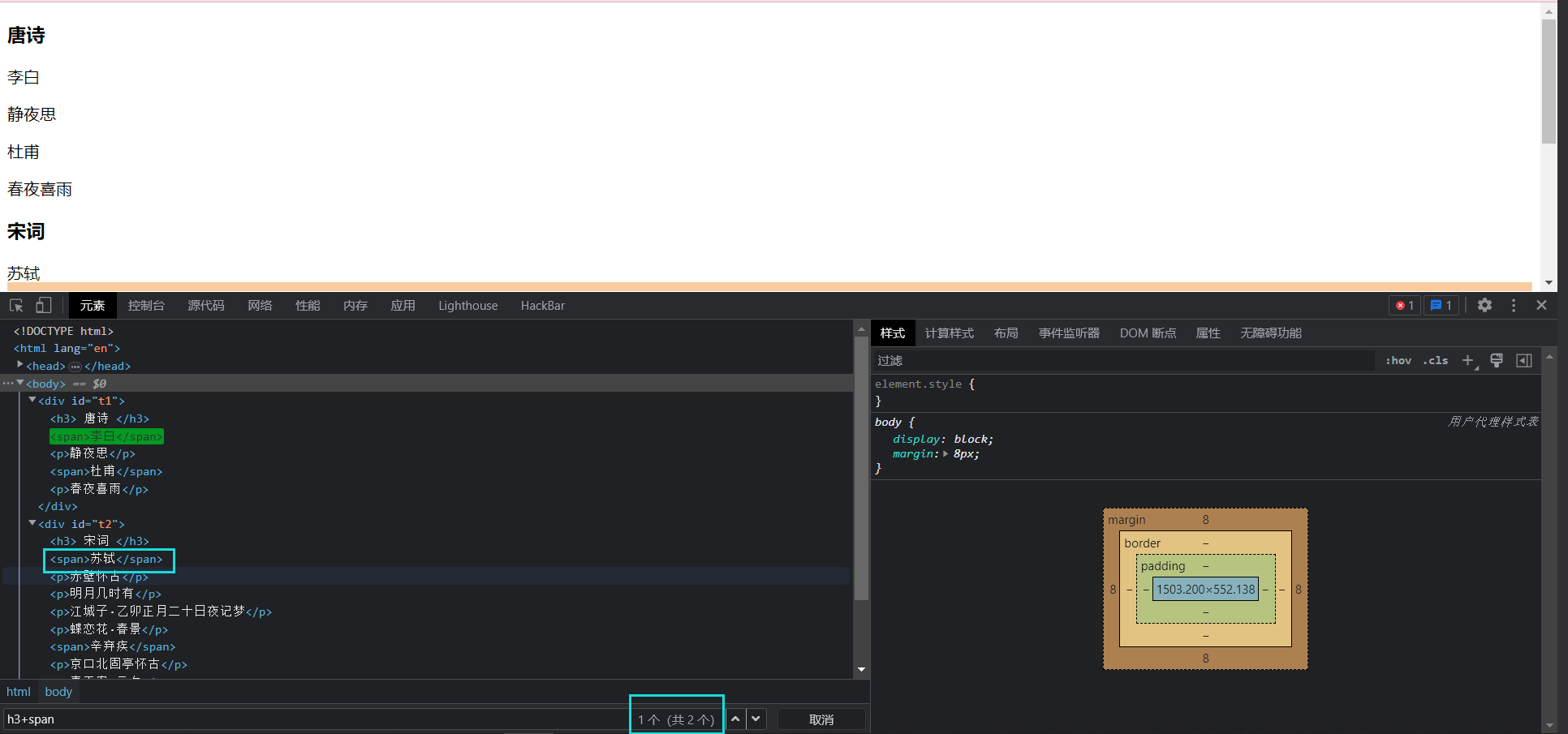
如果不相邻, 但是是后面的兄弟节点, 可以用~表示
frame切换
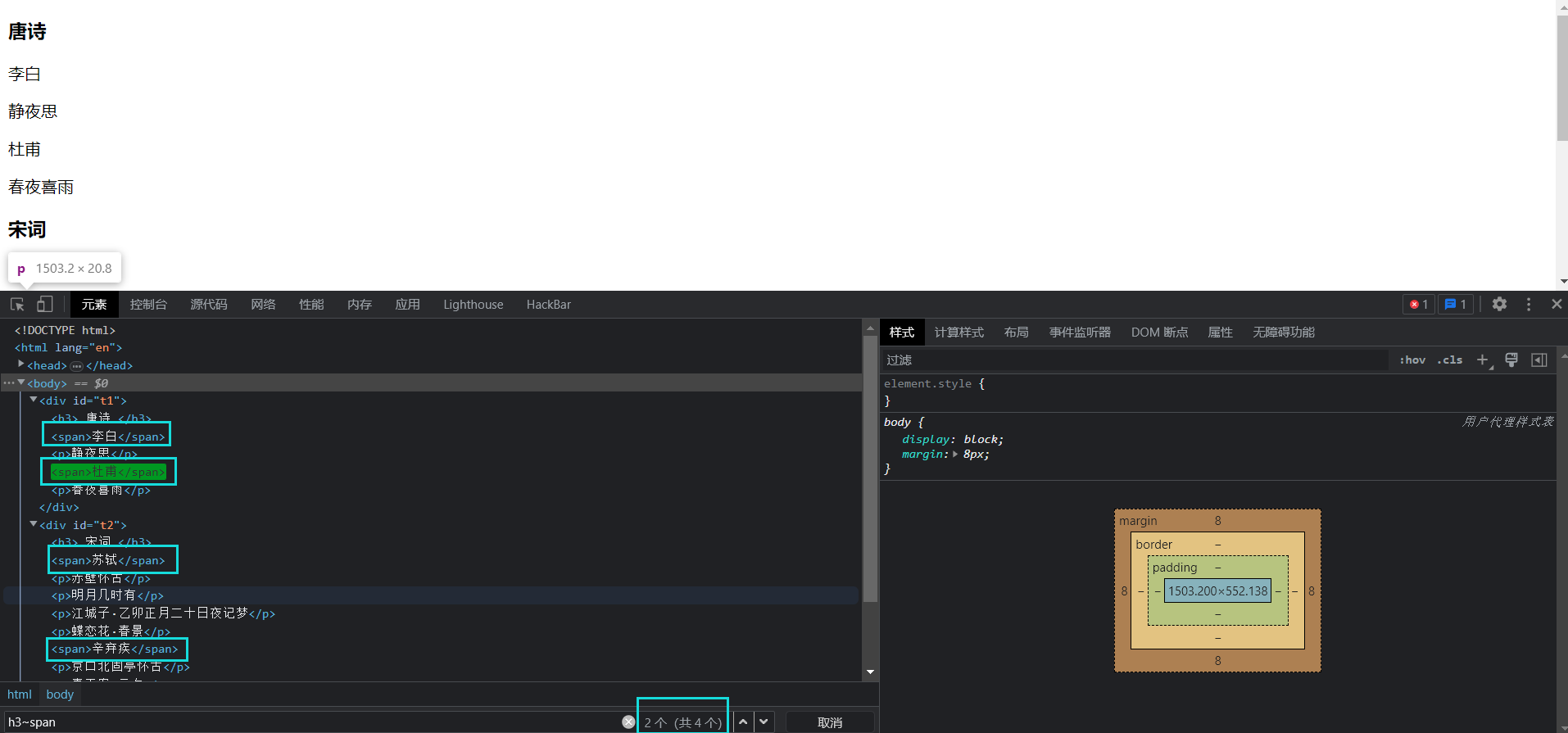
这里我们再次借用一下白月黑羽的测试页, 比如说, 在这个界面里我们想要获取这些蔬菜的名字, 我们像往常一样, 写下这一串代码
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample2.html')
elements = wd.find_elements(By.CSS_SELECTOR, '.plant')
for i in elements:
print(i)
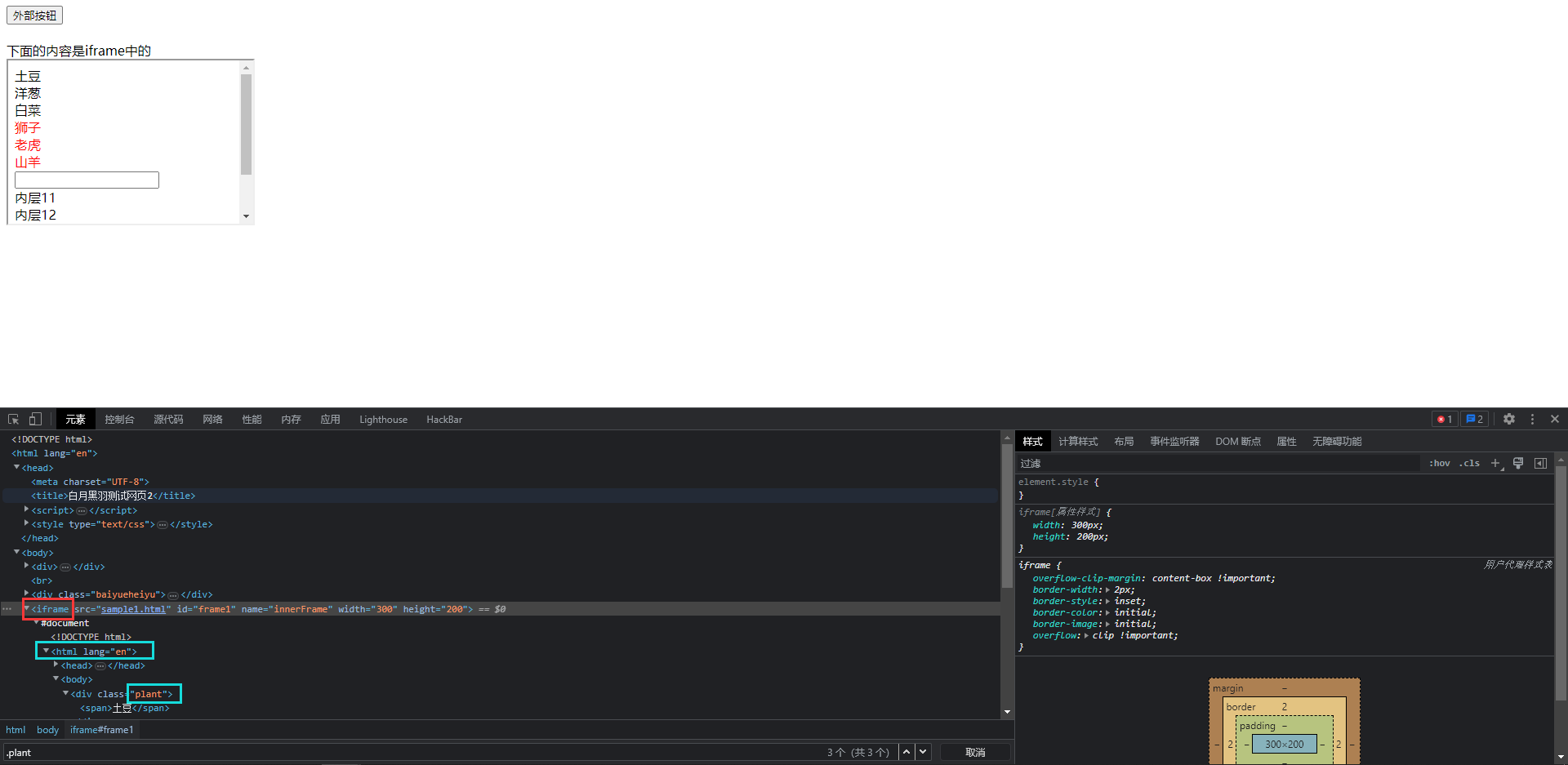
仔细看, 我们会发现这些元素都是在一个叫iframe的元素中, 这个iframe中又嵌套了一个HTML, 在HTML语法中, frame元素或者iframe元素的内部会包含一个被嵌入的一个HTML
如果我们直接find_elements的话, 是在我们第一层的里寻找, 很明显是无法找到的, 就算找到了也不是我们想要的内容
如果我们要操作被嵌入的HTML中的元素, 就必须切换一下操作范围, 使用wd.switch_to.frame(frame_reference)
其中frame_reference可以是frame元素的属性name或者ID
比如这里, 可以直接写成wd.switch_to.frame('frame1')或者wd.switch_to.frame('innerFrame')
我们也可以填写frame所对应的webelement对象, 就是在.switch_to.frame()的括号里再套用find_element系列的方法, 比如这里也可以写成wd.switch_to.frame(wd.find_element(By.TAG_NAME, "iframe"))
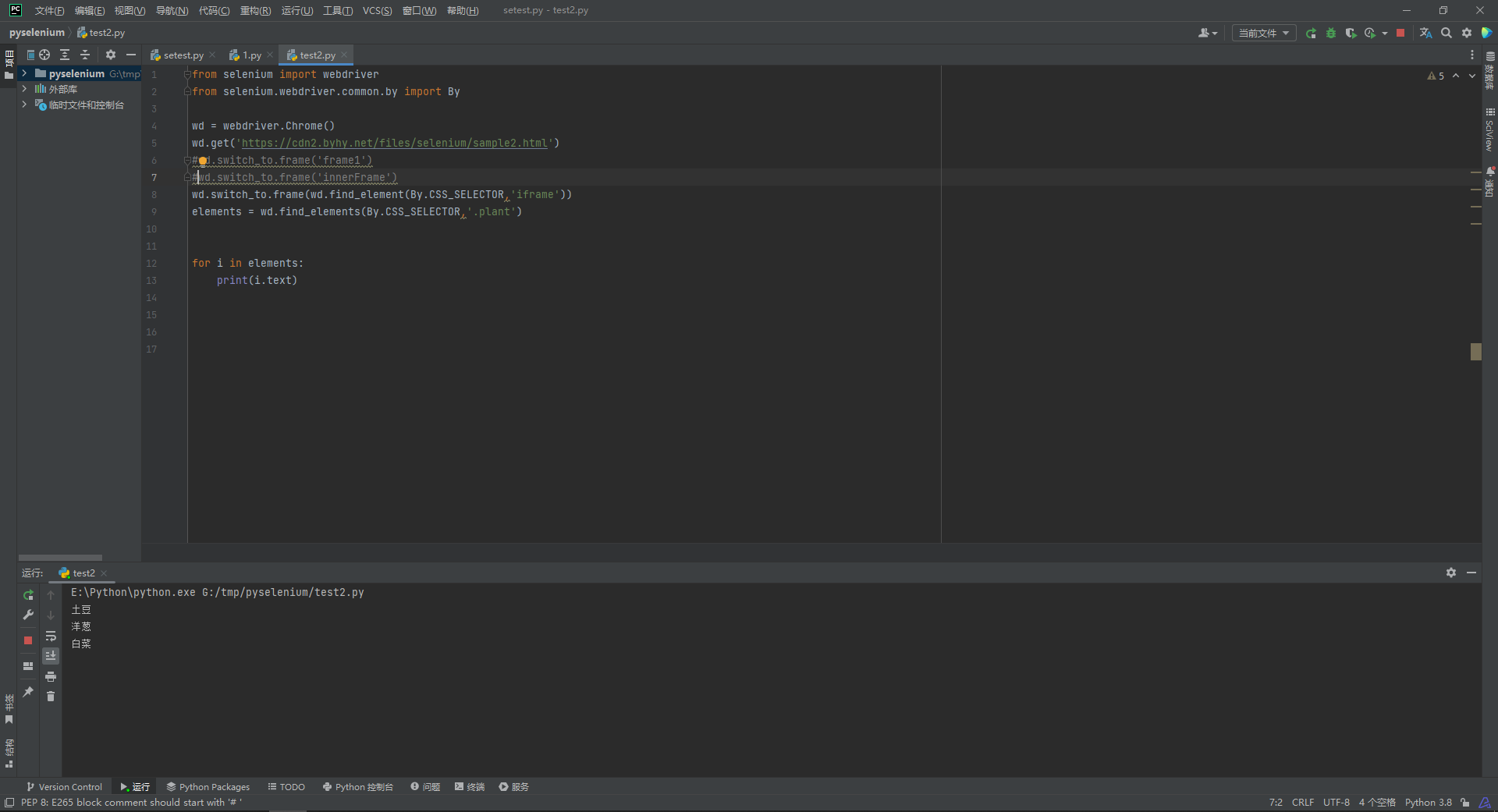
所以我们正确的代码应该是
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample2.html')
#wd.switch_to.frame('frame1')
#wd.switch_to.frame('innerFrame')
wd.switch_to.frame(wd.find_element(By.CSS_SELECTOR,'iframe'))
elements = wd.find_elements(By.CSS_SELECTOR,'.plant')
for i in elements:
print(i.text)
那么, 这时候, 如果我们想再出来操作外层的HTML元素怎么办呢, 例如这里我们想点击一下这个外层的按钮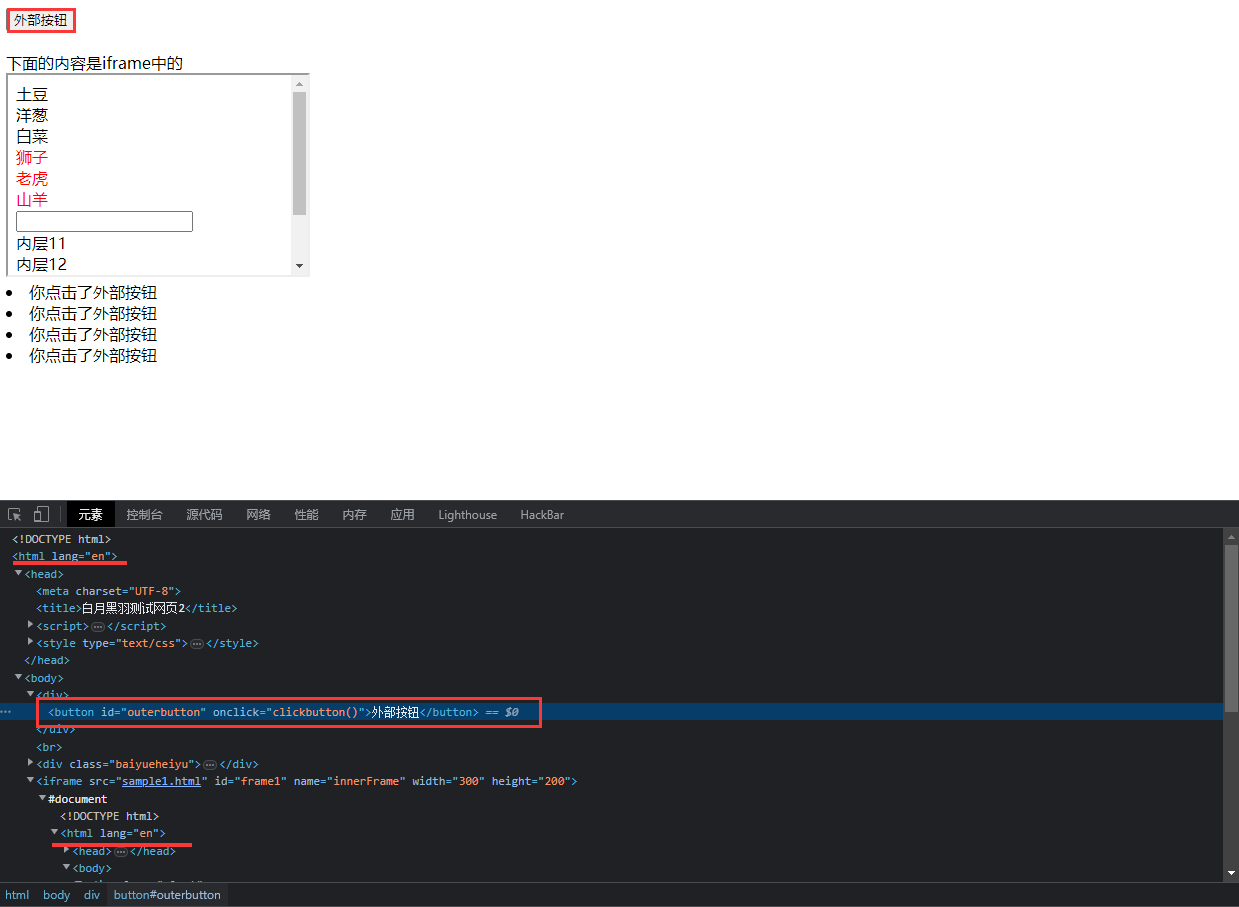
我们只需要执行wd.switch_to.default_content()
像这样, 只要返回了你点击了外部按钮, 就说明我们代码执行成功
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample2.html')
#wd.switch_to.frame('frame1')
#wd.switch_to.frame('innerFrame')
wd.switch_to.frame(wd.find_element(By.CSS_SELECTOR,'iframe'))
elements = wd.find_elements(By.CSS_SELECTOR,'.plant')
for i in elements:
print(i.text)
wd.switch_to.default_content()
wd.find_element(By.ID,'outerbutton').click()
respon = wd.find_element(By.CSS_SELECTOR,'#add>li')
print(respon.text)
有时候我们会遇到, 需要点击超链接进入到下一个窗口的情况, 比方说这里, 我想通过bing找到我的B站后, 进入到我的B站里
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome()#service = Service(r'G:\tools\chromedriver\chromedriver.exe'))
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd.get('https://cn.bing.com/')
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
elements = wd.find_element(By.CSS_SELECTOR, '#sb_form_q')
#通过id选择特定元素
elements.send_keys('Charmersix')
search = wd.find_element(By.CSS_SELECTOR, '#search_icon')
# print(elements.get_attribute('value'))
# elements.clear()
# elements.send_keys('SkyMirror')
search.click()
wd.implicitly_wait(5)
wd.find_element(By.CSS_SELECTOR,'[data-bm="6"]>div>h2>a').click()
wd.implicitly_wait(5)
for handle in wd.window_handles:
wd.switch_to.window(handle)
if 'Charmersix' in wd.title:
break
print(wd.title)
如果我们想再次回到原来的界面, 可以事先保存老窗口, 像这样
main = wd.current_window_handle
wd.find_element(By.CSS_SELECTOR,'[data-bm="6"]>div>h2>a').click()
time.sleep(3)
for handle in wd.window_handles:
wd.switch_to.window(handle)
if 'Charmersix_小六的个人空间_哔哩哔哩_bilibili' in wd.title:
break
wd.switch_to.window(main)
print(wd.title)
这里借用白月黑羽师傅的测试页
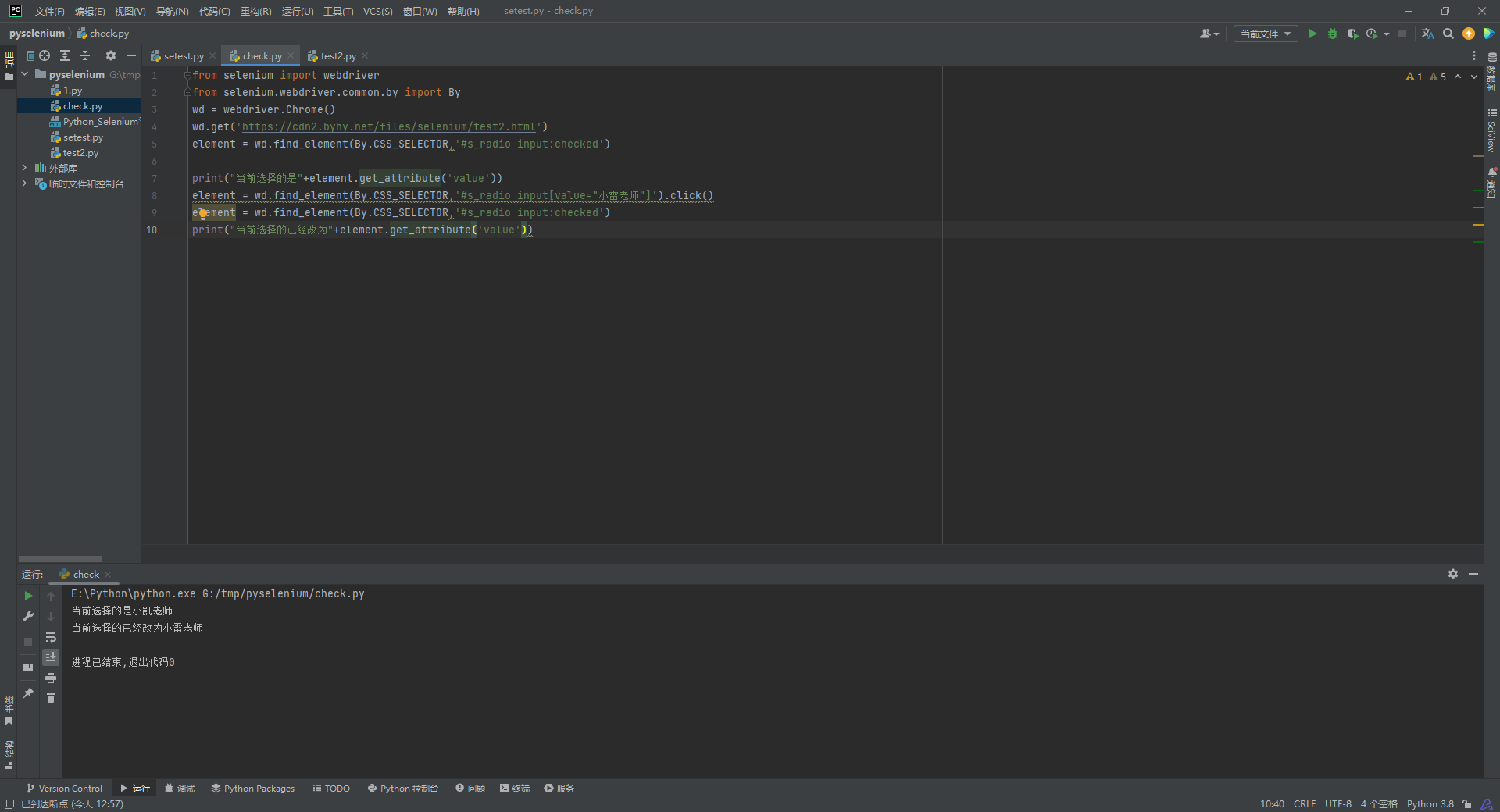
radio
直接使用click方法点击选择即可, 首先, 我们可以用:checked来判断出已经选择的元素, 然后我们再点击重新选择一个新的
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
element = wd.find_element(By.CSS_SELECTOR,'#s_radio input:checked')
#:checked是CSS伪类选择,对radio和checkbox类型的input都有效
print("当前选择的是"+element.get_attribute('value'))
element = wd.find_element(By.CSS_SELECTOR,'#s_radio input[value="小雷老师"]').click()
element = wd.find_element(By.CSS_SELECTOR,'#s_radio input:checked')
print("当前选择的已经改为"+element.get_attribute('value'))
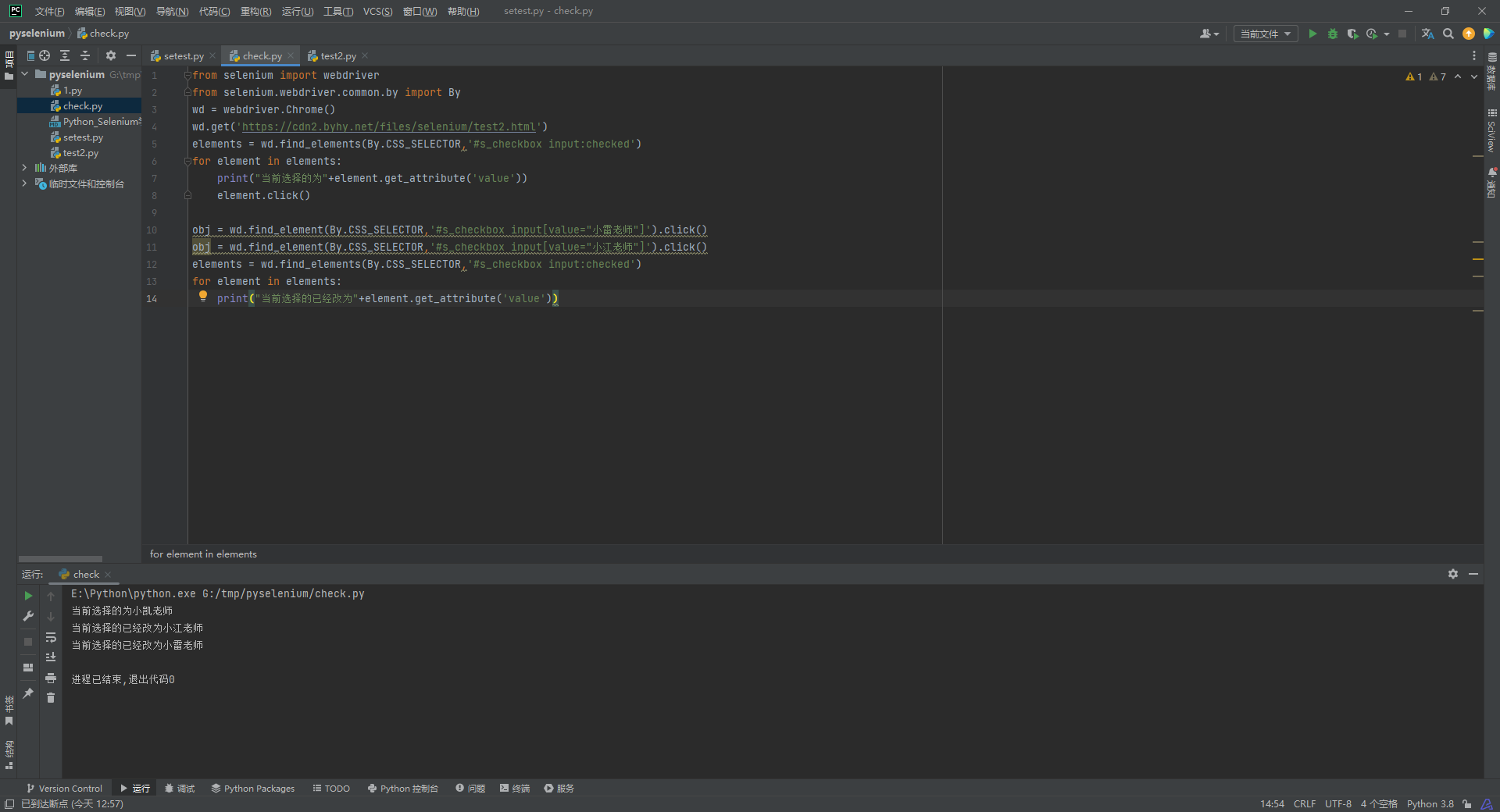
checkbox
checkbox是复选框, 这里如果已经选择的框, 再去点击就会取消选择, 所以我们在选择开始前, 我们就先筛选出已经选择框点一下取消掉, 然后再去选择我们想选的
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
elements = wd.find_elements(By.CSS_SELECTOR,'#s_checkbox input:checked')
for element in elements:
print("当前选择的为"+element.get_attribute('value'))
element.click()
obj = wd.find_element(By.CSS_SELECTOR,'#s_checkbox input[value="小雷老师"]').click()
obj = wd.find_element(By.CSS_SELECTOR,'#s_checkbox input[value="小江老师"]').click()
elements = wd.find_elements(By.CSS_SELECTOR,'#s_checkbox input:checked')
for element in elements:
print("当前选择的已经改为"+element.get_attribute('value'))
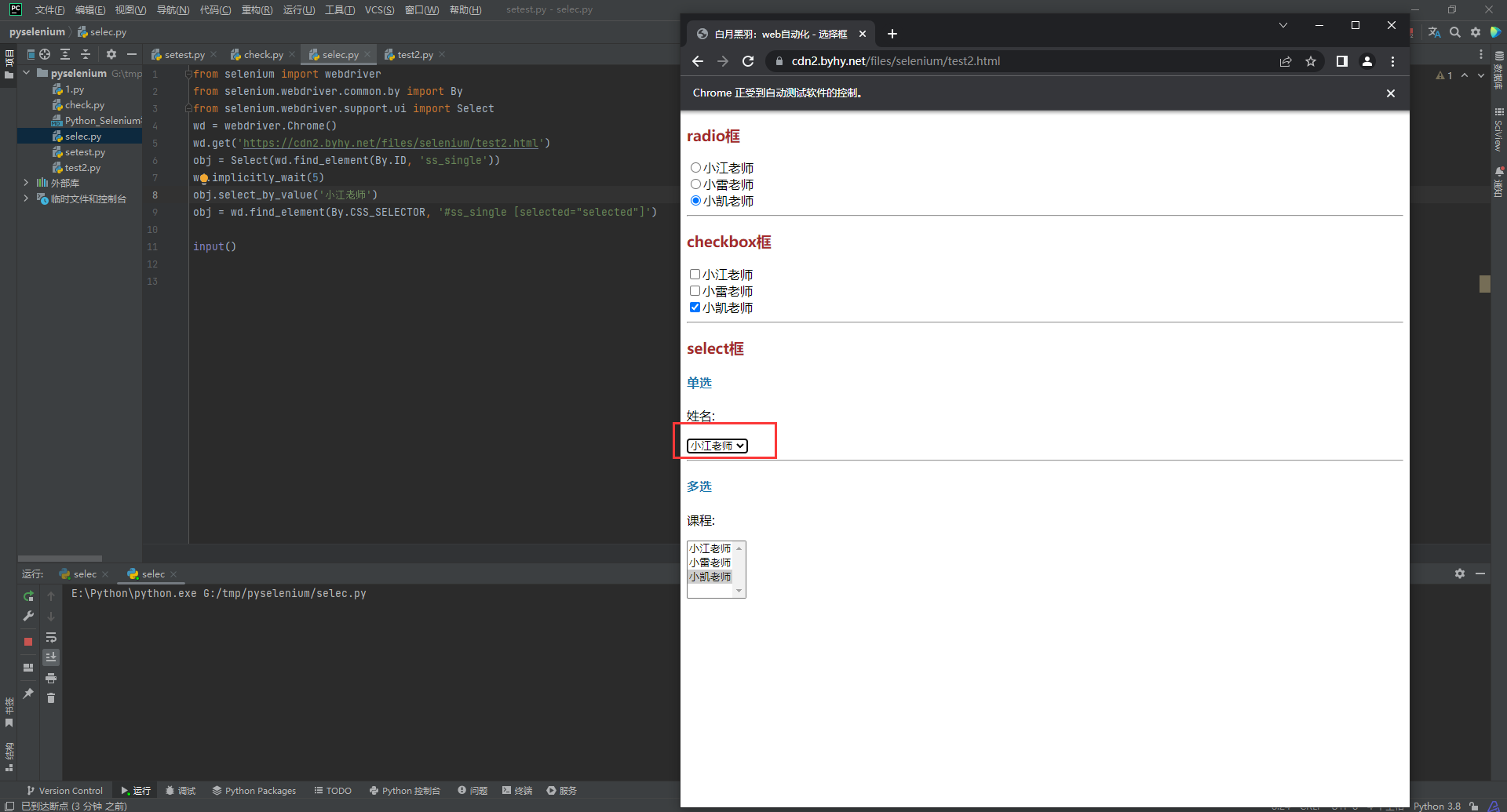
select
radio和checkbox都是input元素, 只是里边的type不同而已
select则是一个新的select标签, 对于select, selenium提供了专门的Select类进行操作
Select类中 提供了以下的方法
- select_by_value 根据选项的value属性值选择元素
- select_by_index 根据选项的次序(从1开始)选择元素
- select_by_visible_text 根据选项的可见文本选择元素
- deselect_by_ 是去除选中元素, 同样适用上述方法
- deselect_all 去除选中的所有元素
对于单选框, 比较简单, 无论之前选的什么, 只需要直接选择即可
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
obj = Select(wd.find_element(By.ID, 'ss_single'))
obj.select_by_visible_text('小江老师')
print("当前选择的为"+obj.get_attribute('value'))
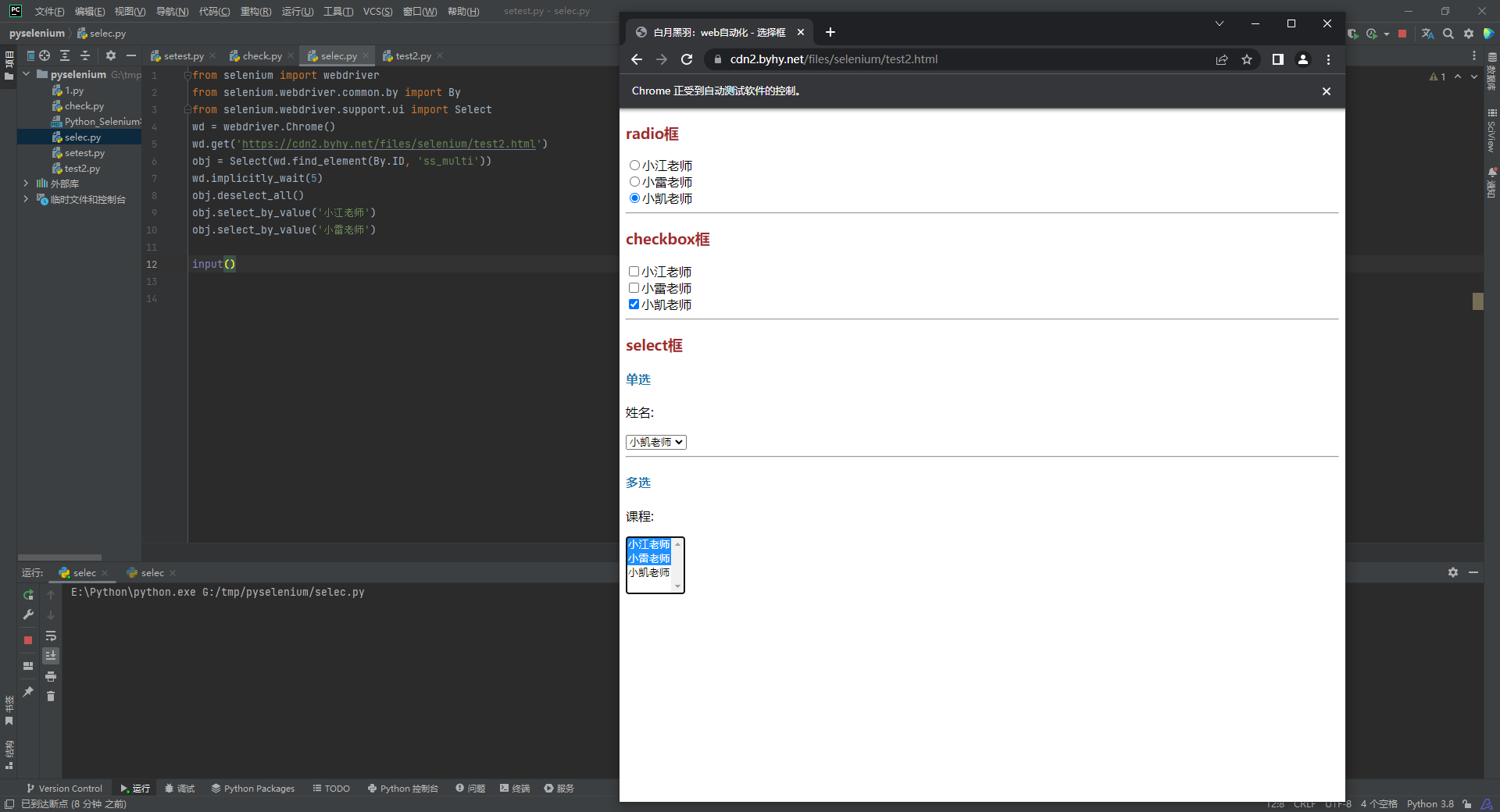
同上, 先用deselect_all()清除所有, 然后再选择
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
obj = Select(wd.find_element(By.ID, 'ss_multi'))
wd.implicitly_wait(5)
obj.deselect_all()
obj.select_by_value('小江老师')
obj.select_by_value('小雷老师')
input()
其他操作方法
之前我们对web元素做的主要操作是:选择元素,然后点击元素或者输入字符串, 其他操作我们可以通过Selenium提供的ActionChains类来实现
ActionChains类里面提供了一些特殊的动作的模拟, 我们可以通过查看ActionChains类的代码看到如下方法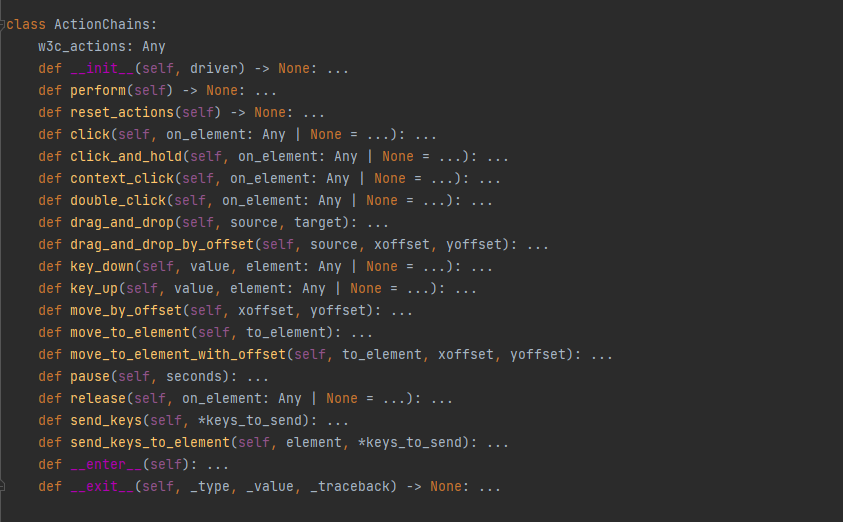
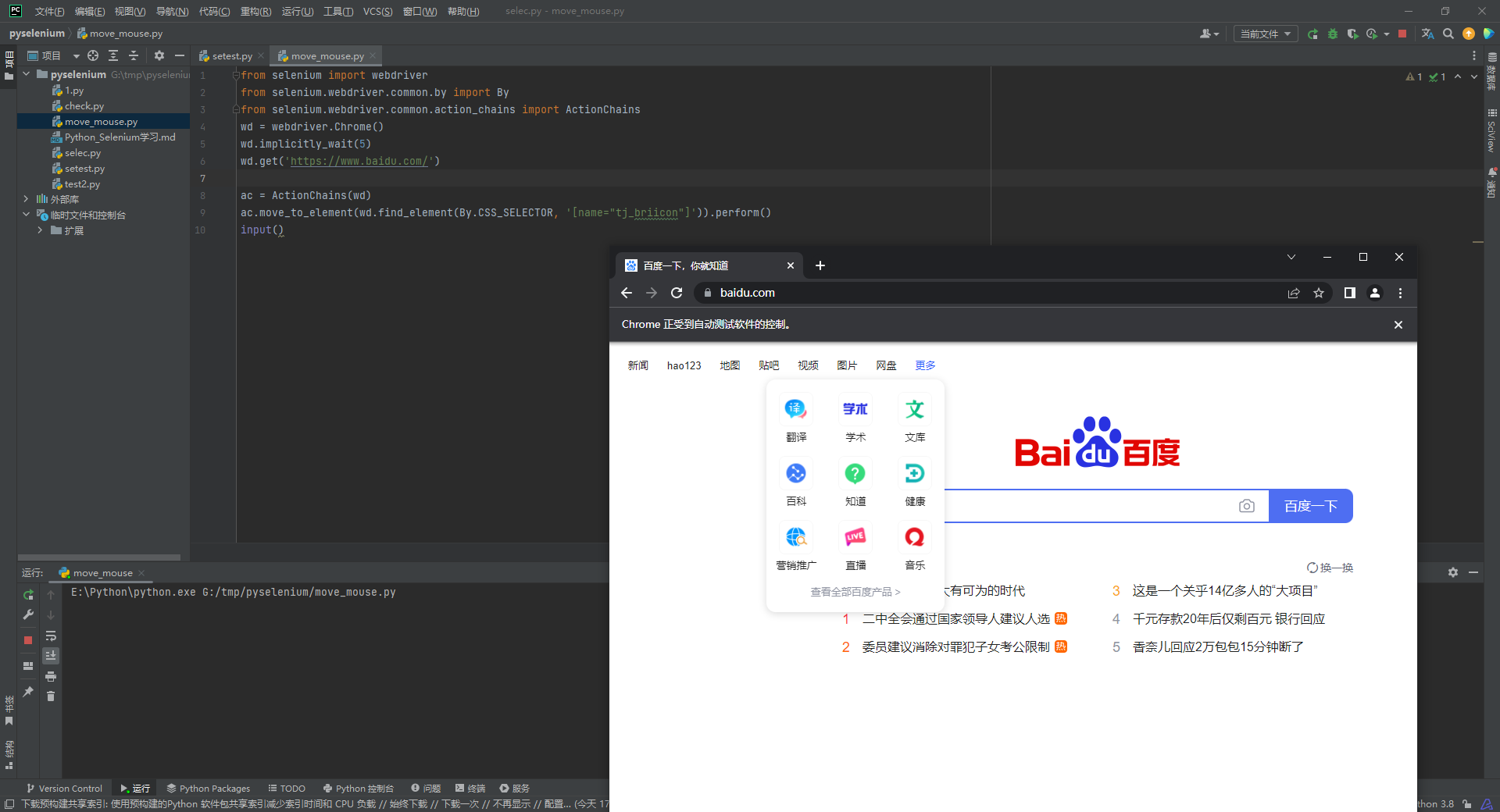
这里我们举一个鼠标移动的例子, 比如说, 我们的百度页面上, 有这个更多框, 这个框里的内容只有将鼠标移上才能显示出来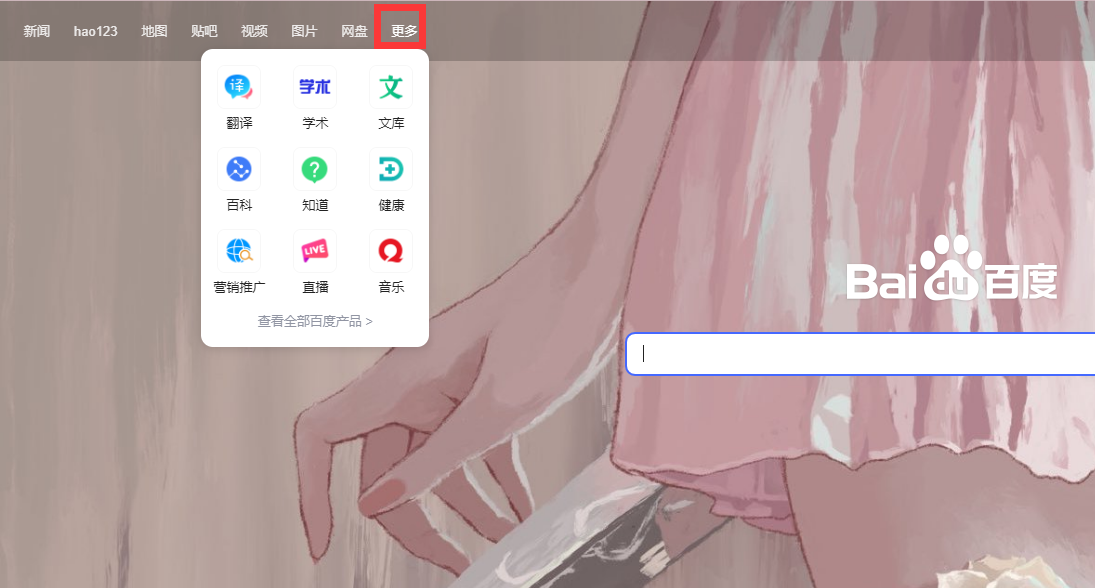
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://www.baidu.com/')
ac = ActionChains(wd)
ac.move_to_element(wd.find_element(By.CSS_SELECTOR, '[name="tj_briicon"]')).perform()
#perform()必须要有, 是执行的意思, 否则操作不会执行
执行JavaScript
我们可以调用execute_script执行我们的JavaScript代码
例如, 有时我们访问的网页很长, 我们要点击的元素没有在窗口可以显示的范围内, selenium就会报类似这种错误
element click intercepted: Element <span>这里是元素html</span>
is not clickable at point (119, 10).
Other element would receive the click: <div>...</div>
这时候, 我们就可以用下面这串代码, 让需要点击的元素出现在页面的最中间
wd.execute_script("arguments[0].scrollIntoView({block:'center',inline:'center'})", job)
其中arguments[0]指代了后面的第一个参数job对应的js对象, js对象的scrollIntoView方法就是让元素滚动到可见部分
block:'center' 指定垂直方向居中
inline:'center' 指定水平方向居中
我们也可以通过下面这串代码, 来判断我们一个网站到底有几页
nextPageButtonDisabled = driver.execute_script(
'''
ele = document.querySelector('.soupager > button:last-of-type');
return ele.getAttribute('disabled')
''')
# 返回的数据转化为Python中的数据对象进行后续处理
if nextPageButtonDisabled == 'disabled': # 是最后一页
return True
else: # 不是最后一页
return False
这段代码是使用 Selenium WebDriver 和 JavaScript 执行一个查询,检查是否存在下一页的按钮,并返回该按钮是否被禁用(disabled)的状态。
具体来说,这段代码做了以下几件事情:
- 使用
driver.execute_script()方法来执行一个 JavaScript 代码块。- JavaScript 代码块中,使用
document.querySelector()方法选择了 HTML 文档中的一个 class 为soupager的元素,并选中了该元素下面的最后一个 button 元素。- 接着使用
ele.getAttribute('disabled')方法获取该 button 元素的disabled属性值,并将其返回给 Python 变量nextPageButtonDisabled。- 最后根据
nextPageButtonDisabled的值是否为字符串 ‘disabled’,来判断下一页的按钮是否被禁用(disabled)。如果
nextPageButtonDisabled的值为 ‘disabled’,则表示下一页的按钮已被禁用,Python 函数将返回 True;否则,Python 函数将返回 False。
像上面例子一样, 当我们光标移开的时候, 更多里面的内容就无了, 这时候我们如果想要进一步操更多里面的内容, 我们就需要将眼前的界面冻结, 才能继续操作
这里我们就需要利用JavaScript代码的debugger功能, 冻结页面
可以让浏览器执行下列js代码, 进入debug状态, 冻住界面
setTimeout(function(){debugger}, 5000)
这串代码意思是, 在5000ms也就是5s后, 执行页面的debugger命令, 冻住界面, 由于我们还需要进行鼠标移动的操作, 所以说要在5s后冻住界面
这样就方便我们寻找元素
弹出对话框
Alert
alert弹出框, selenium提供了点击方法
wd.driver.switch_to.alert.accept()
如果是获取对话框中的文本, 可以通过如下代码
wd.switch_to.alert.text
Confirm
相比于alert, 多了一个取消按钮, 可以用dismiss, 代码如下
wd.switch_to.alert.dismiss()
Prompt
相比于上面两个, 多了一个填信息的框, 方法如下
wd.switch_to.alert.send_keys()
我们可以通过下面的代码感受一下
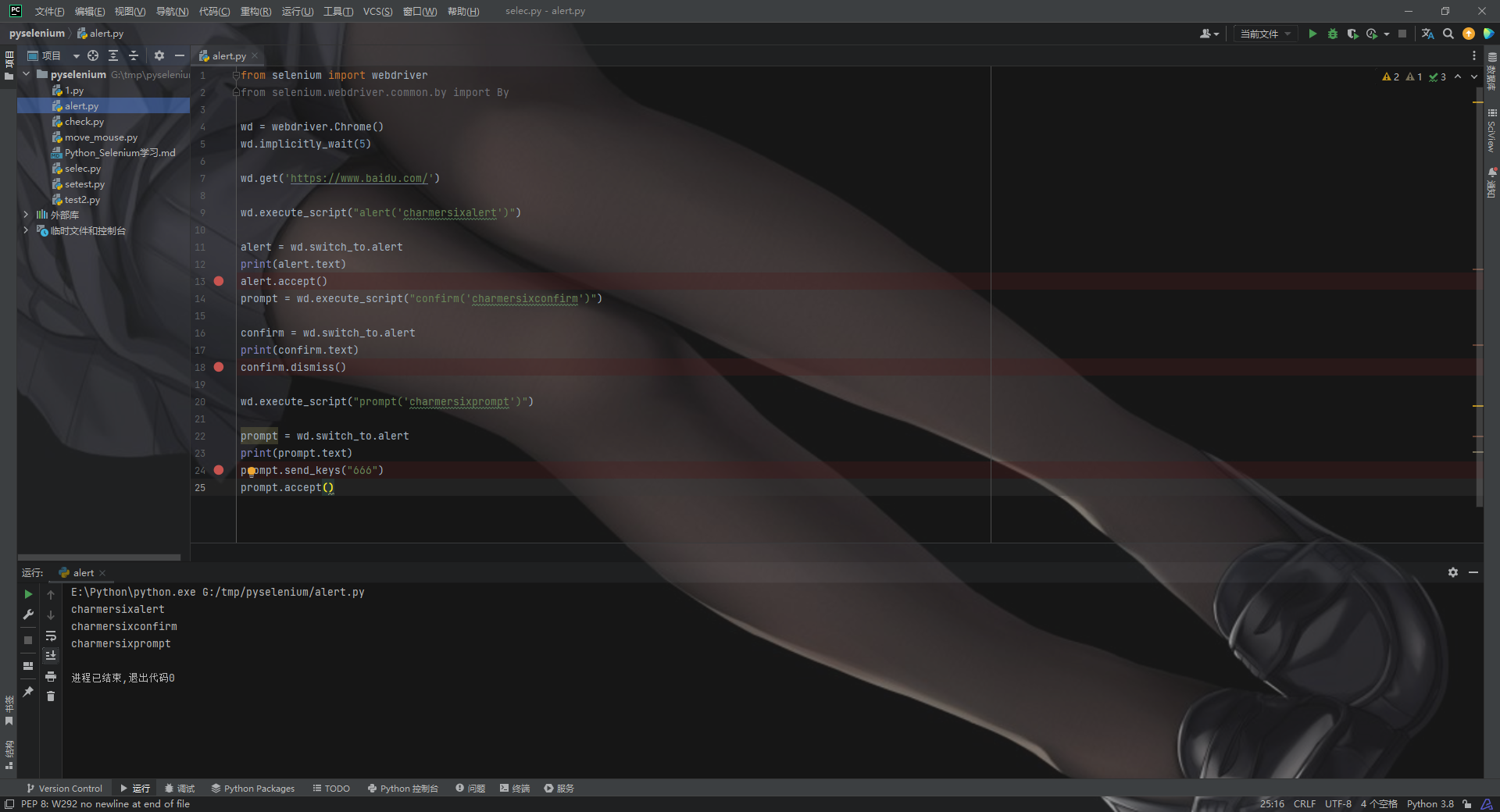
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://www.baidu.com/')
wd.execute_script("alert('charmersixalert')")
alert = wd.switch_to.alert
print(alert.text)
alert.accept()
prompt = wd.execute_script("confirm('charmersixconfirm')")
confirm = wd.switch_to.alert
print(confirm.text)
confirm.dismiss()
wd.execute_script("prompt('charmersixprompt')")
prompt = wd.switch_to.alert
print(prompt.text)
prompt.send_keys("666")
prompt.accept()
获取窗口大小
wd.get_window_size()
改变窗口大小
wd.set_window_size(x, y)
获取当前窗口标题
wd.title
获取当前窗口的url地址
wd.current_url
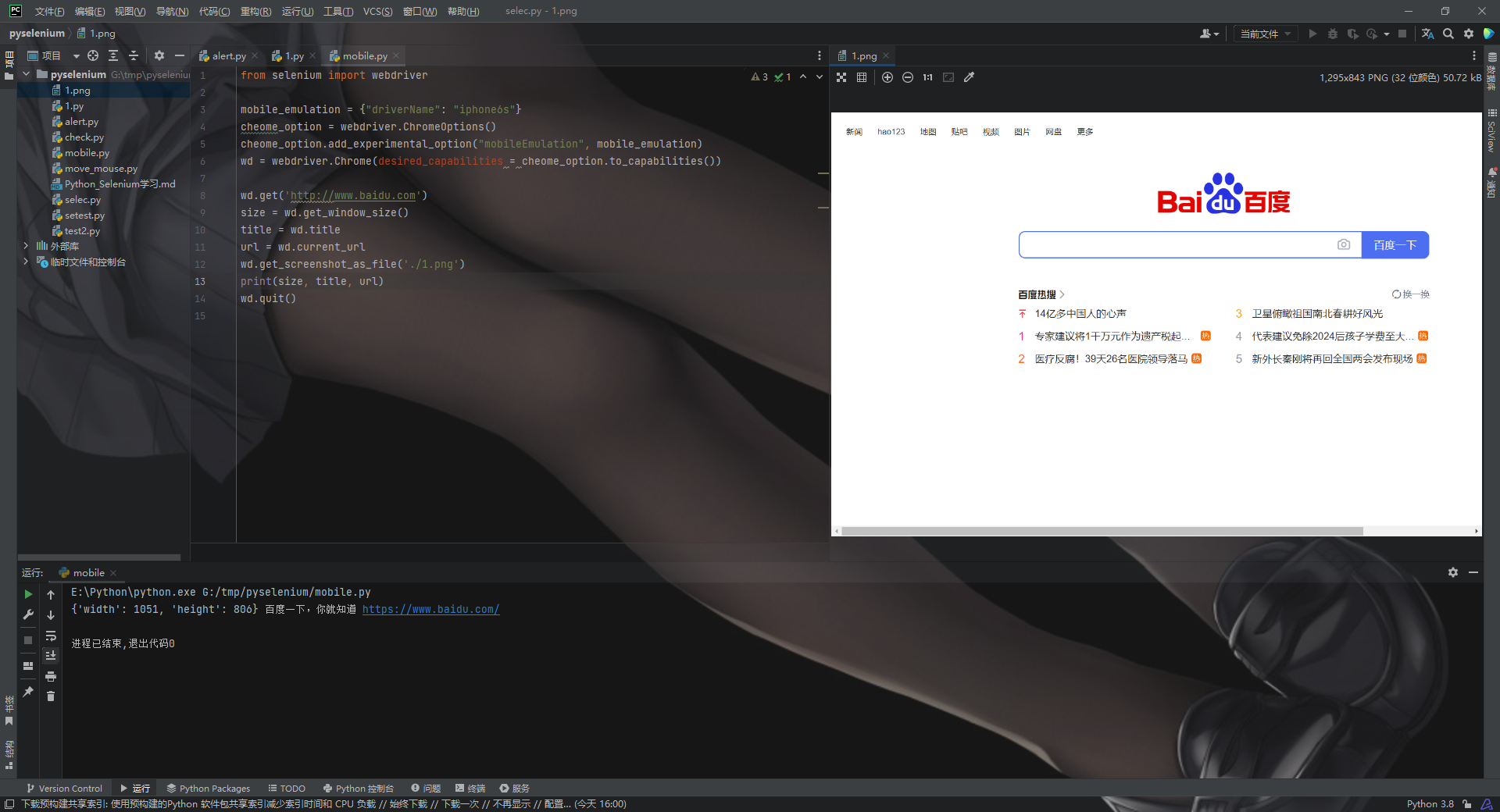
在做自动化测试的时候, 我们有时候需要截屏方便人工核查或者方便debug, 这时候我们可以用get_screenshot_as_file方法来截屏并保存
wd.get_screenshot_as_file('./1.png')
可以通过desired_capabilities参数, 指定以手机模式打开chrome浏览器
这里我们统一实验一下上述代码
from selenium import webdriver
mobile_emulation = {"driverName": "iphone6s"}
cheome_option = webdriver.ChromeOptions()
cheome_option.add_experimental_option("mobileEmulation", mobile_emulation)
wd = webdriver.Chrome(desired_capabilities = cheome_option.to_capabilities())
wd.get('http://www.baidu.com')
size = wd.get_window_size()
title = wd.title
url = wd.current_url
wd.get_screenshot_as_file('./1.png')
print(size, title, url)
wd.quit()
通常, 网站页面上传文件的功能, 是通过type属性为file的HTML input元素实现的, 我们想要自动化上传文件, 只需要定位到input元素, 然后通过send_keys方法传入要上传的文件路径即可
ele = wd.find_element(By.CSS_SELECTOR, 'input[type=file]')
# 先定位到上传文件的 input 元素
ele.send_keys(r'h:\1.png')
# 调用send_keys方法
如果需要多次上传, 则多次调用即可, 但是,有的网页上传,是没有 file 类型 的 input 元素的。就需要再自己分析
如果是Windows上的自动化,可以采用 Windows 平台专用的方法:
确保 pywin32 已经安装,然后参考如下示例代码
# 找到点击上传的元素,点击
driver.find_element(By.CSS_SELECTOR, '.dropzone').click()
sleep(2) # 等待上传选择文件对话框打开
# 直接发送键盘消息给 当前应用程序,
# 前提是浏览器必须是当前应用
import win32com.client
shell = win32com.client.Dispatch("WScript.Shell")
# 输入文件路径,最后的'\n',表示回车确定,也可能时 '\r' 或者 '\r\n'
shell.Sendkeys(r"h:\a2.png" + '\n')
sleep(1)
这段代码是使用Python中的Selenium库,模拟用户上传文件的操作。下面是逐行解释:
driver.find_element(By.CSS_SELECTOR, '.dropzone').click(): 这行代码使用Selenium库的find_element方法根据CSS选择器定位页面上class为dropzone的元素,然后使用click方法模拟用户点击该元素,以此触发文件上传的功能。sleep(2): 这行代码使用Python标准库的time模块中的sleep函数,让程序等待2秒钟,等待上传选择文件对话框打开。import win32com.client: 这行代码导入win32com模块的client子模块,用于调用Windows系统的COM接口。shell = win32com.client.Dispatch("WScript.Shell"): 这行代码使用win32com模块的Dispatch函数创建一个名为shell的COM对象,该对象表示Windows系统中的Shell应用程序。shell.Sendkeys(r"h:\a2.png" + '\n'): 这行代码使用shell对象的Sendkeys方法,向当前应用程序发送一个包含文件路径和回车键的键盘消息。其中r"h:\a2.png"是要上传的文件路径,'\n'表示回车键。由于该函数的实现需要通过Windows的COM接口与应用程序交互,因此该函数的执行结果实际上是模拟用户在应用程序中按下了对应的按键。sleep(1): 这行代码使用time模块的sleep函数,让程序等待1秒钟,确保文件上传完成。
Xpath选择器
有些场景用css选择web元素很麻烦, 然而xpath比较方便
绝对路径选择
相当于css选择器的>
elements = driver.find_elements(By.XPATH, "/html/body/div")
elements = driver.find_elements(By.CSS_SELECTOR, "html>body>div")
相对路径选择
相当于css选择器中的
elements = driver.find_elements(By.XPATH, "//div//p")
elements = driver.find_elements(By.CSS_SELECTOR,"div p")
如果要选择所有div节点的所有直接子节点,可以使用表达式 //div/*
* 是一个通配符,对应任意节点名的元素,等价于CSS选择器 div > *
根据属性选择
Xpath可以根据属性来选择元素, 大致格式是[@属性名='属性值']
这里属性值可以为空
- 属性名前面要有@
- 属性值要有引号, 单双无所谓
但是xpath与css不同的是, xpath选择时, 必须要有标签名, 但是标签名可以用*通配
例如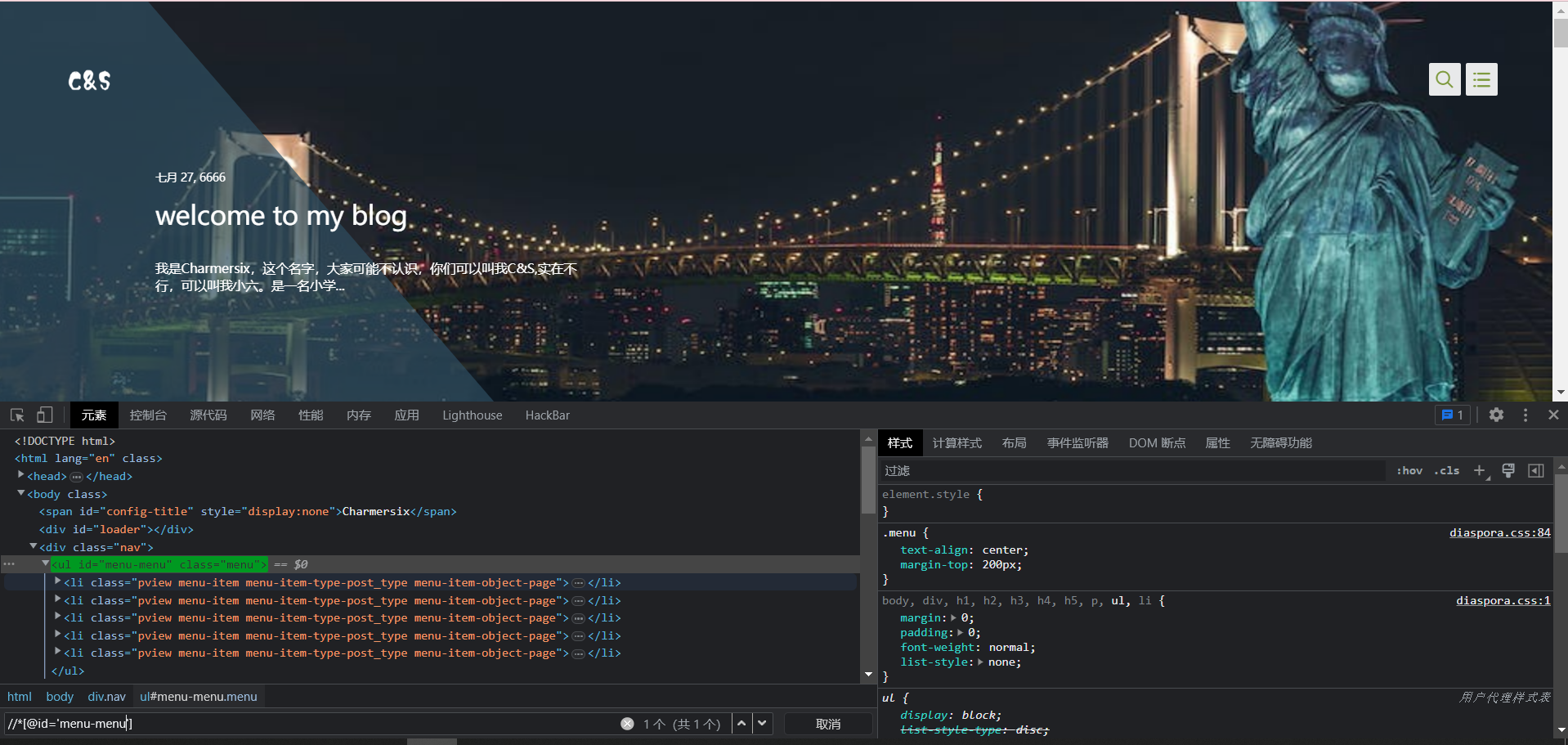
属性值包含字符串
要选择 style属性值 包含 color 字符串的 页面元素 ,可以这样 //*[contains(@style,'color')]
要选择 style属性值 以 color 字符串 开头 的 页面元素 ,可以这样 //*[starts-with(@style,'color')]
要选择 style属性值 以 某个 字符串 结尾 的 页面元素 ,大家可以推测是 //*[ends-with(@style,'color')], 但是,很遗憾,这是xpath 2.0 的语法 ,目前浏览器都不支持
按次序选择
xpath可以直接在[]中使用数字表示次序
某类型的第几个元素
//p[2]
选择的是p类型的第二个子元素, 相当于css选择器的
:nth-of-type()
第几个子元素的话, 可以用通配符*来代替类型
//*[2]
某类型的倒数第几个子元素
使用last()-数字
倒数第一个
PYTHON//p[last()]倒数第二个
PYTHON//p[last()-1]
使用position()
- 比如说
option类型的前两个元素
//option[position()<=2]
//option[position()<3]
- 选择class属性为multi_choice的前3个子元素
//*[@class='multi_choice']/*[position()<=3]
- 选择class属性为multi_choice的后3个子元素
//*[@class='multi_choice']/*[position()>=last()-2]
组选择和兄弟节点
css有组选择, 可以同时多个表达式, 多个表达式选择的结果都是要选择的元素
css组选择, 表达式之间用,隔开
xpath组选择, 表达式用|隔开
比如,要选所有的option元素 和所有的 h4 元素,可以使用
//option | //h4
等同于css选择器的
option , h4
再比如,要选所有的 class 为 single_choice 和 class 为 multi_choice 的元素,可以使用
//*[@class='single_choice'] | //*[@class='multi_choice']
等同于css选择器
.single_choice , .multi_choice
选择父节点
xpath可以选择父节点, 而css没有这一功能, 父节点用/..表示
比如,要选择 id 为 china 的节点的父节点,可以这样写 //*[@id='china']/..
当某个元素没有特征可以直接选择,但是它有子节点有特征, 就可以采用这种方法,先选择子节点,再指定父节点。
兄弟节点选择
类似于前面css选择器的~
这里xpath用following-sibling::
比如,要选择 class 为 single_choice 的元素的所有后续兄弟节点
//*[@class='single_choice']/following-sibling::*
等同于CSS选择器
.single_choice ~ *
如果,要选择后续节点中的div节点, 就应该这样写
//*[@class='single_choice']/following-sibling::div
xpath还可以选择前面的兄弟节点, 使用preceding-sibling::
比如,要选择 class 为 single_choice 的元素的所有前面的兄弟节点
//*[@class='single_choice']/preceding-sibling::*
而CSS选择器目前还没有方法选择前面的 兄弟节点
想了解更多可以关注一下xapth手册
selenium 注意点
我们来看一个例子
我们的代码:
- 先选择示例网页中,id是china的元素
- 然后通过这个元素的WebElement对象,使用find_elements_by_xpath,选择里面的p元素,
# 先寻找id是china的元素
china = wd.find_element(By.ID, 'china')
# 再选择该元素内部的p元素
elements = china.find_elements(By.XPATH, '//p')
# 打印结果
for element in elements:
print('----------------')
print(element.get_attribute('outerHTML'))
运行发现,打印的 不仅仅是 china内部的p元素, 而是所有的p元素。
要在某个元素内部使用xpath选择元素, 需要 在xpath表达式最前面加个点 。
elements = china.find_elements(By.XPATH, './/p')
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK