

如何将模块化应用于 SQL
source link: https://www.jdon.com/63786
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
如何将模块化应用于 SQL
在本文中,我们将了解模块化这一最重要的系统设计原则之一如何应用于 SQL。
定义: 模块是一个单元,其元素与自身紧密相连,但与其他单元弱相连。
当系统在设计时考虑到模块化,独立方很容易并行构建这些组件,以便以后组装。它还使得在生产中调试和修复系统变得容易。
模块化是操作系统设计的核心原则之一。如果您熟悉 Mac 上的命令行界面,您就会看到它的强大功能。它的设计方式是将独立的工具拼接在一起,以解决越来越复杂的问题。
在本文中,我们将学习如何将其应用于 SQL。
三个层次的模块化
在 SQL 中,我们可以在 3 个不同级别应用模块化:
- 在同一个 SQL 查询中
- 跨多个 SQL 查询
- 超越 SQL 查询
您是否曾经编写或调试过很长的 SQL 查询?您是否在试图弄清楚它在做什么时迷失了方向,或者它真的很容易理解吗?
您是否迷路在很大程度上取决于查询是否使用 CTE 将问题分解为逻辑模块,从而使解决问题和理解问题变得非常容易。
级别 1 - 在同一个 SQL 查询中
CTE 或公用表表达式是临时视图,其范围仅限于当前查询。它们不存储在数据库中;它们仅在查询运行时存在,并且只能在该查询中访问。它们的行为类似于子查询,但更易于理解和使用。
CTE 允许您将复杂的查询分解为更简单、更小的独立模块。通过将它们连接在一起,我们可以解决任何复杂的查询。
旁注: 尽管 CTE 自 1999 年以来一直是 SQL 标准定义的一部分,但数据库供应商花了很多年才实现它们。某些版本的旧数据库(如 8.0 之前的 MySQL、8.4 之前的 PostgreSQL、2005 之前的 SQL Server)不支持 CTE。所有现代云仓库供应商都支持它们。
可视化 CTE 的最佳方法之一是通过 DAG(有向循环图)。
以下是如何链接 CTE 以解决复杂查询的一些示例。
这是第一张图及其相应的代码。
在此示例中,每个 CTE 使用前一个 CTE 的结果来构建其结果集并进一步发展。

-- Define CTE 1 WITH cte1_name AS ( SELECT col1 FROM table1_name ), -- Define CTE 2 by referring to CTE 1 cte2_name AS ( SELECT col1 FROM cte1_name ), -- Define CTE 3 by referring to CTE 2 cte3_name AS ( SELECT col1 FROM cte2_name ), -- Define CTE 4 by referring to CTE 3 cte4_name AS ( SELECT col1 FROM cte3_name ) -- Main query SELECT * FROM cte4_name |
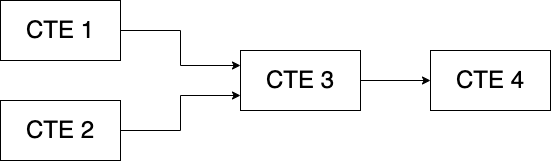
这是另一个第二张图和相应的代码。
在此示例中,CTE 3 依赖于彼此独立的 CTE 1 和 CTE 2,而 CTE 4 依赖于 CTE 3。
-- Define CTE 1 WITH cte1_name AS ( SELECT col1 FROM table1_name ), -- Define CTE 2 cte2_name AS ( SELECT col1 FROM table2_name ), -- Define CTE 3 by referring to CTE 1 and 2 cte3_name AS ( SELECT * FROM cte1_name AS cte1 JOIN cte2_name AS cte2 ON cte1.col1 = cte2.col1 ), -- Define CTE 4 by referring to CTE 3 cte4_name AS ( SELECT col1 FROM cte3_name ) -- Main query SELECT * FROM cte4_name |
最后是更复杂的东西及其相应的代码:
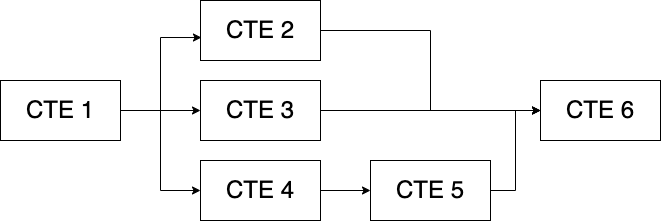
如您所见,您可以通过多种方式链接或堆叠 CTE 来解决复杂查询。
级别 2- 跨多个查询
当您发现自己在多个查询中复制和粘贴 CTE 时,是时候将它们重构为视图、UDF 或存储过程了。
-- Define CTE 1 WITH cte1_name AS ( SELECT col1 FROM table1_name ), -- Define CTE 2 by referring to CTE 1 cte2_name AS ( SELECT col1 FROM cte1_name ), -- Define CTE 3 by referring to CTE 1 cte3_name AS ( SELECT col1 FROM cte1_name ) -- Define CTE 4 by referring to CTE 1 cte4_name AS ( SELECT col1 FROM cte1_name ), -- Define CTE 5 by referring to CTE 4 cte5_name AS ( SELECT col1 FROM cte4_name ), -- Define CTE 6 by referring to CTEs 2, 3 and 5 cte6_name AS ( SELECT * FROM cte2_name cte2 JOIN cte3_name cte3 ON cte2.column1 = cte3.column1 JOIN cte5_name cte5 ON cte3.column1 = cte5.column1 ) -- Main query SELECT * FROM cte6_name |
观点
视图非常适合封装适用于许多查询的业务逻辑。它们还用于安全应用程序,以根据最终用户的权限限制向最终用户公开的行或列。
创建视图很简单:
CREATE OR REPLACE VIEW <view_name> AS SELECT col1 FROM table1 WHERE col1 > x; |
创建后,您可以运行:
SELECT * FROM <view_name> |
这个视图现在存储在数据库中,但它不占用任何空间(除非它被具体化)它只存储每次从视图中选择或在查询中加入视图时执行的查询。
视图可以放在 CTE 内部,或者它们本身可以包含 CTE,从而创建多层模块化。这是一个看起来像的例子:
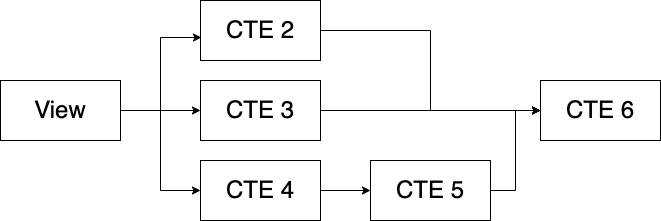
旁注: 通过组合视图和 CTE,您可以在其他查询中嵌套许多查询。这不仅会对性能产生负面影响,而且某些数据库对您可以拥有的嵌套级别有限制。
UDF
与视图类似,您还可以将常用逻辑放入 UDF(用户定义的函数)中。几乎所有数据库都允许您创建 UDF,但它们各自使用不同的编程语言来实现。
SQL Server 使用 T-SQL 创建函数。PostgreSQL 使用 PL/pgsql 或 Python(具有正确的扩展名)BigQuery 和 Snowflake 使用 Javascript、Python 等。
函数允许逻辑和变量的条件流,这使得复杂逻辑的实现变得容易。
UDF 可以返回单个标量值或表格。例如,单个标量值可用于通过正则表达式解析某些字符串。
表值函数返回一个表而不是单个值。它们的行为与视图完全一样,但主要区别在于它们可以获取输入参数并基于该参数返回不同的表。很有用。
存储过程
与表值函数一样,存储过程 (sprocs) 允许您将非常复杂的业务逻辑封装在数据库中。他们还返回表格作为输出。
它们在事务系统中被大量使用以在数据库内实现业务逻辑,但在数据处理中已经失宠。我不会在这里介绍它们。
级别 3 - 超越 SQL 查询
随着dbt (数据构建工具)等工具的出现,您可以超越视图和 CTE 的查询,构建更复杂的 dag,将它们结合起来。
在 dbt 术语中,视图和表被称为模型。通过使用函数ref()dbt 可以引用以前构建的模型。
您还可以将 CTE 与模型混合搭配,以获得所需的结果。
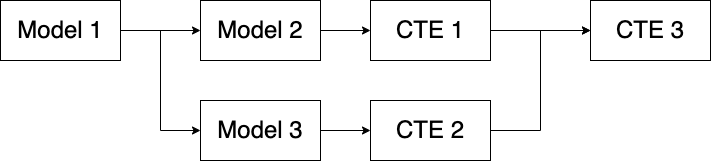
这是实践中的样子:
model_a.sql
select * from public.raw_data
model_b.sql
select * from {{ref('model_a')}}
如何将查询分解为更简单的模块
既然您已经了解了查询组合背后的理论,那么如何应用它呢?在编写查询时,您应用以下 3 条规则之一。它们同样适用于所有 3 个级别。
规则 1:不要重复自己(又名 DRY 原则)
DRY 原则指出,如果您发现自己在查询中多次复制粘贴相同的代码块,则应该将该代码放在 CTE 中并在需要的地方引用该 CTE。通过将重复的逻辑放入单独的模块中,您可以做到轻松编写、维护和调试代码。
规则 2:使模块具有单一用途(也称为 SRP 原则)
软件工程中的单一职责原则 (SRP) 表示每个模块都应该是独立的并且只有一个目的。该模块可以是 CTE、视图或 dbt 模型。
通过自包含和单一职责,每个模型都可以独立编写、测试和调试。Dbt 通过允许您创建宏或函数 (UDF) 来卸载责任,从而多次提高您的灵活性。
规则 3:将逻辑向上游移动
当您发现自己在可能在其他地方使用的模型中实现非常具体的逻辑时,请尽快将该逻辑移至上游。
在 DAG 的世界里,upstream 有着非常明确的含义。这意味着将潜在的通用逻辑移动到图中较早的节点上,因为您永远不知道哪些下游模型可能会使用它。
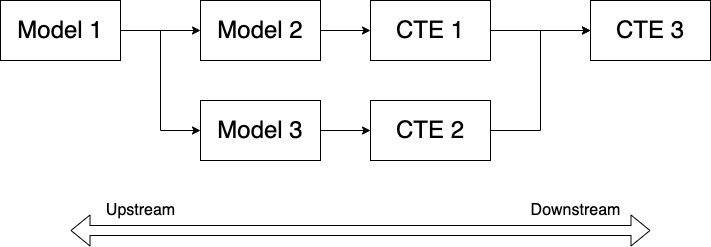
好的,这是足够的理论。单击此处查看示例。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK