

向量嵌入:AutoGPT的幻觉解法?
source link: https://blog.csdn.net/OneFlow_Official/article/details/130377304
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

向量嵌入:AutoGPT的幻觉解法?

来源|Eye on AI
OneFlow编译
翻译|贾川、杨婷、徐佳渝
“一本正经胡说八道”的幻觉问题是ChatGPT等大型语言模型(LLM)亟需解决的通病。虽然通过人类反馈的强化学习(RLHF),可以让模型对错误的输出结果进行调整,但在效率和成本上不占优势,况且仅通过RLHF并不能彻底解决问题,由此也限制了模型的实用性。
由于大型语言模型的本质是基于语言的“统计概率”,幻觉现象表明,LLM并没有真正理解它所生成的内容,也不具备对错的概念。
此前,OpenAI首席科学家Ilya Sutskever谈到,他希望通过改进强化学习反馈步骤来阻止神经网络产生“幻觉”,他对解决这一问题非常自信,但只说了一句“让我们拭目以待”。
不过,向量嵌入(vector embeddings)看上去是解决这一挑战的更为简单有效的方法,它可以为LLM创建一个长期记忆的数据库。通过将权威、可信的信息转换为向量,并将它们加载到向量数据库中,数据库能为LLM提供可靠的信息源,从而减少模型产生幻觉的可能性。
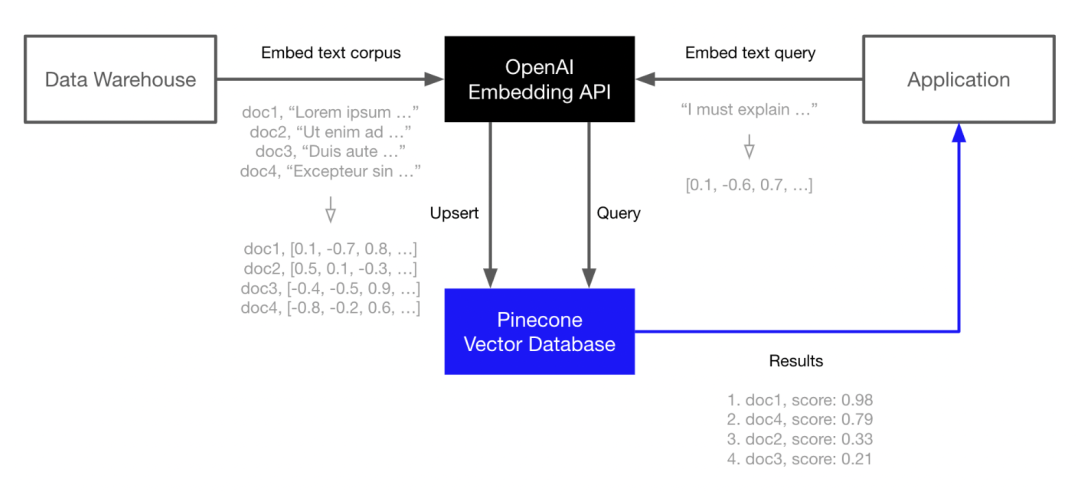
最近,爆火的AutoGPT就集成了向量数据库Pinecone,可以让它进行长期内存存储,支持上下文保存并改进决策。
Pinecone是OpenAI、Cohere等LLM生成商的合作方。现在,用户可以通过OpenAI的Embedding API生成语言嵌入,然后在Pinecone中为这些嵌入建立索引,以实现快速且可扩展的向量搜索。
“嵌入(embedding)”一词最初由Yoshua Bengio于2003年提出。捷克计算机科学家Tomas Mikolov在2013年提出了文本向量表示的工具包word2vec,可用于下游深度学习任务。
Pinecone创始人Edo Liberty在亚马逊工作期间就负责向量嵌入,在离开亚马逊后开始研发Pinecone向量数据库。他是耶鲁大学计算机科学博士学位,曾担任雅虎的技术总监,并负责管理AI实验室。随后在AWS构建了包括SageMaker机器学习平台和服务。2019年年中,他意识到大型语言模型具有特殊意义,通过深度学习模型表示数据的新方法将成为数据和AI的基本组成部分。
近期,在Eye on AI播客的主持人Craig S. Smith与Edo Liberty的对话中,他介绍了如何通过向量嵌入解决LLM的幻觉问题,并分享了技术细节和构建流程。
(以下内容经授权后由OneFlow编译发布,译文转载请联系OneFlow获得授权。原文: https://www.eye-on.ai/podcast-117;sponsored by Netsuite,netsuite.com/eyeonai)
1
“幻觉”的解决方法
CRAIG:什么是Pinecone?
EDO:Pinecone是一个向量数据库,但其并未采用结构或语法树等文本表示方式,而是使用一种数值形式的内部表示方式,这种方式被用于深度学习模型、语言模型或聊天引擎等文本处理任务中。
机器学习模型是一种数值引擎,处理的是数字对象,因此唯一能够表示数据的方式就是使用数字列表,这些列表被称为向量或嵌入。如果你想为深度学习模型提供长期记忆(long-term memory)和上下文(context),真正记住事物并了解世界的能力,就需要使用这些数值对象来表示数据。
但存储层、查询语言、访问模式以及我们想从数据库得到的一切对这些对象并不适用,你需要特定的硬件和软件才能实现。而Pinecone提供的服务就可以大规模地实现这一点。比如,如果你想增强ChatGPT的上下文能力,以便获得更好的回答,就可以将自己的数据存储在一个特定的数据库中。这些数据可以是用户手册、历史记录、图片、文本、Jira票据或邮件等。
Pinecone现在还发布了自己的检索引擎插件,用户可以将这些东西插入到底层,让ChatGPT实时搜索Pinecone,从而获得更准确的答案,并且不需要进行太多的连线设置。
Pinecone的优点是你不必成为机器学习专家,只需按教程复制粘贴代码,进行调整来训练模型,无需与我们联系,也无需向我们支付费用。
CRAIG:这有助于解决ChatGPT的幻觉问题吗?
EDO:完全可以。如果现在问ChatGPT如何关闭C70X车型自动反向刹车灯,它会给出一个非常地道、连贯的答案,但这其实只是它的幻觉。它回答得非常自信,但毫无价值。在说明如何解决幻觉问题之前,我想先强调一下这项技术本身的突破。
我并不是想要贬低语言模型。对于从事该领域15-20年的人来说,这项技术无疑是很令人震惊的。ChatGPT在语言的连贯性、组合方式以及所吸纳的数据量方面都让人眼前一亮,但就因幻觉的存在,其价值大打折扣。如果将沃尔沃的用户手册作为向量嵌入输入到Pinecone中,让ChatGPT实时搜索并获取正确的上下文来回答问题,那么ChatGPT就能得到正确的答案。
CRAIG:Ilya Sutskever关注点是用人类反馈的强化学习(RLHF)方式来训练模型,以避免幻觉。但这种方法的效率似乎不是很高,很多人对模型能否学会贴合现实也存在疑虑。我还曾和Yann LeCun探讨过建立一个世界模型(world model),以供语言模型参考。而你所讲的是通过Pinecone来构建一个特定领域的“世界模型”。
EDO:比如学医,人们学习的是一整个知识体系,而不是医学英语。实际上,在进入医学院前人们就已经掌握了英语,因此我们学到的是一些知识、记忆和事实,现在你可以将这些知识清晰地表达出来。你学到的不是将自然语言模型微调到医学领域,而是将知识注入到语言中。
其实,将OpenAI和Pinecone配对也与之类似。我们把数据和知识存储到Pinecone中,这些数据和知识可以是任何领域的专业知识,比如Jira票证、销售电话等等。然后语言模型就可以把这些知识转化成语言,并进行总结、理解问题等。
这些都是完全不同的功能,所以不应该使用相同的机制。比如“理解你说的话”和“确定你说的内容是否正确”就是两个完全不同的机制。前者关于语言处理,后者则关于记忆。
比如我说可以用木棍推动某些东西,也可以说用绳子推动某些东西。但事实上,我们只能能用绳子拉东西,而不能推东西。这是世界知识的一部分,也是记忆的一部分,既需要理解,也需要判断。人们会以一种现实可行的方式谈论世界,因此不会使用“用绳子推东西”这样不切实际的词汇来表达。
所以,如果训练的语言模型足够大,它就能像正常人类一样来谈论世界。但这并不代表模型真的就理解任何东西,也有可能会像《猫鼠游戏》中的主人公一样来“冒充”医生。比如,如果你只是在医院待了五年,可能会接触到很多专业术语,因此在谈论相关知识和技能时,你就像一个经验丰富的医生,但实际上并没有任何实际经验。
有些所谓的“幻觉解决方案”就像这样,它们似乎可以让人看起来拥有某种技能或知识,但实际上并没有真正理解这些内容。对我来说,这就是幻觉。就像是听医生讲述了很多医学术语,我们可以用英语说出这些术语,但却根本不懂医学。
CRAIG:所以增加记忆能力就是Pinecone目前正在做的事情。是否有其他用于增加记忆或领域知识的机制呢?据我所知,可以用无监督方式预训练大型语言模型,但最后会有一个监督层训练。我们能否在监督训练时将领域知识给到大型语言模型呢?
EDO:我会区分能够做的事和经常做的事。我们可以做很多事,并用各种方式进行训练,且已做过大量尝试。不过在我看来,AI领域真正值得兴奋的点是,AI终于真正走进了人们的生活。现在普通工程师、用户等终于能够实际利用AI,并在AI的基础上构建应用。
就拿Pinecone和OpenAI的结合来说,我们无需重新训练或发明任何东西,也无需微调,更不必收集数据标签。基本上只需用向量嵌入的形式将数据输入Pinecone就可以,网上有很多类似范例。我们可以实时向OpenAI提问,让它在Pinecone上查找相关信息。
比如,我是一个销售员,并且已经将所有的销售对话输入了Pinecone。那么我可以进行提问,“我是否给某个顾客打折?如果打折了,折扣又是多少?”现在我们可以用OpenAI或其他大型语言模型供应商,基本上我们只需输入查询,找到与答案相关的对话部分,就能得到答案,并且还能获得明确起因。比如给顾客发的有关折扣信息的邮件,内容显示打了八折等等。
总之,我们不需要再重新训练任何东西,只需在大型语言模型中输入它所需的上下文,当我们调用聊天API时,它们会包含查询(即提问),我们也能提供与答案相关的上下文,以便获取更多信息。
如果我们能提供正确的上下文,就可以得到更好的答案。就像对他人提问一样,比如问销售员某个问题,如果他们知道问题的相关信息,就能进行整合,从而给出回答;如果不知道相关信息,人类会如实回答不知道,但现在聊天机器人却可能编造答案。
2
如何将信息转换为向量嵌入
CRAIG:OpenAI曾表示ChatGPT会应用在医学领域,但目前还不太可靠。如果没有医生审核,我们就不能依赖ChatGPT给出的任何医学建议。但如果能让大型语言模型参考可信的医疗文件或教科书,那么不需要医生,直接参考大型语言模型给出的答案了。所以,如何才能将实用医学文本导入Pinecone呢?
EDO:首先,我不建议就医学问题参考大型语言模型给出的答案,尤其是当自身或所爱之人面临健康危机时。但我也理解想要勇于尝试的想法,毕竟有总比没有好,相比没有医生,技艺不精的医生也并非不能接受。总之,我并不提倡这一行为。
其实要做到这一点非常简单。我们可以获取医学领域教科书或医学笔记,将它们分成句子或段落,然后将分好的句子、段落喂入嵌入模型,这些语言模型以深度学习模型表示文本的方式来表示语言,这种数字表示形式称为向量或嵌入。
然后将它们保存到Pinecone,保存的时候,我们可以将有用的资料一起保存,比如文本来源,或者源文本,但数字表示才是可操作部分。在实际查询的时候,比如我们有一些症状或者医学问题时,基本上就是在做相同的事。你可以嵌入问题、搜索嵌入、要求提供相关文件或者与查询主题相同或相似的内容。查询以后,比如我们得到了一百个文件或一百个段落句子,将它们作为上下文添加到查询中,输入聊天引擎,之后就可以对聊天引擎说“这些是我的症状,我想了解这些方面的信息”。
假如搜出来50个与答案相关的不同来源数据,我们可以在短时间内将这些数据整合起来,就像旧金山、纽约等地举办的黑客马拉松那样,参赛人员可以在一天内整合这些信息。要整合这些信息其实非常容易,因为我们不用重新训练任何东西,一切都可以交给托管服务,不必启动硬件,也不必处理大量废话,只需调用API,让它们处理并调整数据。这样一天内就能完成一项大工程。
CRAIG:我对pipeline比较好奇,假如我想把一本权威历史书籍喂入Pinecone,应该怎么做?如何将信息转换为向量嵌入?
EDO:首先,必须将文本数据化,你可以通过扫描或其他方式,也可以直接用PDF、word等格式的数据文本。然后我们需要将这些文本拆分成更小的部分,比如句子、段落等连贯的形式。也就是不能直接喂入一整本书或者只喂入一两个单词,而是有意义、人类能够阅读且逻辑连贯的精炼内容。
在完成文本拆分以后,就可以将其嵌入到深度学习模型中。此外,线上有很多免费的文本资源可以使用,人们只需简单编写几行Python代码,便可以将这些文本导入到计算机中,然后使用这些资源进行训练或者你也可以使用API在云上进行训练。
如此一来,你会得到模型返回的向量嵌入以及包含大量成百上千数字的列表。随后,再将向量传递给Pincone数据库,并告诉它哪些是有用信息,比如历史书上拿破仑入侵的介绍在第712页,这个过程等同于建立了自己的数据库。现在,你可以在此基础上构建机器模型,并将该历史书内容用作模型对话的知识源。
CRAIG:Pincone是否能提供前端来完成所有操作?或者说用户需提前备好向量嵌入将其融入Pincone?
EDO:目前,我们公司只负责数据库,因此选择何种机器学习模型或语言模型的决定权仍在用户手中,我们只提供最便利的工具,以便用户能毫不费力找到该模型。我们与OpenAI、Hugging Face、Cohere、Google、Amazon和Azure等公司有合作,共同构建新型语言模型。约有50或60家初创公司获得我们的支持,旨在构建更好的语言模型。
CRAIG:如果Pinecone将信息转换为向量嵌入,是否涉及版权问题?
EDO:客户使用Pinecone的方式类似于MongoDB、Elasticsearch、Redis、Dynamo DB、Spanner等其他数据库服务。作为客户的数据基础设施,我们通过Pinecone来存储和管理客户数据,但作为服务提供商,我们不会接触、使用、分享这些数据,也不会用作模型训练。
人们之所以更倾向于使用类似向量数据库的工具来创建上下文,而不是重新训练或优化模型,最实际的原因是前者可以删除数据。举个例子,若需要删除某些数据以满足GDPR相关规定,你可以说:“针对已有数据,进行明确操作,即删除数据点776。”随后便可以执行删除操作,实现数据点永久删除。
若将这些数据点输入优化后的模型,并尝试利用这些数据点来改善任务的执行,那么这些数据点就会保留在模型中,因为不存在可以将其删除的机制。
CRAIG:你们目前遇到的挑战是什么?
EDO:最大挑战是启动足够的硬件来支持所有训练需求,这也几乎是我们核心工程师团队每天都需要解决的问题。当前的硬件使用需求巨大,而ChatGPT的出现,使其需求量更是猛增。
其他人都在看
欢迎Star、试用OneFlow: github.com/Oneflow-Inc/oneflow/![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK