

台积电3nm制程节点遇到难题:SRAM单元缩减速度放缓,未来CPU/GPU或更贵 - 超能网
source link: https://www.expreview.com/86024.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
台积电3nm制程节点遇到难题SRAM单元缩减速度放缓,未来CPU/GPU或更贵
吕嘉俭发布于 2022-12-16 15:34
此前有报道称,台积电在(TSMC)3nm制程节点完成技术研发和初步试产后,今年第三季度下旬的产能将大幅度攀升,N3工艺正式进入量产阶段。不过最终由于各种原因,一直推迟,传言英特尔延后了订单,而苹果对现有的N3工艺并不满意。
按照台积电的计划,从2022年到2025年,将陆续推出N3、N3E、N3P、N3X等制程,后续还会有优化后的N3S制程,可涵盖智能手机、物联网、车用芯片、HPC等不同平台的使用需求。台积电在3nm制程节点仍使用FinFET(鳍式场效应晶体管),不过可以使用FINFLEX技术,扩展了工艺的性能、功率和密度范围,允许芯片设计人员使用相同的设计工具集为同一芯片上的每个关键功能块选择最佳选项,进一步提升PPA(功率、性能、面积)。
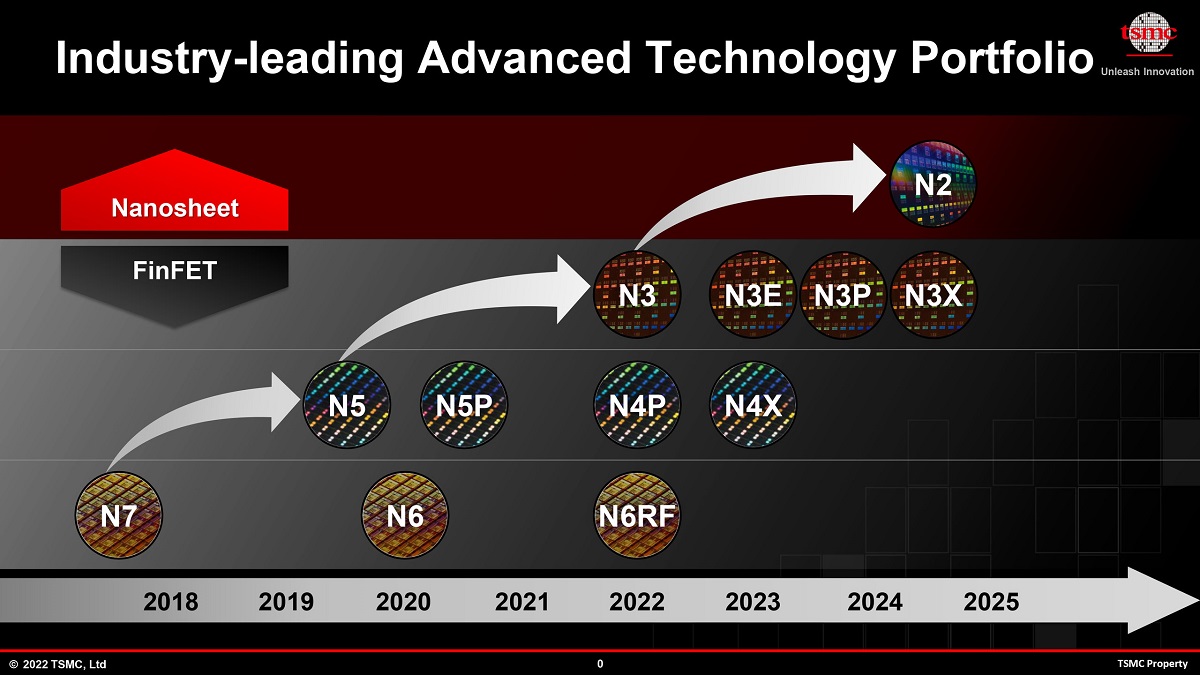
每一次进入新的制程节点,大家都系希望能够提升性能、降低功耗并增加晶体管密度。尽管逻辑电路方面在新的工艺技术中有着很好的提升,但SRAM方面则一直落后,而台积电最新的3nm制程节点甚至出现了停滞。据WikiChip的一份报告称,台积电在SRAM单元的缩减速度已大大放缓。
台积电曾表示,如果将N3和N5工艺放在一起做比较,前者预计会带来10%到15%的性能提升(相同功耗和复杂程度),或者降低25%-30%的功耗(相同频率和晶体管数量),同时会将逻辑密度提高约1.6倍。N3E是台积电(TSMC)第二代3nm工艺,相比N5的性能提升幅度大概为18%,或者降低34%的功耗,逻辑密度提高约1.7倍。
近期台积电在IEDM 2022会议上发表的论文上称,采用N3和N5工艺的SRAM位单元大小为0.0199μm²和0.021μm²,仅缩小了约5%,而N3E工艺更糟糕,基本维持在0.021μm²,这意味着相比N5工艺几乎没有缩减。英特尔方面,Intel 7工艺的SRAM位单元大小为0.0312μm²,接下来的Intel 4工艺为0.024μm²。台积电针对密度优化的N3S工艺或许表现会更好一些,预计推出的时间是2024年,但如果想有较大突破,就要等未来的2nm制程节点,也就是说还要等上几年的时间。

现代的CPU、GPU和SoC在处理数据的时候都将SRAM用于各种缓存,尤其是针对人工智能(AI)和机器学习(ML)的工作负载,配备大容量缓存已成为趋势。展望未来,对缓存的需求只会增加,不过选择3nm制程节点并不能减少SRAM占用芯片的面积,且相比现有的5nm制程节点的工艺成本更高,也就是说高性能芯片的芯片尺寸增加,同时成本也在增加。这也就可以解释为什么台积电会在3nm制程节点推出FINFLEX技术,以缓解SRAM方面的问题。
一种比较现实的解决办法是采用小芯片设计,将容量较大的缓存分解到成本较低的工艺上单独制造芯片,这就是AMD近两年集中精力在3D V-Cache技术的原因之一。近期发布的RDNA 3架构GPU上,AMD在GCD和MCD上采用了不同的工艺制造,后者采用的N6工艺要比前者的N5工艺便宜得多。另外一种方法是采用替换技术,比如使用eDRAM或FeRAM用于缓存。
可以预见在未来几年里,基于新制程节点的芯片因SRAM单元缩减速度放缓将是设计人员面临的主要挑战。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK