

文字语义纠错技术探索与实践-张健
source link: https://www.52nlp.cn/%E6%96%87%E5%AD%97%E8%AF%AD%E4%B9%89%E7%BA%A0%E9%94%99%E6%8A%80%E6%9C%AF%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5-%E5%BC%A0%E5%81%A5
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

背景
文本语义纠错的使用场景非常广泛,基本上只要涉及到写作就有文本纠错的需求。书籍面市前就有独立的校对的环节来保障出版之后不出现明显的问题。在新闻中我们也时不时看到因为文字审核没到位造成大乌龙的情况,包括上市公司在公开文书上把“临时大会”写成为“临死大会”,政府文件把“报效国家”写成了“报销国家”。有关文本纠错的辅助工具能给文字工作人员带来较大的便利,对审核方面的风险也大幅降低。
除了不同的写作场景,文本纠错还会用在其他一些智能处理系统中,具体的情况包括:音频通话记录经过自动语音识别(ASR)转写成文本之后,存在一些转译错误;光学字符识别(OCR)系统识别图片中的文字并进行提取,会存在字符识别错误;在搜索引擎或自动问答系统里面,用户在查询过程中的输入错误,往往会导致系统无法理解用户的真实意图,需要进行查询纠正改写。这些情况都需要通过文本纠错技术来进行修正,使产品整体的用户体验更加友好。
文本语义纠错在学术领域有三个子任务,分别是拼写检查(Spelling Check)、语法检错(Grammatical Error Detection)和语法纠错(Grammatical Error Correction)。其中语法检错是对文本中的语法错误进行检测,拼写检查是对文本中的错别字进行修正,语法纠错是纠正文本中的语法错误。拼写检查在英文场景表现为单词拼写错误,在中文场景表现为音近形近错别字。而语法纠错除此之外,还包括字词缺失、字词冗余、字词使用不当、语序不当等错误类型。语法纠错区别于拼写检查的一个显著特点是,语法纠错纠正后的文本和原始文本的长度不一定相等,而拼写检查纠正前后的文本长度都是保持一致的,这也决定了两者的算法支持存在差异。一般来说,拼写检查可以看作为语法纠错的一个任务子集。
我们对语法纠错的问题作一下形式化定义,输入的原始文本定义为X={x1,x2,...,xn};原始文本正确的纠正结果文本序列定义为Y={y1,y2,...,ym},算法预测输出的文本,定义为P={p1,p2,...,pk}。
评估指标
在开始我们的文本语义纠错算法探索之旅之前,我们先思考一个问题,究竟怎么样的模型表现才是公认更有效的,这个好坏应该从何种方式、如何量化地评估出来。这也是我们在解决其他所有类型的NLP任务都需要先考虑的问题,这个问题就是如何定义我们的评测指标。下面罗列了纠错算法常用的一些评测指标:
01M2(MaxMatch)
M2指标主要是通过计算输出文本和原始文本之间的编辑集合G,然后与人工标注的编辑集合E结合,计算准确率、召回率、F0.5值(采用F0.5表示对准确率更加关注)。这里的编辑理解为一个转换动作,经过一组转换动作,可以完成原始文本到纠正文本的转换,M2指标定义形如:
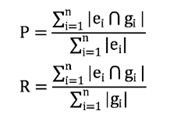
F0.5=1.25*RP/(R+0.25P)
下表罗列了一组示例和计算过程:

表 1 纠错文本示例
其中编辑集合G={孜→自,书→书写},人工标注编辑集合E={孜→自,俱→具,读书→读}
可以计算出来:
P=1/2=0.5
R=1/3=0.33
F0.5=1.25*0.33*0.5/(0.33+0.25*0.5)=0.45
02 ERRANT
ERRANT[1]是升级版的M2。M2的局限性也比较明显,依靠前置的人工标注,有比较大的工作量,而且人工标注编辑集合产生的方式可能不太一致,导致匹配不准。ERRANT在生成标准答案的编辑集合和生成预测的编辑集合都采用了自动判别的方式,同时支持了25种的错误类型,输出了更丰富维度的错误报告信息。缺点是该工具面向英文,中文需要做较大改造。
03面向标注形态的其他指标
上述两者在处理纠错任务评测时存在一些缺点,包括M2不支持检错性能评估,编辑不能正确反映合理纠错动作等等。
我们会在一些学术评测上看到,根据对待纠文本进行的错误标注类型来制定的评测指标。下面举了NLPCC2022语法纠错评测指标为例,它对应的错误类型总共有赘余(Redundant Words,R)、遗漏(Missing Words,M)、误用(Word Selection,S)、错序(Word Ordering Errors,W)四类,评估的维度包含以下方面:
- 假阳性(False Positive):正确句子被判包含错误的比例。
- 侦测层(Detective-level):对句子是否包含错误做二分判断。从句子是否有错,判断p/r/f1
- 识别层(Identification-level):给出错误点的错误类型。按一个句子的错误种类计算p/r/f1
- 定位层(Position-level):对错误点的位置和覆盖范围进行判断,以字符偏移量计。错误位置是否对计算p/r/f1
- 修正层(Correction-level):提交针对字符串误用(S)和缺失(M)两种错误类型的修正词语。修正词语可以是一个词,也可以是一个词组。M/S的修正词语角度
由于纠错任务本身的特殊性(同一个错误的文本可以有多种正确的纠正答案,或者同一个位置可以采用不同的错误类型进行标注),目前现存的评测指标大都有其局限性,如何定义主客观、统一、合理的语法纠错评测指标仍然在不断探讨。
公开数据集
在确定了评估指标之后,我们已经确定了评判算法好坏的一个标准。锅已经端好,就等米下锅了,数据对于算法研发人员来说是必需品,一方面它是验证效果的信息来源,另一方面它是进行模型构建的训练语料。比较好的方式是从公开的渠道获取比较优质的标注数据。目前公开的中文语义纠错数据集包括NLPCC2018[2]、NLPTEA2020[3]、SIGHAN2015[4]等,较多是非母语学生学习汉语收集得来的语料集,训练和验证的数据标注形式如图所示:

图1 公开数据集(NLPTEA2020、NLPCC2020和SIGHAN2015)
无监督方法
文本语义纠错的算法整体可以分成无监督和有监督的两种方式,我们先从无监督的方法开始看。无监督方法的核心是如何构建一个好用的语言模型,并且用在纠错的任务上。对于NLPer来说,我们经历了太多的预训练语言模型,像BERT、XLNet、GPT3等等,其本质还是语言模型或者说经典语言模型的一些变种。语言模型实际上是对文本序列的概率分布进行建模,通俗地来表达,语言模型是判断一句话是不是符合常理,或者说话应该怎么说才合理(符合概率分布)。这个正好就对应上了纠错任务的本质需求,我们从最经典的N元语言模型开始来介绍一下语法纠错的处理逻辑。
01n元语言模型
一个语言模型构建字符串的概率分布p(W),假设p(W)是字符串作为句子的概率,则概率由下边的公式计算:
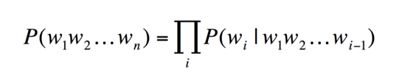
但是这样去计算句子概率会导致庞大的计算量,导致根据马尔科夫假设,一个词只和他前面n-1个词相关性最高,这就是n元语法模型,简化后的计算公式为:
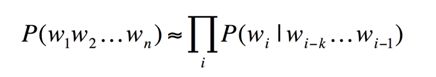
在得到这个结论之后,我们尝试使用N元语言模型来解决拼写检查的问题。
假设我们采用的是5元语言模型,训练阶段使用大量的语料来进行统计所有的p(w5|w1w2w3w4)并存储起来。在预测阶段,设定待纠正的文本序列为W={w1,w2,...,wn},针对每个位置的wk,我们通过预先构建好的混淆集获得w的音近形近字wk'。
然后通过上述公式分别计算原始文本和修改文本的句子概率P(w1...wk...wn)、P(w1...wk'...wn)。如果P(w1...wk’...wn)>P(w1...wk...wn),则说明修改后文本的通顺度提升(概率升高),可以接受该纠正修改(wk替换为wk')。
从而我们的纠错执行过程则包含如下:
- 计算输入句子的归一化对数概率,并且为句子的每个字构建一个混淆集合;
- 对句子每个字针对其不同混淆字重新打分,应用单个最佳进行校正,将概率提高到当前最高值以上;
- 重复上面过程直至概率没变化。
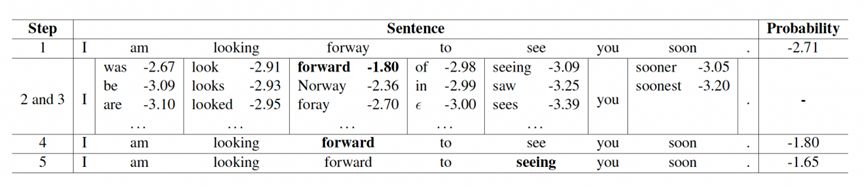
图2 N元语言模型纠错执行计算过程
上述过程比较好理解,同时可以明显看出来一些硬伤,包括会OOV(未登录词)问题导致语言模型计算出来的概率为0;模型会过分优待高频短串,或者忽视低频短串。这时候需要通过平滑技术来改善概率算法,典型平滑方法包含Add-one、Interpolation和Modified Kneser-ney等。此外,仍有些难以通过技术手段解决的问题,包括上下文范围局限较大(n 的增加会导致计算和资源消耗成倍增加)和缺少泛化(缺乏实际予以的理解),此时需要引入基于神经网络的语言模型。
02基于神经网络的语言模型
比较经典的基于神经网络的语言模型,数学表达式可以写为:
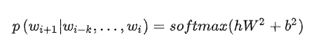
以k元文法为例,把前k-1个词作为特征,用softmax预测最后一个词。
一般基于神经网络的语言模型设计得更加复杂,会把上下文的信息形成特征,来预测当中的每一个词。定义基于上下文context下wi的预测概率为P(wi|context_i),句子的概率可以表示为:
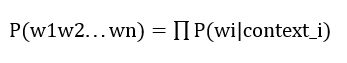
方法[5]就是采用了BERT和GPT作为基础的语言模型来计算句子的概率。
有监督方法
无监督的纠错算法在处理文本时存在以下弱点:容易受局部高频或低频的序列影响,效果不够稳定;在需要对准确率和召回率进行平衡调整时,不太好通过阈值的方式进行控制;可以较好应用在拼写检查的任务上,但是对于句子长度有变化的语法纠错任务支持就比较弱。此时需要使用有监督算法来作为实现手段。
01NMT/Seq2Seq
解决字词冗余/缺失这类纠错前后句子长度有变化的任务,我们第一感觉就想起可以通过文本生成的方式来训练对应的模型实现该功能。而且语法纠错任务和文本生成任务的形态基本上是一致的,也导致了文本生成模型很自然地被研究者注意,引入到语法纠错的任务领域。
NMT-based GEC[6]是第一篇通过使用神经网络机器翻译来实现语法纠错的文章。2014年seq2seq模型一提出即引发了较大反响,后续seq2seq成为了文本生成的主流结构。seq2seq将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码(Encoder)输入与解码(Decoder)输出两个环节组成, 前者负责把序列编码成一个固定长度的向量,这个向量作为输入传给后者,输出可变长度的向量。下图展现了一个基础的seq2seq结构。
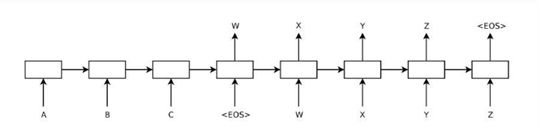
图3 seq2seq结构
方法[7]使用了经典的Encoder-Decoder模型结构来解决中文语法纠错问题,嵌入层使用了特殊的嵌入表示,同时在编码层使用了卷积神经网络强化了纠错的局部性,具体的模型结构如下:
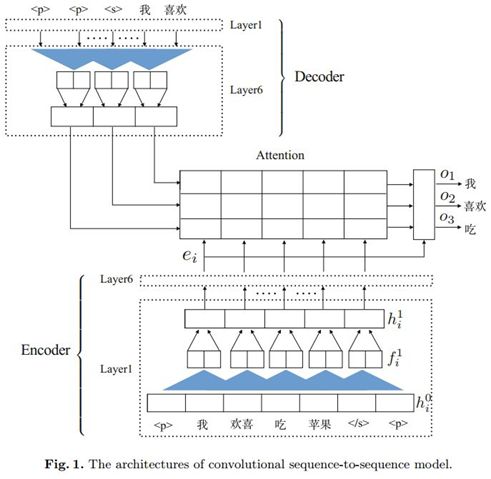
图4 Encoder-Decoder结构纠错模型
02 LaserTagger
由于书写错误的出现概率普遍不高,纠错任务本身的输入输出存在大量重叠(基本不用改),所以大多数文本可以保持不变。但是我们在通过seq2seq的方式进行实现时,对于正常的字符也要全部进行预测,造成效率非常低下。因此谷歌在EMNLP 2019提出了LaserTagger,在使用Encoder-Decoder的模型结构条件下,把预测的内容从文字变成了编辑操作类型。lasertagger其模型结构(采用BERT作为编码层、自回归Transformer作为解码层)如下所示:
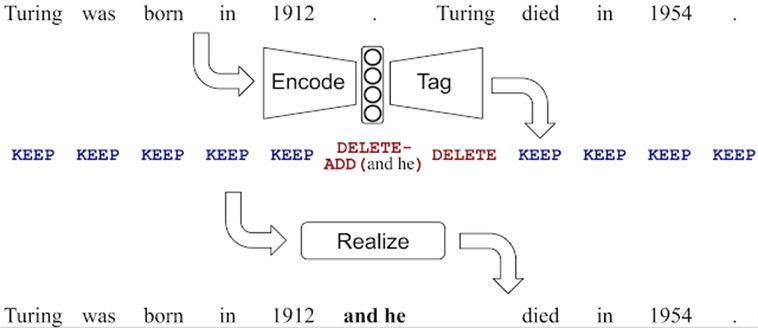
图5 LaserTagger纠错模型
编辑操作类型包含Keep(将单词复制到输出中),Delete(删除单词)和Add(在之前添加短语X),其中被添加的短语来自一个受限的词汇表。
通过结构的改造,lasertagger体现了推理速度快和样本训练效率高的有点。因为预测的类型只有三种,相对于seq2seq而言,解码的空间大幅降低,推理性能提升明显,相对于BERT+seq2seq的模型结构,larserTagger的性能提升接近100倍。同时因为预测的内容求解空间也大幅降低,所以对样本的需求量也大幅减少,在1000份的样本下也能取得不错的效果。
03 PIE
与LaserTagger同年提出来的PIE(Parallel Iterative Edit Models)[8]同样是针对seq2seq 生成文本的可控性较差,推理速度也比较慢的问题进行来改进。与LarserTagger类似,PIE构造模型来对编辑操作进行预测,不过编辑操作的类型稍有区别,多了一个替换(replace)和词性变换(面向英文)。在处理替换和添加操作时,PIE将BERT编码层进行了扩展来支持替换和添加的信息输入,采用了一个双层的双向transformer,结构如下所示:
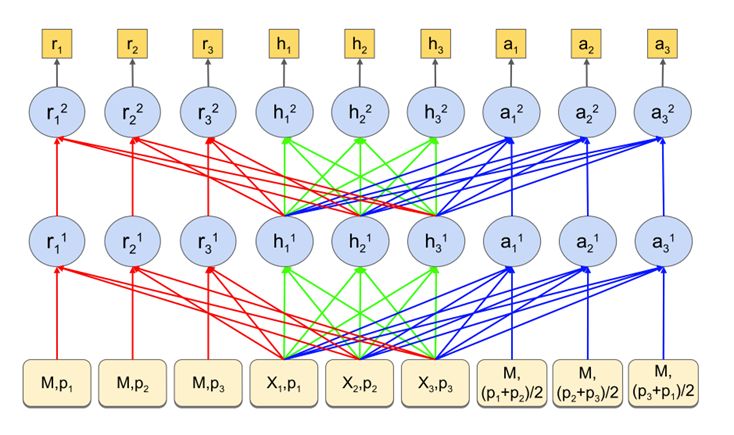
图6 PIE纠错模型
上图表示了一个长度为3的文本输入(x1,x2,x3)。在最底层的输入层,M表示mask标识符的嵌入向量,p表示位置嵌入,x表示词嵌入。在中间层和输出层,r表示对应位置的替换信息,h表示对应位置的的原始信息,a表示对应位置的插入信息。之后利用三类信息来分别计算不同操作的概率,并归一化,CARDT 分别代表复制、插入、替换、删除、词形变换,计算公式如下:
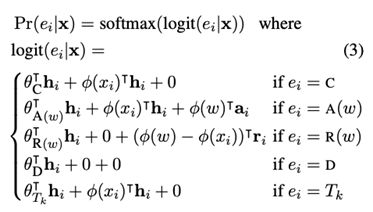
纠错过程中,PIE模型输出概率最高的编辑操作,完成修改后再迭代地进行预测,直至句子不发生改变后停止。
PIE定义的结构可以实现在并行解码的同时保持较高的准确率,它在这篇文章第一次提出了seq2edit的概念。
04 GECToR
GECToR[9]提出了一种序列标注模型,编码层由预训练的 BERT 型 transformer 组成,上面堆叠两个线性层,顶部有 softmax 层。模型输出的标签包含了基本变换和g-变换两种类型。其中基本变换包含保留(KEEP)、删除(DELETE)、添加(APPEND)和替换(REPLACE)。g-变换主要面向英文,针对了英语的语法变化总结出了5大类(大小写、单词合并、单词拆分、单复数和时态)29个小类的状态变换。
GECToR另外两个亮点是引入了不同的预训练Transformer解码器(包括XLNet、RoBERTa、ALBERT、BERT和GPT-2)并进行了比较,以及采用了三阶段的训练方式。第一阶段使用了大量(九百万)实验合成的包含语法错误+语法正确的句子对进行预训练,第二阶段使用了少量的公开纠错数据集的句子对进行Fine-tuning,第三阶段使用了语法错误+正确和语法正确+正确的句子对来进行Fine-tuning,实验证明第三阶段的Fine-tuning有效果提升。
在预测阶段,GECToR也是采用了多轮预测的方案。
05 PLOME
PLOME[10]在2021ACL发表,是针对中文文本纠错任务构建的预训练语言模型,结构和BERT比较类似(12层Transformer)。PLOME的创新点主要在于采用了基于混淆集的掩码策略、把拼音和字形信息作为模型输入以及把字符和拼音的预测任务作为了模型的训练和微调目标。
PLOME的掩码策略主要是基于以下4种:字音混淆词替换(Phonic Masking)、字形混淆词替换(Shape Masking)、随机替换(Random Masking)、原词不变(Unchanging)。PLOME的掩码策略同样仅遮盖15%的token,且4种MASK策略占比分别为: 60% 、15%、10%、15%。
词嵌入模块方面,PLOME采用了字符嵌入(character embedding)、位置嵌入( position embedding)、语音嵌入(phonic embedding)和形状嵌入(shape embedding)。其中,字符嵌入和位置嵌入与BERT的输入一致。其中构建语音嵌入时,使用Unihan数据库得到字符-拼音的映射表(不考虑音调), 然后将每一个字的多个拼音字母序列输入到GRU网络中,得到该字的拼音嵌入向量。同样,构建字形嵌入时,使用Chaizi数据库得到字形的笔画顺序,然后将字形的笔画顺序序列输入到GRU网络中,得到该字的字形嵌入向量。
在训练任务方面,PLOME训练了2个任务,字符预测和BERT一样,增加了拼音的预测,预测被替换词的正确发音,更够更好解决同音和音近错误。
PLOME预训练语言模型的下游任务主要是文本纠错任务。该任务的输入是字符序列 ,输出是预测的字符序列。该论文仅在拼写检查任务上做了验证。
06 其他策略
(1)COPY机制
COPY机制同样是利用目标文本和源文本有大量重复这个特点。研究[11]提出了Copy-Augment的GEC模型,其主要思想是:在生成序列过程中,考虑两个生成分布:分别是复制输入序列中的词语(0/1表示是否复制)的概率分布和从候选词典中的词语生成的概率分布。将两者的概率分布加权求和作为最终生成的概率分布,进而预测每一个时刻生成的词语。基本架构如下:
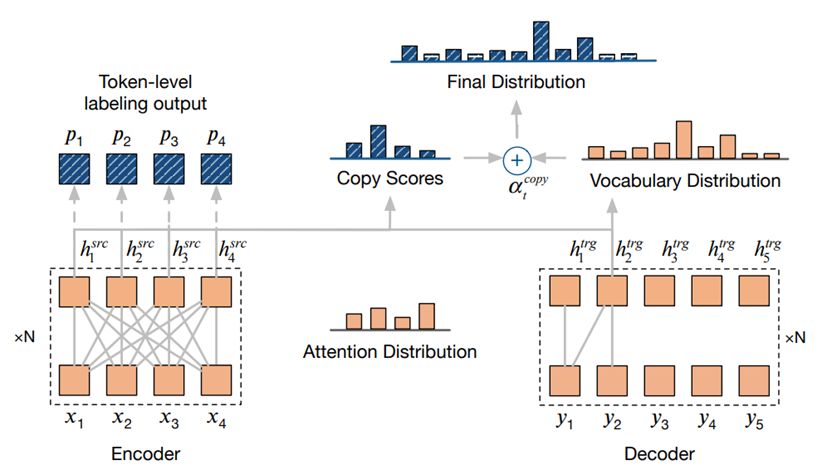
图7 COPY机制
该模型将简单的词语复制任务交给了Copy机制,将模型结构中的Attention等结构更多地用来学习比较难的新词生成,对训练更加可控。
(2)数据增强
数据增强可以通过基于规则和基于生成的方式实现。
基于规则这个比较简单,我们可以按照错误的类型(字词冗余、缺失、词序错误等)针对性地制定策略构造包含语法错误的样本,然后扔到模型来进行训练。不过基于规则的方式有点过于粗暴,很可能规则生成的错误与实际产生的错误差距比较大,或者比较不符合常规认知。
第二种方式就是基于生成。最早基于生成的数据增强方式应该是回译法,就是将文本从一个语种翻译到另外一个语种,然后再翻译回来,从而构造了句子对,这种数据增强形式针对正常的编辑写作可能不太有效,更加符合跨语言学习的用户的错误特点。另外有研究[12]结合了分类器和自编码器来联合训练,达到生成固定类型错误样本的目的。而研究[13]通过对GEC模型进行对抗攻击,可以生成有价值的带有语法错误的句子,可以利用生成的句子训练GEC模型,提升性能的同时提升鲁棒性。
处理难点与技术挑战
01语料收集
目前公开的中文语义纠错数据集主要是不同母语的人学习汉语作为第二语言收集得来的语料集,目前大部分关于语法纠错的算法模型都是基于这些数据集来做效果验证的,不过我们实际中要处理的数据通常并不是同样的形式诞生,更多是掌握汉语作为母语的人由于失误导致的语法错误,这种情况和公开预料的情况差别比较大,错误的分布差距也比较大,从而通过公开语料集训练得来的模型在上线到正常的业务流程里面,效果通常都会比较一般。
02长依赖
长距离包括跨语句依赖在论文等文本中很常见,一旦出现错误,很难察觉并纠正。当前语法研究大多集中在单个语句的语法检查和纠错,很少涉及长距离语法问题,相关数据集和模型方法缺失,是语法纠错的难题之一。
03模型的泛化能力与鲁棒性
一般来说,不同行业、不同领域的文本在措辞运用、表达习惯和专有名词等方面都存在较大的差异。譬如说政务机关红头文件非常严谨的语言表达和自媒体新闻相对较自由的文风就有明显的差别,又譬如金融行研报告和医学论文在基本内容和专业术语上也截然不同。在一个领域性能出色的纠错模型在切换到另外一个领域,往往效果下降明显。如何提升模型的泛化能力和鲁棒性,面临着巨大的技术挑战。
04效果指标与体验的平衡
SOTA的指标可以刷到,但是这些模型一旦介入实际场景的数据,效果会差得一塌糊涂,这个一方面是由于模型和场景紧密相关,另外一方面是,通常公开数据集的错误分布是呈高密度,但是实际场景是低密度,会容易导致非常高的误判。譬如说SOTA里面准确率的指标是80%,对于在低密度错误的样本中,很可能准确率会下降到20~30%左右。纠错系统的体验会比较差。
05效果指标与纠错性能的平衡
工业界往往会采用pipeline的方式,先对文本进行检错,如果检测出来有错误,再对文本进行纠错处理。但是这个检错阶段的错误会传递到纠错阶段,导致效果下降。如果直接走seq2seq或seq2edit的纠错模型,或者需要融合多种模型策略来生成最终纠错结果,纠错的性能会下降非常快,部分实验3000字的纠错可能需要长达40~60秒,这个无法处理大量并发的文本纠错需求。我们需要再效果和性能上取得平衡,或者有更好的方法在保障效果指标的前提下提升纠错性能。
达观在语义纠错方面的产品实践
达观数据在语义纠错方面有比较深入的产品实践,开发出的投行质控系统和公文智能处理系统均处理了相关场景。
达观投行质控系统基于深度学习、NLP(自然语言处理)算法,帮助用户解决几大文书审核场景,包括:文书格式纠错,文字纠错和完整性审核;文档目录智能识别,一键定位:文档条款内容智能提取,方便业务人员对条款内容进行预审;支持文档多版本的内容比对等。
达观智能公文处理系统,严格遵循《党政机关公文处理工作条例》和《党政机关公文格式》规定,通过公文智能分析、公文知识库引用、公文审校、公文排版、公文格式纠错、公文内容语义纠错、公文在线比对修改等一体化的功能,实现基础字词校对准确率超90%、法律引用校验和公务文书完整性校对准确率超95%,有力提升政府机关整体公文质量,避免公文“带病”发布情况,确保政府机关公信度。
参考文献:
[1] Korre K, Pavlopoulos J. Errant: Assessing and improving grammatical error type classification[C]//Proceedings of the The 4th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature. 2020: 85-89.
[2] Zhao Y, Jiang N, Sun W, et al. Overview of the nlpcc 2018 shared task: Grammatical error correction[C]//CCF International Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2018: 439-445.
[3] Rao G, Yang E, Zhang B. Overview of NLPTEA-2020 shared task for Chinese grammatical error diagnosis[C]//Proceedings of the 6th Workshop on Natural Language Processing Techniques for Educational Applications. 2020: 25-35.
[4] Tseng Y H, Lee L H, Chang L P, et al. Introduction to SIGHAN 2015 bake-off for Chinese spelling check[C]//Proceedings of the Eighth SIGHAN Workshop on Chinese Language Processing. 2015: 32-37.
[5] Alikaniotis D, Raheja V. The unreasonable effectiveness of transformer language models in grammatical error correction[J]. arXiv preprint arXiv:1906.01733, 2019.
[6] Yuan Z, Briscoe T. Grammatical error correction using neural machine translation[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 380-386.
[7] Ren H, Yang L, Xun E. A sequence to sequence learning for Chinese grammatical error correction[C]//CCF International Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2018: 401-410.
[8] Awasthi A, Sarawagi S, Goyal R, et al. Parallel iterative edit models for local sequence transduction[J]. arXiv preprint arXiv:1910.02893, 2019.
[9] Omelianchuk K, Atrasevych V, Chernodub A, et al. GECToR--grammatical error correction: tag, not rewrite[J]. arXiv preprint arXiv:2005.12592, 2020.
[10] Liu S, Yang T, Yue T, et al. PLOME: Pre-training with misspelled knowledge for Chinese spelling correction[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 2991-3000.
[11] Zhao W, Wang L, Shen K, et al. Improving grammatical error correction via pre-training a copy-augmented architecture with unlabeled data[J]. arXiv preprint arXiv:1903.00138, 2019.
[12] Wan Z, Wan X, Wang W. Improving grammatical error correction with data augmentation by editing latent representation[C]//Proceedings of the 28th International Conference on Computational Linguistics. 2020: 2202-2212.
[13] Wang L, Zheng X. Improving grammatical error correction models with purpose-built adversarial examples[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 2858-2869.
作者简介
张健,达观数据联合创始人,复旦大学计算机软件与理论硕士,曾就职于盛大集团和腾讯文学,担任人工智能和大数据技术专家职位。目前担任达观数据文本应用部总负责人,对于机器学习算法和自然语言处理领域的研发有丰富的实践经验和技术积累,负责客户意见洞察系统、智能客服工单分析系统、文本语义纠错系统、事件分析平台、文本智能审核系统等多个文本应用产品的开发和落地。荣获上海市浦东新区科学技奖、“2021上海科技青年35人引领计划”、上海市青年科技启明星等多个奖项。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK