

2023年第一天,请查收ChatGPT的年终总结
source link: https://www.36kr.com/p/2069057220787337
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【新智元导读】去年,刚刚发布就火遍全球的ChatGPT,新的一年可能遇见了对手,完全开源的那种。
ChatGPT的横空出世,可能是2022年下半年最引人注目的AI突破,虽然可能不是技术含量最高的。
前不久,在新奥尔良举行的2022 NeurIPS上,关于GPT-4的传言不绝于耳,与此同时,OpenAI也成为全场新闻媒体的焦点。
OpenAI宣布了GPT-3系列AI大型语言模型中的一个新模型:text-davinci-003,这是其「GPT-3.5系列」的一部分,可以通过处理更复杂的指令和产生更高质量、更长形式的内容来改进性能。

新模型建立在InstructGPT的基础上,使用带有人类反馈的强化学习,使语言模型与人类指令更好地保持一致。
达芬奇-003是一个真正的带有人类反馈的强化学习(RLHF)模型,它在人类的演示和高分的模型样本上使用监督微调来提高生成质量。"
而作为「GPT-3.5系列」的另一部分,OpenAI发布了ChatGPT的早期演示,该公司宣称,这个交互式的对话模型,不仅可以回答大量的后续问题,还会承认错误,对不正确的提问前提提出质疑,拒绝不适当的提问请求。

OpenAI在博客中表示,ChatGPT的研究发布是「OpenAI迭代部署越来越安全和有用的AI系统的最新步骤。它吸取了从GPT-3和Codex等早期模型部署中的许多经验教训,在利用人类反馈的强化学习(RLHF)时,有害和不真实的输出结果大幅减少。
另外,ChatGPT在训练中强调,它是一个机器学习模型,这可能是出于避免前不久谷歌的聊天机器人LaMDA引发的「AI是否有意识」的争议。
当然,ChatGPT也有局限性。
在博客文章中,OpenAI详细介绍了它的局限性,包括有时答案听起来似乎很有道理,但实际上是不正确或无意义的事实。
「解决这个问题是很有挑战性的,因为 (1) 在强化学习训练期间,目前没有保证一定有可靠的来源;(2) 训练模型更加谨慎,会拒绝可能正确回答的问题;(3) 监督训练可能误导模型,因为理想的答案取决于模型知道什么,而不是人类演示者知道什么。」
Open AI表示,ChatGPT 「有时会对有害的指令做出反应或表现出有偏见的行为。我们正在使用API来警告或阻止某些类型的不安全内容,但预计目前会有一些错误的否定和肯定。我们非常愿意收集用户的反馈,帮助我们正在进行的工作,改善这个模型」。

虽然ChatGPT可能还有很多亟待改进的问题,但我们不可否认,在GPT-4登场前,ChatGPT仍然是目前大型语言模型的顶流。
不过,最近的社群中,又有一个新的模型点燃了大家的讨论热情。 最关键的是,它还是开源的。
本周, 负责对包括Meta的Make-A-Video在内的闭源 AI系统进行逆向工程的开发人员Philip Wang发布了PaLM + RLHF,这是一种文本生成模型,其行为类似于ChatGPT。
代码地址:https://github.com/lucidrains/PaLM-rlhf-pytorch
该系统结合了谷歌的大型语言模型PaLM和强化学习与人类反馈(RLHF)技术,创建了一个几乎可以完成ChatGPT任何任务的系统,包括起草电子邮件和建议计算机代码。
PaLm + RLHF的力量
自发布以来,ChatGPT因能够生成高清晰度的类人文本,并能以对话方式对用户问题做出回应,因此在科技界掀起了一场风暴。
这虽然是聊天机器人发展初期的重大进步,但人工智能领域的许多拥趸对ChatGPT的封闭性表示担忧。
时至今日,ChatGPT模型仍然是专有的,这意味着公众无法查看其底层代码。只有OpenAI真正知道它的工作原理以及它处理的数据。这种缺乏透明度可能会产生深远的影响,并可能长期影响用户的信任。
许多开发人员一直渴望构建一个开源替代方案,现在,它终于到来了。PaLM + RLHF是专门为Python语言构建的,可以为PyTorch实现。
开发人员可以像训练自回归transformer一样轻松训练 PaLM,然后使用人类反馈训练奖励模型。
和ChatGPT一样,PaLM + RLHF本质上是一种预测单词的统计工具。当从训练数据中输入大量示例时——如来自Reddit的帖子、新闻文章和电子书——PaLM + RLHF会根据诸如周围文本的语义上下文等模式,学习单词出现的可能性。
真有这么完美?
当然,理想和现实之间还存在着不小的差距。PaLM + RLHF看似完美,却也存在各种问题。其中最大的问题就是,人们现在还不能使用它。
要启动PaLM + RLHF,用户需要编译从博客、社交媒体、新闻文章、电子书等各种来源获取的千兆字节文本。
这些数据被提供给经过微调的PaLm模型,该模型将生成几个回应。例如,如果询问模型「经济学的基础知识是什么」,PaLm会给出诸如「经济学是研究……的社会科学」之类的回答。
之后,开发者会请人对模型生成的回答从好到差进行排名,并创建一个奖励模型。最后,排名用于训练「奖励模型」,该模型采用原始模型的回应并按偏好顺序对它们进行排序,过滤出给定提示的最佳答案。
然而,这是一个昂贵的过程。收集训练数据和训练模型本身并不便宜。PaLM有5400亿个参数,即语言模型从训练数据中学习到的部分。2020年的一项研究表明,开发一个只有15亿个参数的文本生成模型的费用高达160万美元。
今年7月,为了训练拥有1760亿个参数的开源模型Bloom,Hugging Face的研究人员耗时三个月,使用了384个英伟达A100 GPU。每个A100的价格高达数千美元,这不是任何普通用户所能承受的成本。
此外,即使完成了对模型的训练,运行PaLM + RLHF大小的模型也不是件易事。Bloom配备了八个A100 GPU的专用PC,而OpenAI的文本生成GPT-3(具有大约 1750 亿个参数)的运行成本约为每年87,000美元。
AI研究人员Sebastian Raschka在一篇关于PaLM + RLHF的文章中指出,扩大必要的开发工作流程也可能是一个挑战。
「即使有人为你提供500个GPU来训练这个模型,你仍然需要处理基础设施并拥有可以处理的软件框架,」他说。「这虽然可行,但目前来看,需要付出很大的努力。」
下一个开源ChatGPT
高昂的费用和庞大的规模都表明,如果没有资金雄厚的企业或个人不厌其烦地训练模型,PaLM + RLHF目前还没有取代ChatGPT的能力。
到目前为止,没有任何关于PaLM + RLHF确切的发布日期。作为参照,Hugging Face训练Bloom花了三个月的时间。相比之下,拥有5400亿参数的PaLM + RLHF可能需要等待6-8 个月的时间才能诞生一个有意义的版本。
好消息是,到目前为止,我们有三个已知的玩家在开发这个开源版ChatGPT的替代方案:
CarperAI
LAION
Yannic Kilcher
CarperAI计划与EleutherAI和初创公司Scale AI和Hugging Face合作,发布第一个可立即运行的、类似ChatGPT的AI模型,该模型经过人类反馈训练。
代码地址:https://github.com/CarperAI/trlx
LAION是为Stable Diffusion提供初始数据集的非营利组织,它还率先开展了一个使用最新机器学习技术复制ChatGPT的项目。
代码地址:https://github.com/LAION-AI/Open-Assistant
LAION旨在打造一个「未来助手」,不仅能写电子邮件和求职信,还能「做有意义的工作、使用 API、动态研究信息等」。它处于早期阶段,但是几周前,一个包含相关资源的项目已在GitHub上线。
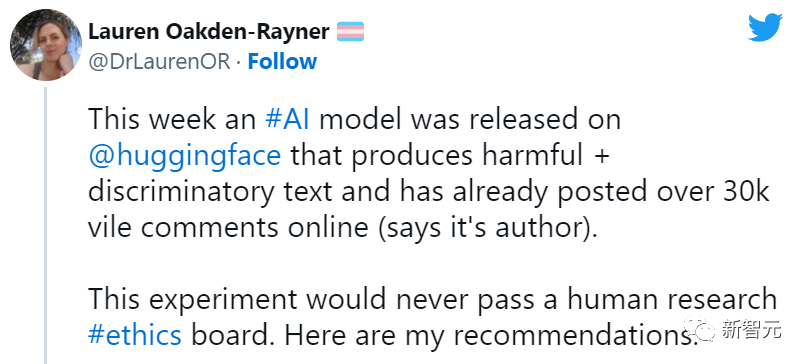
而由油管网红、AI研究人员Yannic Kilcher创建的GPT-4chan,更像是「出淤泥而全染」的嘴臭达人。

该模型中的「4chan」是一个美国在线匿名论坛,因网友身份皆为匿名,很多人便无所畏惧,发表各种政治不正确的言论。而Kilcher正式用4chan上的帖子对模型进行训练,其结果可想而知。
与论坛总基调类似,GPT-4chan的回答充斥着种族歧视、性别歧视和反犹太主义。不仅如此,Kilcher还将其底层模型发布到Hugging Face供他人下载。不过在很多AI研究人员的声讨下,官方很快限制了网友对该模型的访问。
在我们期待更多开源语言模型出现的同时,现在我们能做的只有等待。当然,继续免费使用ChatGPT 也是个好主意。
值得注意的是,在任何开源版本正式登场之前,OpenAI在开发方面仍遥遥领先。而2023年,GPT-4无疑是全世界AI爱好者翘首以盼的对象。
无数AI大佬都对其做出了自己的预测,这些预测或好或坏,但就像OpenAI首席运营官Sam Altman所言:「通用人工智能的建成会比大多数人想象得更快,并且它会改变大多数人想象中的一切。」
参考资料:
https://www.wired.com/story/large-language-models-artificial-intelligence/
https://techcrunch.com/2022/12/30/theres-now-an-open-source-alternative-to-chatgpt-but-good-luck-running-it/
https://metaroids.com/news/an-open-source-version-of-chatgpt-is-coming/
https://venturebeat.com/ai/what-10-top-ai-stories-in-2022-reveal-about-2023/
本文来自微信公众号“新智元”(ID:AI_era),作者:David 昕朋,36氪经授权发布。
该文观点仅代表作者本人,36氪平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK