

How to Achieve ACID Compliance on Distributed, Highly Available Systems
source link: https://www.gigaspaces.com/blog/acid-distributed-transactions
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
How to Achieve ACID Compliance on Distributed, Highly Available Systems

As organizations move from a monolithic architecture to a distributed architecture based primarily on microservices, data operations are often performed across two or more data databases. Today’s applications usually require data from multiple sources, which may be located in separate nodes connected by a network, or may span multiple databases on a single server.
Despite the added complexity of utilizing data from remote sources, these distributed transactions, like ‘plain old database transactions,’ must provide predictable behavior by enforcing the ACID properties that define all transactions.
Let’s take a step back and look at the transactions themselves – why are transactions required?
Database transactions execute multiple statements, and ensure that all operations within the scope of that transaction either all succeed, or all fail. Let’s consider an information system in the financial sector that manages customers’ accounts and is responsible for deposits and withdrawals. To explore why we need transactions, consider the following example:
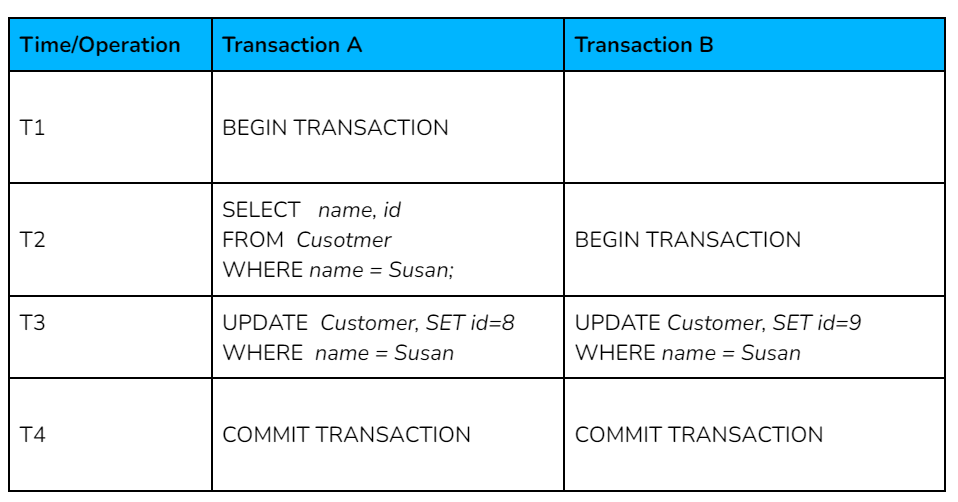
What would the ID’s value of the employee named Susan be in T4 ?
Obviously, there is no right answer, since each database maintains its own transactional properties that can be applied per use case. Nevertheless, the behavior must be consistent and deterministic for the given application. Each organization uses a specific set of rules, the ACID properties of transactions, to maintain the consistency and integrity of the database before and after each transaction.
ACID Properties of Transactions
To maintain consistency in a database, before and after a transaction, ACID properties are required. ACID stands for Atomicy, Consistency, Isolation and Durability:
- Atomicy – Guarantees that each transaction is accurately executed. If not, the process will stop and the database will revert back to its previous state. This prevents data corruption or loss to the dataset.
- Consistency – A processed transaction will never endanger the structural integrity of the database. Ensures that a processed transaction does not affect the validity of the database, by only allowing updates according to established rules and policies
- Isolation – Transactions cannot compromise the integrity of other transactions by interacting with them while they are still in progress.
- Durability – committed transactions will remain committed even upon system failures
When applying ACID properties to transactions, it guarantees that each read, write, update or delete operation possesses the ACID attributes.
When choosing the right ACID schema it is important to take into account not only the functional requirements but also the database capabilities. Certain implementations might be very expensive as they require some database records locking. Locking can be performed on different database layers, perhaps just a row, or in some cases the whole table may be locked, so that update operations block all reads and writes. This can add latency to the total operation time and may consume a significant amount of memory.
The CAP Theorem
The CAP theorem refers to the three attributes of distributed data stores:
- Consistency: All reads receive the most recent write or an error.
- Availability: All reads contain data, but it might not be the most recent.
- Partition tolerance: The system continues to operate despite network failures.
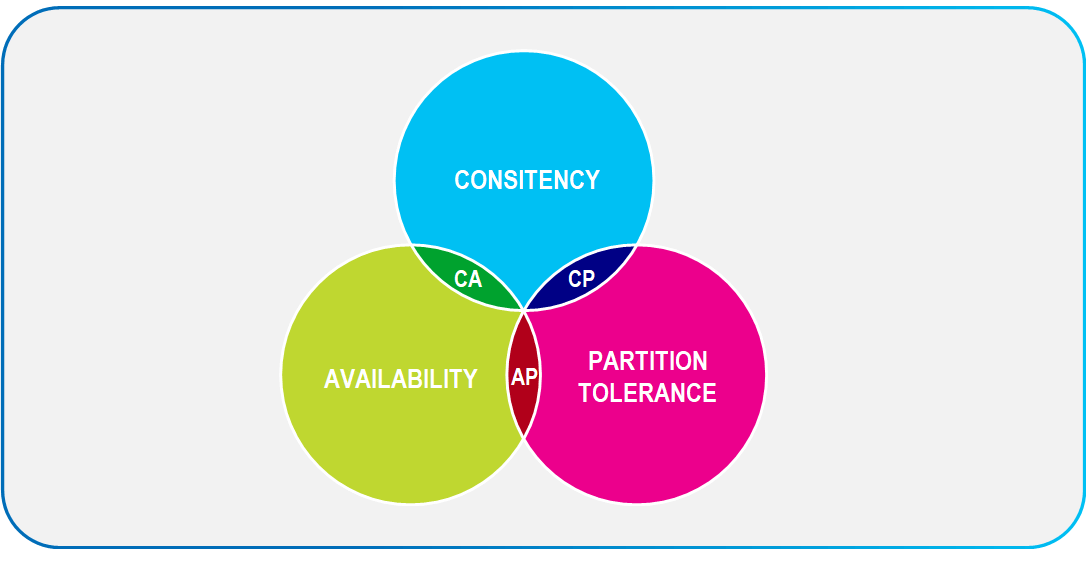
According to the CAP theorem, only two of the three properties (Consistency, Availability, and Partition-tolerance) can be guaranteed at any given time in distributed data stores, but never all three. Since distributed data stores are partitioned by nature, and the assumption is that network failure will happen, partition tolerance is considered mandatory. As a result, the theorem argues that any system has to select between complete Consistency and complete Availability.
- Consistency + Partition Tolerance (CP): Every client sees the same data at a given point in time, this is mostly used with storage-based, big cache scenarios favoring consistency over availability.
- Availability + Partition Tolerance (AP): Every client receives a response for all read and write requests at all times, regardless of the state of any individual node in the system. This combination can be found in distributed transactional systems favoring availability over consistency.
It is important to mention that different mechanisms allow maintenance of the third element (Availability and Consistency in accordance) at a very high level using mechanisms such as those implemented by Smart DIH.
Methods to Achieve ACID Compliance on Distributed Systems
Distributed systems – usually NoSQL data systems – can achieve very high levels of availability and performance even during massive updates. However, in many cases they break the ACID model and cannot be used as a valid solution for use cases where consistency is required. The banking domain applies such standards, as maintaining a reputation as trusted funds managers is essential to retaining those customers. Imagine withdrawing money from a shared account. Then imagine that the account’s co-owner withdraws from the same account, assuming that the money is still there, since the database query reflects the wrong balance. The query still does not reflect the first withdrawal transaction, resulting in a negative balance. Customers would be unlikely to continue trusting that bank to manage their money.
Implementing ACID over such systems needs to be carefully evaluated to ensure that the core NoSQL functionality (such as high availability and throughput) is not broken. Following are some methods used to achieve ACID compliance in distributed environments.
Two-Phase Commit
One common approach for maintaining atomicity is to use the Two Phase Commit (2PC) method, which enables coordinated transaction management over a distributed system. Coordination refers to the process of agreement between the distributed system nodes to ensure that the transaction is not committed until all partitions in the distributed environment acknowledge the transaction. Depending on the transaction durability properties of the database, the coordination process may be quite slow.
Multi-Version Concurrency Control
A common approach for ensuring isolation as well as atomicity is the Multi Version Concurrency Control (MVCC), an effective algorithm that creates point-in-time consistent snapshots in a data system. With this method, the data is not overridden but is versioned. The version that each transaction is exposed to is based on the isolation level. A further explanation about the MVCC mechanism and how it is used in Smart DIH can be found below.
Persistency Methods
To maintain the durability of data in Smart DIH’s in-memory data grid, several mechanisms are employed:
- Backup partitions: the data grid, as a distributed data store, is made of a number of partitions, over which data objects are spread. In a standard system each partition has a parallel backup partition that is fully synchronized with the primary partition, but resides on a different machine. When a primary partition encounters a failure, the system immediately directs the client to the backup partition that holds all the data, allowing the failed partition to recover.
- Tiered Storage: GigaSpaces’ Tiered Storage mechanism automatically assigns data to different categories of storage types based on considerations of cost, performance, availability, and recovery. It holds a synchronized backup for each partition on a persistent storage device – it may hold a much larger data set on disk while only part of it is maintained in-memory. A failure of a whole cluster, where both primary and backup partitions are restarted, is automatically recovered from the permanent replication of the data.
- Mirroring: the mirroring mechanism maintains a copy of all the data stored in the in-memory data grid on an external database, which can be used for recovery from that backup.
Transaction Support as Implemented by Smart DIH
Maintaining ACID properties in a distributed data grid is challenging. This challenge becomes more extreme with Digital Integration Hub (DIH) architecture, as not only is the DIH required to keep its high-performance data store in sync with the Systems of Record (SoRs), but also changes to it must be transactional. Maintaining consistency between the DIH and the SoR is critical, as breaking the transaction will produce inferior user experiences.
Learn more about Smart DIH’s highly performant data management platform
For example, a money transfer application should be able to show the right balance within the DIH at any given state, no matter how many operations are performed on the SoR. Showing a partial balance during the transfer will be a real nightmare for application developers and will be misleading for end users.
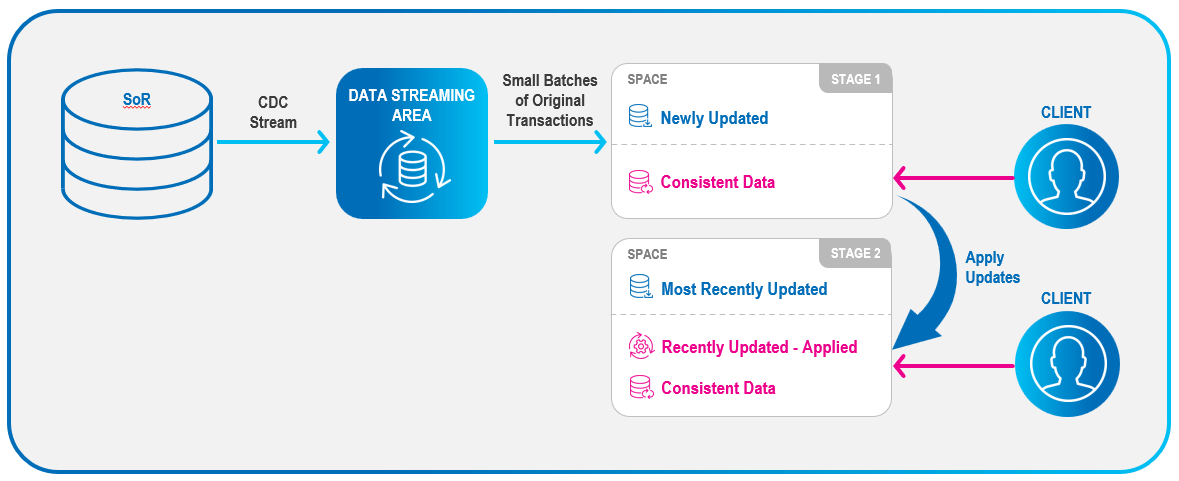
Smart DIH maintains transactions end-to-end, from the moment they are written to the data sources, to the moment they are consumed by the application. The platform is responsible for ensuring that no partial updates are visible to the client. The platform utilizes Data Pipelines (well-defined flows that manage the data journey from a data source and into a Space) that apply the transaction logic of the data sources when integrating data into the Space. These pipelines offer data integrity and consistency over CDC, and also support batch data load.
Isolation Levels
Isolation enables multiple transactions to execute simultaneously, without affecting each other. It does not determine the order by which the transactions will occur, but ensures that transactions don’t prevent another from executing. The following levels of transaction isolation determine the logic which will handle concurrent transactions in databases:
- Read uncommitted: allows access to the data before the updates have been committed
- Read committed: allows access only to committed data. That includes changes that were committed during the transaction execution and repeated read may not yield the same results
- Repeatable read: ensures that read is done over a static snapshot throughout the transaction
The following diagram represents the transactional data flow in Smart DIH:
Advantages of Multi-Version Concurrency Control (MVCC)
As mentioned above, implementing ACID operations have their tradeoffs. Objects under transactions are usually locked. This creates a data objects’ contention during extended operations, which may occur during extended updates. MVCC solves this problem by maintaining multiple copies of the objects. Clients are exposed to a consistent point-in-time snapshot of the database, and read and write operations are isolated from each other so that locking is not required.
Processing a large number of simultaneous transactions in Smart DIH requires an extreme write throughput that cannot be paused. In order to maintain transactions in the platform, Space objects must not be locked. The MVCC mechanism provides an elegant solution, allowing massive updates while maintaining consistency in the Space with the systems of record. In this manner, the ACID properties of transactions are maintained, ensuring the consistency and integrity of the database before and after each transaction, even in highly available distributed systems.

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK