

5分钟带你了解数据库分库分表
source link: https://www.extlight.com/2021/04/13/5%E5%88%86%E9%92%9F%E5%B8%A6%E4%BD%A0%E4%BA%86%E8%A7%A3%E6%95%B0%E6%8D%AE%E5%BA%93%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8/;jsessionid=484B1493A4AD9B5956933F89C16E27ED
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

随着公司业务快速发展,数据库中的数据量猛增,访问性能也变慢了,优化迫在眉睫。原因在于关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。当单表的数据量达到 1000W 或 100G 以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
解决上述问题通常有以下两种方案:
通过提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU 等,这种方案成本很高,并且如果瓶颈在 MySQL 本身那么提高硬件也是有很的
把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
而方案2正是本篇要介绍的内容。
二、分库分表
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
从垂直和水平两个维度,我们可以将分库分表分成4种方式:垂直分库、水平分库、垂直分表、水平分表。
2.1 垂直分表
垂直分表:将一个表按照字段分成多表,每个表存储其中一部分字段
我们拿网上商城举例:用户在浏览商品列表时,通常只会快速浏览商品名称、商品图片、商品价格等其他字段信息,这些字段数据访问频次较高。当只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品信息中商品描述字段访问频次较低,且该字段存储占用空间较大,访问单个数据 IO 时间较长。
由于这两种数据的访问频次的不同,我们可以将商品信息表分成如下 2 张表:
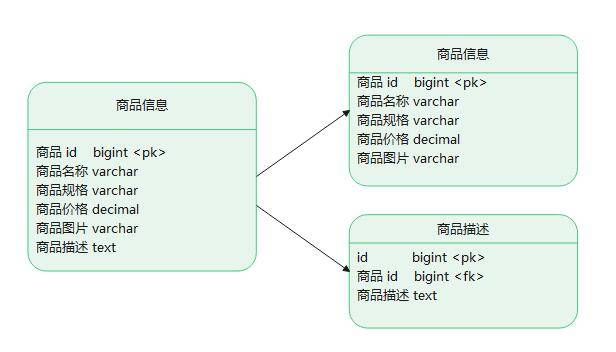
优化提升:
- 为了避免 IO 争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
- 充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累
拆分原则:
- 把不常用的字段单独放在一张表
- 把text,blob等大字段拆分出来放在附表中
- 经常组合查询的列放在一张表中
2.2 垂直分库
垂直分库:按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
继续拿商城举例:一个商城系统通常都包含用户信息表和商品信息表,这两张表在业务上是独立的,因此我们可以将它们拆开分到2个不同的库中。
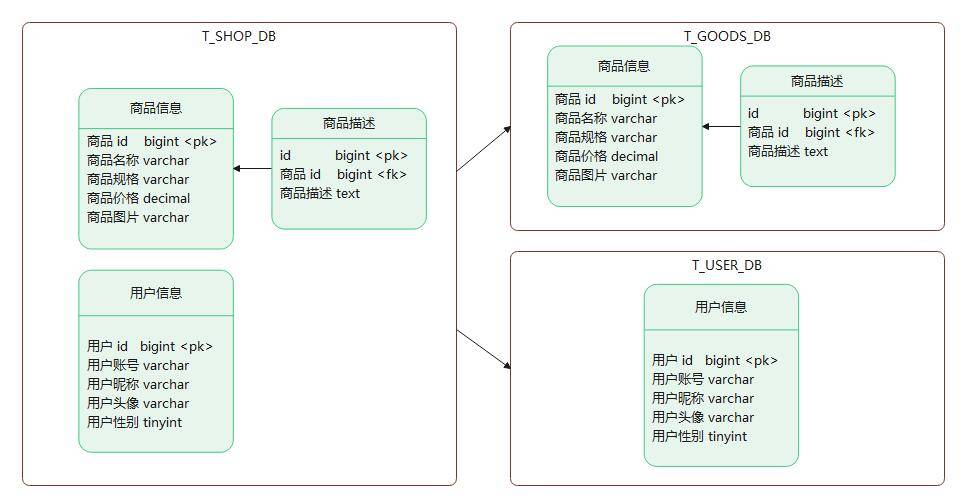
优化提升:
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
2.3 水平分库
水平分库:把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,单库存储数据已经超出预估。单台服务器已经无法支撑。此时该如何优化?
垂直拆分已达到极限,只能从水平维度拆分。
继续拿商城举例:我们要查询某个商品信息时,需要分析这条商品信息的ID。如果ID为双数,将此操作映射至DB_1(商品库1)。如果店铺ID为单数,将操作映射至DB_2(商品库2)。此操作要访问数据库名称的表达式为DB_[商品信息ID % 2 + 1]。
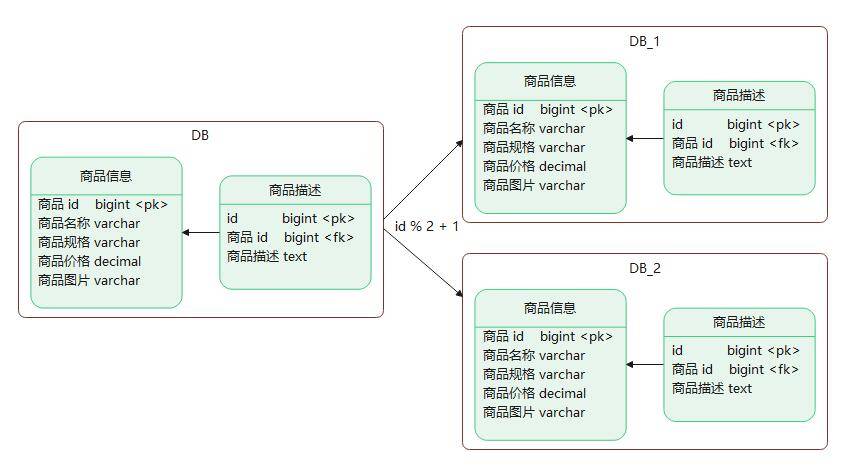
优化提升:
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性。
2.4 水平分表
水平分表:在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
即便水平分库,随着业务的增长还是会出现单表数量大导致查询效率下降的问题。
按照水平分库的思路,我们可以对单表进行水平拆分:

优化提升:
- 优化单一表数据量过大而产生的性能问题
- 避免IO争抢并减少锁表的几率
垂直分表: 可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库: 可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分库: 可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题。
水平分表: 可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
四、引发问题
4.1 事务一致性问题
由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题。
4.2 跨节点关联查询
如果业务数据查询的 SQL 存在多表关联查询,在分库分表情况下,SQL 无法正常执行。我们需要调整 SQL:先查询主表数据,再通过主表数据 id 查询从表数据。
4.3 跨节点分页、排序函数
跨节点多库进行查询时,limit 分页、order by 排序等问题,就变得比较复杂了。需要先在不同的节点中将数据进行排序并返回,然后将不同节点返回的结果集进行汇总和再次排序。
4.4 主键避重
在分库分表环境中,由于表中数据同时保存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的 ID 无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。
4.5 公共表
参数表、数据字典表等都是数据量较小,变动少的公共表,属于高频联合查询的依赖表。
分库分表后,我们需要将这类表在每个数据库都保存一份,所有对公共表的更新操作都同时发送到所有分库执行。
Recommend
-
96
需求背景 近年来,微服务概念持续火热,网络上针对微服务和单体架构的讨论也是越来越多,面对日益增长的业务需求是,很多公司做技术架构升级时优先选用微服务方式。我所在公司也是选的这个方向来升级技术架构,以支撑更大访问量和更方便的业务扩展。 发现问题 微...
-
56
本文是Mycat 数据库分库分表中间件系列文章的第三篇,平时工作太忙,加上又忙着从PHP转Java,平日的空闲时间都去研究Java了。什么Spring MVC、Spring Boot、Spring Cloud、Dubbo,东西真尼玛的多!正好国庆一人没事干,再次拾起来Mycat...
-
31
-
51
最近与同行科技交流,经常被问到分库分表与分布式数据库如何选择,网上也有很多关于中间件+传统关系数据库(分库分表)与NewSQL分布式数据库的文章,但有些观点与判断是我觉得是偏激的,脱离环境去评价方案好坏其实有失公允。
-
29
-
11
老大让我优化数据库,我上来就分库分表,他过来就是一jio。。。发布于 55 分钟前记得,如果有人问你做数据库优化最有效的方式是什么?SQL优化、分布式集群、...
-
6
随着业务数据的增加,原有的数据库性能瓶颈凸显,以此就需要对数据库进行分库分表操作。 为啥需要分库分表 随着业务数据的增加,原有的数据库性能瓶颈凸显,主要体现在以下两个方面。 IO瓶颈主要有以下几种情况: 第...
-
12
『 5分钟带你了解数据库分库分表 』 2021...
-
4
分库分表实战之从根上带你吃透MySQL的索引 作者:石杉的架构笔记 2022-10-13 17:43:10 在磁盘中,MySQL存放数据的基本单位是数据页,数据是放在数据页中的,每个数据页中都有很多的数据行。
-
3
SQL Server 数据库分表分库操作 精选 原创 数据库高可用环境的搭建可以参考以下文章 SQL Server 高可用(always on)配置...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK