

线上排查:内存异常使用导致full gc频繁 - IntoTw
source link: https://www.cnblogs.com/intotw/p/17098308.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

线上排查:内存异常使用导致full gc频繁
日常巡检发现,应用线上出现频繁full gc

分析dump
拉dump文件:小插曲:dump时如果指定:live,则在dump前jvm会先进行一次full gc,并且gc log里会打印dump full gc,这种对非内存泄漏导致的线上异常内存情况排查反而会带来不便,导致我们多dump了好几次。
分析dump文件:
a. 发现大量long[]数组占用最大空间,有异常情况
b. 查看gc根节点,发现这些long[]数据大部分是被org.HdrHistogram.Histogram持有,每个Histogram对象会持有一个2048size的long[]
c. 查看Histogram实例的数量,竟然有5w个,对比下正常项目的堆栈,大约是100倍
d. 这里又有一个插曲,一开始习惯用mat分析,但是mat生成的报告对分析泄露比较有用,对于分析异常的内存没有jvisualvm.exe和idea的profiler好用
本地启动,可以复现这个类的内存使用情况,于是本地起一个其他内存正常的服务与有问题的应用,分析内存对比
这里用的是idea的profiler,很方便
发现差异:
对比正常的应用,发现异常应用的引用存在异常的来自


● rx.internal.operators.OnSubscribeReduceSeed$ReduceSeedSubscriber的引用,怀疑就是这个异常引用就是导致这些实例无法在新生代回收而是堆积到了老年代触发full gc的原因
排查差异:
简单看了下相关代码,看不出个所以然,直接debug对比
系统确实走进了相关的代码,增加了对Histogram的引用,而正常应用没有

但是光这样也看不出来为什么,此时关注到了左下角的线程池,这个线程池比较奇怪,是Metric的线程池
Metric是Hystrix用来统计相关指标,来供自己的dashboard或者用户来获取,以此来了解系统熔断相关参数和指标的功能
再看堆栈,走到这里的逻辑是

这个流用来统计单位时间内的系统指标,导致Hystrix使用Histogram的long数组实现类似滑动窗口的效果统计单位时间内的指标
Histogram本身是Hystrix用来实现类似桶+滑动窗口的功能,来统计单位时间内的流量,但是因为开启了指标参数,导致hystrix为了统计更长时间范围内的指标,新增了对象持有更多(单位时间内)的Histogram引用来聚合,这部分引用因为是统计更长时间范围周期的,就会因为引用持有时间长而到老年代,但是本质并不是内存泄漏,所以每次full gc后又可以得到回收
看到上面的差异和怪异的线程池,第一反应就是关闭metric使应用不走到这段逻辑中增加引用,看官方文档,该配置默认是打开的,并且确认该功能只影响指标统计不影响断路器本身功能,使用配置hystrix.metrics.enabled=false配置来关闭
新增配置后,验证并查看堆栈,引用恢复正常,并且系统在一段时间后并没有新增更多的Histogram实例,发布线上后观察一段时间,full gc问题确实得到解决
在当时发现解决的办法并验证后,并没有时间去研究hystrix.metrics.enabled默认配置就是true但是其他应用没有出现这个full gc问题的原因, 先解决了之后后续再继续跟进排查根本原因防止其他项目也出现相同问题
之前发现可疑的线程池是HystrixMetricsPoller ,经过查看,该线程池由HystrixMetricsPollerConfiguration

类开启,主要依靠hystrix.metrics.enabled开启,但是默认是true,为什么其他项目没有开启呢?
搜了下源码,这个类的开启还和一个注解有关
对比了一下代码,果然只有异常的应用使用了这个注解,这个注解的目的是开启断路器
但是研究之后发现,不使用这个注解,熔断等功能依旧可用,原因是在spring-cloud高版本之后,spring通过使用hystrix封装openfeign的方法来使用熔断,而不是集成整个hystrix体系,可能spring-cloud也发现了hystrix内存使用上的问题
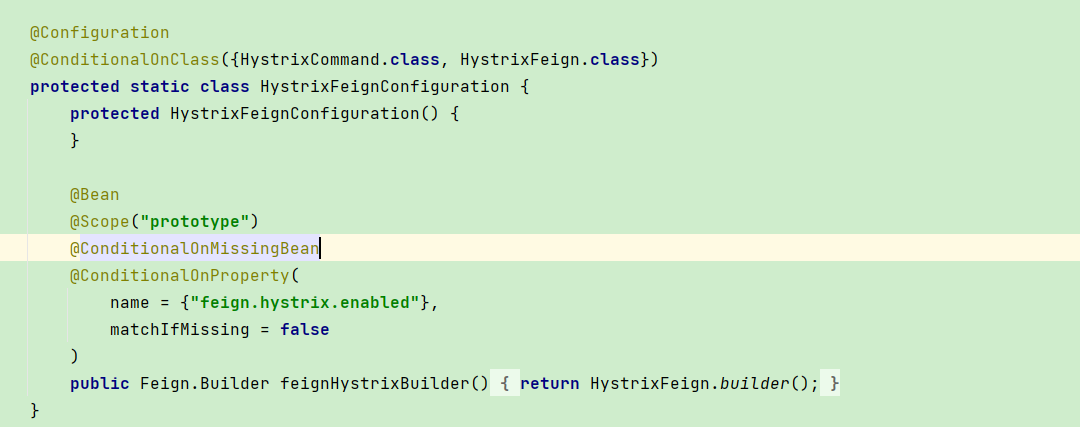
所以在较高版本(起码我们的版本),feign是通过feign.hystrix.enabled来开关断路器的(这个开关是关闭的话,单纯加@EnableCircuitBreaker注解断路器是不会生效的)
其实在更高点版本的spring-cloud中,@EnableCircuitBreaker这个注解已经被标注为废弃了,但是可能因为我们是中间版本,所以存在既没有标注废弃其实又没有什么用的情况
总而言之,feign的断路功能只通过feign.hystrix.enabled来控制,增加@EnableCircuitBreaker注解之后仅仅只是会开启Hystrix其他所有的指标等功能
问题根本原因
本次问题产生的根本原因是因为开启了@EnableCircuitBreaker注解,开启了Hystrix指标功能,导致Histogram实例大量进入老年代,只有full gc才可以回收
Histogram本身是Hystrix用来实现类似桶+滑动窗口的功能,来统计单位时间内的流量,但是因为开启了指标参数,导致hystrix为了统计更长时间范围内的指标,新增了对象持有更多(单位时间内)的Histogram引用来聚合,这部分引用因为是统计更长时间范围周期的,在访问量上升新生代复制速度变快时,就会因为引用持有时间长而到老年代,但是本质并不是内存泄漏,所以每次full gc后又可以得到回收
后续关注点
- Spring-Cloud本身体系比较复杂,因为和Netfilx套件纠缠不清加上很多历史原因,能用明白某一个版本的就很不错了
- 开发本身并不了解这个版本断路器到底怎么开启,没有仔细看过对应版本的官方文档就去使用注解,在老版本,断路器确实是通过这个注解才能启用的
关闭metric功能或者去掉@EnableCircuitBreaker注解均可解决
百度spring-cloud教程和文档时,一定一定一定要看对应版本的,否则可能加一堆配置解决某个问题,结果开启一大堆乱七八糟的功能
__EOF__
本文链接:https://www.cnblogs.com/intotw/p/17098308.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
Recommend
-
33
点击上方“ 小码宋 ”,关注“设为星标” 技术文章第一时间送达!...
-
14
作者:爱宝贝、 https://my.oschina.net/zhangxufeng/blog/3017521 处理过线上问题的同学基本上都会遇到系统突然运行缓慢,C...
-
26
Java小能手21小时前故障案发缘起 网关上线一周以来,运行一直稳定,从未出现CPU飙高的情况。发生故障的当天,CPU开始缓慢上升,但是上升的过程并不是...
-
15
etcd clientv3的lease keepalive租约频繁续期bug 排查小记 文章目录 [显示] etcd 3.2.23
-
29
...
-
7
线上故障主要会包括cpu、磁盘、内存以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。同时例如jstack、jmap等工具也是不被局限在一个方面的问题的,基本上出问题就是df、free、top 三连,...
-
4
V2EX › Java 线上 JVM 内存溢出, OOM 问题排查求指点。
-
5
记一次内存占用异常排查 —— memory ballast 被分配了物理内存 2023-03-12 2023-03-12 约 2201 字 预计阅读 5 分钟 memory ballast 的概念这里不...
-
7
家里配置了一套软路由,使用有 1~2 年都非常稳定,速度和稳定性都很好。 但是,上周末家里的软路由出现问题,WAN 口频繁掉线,掉线后在 2 分钟之后又自动重连,过 30 分钟~2 个小时之间又再次掉线重连,该现象一直持续。 查看日志后关键信...
-
6
天网风控灵玑系统是基于内存计算实现的高吞吐低延迟在线计算服务,提供滑动或滚动窗口内的count、distinctCout、max、min、avg、sum、std及区间分布类的在线统计计算服务。客户端和服务端底层通过netty直接进行tcp通信,且服务端也是基于netty将数...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK