

AI已经把你看得明明白白,YOLO+ByteTrack+多标签分类网络
source link: https://www.51cto.com/article/744507.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
AI已经把你看得明明白白,YOLO+ByteTrack+多标签分类网络
今天给大家分享一个行人属性分析系统。从视频或者相机的视频流中能识别行人,并标记每个人的属性。

识别的属性包括以下 10 类
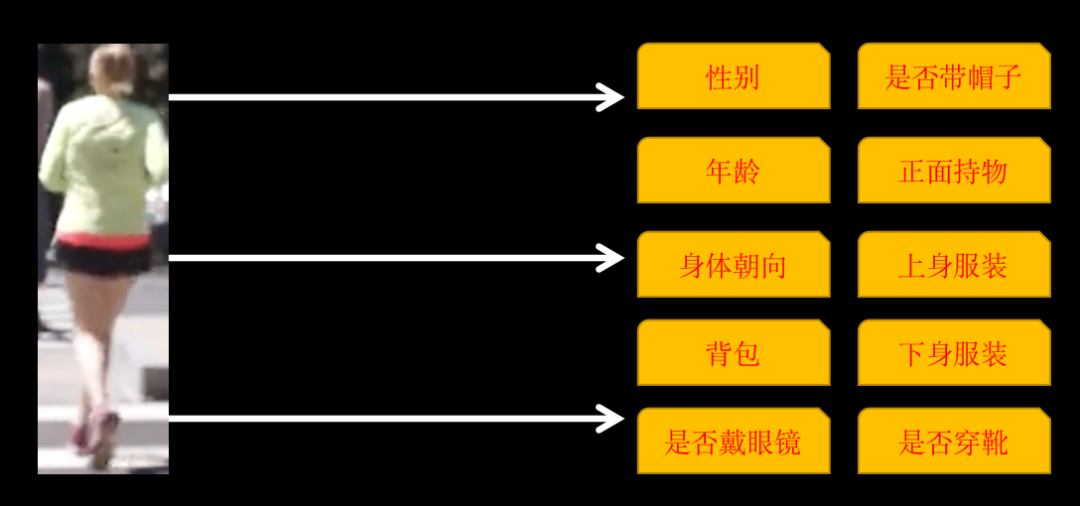
有些类别有多个属性,如果身体朝向有:正面、侧面和背面,所以,最终训练的属性有 26 个。
实现这样的系统需要 3 个步骤:
- 用 YOlOv5 识别行人
- 用 ByteTrack 跟踪标记同一个人
- 训练多标签图像分类网络,识别行人 26 个属性
1. 行人识别与追踪
行人识别使用YOLOv5目标检测模型,可以自己训练模型,也可以直接使用YOLOv5预训练好的模型。
行人追踪使用的是多目标跟踪技术(MOT)技术,视频是由一幅幅画面组成,虽然我们人类能够识别出不同画面中的同一个人, 但如果不对行人做追踪,AI是无法识别的。需要用MOT技术追踪同一个人并给每个行人分配唯一的ID。
YOLOv5模型的训练、使用,以及多目标跟踪技术(MOT)技术的原理、实现方案,在上一篇文章有详细的教程,感兴趣的朋友可以查看那边文章《YOLOv5+ByteTrack统计车流》。
2. 训练多标签分类网络
我们最开始接触的图像分类大部分是单标签分类的,即:一张图片归为1类,类别可以是二分类也可以是多分类。假设有三个类别,每一张图片对应的label可能是下面这总格式:
001.jpg 010
002.jpg 100
003.jpg 100label只有一个位置是1。
而我们今天要训练的多标签分类网络是一张图片同时包含多个类别,label格式如下:
001.jpg 011
002.jpg 111
003.jpg 100label可以有多个位置是1。
训练这样的网络,有两种方案。一种是把每个类别看成是单标签分类,单独计算损失,汇总总,计算梯度更新网络参数。
另一种可以直接训练,但对需要注意网络细节,以ResNet50为例
resnet50 = ResNet50(include_top=False, weights='imagenet')
# 迁移学习,不重新训练卷积层
for layer in resnet50.layers:
layer.trainable = False
# 新的全连接层
x = Flatten()(resnet50.output)
x = Dense(1024)(x)
x = Activation('relu')(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
# 输出 26 个属性的多分类标签
x = Dense(26, activatinotallow='sigmoid')(x)
model = Model(inputs = resnet50.input, outputs=x)最后输出层的激活函数必须要sigmoid,因为需要每个属性单独计算概率。同理,训练时的损失函数也需要用二分类交叉熵binary_crossentropy。
实际上,上面两种方法原理都是类似的,只不过开发的工作量不同。
这里为了方便,我使用的是PaddleCls进行训练。Paddle的配置简单,缺点是有点黑盒,只能按照他那一套来,需要自定义的地方就比较麻烦。
模型训练使用的是PA100K数据集,需要注意的是,PA100K数据集定义的原始label与Paddle虽然含义相同,但顺序不同。
如:原始label第1位代表是否是女性,而Paddle要求第1位代表是否戴帽子,第22位才是是否是女性。

我们按照Paddle的要求调整下原始label位置即可,这样我们后面推理会方便些。
下载PaddleClas
git clone https://github.com/PaddlePaddle/PaddleClas将下载的数据集解压,放到PaddleClas的dataset目录。
找到ppcls/configs/PULC/person_attribute/PPLCNet_x1_0.yaml配置文件,配置图片和label路径。
DataLoader:
Train:
dataset:
name: MultiLabelDataset
image_root: "dataset/pa100k/" #指定训练图片所在根路径
cls_label_path: "dataset/pa100k/train_list.txt" #指定训练列表文件位置
label_ratio: True
transform_ops:
Eval:
dataset:
name: MultiLabelDataset
image_root: "dataset/pa100k/" #指定评估图片所在根路径
cls_label_path: "dataset/pa100k/val_list.txt" #指定评估列表文件位置
label_ratio: True
transform_ops:train_list.txt的格式为
00001.jpg 0,0,1,0,....配置好后,就可以直接训练了
python3 tools/train.py \
-c ./ppcls/configs/PULC/person_attribute/PPLCNet_x1_0.yaml训练完后,导出模型
python3 tools/export_model.py \
-c ./ppcls/configs/PULC/person_attribute/PPLCNet_x1_0.yaml \
-o Global.pretrained_model=output/PPLCNet_x1_0/best_model \
-o Global.save_inference_dir=deploy/models/PPLCNet_x1_0_person_attribute_infer将导出的结果放在~/.paddleclas/inference_model/PULC/person_attribute/目录下

便可以使用PaddleCls提供的函数直接调用
import paddleclas
model = paddleclas.PaddleClas(model_name="person_attribute")
result = model.predict(input_data="./test_imgs/000001.jpg")
print(result)输出结果如下:
[{'attributes': ['Female', 'Age18-60', 'Front', 'Glasses: False', 'Hat: False', 'HoldObjectsInFront: True', 'ShoulderBag', 'Upper: ShortSleeve', 'Lower: Trousers', 'No boots'], 'output': [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0], 'filename': './test_imgs/000001.jpg'}]模型训练过程就到这里了,数据集和整个项目的源码已经打包好了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK