
1

神經網路入門課程筆記
source link: https://blog.darkthread.net/blog/neural-network-moocs/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
神經網路入門課程筆記
| 2022-12-07 11:08 PM | 0 | 162 |
前幾個月因為自主防疫多出幾天空閒,時間沒拿來追劇倒是追了幾天 AI 線上課程。這個年頭,線上免費資源之多,讓你除了人懶毅力不夠,已無學不會的藉口。(鳴... 人生好難)
意外發現許多大學有所謂「磨課師」課程。磨課師課程是 MOOCs 的音譯,MOOCs 是 Massive Open Online Courses 縮寫,意指大規模開放式線上課程,磨課師強調互動,比大學課堂錄影形式的開放式課程(Open CourseWare,OCW)更精緻生動,對求學意志力已不夠堅定,看線上課堂影片會線上打瞌睡的老人來說,更容易消化吸收。
在政大磨課師平台找到一門蔡炎龍老師的 Python 實現人工智慧 ,課程內容還算淺顯易懂,數學部分點到為止(但人工智慧背後是滿滿的數學,想深入要有心理準備),讓本來對 AI 幾乎一無所知的我,對於神經網路、深度學習是怎麼一回事有了基本概念,甚至有能力自己訂個題目玩玩機器學習。
以下是看影片時抄的筆記,主要在記重點跟關鍵字,當作未來要深入學習的傳送點,分享給大家加減參考。
- 神經網路:主要分為 NN、CNN、RNN。其他:強化學習、生成對抗模式
- 人工智慧:問個好問題
- 將問題化成函數(解答本),輸入 X 得到 Y。給一堆已知 X 對映已知答案 Y (訓練資料),機器學習具備遇到未知輸入值也能猜出答案的能力。
- 訓練時將資料(考古題)分成兩組:訓練資料跟測試資料,一個用來調參數,一組用來驗證(Lost Function,差距愈小愈好)
- 讓差距愈小愈好的方法:Gradient Descent (梯度下降) (在神經網路叫 Backpropagation)
- 可以用 AI 解的問題:
- 某天的股價?用前一週資料預測下一期
- 某 MLB 選手在 2022 可以打幾支全壘打?用 t-1 年打擊資料測 t 年全壘打數 (RNN 會自動多看幾年)
- 對話機器人 => 輸入目前的字,得到回答 (RNN 會自動找出規律)
- AI 玩遊戲(自動駕駛、泡咖啡)
遊戲畫面用 CNN+NN 找出最好動作
強化學習: 畫面+動作 -> 函數 -> 評分
- 字型缺字:用現存的字型生出不存在的字型 (CNN、VAE、GAN)
- 標準 NN (Feedforward Fully-Connected Neural Network), input layer -> f (hidden layer) -> output layer
一堆神經元構成網路,隱藏層有三層以上就叫深度學習,設計時決定要有幾層,每層幾個神經元
每個神經元的動作都一樣,收到多個權重不同的輸入,送出一個輸出(傳給多個神經元)。 輸入乘權重(Weight)加總再加偏值(Bias),經激活函數(Activation Function)決定輸出,激活函數有三種:ReLU、Sigmoid、Gaussian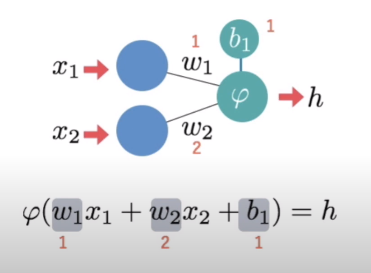
- 學習方法:Backpropagation,θ 為 w 跟 b 集合,每個 θ 定義一個函數 Fθ,找出讓 Lost Function 最小的 θ
- Lost Function = 所有誤差值的平方和 (MSE)
- 假設權重只有一個 w 比較好想像,再推成多 w,原理相同。數學上用切線斜率(微分)決定該向左還是向右移:
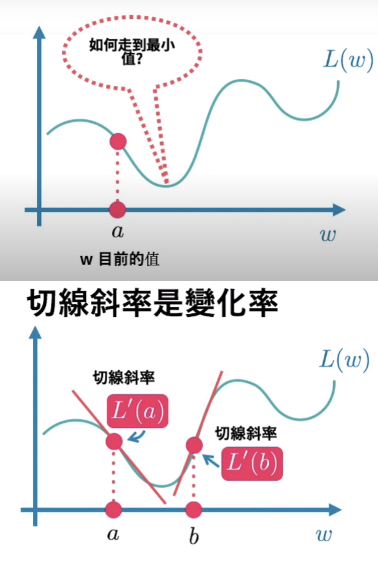
調整方向 w - η (Learning Rate,避免調過頭) * dL / dw 推導出 [w1,w2,b1] - η * [∂L/∂w1,∂L/∂w2,∂L/∂b1] (∂=偏微分) = [w1,w2,b1] - η * ▽L (Gridient 梯度) - NN 練習:手寫字 0 - 9 辦識,掃瞄手寫內容像素成為 28x28=784 陣列當成輸入,輸出 float[] r = new float[10], r[3] == 1 表示數字 3 機率為 100% (One-Hot Encoding) 784 維轉 10 維,10 維陣列加總要等於 1 (用 Soft Max,r[i] / Sum(r[0..9])
- 資料來源:Modified National Institute of Standard and Technology (MNIST) 的手寫資料庫。(深度學習大師 Hinton 稱它為「機器學習的果蠅」) 訓練資料 6 萬筆、測試資料 1 萬筆
- 兩個隱藏層,神經元數目隨便(例如 500 個)
- Stochastic Grandient Descent: SGD, 用打亂順序資料去訓練,以免背答案
- 使用 Keras
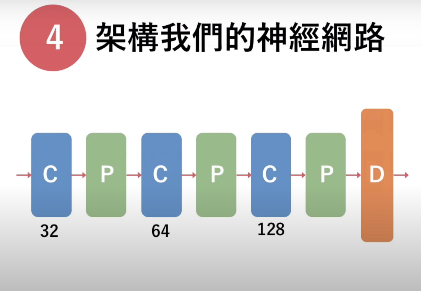
- CNN Convolutional Neural Network,捲積雲神經網路。讓機器學習紅起來的關鍵,圖形辦識的超級天王
- LeCun (FB 首席 AI 科學家)-Bengio-Hinton, Deep Learning 三巨頭 (2015 期刊發表文章)
- 圖形識別 - 建立 Filter,每個 Filter 看一種特徵 (直線、橫線...)
- Convolutional Layer - 做 Filter,8x8 圖片,3x3 像素矩陣乘 3x3 權重矩陣,內積取一個數字,得到一個相同大小矩陣(用一些技巧 6x6 升 8x8)
Filter 一多,資料變很大 - Max-Pooling Layer - 用投票減少資料量,2x2 取最大的(Max-Pooling),6x6 變 3x3, Convolution -> Max-Pooling -> Convolution -> Max-Pooling...
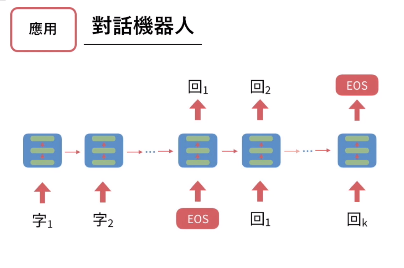
- RNN Recurrent Neural Network - 有記憶的神經網路,把上次輸出資料當成本次輸入
- 有名應用:對話機器人,f(目前的字) = 下個字 (前後文)
翻譯、影片描述、生成一段文字、完成畫一半的圖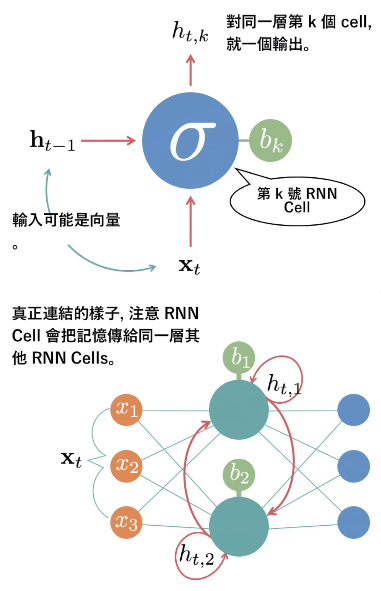
- RNN 常見問題 - 前面部分調不到,改良:Long Short Term Memory (LSTM)、Gated Recurrent Unit (GRU)
- 練習:IMDB 分析評論是好評或負評。IMDB 資料庫,訓練 25000 筆、測試 25000 筆
1 萬個常用字 One-Hot Encoding -> Embedding 層 -> RNN 層:150 個 RNN Cell (LSTM) -> Desnse
前置處理,前 100 個字,太短補 0, - Word Embedding 將 10000 維(1 萬常用字)變成 128 維
- Loss 用 binary_crossentropy, Optimizer 用 adam
- Sequential 傳統做法,線性堆疊,有一層錯,所有層都要重新定義
md = Sequential() md.add(Dense(3, input_shape=(2,))) md.summary() md.add(Dense(2)) md.add(Dense(3)) md.summary() - 轉移學習:將訓練好模型的一部分搬到新模型
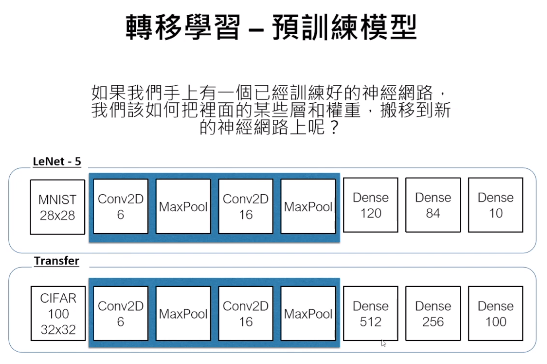
- 資料不平均(Imbalance),例如:糖尿病資料來源,有病的佔多數,因為健康的人不會主動檢查
- 不同設定 Sequential 的做法 模型定義跟權重資料可分開儲存,重新組裝利用,已訓練過的參數直接用。例子:識別 0-9 模型改成識別 0 或 1,速度快 N 倍。
first_layer = [Dense(500, input_dim=784), Activation('sigmoid')] model = Sequential(fist_layer + second_layer + output_layer) # .... for layer in all_except_last: layer.trainable = False - Keras 上一些 Pre-Trained 模型:
- Xception
- VGG16
- VGG19
- ResNet50
- InceptionV3
- InceptionResNetV2
- MobileNet
- DenseNet
- NASNet
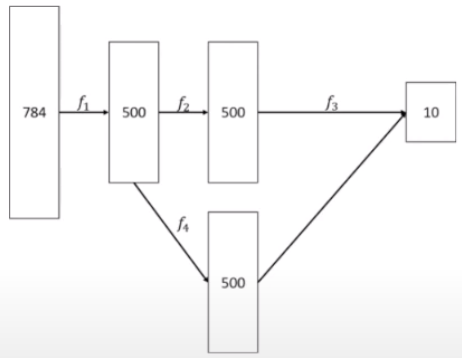
- 用 Model 指令建立線性堆疊模型
R^784 --f1--> R^500 --f2--> R^500 --f3-> R^10f_1 = Dense(500, activation='sigmoid') f_2 = Dense(500, activation='sigmoid') f_3 = Dense(10, activation='softmax') x = Input(shape=(784,)) h_1 = f_1(x) h_2 = f_2(h_1) y = f_3(h_2) model = Model(x, y) model.summary() model.compile(loss='mse', optimizer=SGD(lr=0.1), metrics=['accuracy']) model.fix(x_train, y_train, batch_size=100, epochs=5) - 分歧再合併(Branch-and-Merge)
- 自訂不具訓練權重的神經網路層
TensorFlow 與 Python 類別撰寫,範例:計算平均值、抽樣功能 - Varitional Autoencoder (VAE) 非監督式學習模型:會用到分歧-合併、抽樣函數
- AutoEncoder Rn --Encoder-> Rm --Decoder-> Rn 先降維再升維
x --Encoder-> h --Decoder-> x (h 稱為 Latent 變數、Latent 表示)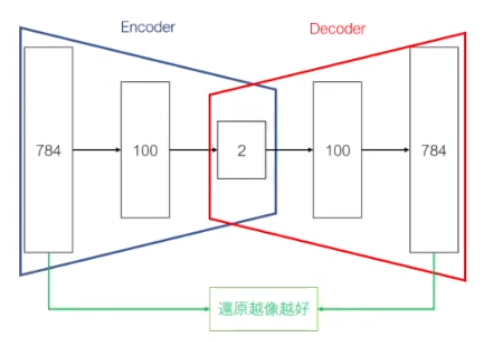
- VAE 比 AutoEcnoder 提供更好的視覺化表現(降維後的分群較符合預期)
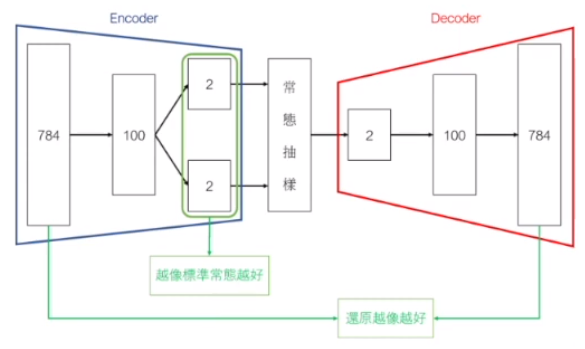
Loss 函數會用到訊息理論(Information Theory)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK