

基于训练和推理场景下的MindStudio高精度对比
source link: https://blog.51cto.com/u_15214399/5916313
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于训练和推理场景下的MindStudio高精度对比
精选 原创摘要:MindStudio提供精度比对功能,支持Vector比对能力。
本文分享自华为云社区《 【MindStudio训练营第一季】MindStudio 高精度对比随笔》,作者:Tianyi_Li。
训练场景下,迁移原始网络 (如TensorFlow、PyTorch) ,用于NPU上执行训练,网络迁移可能会造成自有实现的算子运算结果与用原生标准算子运算结果存在偏差。推理场景下, ATC模型转换过程对模型进行优化,包括算子消除、算子融合算子拆分,这些优化也可能会造成自有实现的算子运算结果与原生标准算子(如TensorFlow、ONNX、 Caffe ) 运算结果存在偏差。
为了帮助开发人员快速解决算子精度问题,需要提供自有实现的算子运算结果与业界标准算子运算结果之间进行精度差异对比的工具。
精度比对工具能够帮助开发人员定位本次任务两个网络间的精度差异。准备好昇腾腾AI处理器运行生成的dump教据与Ground Truth数据 (基于GPU/CPU运行生成的数据)后,即可进行不同算法评价指标的数据比对。
MindStudio提供精度比对功能,支持Vector比对能力,支持下列算法:
- 余弦相似度
- 最大绝对误差
- 累积相对误差
- 欧氏相对距离
- KL散度…
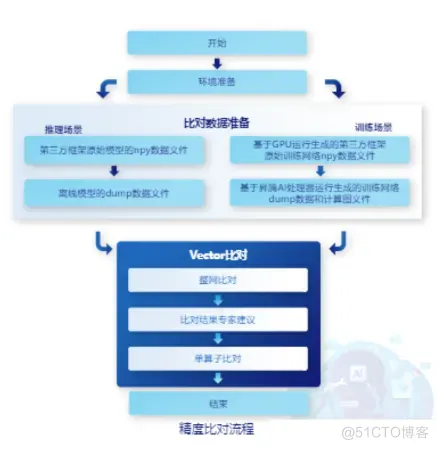
精度比对根据推理/训练和不同的框架分为多个比对场景。
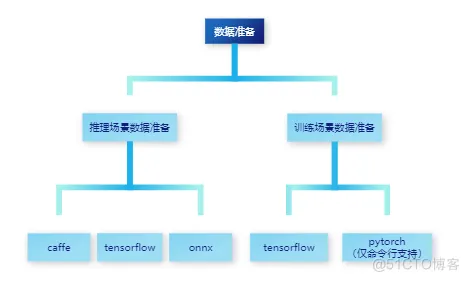
原始模型数据即为原始网络在GPU/CPU侧生成的数据,主要依赖原始框架中的源生能力,将模型中每一个算子节点的输入输出数据进行保存。
NPU模型数据即为通过对原始模型的迁移或训练在县腾A处理器上得到的数据,主要依赖华为侧提供对应用推理及训练提供的Dump能力,将模型中每一个算子节点的输入输出数据进行保存。
由于MindStudio精度比对工具的使用约束,数据需要满足以下格式:

原始模型数据准备
以TensorFlow为例
在进行TensorFlow模型生成npy数据前,您需要已经有一套完整的、可执行的、标准的TensorFlow模型应用工程。然后利用TensorFlow官方提供的debug工具tfdbg调试程序,从而生成npy文件。通常情况下,TensorFlow的网络实现方式主要分为Estimator模式和session.run模式,具体操作如下:
1.修改tf训练脚本,添加debug选项设置
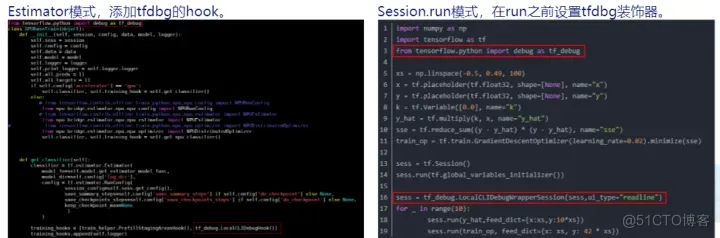
2.执行推理或训练脚本,任务运行到前面debug配置后暂停
3.进入调试命令行交互模式后,
- 3.1 输入run命令,训练会往下执行一个step
- 3.2 执行lt >tensor name将所有tensor的名称暂存到文件里,在另一个窗口,在Linux命令下执行下述命令,用以生成在tfdbg命令行执行的命令:
- 3.3 将上一步生成的tensor name cmd.txt文件内容粘贴执行,即可存储所有npy文件,实现训练数据的Dump。
注: 更加详细操作见《CANN开发辅助工具指南》中“精度比对工具使用指南”章节。
NPU模型数据准备
以推理场景为例
推理场景数据准备一NPU的融合后推理数据NPU采用AscendCL完成离线推理:
1.在代码中调用acllnit(“./acl.json”)
acl.json的文件内容如下:

2.运行推理应用,生成dump数据
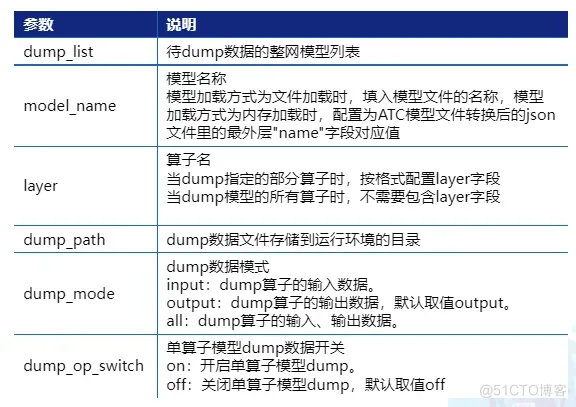
以训练场景为例
训练场景数据准备-NPU的迁移后网络训练数据
以TensorFlow为例,步骤如下:
1.设置“DUMP GE GRAPH=2”生成计算图文件,同时修改训练脚本,开启dump功能

2.执行训练脚本,生成dump数据和计算图文件
- 计算图文件:“ge”开头的文件,存储在训练脚本所在目录
- dump数据文件: 生成在dump path指定的目录下,即(dump path)/time)/(deviceid)/(model name)/(model id)/(data index) 。
3.选取计算图文件
可使用grep lterator* Build.txt命令快速查找出的计算图文件名称,如ge proto 00005 Build.txt.
4.选取dump数据文件
打开上述计算图文件,找出第一个graph中的name字段,即为dump文件存放目录名称。
精度对比工具使用方法
创建对比任务
将准备好的标准数据文件与待比对数据文性作为输入文件,并配置对应的离线模型文件,通过对文件内所有参与计算的算子输入与输出进行精度比对。
整网比对在MindStudio界面菜单栏洗择“Ascend > Model Accuracy Analvzer > New Task菜单,进入比对界面。
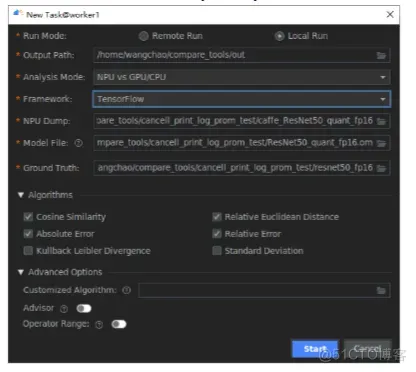
整网对比结果
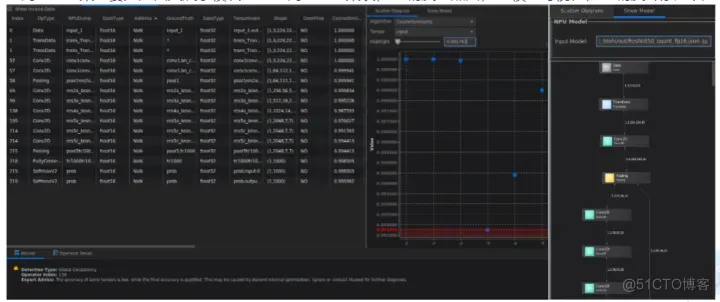
整网比对结果主要分为四大展示模块:
- 整网对比结果表;
- 精度散点图;
- 模型可视化:
- 精度专家建议
精度比对工具本身只提供自有实现算子在昇腾AI处理器上的运算结果与业界标准算子的运算结果的差异比对功能,而输出的比对结果需要用户自行分析并找出问题。而对结果的分析工作对于用户来说也是一大难点,而专家系统工具为用户提供精度比对结果的结果分析功能,有效减少用户排查问题的时间。只需在比对操作配置任务时勾选“Advisor”选项,系统则会在比对完成后自动进行结果文件的分析,并输出优化建议。
当前支持的分析检测类型有:FP16溢出检测、输入不一致检测、整网一致性检测(整网一致性检测包括:问题节点检测、单点误差检测和一致性检测三个小点)
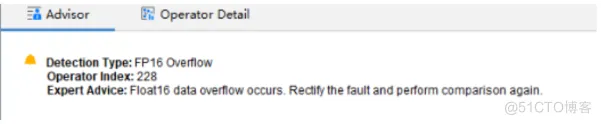
这里特别说明下FP16溢出检测,针对比对数据中数据类型为FP16的数据,进行溢出检测。如果存在溢出数据,输出专家建议,示例图如下所示。
Detection Type: FP16 overflow
Operator Index: 228
Expert Advice: Float16 data overflow occurs. Rectify the fault and perform comparison again.
检测类型:FP16溢出检测
Operator Index:228
专家建议:存在Float16数据溢出,请修正溢出问题,再进行比对。
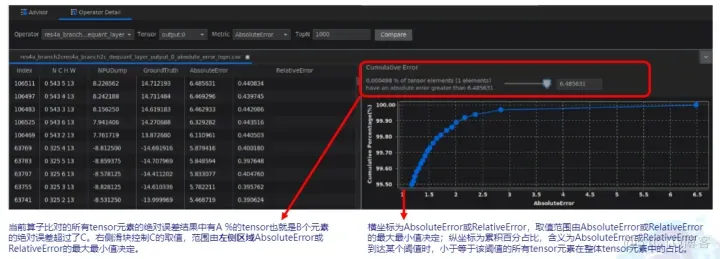
单算子对比
可针对整网任务中的某个算子进行单算子比对,分析某个算子的具体精度差异。
使用约束
- 精度比对功能不支持打开多个工程同时进行比对,可以先完成一个比对程序后再进行下一个。
- 精度比对支持的dump数据的类型:
FLOAT16
DT_INT8
DT_UINT8
DT_INT16
DT_UINT16
DT_INT32
DT_INT64
DT_UINT32
DT_UINT64
DT_BOOL
DT_DOUBLE
dump文件无法通过文本工具直接查看其内容,为了查看dump文件内容,需要用脚本将dump文件转换为numpy格式文件后,再通过numpy官方提供的能力转为txt文档进行查看。脚本在/home/HwHiAiUser/Ascend/ascend-toolkit/latest/tools/operator_cmp/compare目录,名为msaccucmp.py。举例用法如下:
调用Python,转换numpy文件为txt文件的完整示例如下:
>>> import numpy as np
>>> a = np.load("/home/HwHiAiUser/dumptonumpy/Pooling.pool1.1147.1589195081588018.output.0.npy")
>>> b = a.flatten()
>>> np.savetxt("/home/HwHiAiUser/dumptonumpy/Pooling.pool1.1147.1589195081588018.output.0.txt", b)
但转换为.txt格式文件后,维度信息、Dtype均不存在。详细的使用方法请参考numpy官网介绍。
精度对比总计分为环境准备、数据准备和对比三步。
数据准备要根据推理场景和训练场景分别分析:
- 推理场景:准备第三方框架原始模型的npy数据文件与离线模型的dump数据文件。
- 训练场景:准备基于GPU运行生成的第三方框架原始训练网络npy数据文件与基于昇腾AI处理器运行生成的训练网络dump数据和计算图文件。
准备后上述步骤,可进行对比:
- 执行整网比对操作。
- 开启MindStudio的“Ascend > Model Accuracy Analyzer”功能,将准备好的比对数据文件配置到对应参数下并配置具体比对参数。
- MindStudio执行比对操作并输出比对结果。
- 比对结果专家建议(可选)。请参见比对结果专家建议。
- 根据分析结果定位具体问题算子。
- 执行单算子比对操作。
- 分析单算子具体问题。
最后说下Tensor比对,Tensor对比提供整网比对和单算子比对两种精度比对方式,需要根据比对场景选择比对方式。其中,整网比对:将准备好的标准数据文件与待比对数据文件作为输入文件,通过对文件内所有参与计算的算子进行精度比对。而单算子比对:在整网比对的基础上指定具体算子名,对单个算子进行详细数据的比对。
个人认为,精度对比这是一个需要时间、精力和经验的操作,要充分利用好MindStudio工具,或查文档,或提问,可大大降低我们的工作量,提高效率。但是不得不说,这是需要一定经验的,还是要多看多学习,多试多问啊。
Recommend
-
27
导读: 本文主要分享 小米 AI 实验室 NLP 团队 在 NLPCC 轻量级语言模型比赛 上的经验,以及我们在预训练模型推理优化上所作的工作和达到的实际落地后的效果。此次分享的目的是帮助大家快速进入比赛,...
-
12
ML训练推理的大规模数据吞吐解决思路
-
16
作者:dickzhu、raccoonliu、beiping 导语 NLP 任务(序列标注、分类、句子关系判断、生成式)训练时,通常使用机器学习框架 Pytorch 或 Tensorflow,在其之上定义模型以及自定义模型的数据预处理,这种方...
-
10
机器之心报道 机器之心编辑部 在AI计算机训练与推理领域,存在着这样一种理念:如果计算需求很大,那么为其提供动力所需的能量也将很大。这种理念也被该领域广泛接受。那么有没有可能开发出...
-
6
作者|Chien Vu 编译|Flin 来源|towardsdatascience 背景与挑战📋 在现代深度学习算法中,对未标记数据的手工标注是其主要局限性之一。为了训练一个好的模型,我们通常需要准备大量的标记数据。在少数类和数据的情况下,我们可以使用...
-
6
面向推理训练一体化的 MNN 工作台 作者:修玉同(音弦) MNN 工作台是阿里淘系端智能团队构建并对外免费开放的一站式端侧 AI 研发平台,它基于已开源的 MNN 深度学习端侧推理引擎(开源地址:
-
5
9.2. 训练模型到推理模型的转换及优化 ¶...
-
6
摘要:MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。本文分享自华为云社...
-
4
摘要:本实践是基于Windows版MindStudio 5.0.RC3,远程连接ECS服务器使用,ECS是基于官方分享的CANN6.0.RC1_MindX_Vision3.0.RC3镜像创建的。 本文分享自华为云社区《
-
6
摘要:本实践是基于Windows版MindStudio 5.0.RC3,远程连接ECS服务器使用,ECS是基于官方分享的CANN6.0.RC1_MindX_Vision3.0.RC3镜像创建的。本文分享自华为云社区《
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK