

深入理解MySQL索引底层数据结构 - 京东云开发者
source link: https://www.cnblogs.com/Jcloud/p/17291778.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在日常工作中,我们会遇见一些慢SQL,在分析这些慢SQL时,我们通常会看下SQL的执行计划,验证SQL执行过程中有没有走索引。通常我们会调整一些查询条件,增加必要的索引,SQL执行效率就会提升几个数量级。我们有没有思考过,为什么加了索引就会能提高SQL的查询效率,为什么有时候加了索引SQL执行反而会没有变化,本文就从MySQL索引的底层数据结构和算法来进行详细分析。
2 索引数据结构对比
索引的定义:索引(Index)是帮助MySQL高效获取数据的排好序的数据结构。
索引中常见的数据结构有以下几种:
- Hash表
- B-Tree
- B+Tree
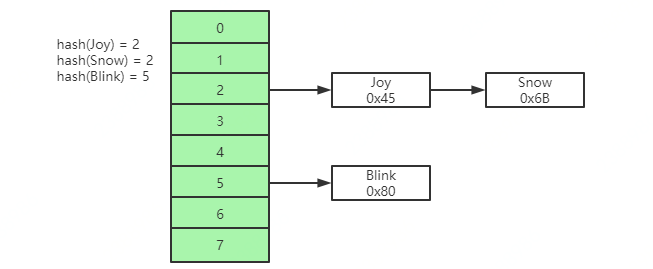
Hash表
通过索引的key进行一次hash计算,就可以快速获取磁盘文件指针,对于指定索引查找文件非常快,但是对于范围查找没法支持,有时候也会出现Hash冲突的情况。
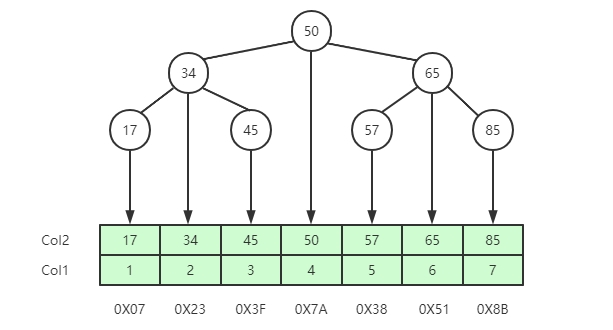
二叉树
二叉树的特点:左边子节点的数据小于父节点数据,右边子节点的数据大于父节点数据。如下图所示,如果col2是索引,查找索引为65的行元素,只需要查找两次,就可以获取到行元素所在的磁盘指针地址。
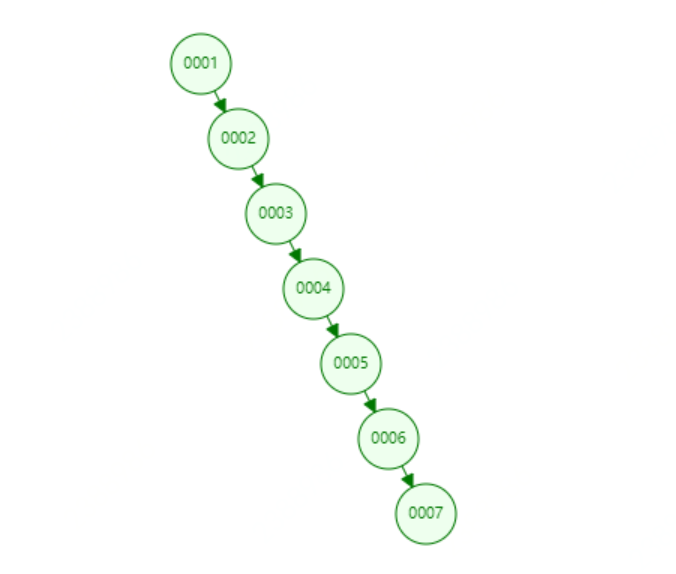
但如果是一个按照顺序递增的值,例如为col1建立索引,不再适合使用二叉树建立索引,因为此时使用二叉树建立索引将会变成一个链式索引,此时的索引结构如下图所示,如果查找6节点需要6次遍历才能找到。
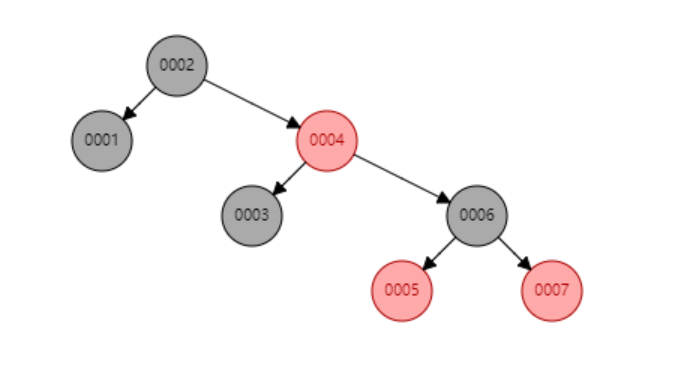
红黑树
红黑树是一种二叉平衡树,可以提高查询效率,此时若再查找6节点只需要遍历3次就能找到了。但红黑树也有缺点,当存储大数据量时,树的高度就会变的不可控, 数量越大,树的高度越高,查询的效率将会大大降低。
B-Tree
B-Tree是一种多路二叉树,所具有的特点:1 叶节点具有相同的深度,叶节点的指针为空;2 所有索引元素不重复;3 节点中的数据索引从左到右递增排列。
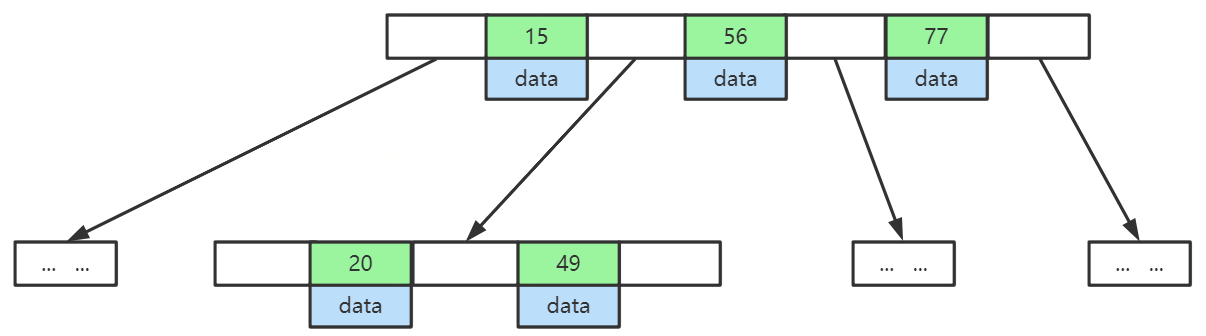
B+Tree
B+Tree是B-Tree的变种,所具有的特点:1 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引;2 叶子节点包含所有索引字段;3 叶子节点用指针连接,提高区间访问的性能。
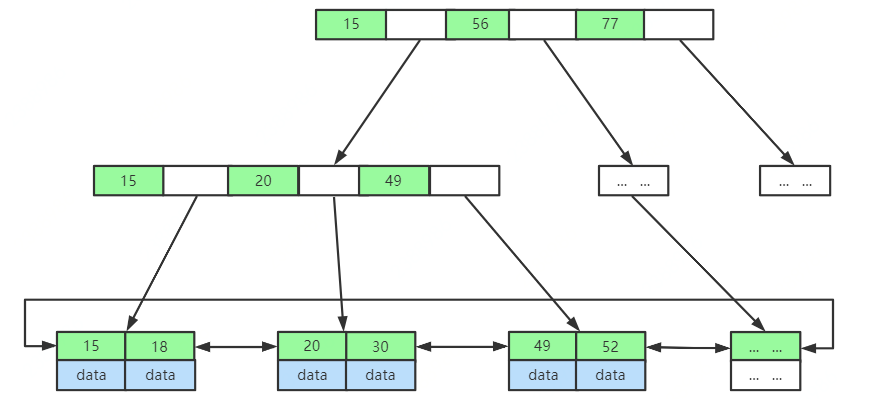
与红黑树相比,B-Tree和B+Tree两种数据结构都更加矮胖,存储相同数量级的索引数据时,层级更低。
B-Tree和B+Tree之间一个很大的不同,是B+Tree的节点上不储存value,只储存key,而叶子节点上储存了所有key-value集合,并且节点之间都是有序的。这样的好处是每一次磁盘IO能够读取的节点更多,也就是树的度(Max.Degree)可以设置的更大一些,因为每次磁盘IO读取的磁盘页数是一定的。例如,每次磁盘IO能够读取1页=4kb,那么省去value的情况下同样一页数据能够读取更多的key,这样就大大减少了磁盘的IO次数。
此外,B+Tree也是排好序的数据结构,数据库中><或者order by等都可以直接依赖这一特性。
MySQL中对于索引使用的主要数据结构也是B+Tree,目的也是在读取数据时能够减少磁盘IO。
3 千万级数据如何用B+树索引快速查找
MySQL 官方对非叶子节点(如最上层 h = 1的节点,B+Tree高度为3) 的大小是有限制的,最大的大小是16K,可以通过以下SQL语句查询到,当然这个值是可以调的,既然官方给出这个阈值说明再大的话会影响磁盘IO效率。
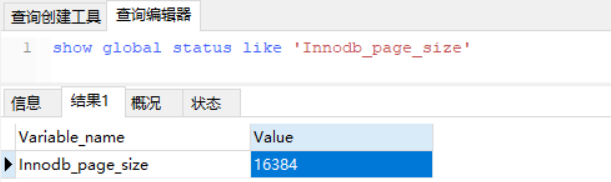
从执行结果,可以看到大小为 16384,即 16K大小。
假如:B+Tree的表都存满了。主键索引的类型为BigInt,大小为8B,指针存储了下个节点的文件地址,大小为6B。最后一层,假如 存放的数据data为1K 大小,那么
- 第一层最大节点数为: 16k / (8B + 6B) ≈ 1170 (个);
- 第二层最大节点数也应为:1170个;
- 第三层最大节点数为:16K / 1K = 16 (个)。
则,一张B+Tree的表最多存放 1170_1170_16 ≈ 2千万。
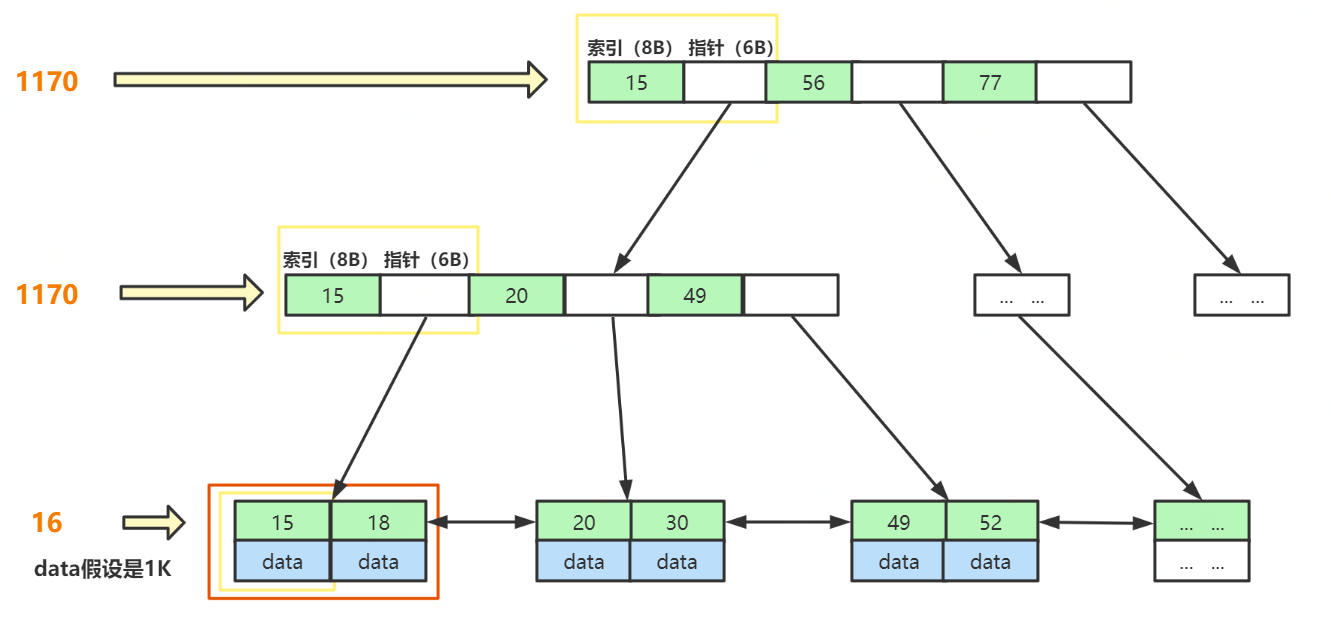
所以,通过分析,我们可以得出,B+Tree结构的表可以容纳千万数据量的查询。而且一般来说,MySQL会把 B+Tree 根节点放在内存中,那只需要两次磁盘IO就行。
4 存储引擎索引实现
MySQL中索引储存在哪里呢?和数据一样,索引以文件形式储存在硬盘上。
在MyISAM储存引擎中,数据和索引文件试试分开储存的,数据存在.MYD结尾的文件中,索引单独存在.MYI结尾的文件中。

在InnoDB中,数据和索引文件是合起来储存的,注意下图中没有了.MYI结尾的文件,只有一个.ibd结尾的文件。

MyISAM索引文件和数据文件是分离的(非聚集),并且主键索引和辅助索引(二级索引)的储存方式是一样的。
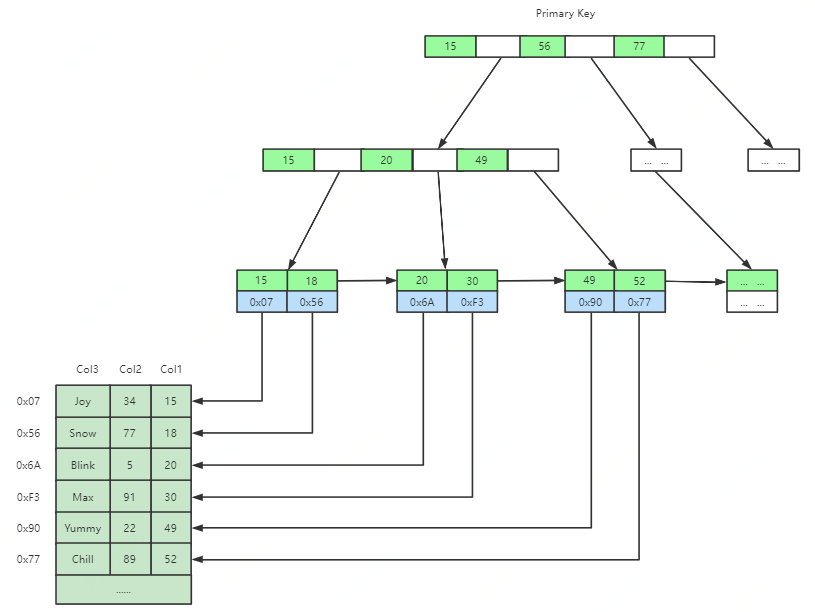
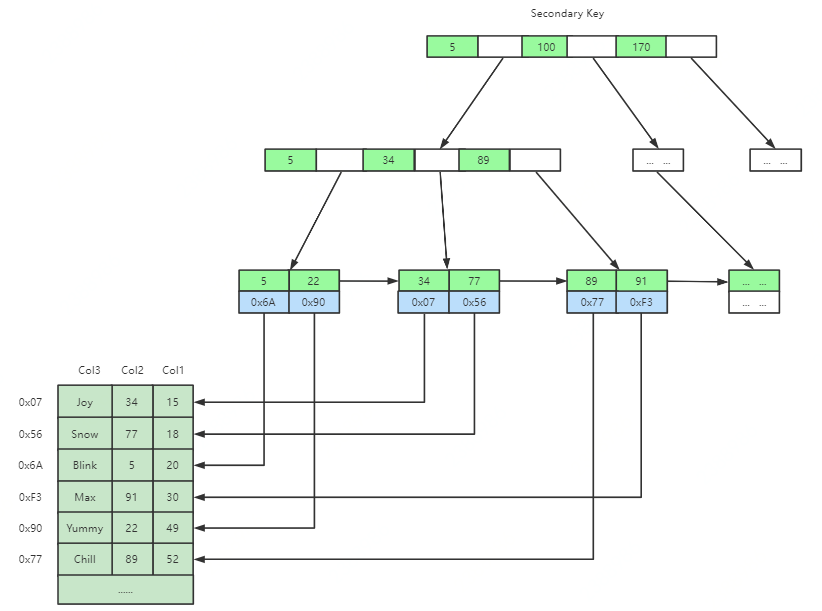
InnoDB中索引文件和数据文件是同一个文件(聚集),并且主键索引和二级索引储存方式有所不同,如图所示,二级索引的叶子节点不储存数据,仅储存主键ID。
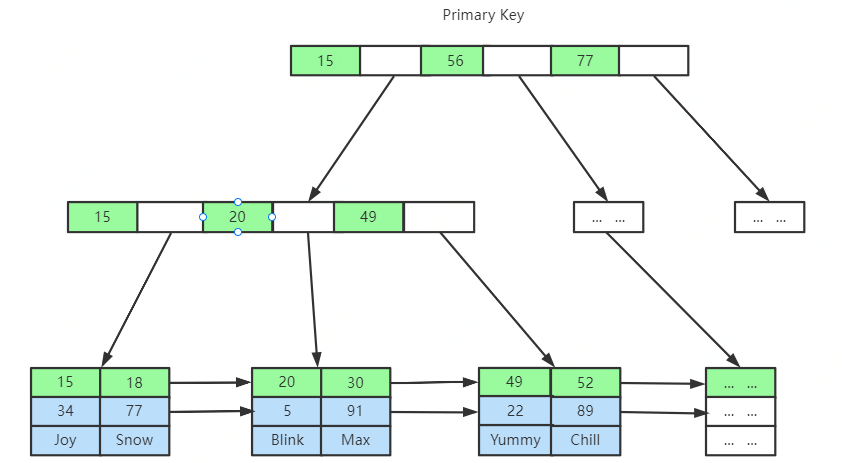
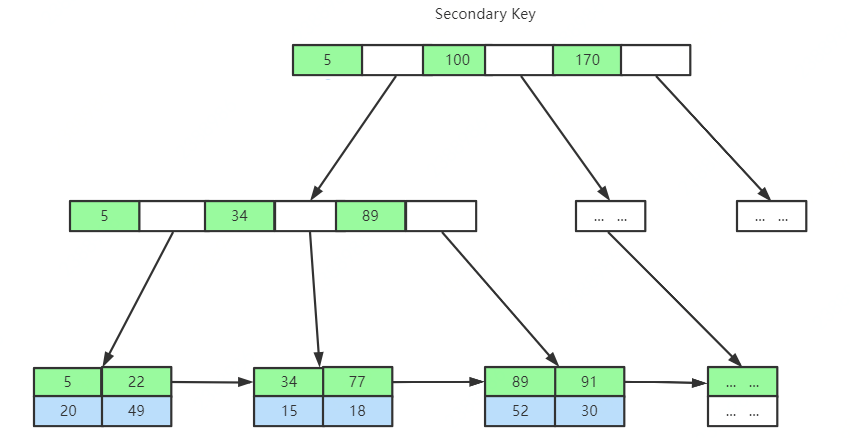
这里思考几个问题:
- 为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
- 为什么非主键索引结构叶子节点存储的是主键值?
如果我们在创建表时不设置主键,InnoDB会自动帮我们从第一列开始筛选一列数据不重复的列做为主键,如果找不到这样的列,就会创建一个隐藏的列(rowid)做为主键,这会增加很多MySQL的工作,所以建议我们在创建InnoDB表时一定要设置主键。
整型的字段做为主键,一方面在数据比较时不需要进行转换,另一方面存储也比较节省空间。那为什么要强调主键自增呢?如果主键id是无序的,那么很有可能新插入的值会导致当前节点分裂,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。反之,如果每次插入有序,那就会在当前页后面连续写入,写不下就会重新分配一个节点,内存都是连续的,这样效率自然也就最高了。
非主键索引的叶子节点存储主键值而非全部数据,主要也是为了一致性和节省空间。如果二级索引储存的也是数据,那么每次插入MySQL都不得不更新每棵索引树,这样就加剧了新增编辑时的性能损耗,并且这样一来空间利用率也不高,必然产生了大量冗余数据。
5 联合索引底层数据结构又是怎样的
联合索引又叫复合索引,例如下表:
CREATE TABLE `test` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL,
`age` int NOT NULL,
`position` varchar(32) NOT NULL,
`address` varchar(128) NOT NULL,
`birthday` date NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如下索引就是一个联合索引。
`idx_name_age_position` (`name`,`age`,`position`) USING BTREE
联合索引底层数据结构长什么样?
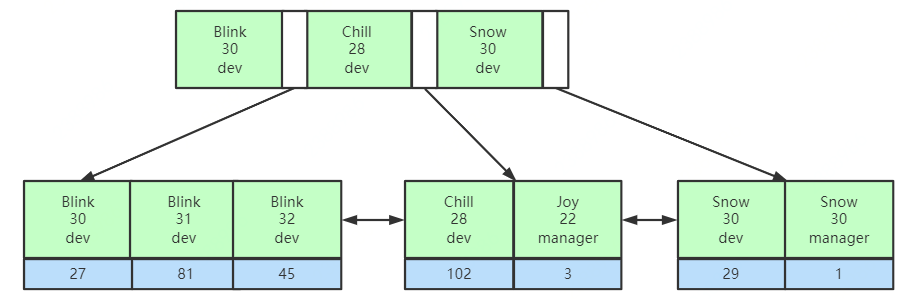
比较相等时,先比较第一列的值,如果相等,再继续比较第二列,以此类推。
了解了联合索引的存储结构,我们就知道了索引最左前缀优化原则是怎么回事了,在使用联合索引时,对于索引列的定义顺序将会影响到最终查询时索引的使用情况。例如联合索引(name,age,position),MySQL会从最左边的列优先匹配,如果最左边的带头大哥name没有使用到,在未使用覆盖索引的情况下,就只能全表扫描。
联合底层数据结构思考:MySQL会优先以联合索引第一列匹配,此后才会匹配下一列,如果不指定第一列匹配的值,也就无法得知下一步查询哪个节点。
索引本质上是一种排好序的数据结构,了解了MySQL索引的底层数据结构及存储原理,可以帮助我们更好地进行SQL优化。其实数据库索引调优是一项技术活,不能仅仅靠理论,因为实际情况千变万化,而且MySQL本身存在很复杂的机制,如查询优化策略和各种引擎的实现差异等都会使情况变得更加复杂。但同时这些理论是索引调优的基础,只有在明白理论的基础上,才能对调优策略进行合理推断并了解其背后的机制,然后结合实践中不断的实验和摸索,从而真正达到高效使用MySQL索引的目的。
最后,如果大家想再温习一下数据结构的知识,这个数据结构网站(https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)不可错过,可以很好地帮助我们演示数据结构的存储过程。
作者:京东物流 于朔
Recommend
-
13
案例 分析以下几条sql的索引使用情况 Mysql的索引分析 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高...
-
26
欢迎关注WX公众号:【程序员管小亮】 专栏C++学习笔记 1)该文章整理自网上的大牛和相关专家无私奉献的资料,具体引用的资料请看参...
-
17
作者:junshili 一步一步推导出 Mysql 索引的底层数据结构。 Mysql 作为互联网中非常热门的数据库,其底层的存储引擎和数据检索引擎...
-
33
前言 当提到 MySQL 数据库的时候,我们的脑海里会想起几个关键字:索引、事务、数据库锁等等, 索引是 MySQL 的灵魂,是平时进行查询时的利器,也是面试中的重中之重 。 可能你了解索引的底层是 b+ 树...
-
16
本文原题“聊聊TCP连接耗时的那些事儿”,本次收录已征得作者同意,转载请联系作者。有少许改动。1、系列文章引言1.1 文章目的作为即时通讯技术的开发者来说,高性能、高并发相关的技术概念早就了然与胸,什么线程池、零拷贝、多路复用...
-
18
前言 作为即时通讯技术的开发者来说,高性能、高并发相关的技术概念早就了然于胸,什么线程池、零拷贝、多路复用、事件驱动、epoll等等名词信手拈来,又或许你对具有这些技术特...
-
8
一文理解 Redis 底层数据结构 (查看原文) Redis的5种常见数据结构:字符串(String)、列表(List)、散列(Hash)、集合(Set)、有序集...
-
7
一、synchronized简介synchronized是Java中的关键字,是一种同步锁。在多线程编程中,有可能会出现多个线程同时争抢同一个共享资源的情况,这个资源一般被称为临界资源。这种共享资源可以被多个线程同时访问,且又可以同时被多个线程修改,然而线程的...
-
10
深入理解 Git 底层实现原理 ...
-
3
前言 跳表可以达到和红黑树一样的时间复杂度 O(logN),且实现简单,Redis 中的有序集合对象的底层数据结构就使用了跳表。其作者威廉·普评价:跳跃链表是在很多应用中有可能替代平衡树的一种数据结构。本篇文章将对跳表的实现及...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK