

A brief history of LLaMA models
source link: https://agi-sphere.com/llama-models/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
A brief history of LLaMA models

The LLaMA base model was released in February 2023. Now we have seen a handful of new fine-tuned LLaMA models released.
It is literally a brief history, but a lot has happened for sure. So let’s do a brief review.
I will cover some developments in models and briefly touch on tools.
- LLaMA base model
- Alpaca model
- Vicuna model
- Koala model
- GPT4-x-Alpaca model
- WizardLM model
- Software to run LLaMA models locally
Below is an overview of the models.
| Model | Size | Training data |
|---|---|---|
| LLaMA (base model) | 7B, 13B, 33B, 65B | Various |
| Alpaca | 7B, 13B | 52k GPT-3 instructions |
| Vicuna | 7B, 13B | 70k ChatGPT conversations |
| Koala-distill | 7B, 13B | 117k cleaned ChatGPT conversations |
| GPT4-x-Alpaca | 13B | 20k GPT4 instructions |
| WizardML | 7B | 70k instructions synthesized with ChatGPT/GPT-3 |
Model comparison
LLaMA base model
LLaMA (Large Language Model Meta AI) is a language model released by Meta (Facebook). It is Meta’s answer to OpenAI’s GPT models.
Like GPT, LLaMA is intended to be a general-purpose foundational model suitable for further fine-tuning.
LLaMA models have the following variants
- 7B parameters
- 13B parameters
- 33B parameters
- 65B parameters
The larger the number of parameters, the more powerful the model, but it also takes up more resources to run.
Accessibility
Unlike GPT, LLaMA is an open-source model. You can download, study and run them locally. Officially, you will need to use a Google form to request the model weights.
However, the models were leaked on Torrent in March 2023, less than a month after its release.
Objective
The objective of LLaMA is to build the best-performing model for a given inference budget, for example, running on an NVIDIA 3090 using less than 10GB VRAM.
Model architecture
LLaMA is a transformer model similar to GPT with the following modifications.
- Normalize the input of each transformer sub-layer to improve training stability.
- Use SwiGLU instead of ReLU to improve performance.
- Use rotary embedding instead of absolute positioning to improve performance.
The table below summarizes the model parameters.
| Parameters | Layers | Attention heads | Embedding dimension | |
| 7B | 6.7B | 32 | 32 | 4,096 |
| 13B | 13B | 40 | 40 | 5,120 |
| 33B | 33B | 60 | 52 | 6,656 |
| 65B | 65B | 80 | 64 | 8,192 |
Model parameters
For reference, GPT-3 has 175B parameters. LLaMA models are small.
Training
The pre-training data used in LLaMA are
- English CommonCrawl (67%): Removed non-English text and duplicated content. Only includes pages used as references in Wikipedia.
- C4 (15%): A cleaned version of CommonCrawl. The same filters were applied.
- Github (4.5%): Public GitHub dataset available on Google BigQuery.
- Wikipedia (4.5%): From June-August 2022 period covering 20 languages.
- Gutenberg and Books3 (4.5%): Both are book datasets.
- ArXiv (45%): Scientific data.
- StackExchange (2%): High-quality Q&As covering science and engineering topics.
The tokenizer is with byte-pair encoding using SentencePiece.
The training data has 1.4T tokens.
Performance
They evaluated the models with tasks such as common sense reasoning, reading comprehension, and code generation.
Summary of performance:
- Larger is better: Larger models perform better in most tasks.
- More examples in the prompt are better: Give 5 examples to LLaMA 7B model is almost as good as not giving any to a 65B model in Natural Questions tasks.
- Smaller performant model. LLaMA 13B’s performance is similar to GPT-3, despite 10 times smaller. (13B vs 175B parameters)
- LLaMA is not very good at quantitative reasoning, especially the smaller 7B and 13B models.
- LLaMA is not tuned for instruction following like ChatGPT. However, the 65B model can follow basic instructions. We will wait for Alpaca (not for long).
Model size comparison
How much do you gain by using a bigger LLaMA model? The following table summarizes the performance of tasks in different categories. They are calculated based on the scores provided in the research article, assuming linear scales.
| Average | Common sense reasoning | Natural Questions | Reading comprehension | TriviaQA | Quantitative reasoning | Code generation | Multitask language understanding | |
|---|---|---|---|---|---|---|---|---|
| 7B | 65% | 92% | 65% | 90% | 76% | 27% | 53% | 56% |
| 13B | 76% | 95% | 80% | 91% | 86% | 39% | 69% | 74% |
| 33B | 91% | 99% | 95% | 94% | 96% | 72% | 89% | 91% |
| 65B | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
Performance of LLaMA models (normalized to 65B as 100%).
Is it worth using a bigger model? You can expect a ~50% generic improvement when switching from the 7B to the 65B model.
But it also depends on what you use the models for. You will only see a small gain for common sense reasoning and reading comprehension tasks. You will see a big gain for code generation and technical reading tasks.
Summary for LLaMA
The take-home message in this study is small models can perform well if you train them with enough data. This opens up the possibility of running a “local ChatGPT” on a PC.
But the LLaMA base model was not trained to follow instructions. This is saved for later development.
To sum up, LLaMA is designed to be a base model for further fine-tuning. Its advantages are
- Small size
- Performant – thanks to extensive training
- Open source
Alpaca model
Alpaca is a fine-tuned LLaMA model, meaning that the model architecture is the same, but the weights are slightly different. It is aimed at resolving the lack of instruction-following capability of LLaMA models.
It behaves like ChatGPT and can follow conversations and instructions.
The 7B and 13B Alpaca models are available.
Training
It was trained to follow instructions like ChatGPT.
The authors first generate the training data using OpenAI’s GPT-3, then convert them to 52k instruction-following conversational data using the Self-Instruct pipeline.

Training pipeline of Alpaca (Source: Alpaca model page)
As a result, Alpaca is fine-tuned to respond to conversations like ChatGPT.
Performance
A blinded evaluation for instruction-following ability performed by some of the authors ranked the responses of Alpaca 7B and GPT-3 (text-davinci-003 specifically, which is also trained with instructions) roughly equally.
This is a surprising result because Alpaca is 26 times smaller than GPT-3.
Of course, this is just a narrow aspect of performance. It doesn’t mean Alpaca performs equally with GPT-3 in other areas like code generation and scientific knowledge, which were not tested in the study.
Summary for Alpaca
Alpaca is a nice first step in fine-tuning the LLaMA model. As we see in the next section, it is outperformed by a similar fine-tuning effort, Vicuna.
Vicuna model
Vicuna is trained by fine-tuning the LLaMA base models on user-shared conversations collected from ShareGPT.com. So it is basically fine-tuned with ChatGPT conversations.
It comes in two sizes: 7B and 13B.
Training
The model was fine-tuned by an academic team from UC Berkeley, CMU, Stanford, and UC San Diego.
It was trained with user-contributed ChatGPT conversations. So you can expect its behavior mimics ChatGPT. Precisely, it is trained with 70,000 ChatGPT conversations users shared on ShareGPT.com.
It only costed $140 to train the 7B model and $300 to train the 13B model.
Performance
How good is Vicuna? According to their website, the output quality (as judged by GPT-4…) is about 90% of ChatGPT, making it the best language model you can run locally.

Response quality as judged by GPT-4. (from Vicuna site)
The authors used an interesting method to evaluate the model’s performance: Using GPT-4 as the judge. They asked GPT-4 to generate some challenging questions and let Vicuna and some other best language models answer them.
They then ask GPT-4 to evaluate the quality of the answers in different aspects, such as helpfulness and accuracy.
Here’s the result for comparing LLaMA, Alpaca, Bard, and ChatGPT. In the eyes of GPT-4, Vicuna is almost as good as ChatGPT, beating LLaMA and Alpaca by a large margin.
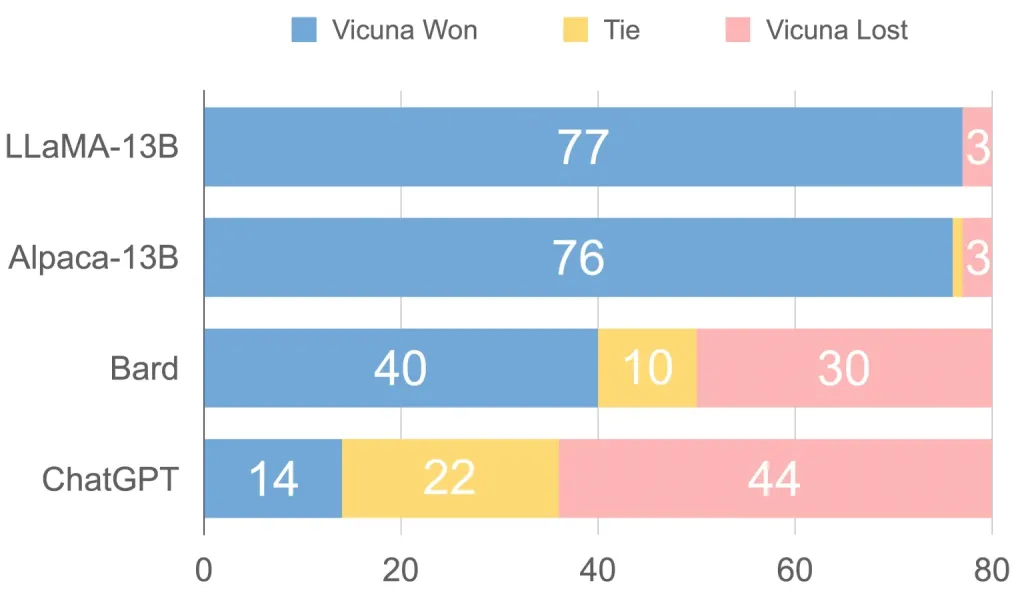
GPT-4’s judgment. (source: Vicuna model page)
Summary
The Vicuna model is considered to be one of the best LLaMA models that you can run locally. But I won’t be surprised if things change in the coming weeks.
Koala
- Koala model page
- Release date: April 2023
Koala is a LLaMA 7B and 13B models fine-tuned with publicly available dialog data by an academic team at UC Berkeley.
Training
The training data includes filtered data from multiple datasets.
They trained two models
- Koala-All: Used all datasets
- Koala-Distill: Used the first two datasets (i.e., data distilled from ChatGPT)
Performance
They evaluated the performance of Koala-All and Koala-Distill by comparing them with Alpaca and ChatGPT. 100 evaluators from Amazon Mechanical Turk judged the responses of these models from the same prompts.
The results are
- Koala-All is better than Alpaca but worse than ChatGPT.
- Koala-Distill is slightly better than Koala-All. — This is surprising as Koala-All was fine-tuned with more data.
Summary
The take-home message is quality of the data is more important than quantity. Koala-Distll fine-tuned with ChatGPT data alone outperforms Koala-All trained with additional data.
Going forward, finding or generating high-quality data to fine-tune LLaMA models is going to be important.
GPT4-x-Alpaca
- HuggingFace page
- Release date: April 2023
GPT4-x-Alpaca is a LLaMA 13B model fine-tuned with a collection of GPT4 conversations, GPTeacher. There’s not a lot of information on its training and performance.
Below are some community efforts to evaluate the model
WizardLM
WizardLM is a fine-tuned 7B LLaMA model. It was fine-tuned with a large amount of instruction-following conversations with varying difficulties. The novelty of this model is using an LLM to generate instructions automatically.
Training
The WizardLM model was trained with 70k computer-generated instructions with a new method called Evol-Instruct. The method produces instructions with varying levels of difficulty.
Evol-Instruct expands a prompt with these five operations
- Add constraints
- Deepening
- Concretizing
- Increase reasoning steps
- Complicate input
These operations were applied sequentially to an initial instruction to make it more complex.
The responses were generated by an LLM.
Performance
The authors compared the performance of WizardLM with Alpaca 7B, Vicuna 7B, and ChatGPT. They recruited 10 people to judge the responses of WizardLM and other models in five aspects blindly: Relevance, knowledge, reasoning, calculation, and accuracy.
The authors conclude that:
- The instructions generated by Evol-Instruct are superior to ShareGPT (used by Vicuna).
- WizardLM significantly outperforms Alpca and Vicuna.
- ChatGPT is better overall, but WizardLM excels in high-complexity questions.

WizardLM excels in answering complex instructions. (Source: WizardLM paper)
The community generally agrees that WizardLM is the current state-of-the-art for 7B models.
Software tools
The development on the software engineering side is equally breathtaking. Currently, the two main ways to run LLaMA model on your PC are
- llama.cpp (for Mac or CPU only)
- Oobabooga text-generation-webui
llama.cpp
llama.cpp is written in C++ from the ground up. The goal is to enable running LLaMA models on Macbooks. It is optimized for Apple Silicon M1/M2.
It supports 4-bit quantization to reduce the resources needed for LLaMA models. These quantitation models reduce the storage and RAM usage of the models at the expense of a slight loss in quality.
A 7B model originally takes 13GB of disk space and RAM to load. It only takes about 4 GB after 4-bit quantization.
Due to its native Apple Silicon support, llama.cpp is an excellent choice for running LLaMA models on Mac M1/M2.
However, it only supports usage in a text terminal. Technically, you can use text-generation-webui as a GUI for llama.cpp, but as of writing, it could be a lot slower.
text-generation-webui
Oobabooga text-generation-webui is a GUI for using LLaMA models. It can be run on Windows, Linux and Mac.

You should go with this GUI if you have a GPU card on Windows or Linux.
Like llama.cpp, it supports 4-bit quantization (but in a different file format) for model size reduction.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK