

What’s that magic computation in stb__RefineBlock?
source link: https://fgiesen.wordpress.com/2022/11/08/whats-that-magic-computation-in-stb__refineblock/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

What’s that magic computation in stb__RefineBlock?
Back in 2007 I wrote my DXT1/5 (aka BC1/3) encoder rygdxt, originally for “fr-041: debris” (so it was size-constrained). A bit later I put up the source and Sean Barrett adapted it into “stb_dxt”, which is probably the form that most know it in today.
It’s a simple BC1 encoder that gives decent quality, the underlying algorithm is reasonably fast (fast enough to say bake textures you produce once per session in a game from a character creator, say, which is one of the cases I’ve ended up using it in in a professional context), and is easy to integrate.
The basic algorithm uses the same primitives most BC1 encoders use (I’ll assume in the following you know how BC1 works): compute the average and covariance matrix of the block of pixels, compute the principal component of the covariance to get an initial guess for what direction the vector between the two endpoints should point in. Then we project all pixel values onto that vector to find the min/max support points in that direction as the initial seed endpoints (which determines the initial palette), assign each pixel the palette entry closest to it, and do some iterative refinement of the whole thing.
rygdxt/stb_dxt only uses the 4-color mode. It did not bother with the 3-color + 1-bit transparency mode. It’s much more niche, increases the search space appreciably and complicates the solver, and is rarely useful. The original code was written for 64k intros and the like and this was an easy small potential win to give up on to save on code size.
Nothing in there was invented by me, but at the time I wrote it anyway, DXT1/BC1 encoders (at least the ones I was looking at) were doing some of these steps in a way that was more complicated than necessary. For example, one thing I vividly recall is that one encoder I was looking at at the time (I believe it was Squish?) was determining the principal component of the covariance matrix by forming the characteristic polynomial (which for a 3×3 matrix is cubic), using Cardano’s formula to find the roots of the polynomial to determine eigenvalues, and finally using Gaussian Elimination (I think it was) to find vectors spanning the nullspace of the covariance matrix minus the eigenvalue times the identity. That’s a very “undergrad Linear Algebra homework” way of attacking the problem; it works, but it’s complicated with a fair amount of tricky code and numerical issues to wrestle with.
rygdxt, with its focus on size, goes for a much simpler approach: use power iteration. Which is to say, pick a start vector (the only tricky bit), and then iterate multiplying covariance matrix by that vector and normalizing the result a few times. This gives you a PCA vector directly. In practice, 3-6 iterations usually sufficient to get as good a direction vector as makes sense for BC1 encoding (stb_dxt uses 4), and the whole thing fits in a handful lines of code with absolutely nothing subtle or numerically tricky going on. I don’t claim to have invented this, but I will say that before rygdxt I saw a bunch of encoders futzing around with more complicated and messier approaches like Squish, or even bothering with computing a general 3×3 (or even NxN) eigendecomposition, and these days power iteration seems to be the go-to, so if nothing else I think rygdxt helped popularize a much simpler technique in that space.
Another small linear algebra trick in there is with the color matching. We have a 4-entry palette with colors that lie (approximately, because everything is quantized to an 8-bit integer grid) on a line segment through RGB space. The brute-force way to find the best match is to compute the 4 squared distances between the target pixel value and each of the 4 palette entries. This is not necessarily a bad way to do it (especially if you use narrow data types and SIMD instructions, because the dataflow is very simple and regular), but it is essentially computing four 4-element dot products per pixel. What rygdxt/stb_dxt uses instead is the fact that if it were a perfect line segment in a continuous space, we could just use an orthogonal projection to find the nearest point on the line, which with appropriate normalization boils down to a single dot product per pixel. In that continuous simplification, the two interpolated colors sit exactly 1/3rd and 2/3rds along the way between the two endpoints. However working on the aforementioned 8-bit integer grid means that the interpolated colors can sometimes be noticeably off from their ideal placement, especially when the two endpoints are close together. What rygdxt therefore does is compute where the actual interpolated 1/3rd-of-the-way and 2/3rds-of-the-way colors land on the line (two more dot products), and then we can do our single dot product with the line direction and use the values we computed earlier to figure out which of these 4 colors is closest in the 1D space along the line, which is just a few comparisons and can be done branchlessly if desired.
The result doesn’t always match with the distances code using the brute-force solution would get, but it’s very close in practice, and reducing the computations by a factor of nearly four sped up the BC1 encoding process nicely (old 2008 evaluation by my now-colleague Charles here).
That leaves us with the actual subject of this blog post, the iterative refinement logic! I just answered an email by someone asking for an explanation of what that code does and why, so here goes.
The refinement function
The code in question is here.
Ultimately, what rygdxt/stb_dxt does to refine the results is linear least-squares minimization. (Another idea that’s not mine, this one I definitely got from Squish). We’re holding the DXT indices (interpolation weights) constant and solving for optimal endpoints in a least-squares sense. In each of the RGB color channels, the i’th target pixel is approximated by a linear interpolation
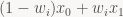
where x0, x1 are the endpoints we’re solving for and wi is one of {0, 1/3, 2/3, 3/3} depending on which of the 4 indices is used for that pixel. Writing that out for the whole block in say the red channel turns into an overdetermined system of 16 linear equations

to be solved for x0r, x1r (the first/second endpoint’s R value).
Let’s call that tall and skinny matrix on the left A; 
That means our problem is to minimize 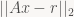
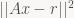
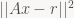

A is a 16×2 matrix, so ATA is a tiny symmetric matrix (2×2) and contains the dot products of the columns of A with each other.
We have 3 color channels, not just r but g and b as well. That means we have 3 copies of the same linear system with 3 different right-hand sides, or equivalently we can view the whole thing as a matrix equation with a 3-wide right-hand side. Either way, all 3 systems have the same A matrix, the only thing that differs is the right-hand sides.
We accumulate 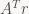
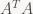
That’s the basic idea. The RefineBlock function uses two more tricks:
- instead of the weights being {0, 1/3, 2/3, 3/3}, we multiply them by 3 and also scale the RHS by 3 (the latter, we never actually do explicitly). Getting the extra scaling is essentially free during the linear system solve, especially since we already need to do some scaling per-channel anyway, because the R/B endpoint values we solve for are in [0,31] (instead of [0,255] for the input pixel values), and the G values are in [0,63]. Scaling everything by 3 means there are no fractions involved in the computation, it’s all small integers, which will be useful for the second trick. It also means that when we compute the determinant of the 2×2 system for Cramer’s rule, it’s an integer computation, so we don’t have to worry about near-zero values and the like. (Although in this case, it’s not too hard to prove that A is singular, i.e. has determinant 0, if and only if all the wi are the same, which is easy enough to detect up front.)
- now our weights wi (matrix entries in A) are all in {0,1,2,3}. The three entries in
turns into
):
,
, and
. Note that all three values we’re summing only depend on wi, and wi is one of 4 possible values (depending on the index), so we can just precompute all of them. Also note they’re all quite small:
.
We sum that one integer per pixel. All of the individual sums are guaranteed to be <256 so we can extract the corresponding bits after the accumulation loop. That means the cost of computing the entries of A^T A becomes quite cheap (a single 4-entry table lookup and 32-bit integer add per pixel), and the bulk of the work in that first loop is just computing the right-hand sides.
And that’s about it. I know that approach was later also used by NVidia Texture Tools, beyond that I have no idea of its reach, but if it’s handy for someone, cool!
Related
Recommend
-
63
除非特别声明,此文章内容采用知识共享署名 3.0许可,代码示例采用Apache 2.0许可。更多细节请查看我们的服务条款。
-
31
Key Takeaways The same factors which make quantum theory so startling also make quantum computers very difficult to implement in practice: quantum phenomena don't manifest themselves in everyda...
-
65
README.md
-
38
Based on the description of the book in the World Scientific Press catalogue, I asked my university library to order a book entitled Automa...
-
54
Abstract: Our main models of computation (the Turing Machine and the RAM) make fundamental assumptions about which primitive operations are realizable. The consensus is that these include logical operations l...
-
63
README.md The PyTorch-Kaldi Speech Recognition Toolkit
-
44
README.md 1. Introduction to blockchain-crypto-mpc blockchain-crypto-mpc is an open source library released by
-
35
Dune is fast. However, if you try to use Dune to develop in a big workspace such as the OCaml platform repository , you will notice that on every run, even if there is no...
-
5
There is No Magic It's my catchphrase, if I were to have one in the technical realm. There is No Magic. It's a mantra and a truism and a guiding principle. All too often, in a technical context, I see developers behave like p...
-
26
JIO STB ATV 7 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK