

Flink SQL管理平台flink-streaming-platform-web安装搭建
source link: https://blog.51cto.com/ikeguang/5916040
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Flink SQL管理平台flink-streaming-platform-web安装搭建
推荐 原创最近看到有人在用flink sql的页面管理平台,大致看了下,尝试安装使用,比原生的flink sql界面确实好用多了,我们看下原生的,通过bin/sql-client.sh命令进入那个黑框,一只松鼠,对,就是那个界面。。。。
这个工具不是Flink官方出的,是一个国内的小伙伴写的,Github地址:
https://github.com/zhp8341/flink-streaming-platform-web
根据github上,作者的描述,flink-streaming-patform-web主要功能:
- [1] 任务支持单流 、双流、 单流与维表等。
- [2] 支持本地模式、yarn-per模式、STANDALONE模式 Application模式
- [3] 支持catalog、hive。
- [4] 支持自定义udf、连接器等,完全兼容官方连接器。
- [5] 支持sql的在线开发,语法提示,格式化。
- [6] 支持钉钉告警、自定义回调告警、自动拉起任务。
- [7] 支持自定义Jar提交任务。
- [8] 支持多版本flink版本(需要用户编译对应flink版本)。
- [9] 支持自动、手动savepoint备份,并且从savepoint恢复任务。
- [10] 支持批任务如:hive。
- [11] 连接器、udf等三jar管理
是不是觉得很强大,很多同学已经摩拳擦掌想试试了。
这里只介绍flink on yarn模式的安装,如果你的hadoop集群已经安装好了,大概半个小时就能好;否则,安装hadoop集群可老费事儿了。总体步骤如下:
第一步 hadoop集群
这里假设你的hadoop集群是好的,yarn是可以正常使用的,8088端口可以访问,如下:
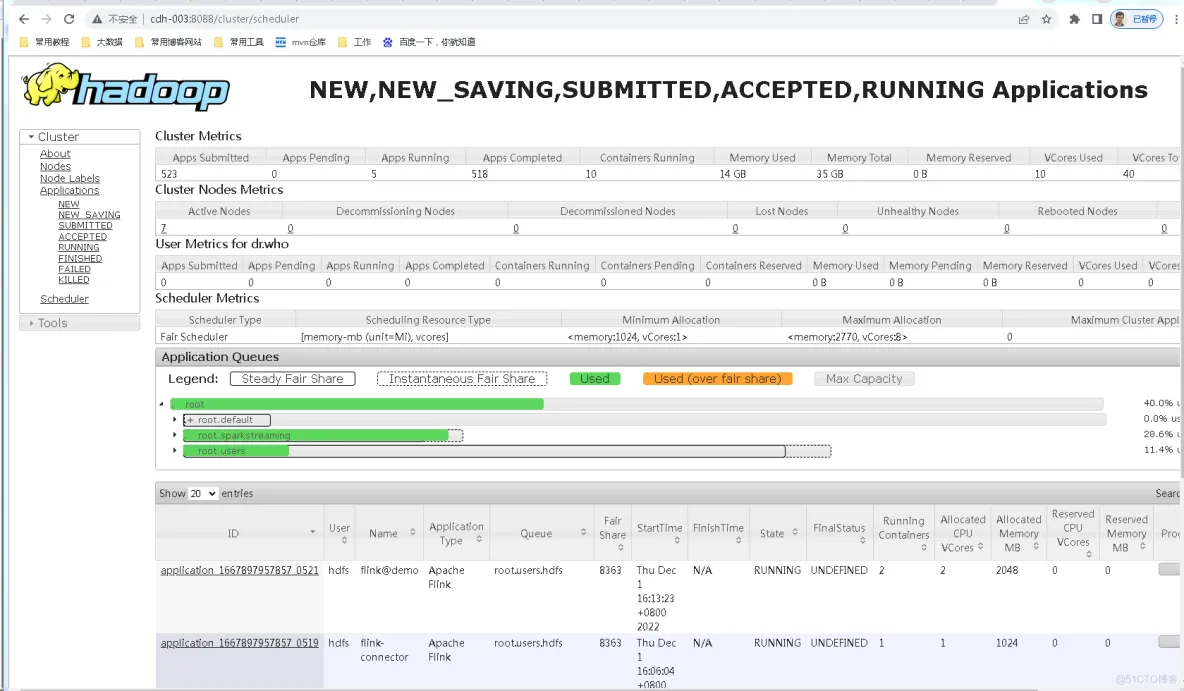
第二步 下载flink
flink on yarn,只需要下载一个flink安装包即可使用,下载命令:
http://archive.apache.org/dist/flink/flink-1.13.5/flink-1.13.5-bin-scala_2.11.tgz
tar -xvf flink-1.13.5-bin-scala_2.11.tgz
关键:这里问题来了,我的flink怎么识别hadoop呢,需要配置一个环境变量,编辑 /etc/profile,键入内容:
export HADOOP_CONF_DIR=填你的hadoop配置文件目录,比如我的是/usr/local/hadoop2.8/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`
好了,这样一个flink on yarn的环境就搭建好了。
第三步 安装flink-streaming-patform-web
官方地址文章开头已经给出,在github找到下载地址: https://github.com/zhp8341/flink-streaming-platform-web/releases/,我下载的版本是这个。
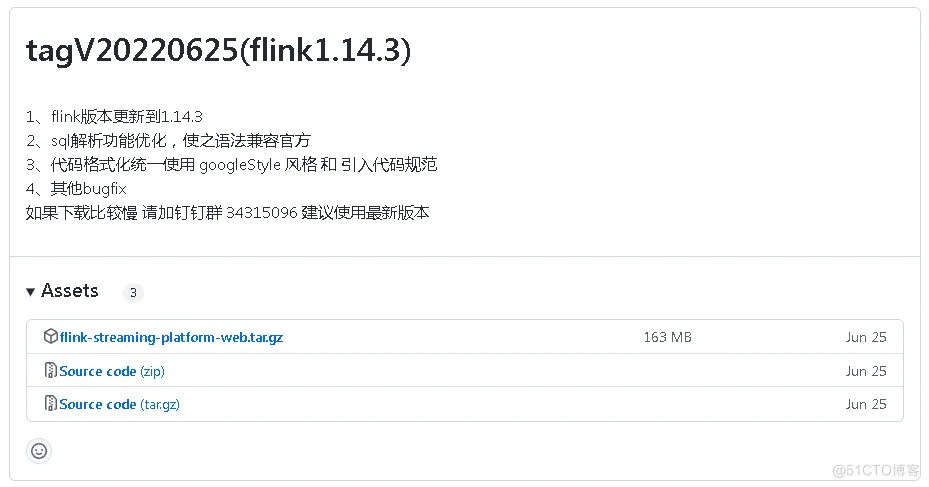
为什么我下的是适配flink 1.14.3的,我前面安装flink1.13.5,我也是下了一堆flink,经过尝试,才发现flink1.13.5这个版本,适配flink-streaming-platform-web tagV20220625。
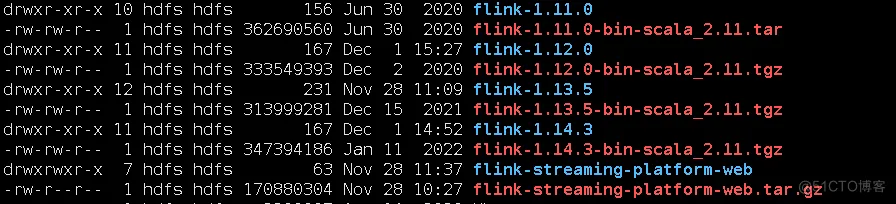
解压后,修改配置文件:application.properties,懂的人知道这个其实是个springboot的配置文件。
#### jdbc信息
server.port=9084
spring.datasource.url=jdbc:mysql://192.168.1.1:3306/flink_web?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=bigdata
spring.datasource.password=bigdata
这里配置了一个数据库,需要自己新建一下,建表语句作者给出了: https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql/flink_web.sql,把这段sql执行一下,在flink_web数据库建相应的一些整个系统运行需要的表。
启动web服务
# bin目录下面的命令
启动 : sh deploy.sh start
停止 : sh deploy.sh stop
服务启动后,通过9084端口在浏览器访问
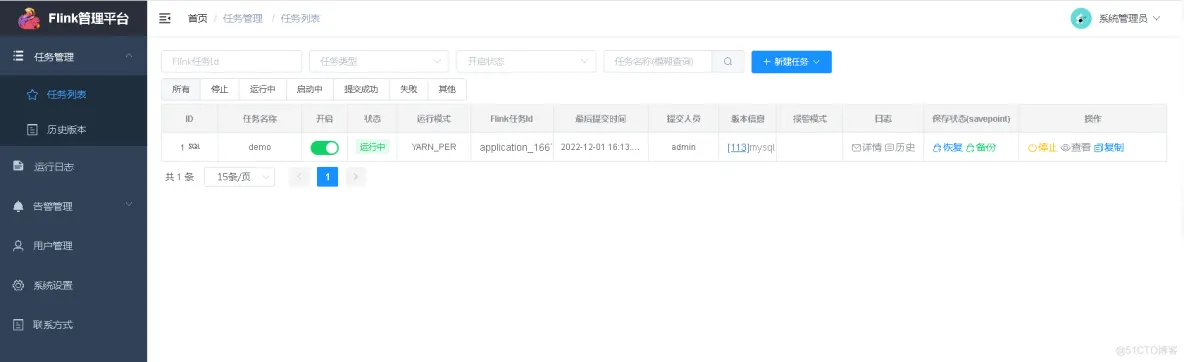
第四步 配置flink web平台
这一步很关键,页面上点击系统设置,进入配置页面:
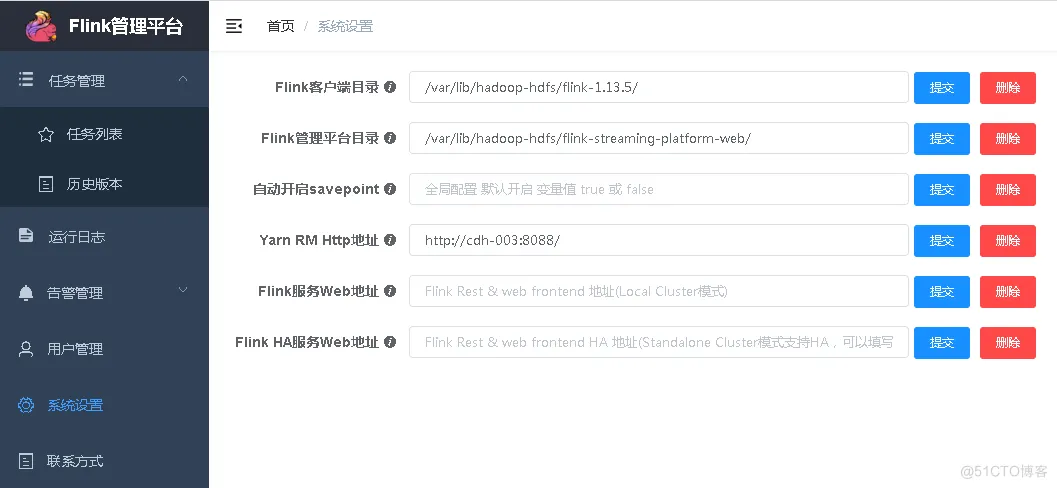
这里的参数意义:
- Flink客户端目录:就是安装的Flink目录;
- Flink管理平台目录:就是下载的flink-streaming-platform-web放的目录;
- yarn RM http地址:就是yarn.resourcemanager.webapp.address,通常是8088端口;
经过测试,配置这3个参数即可使用。
第五步 运行demo
这里以官方demo为例,[ demo1 单流kafka写入mysqld 参考]( https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql_demo/demo_1.md),这是一个通过flink sql消费kafka,聚合结果写入mysql的例子。
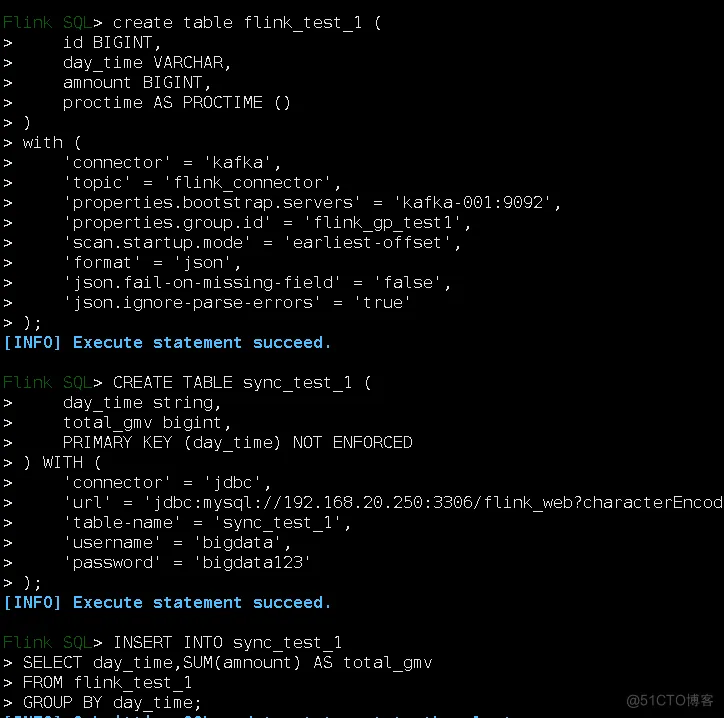
- 在flink_web数据建表
CREATE TABLE sync_test_1 (
`day_time` varchar(64) NOT NULL,
`total_gmv` bigint(11) DEFAULT NULL,
PRIMARY KEY (`day_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 下载依赖jar包
因为涉及到kafka和mysql,需要对应的connector依赖jar包,下图中标注出来了,放在Flink的lib目录(/var/lib/hadoop-hdfs/flink-1.13.5/lib)下面:
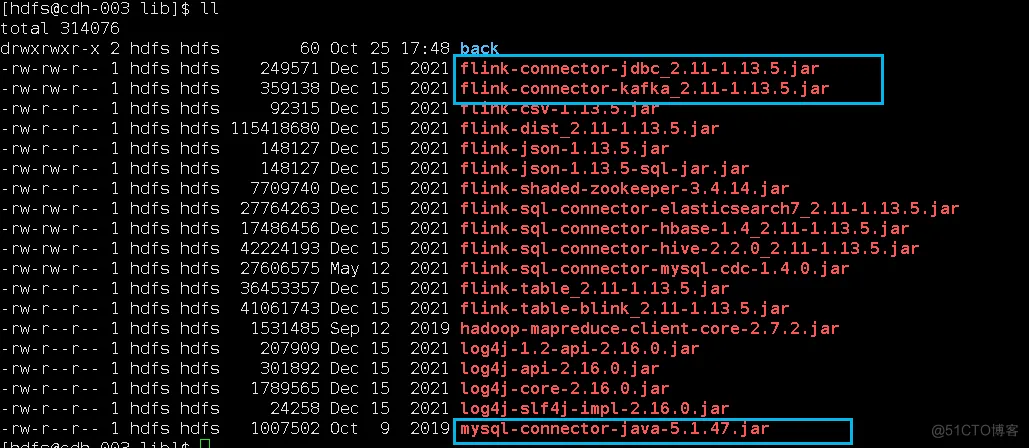
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc_2.11/1.13.5/flink-connector-jdbc_2.11-1.13.5.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.11/1.13.5/flink-connector-kafka_2.11-1.13.5.jar
技巧:下载Flink的依赖jar包,有个地方下载很方便,地址是:
https://repo1.maven.org/maven2/org/apache/flink/
这样依赖,一切都准备好了。
在web页面新建sql流任务:
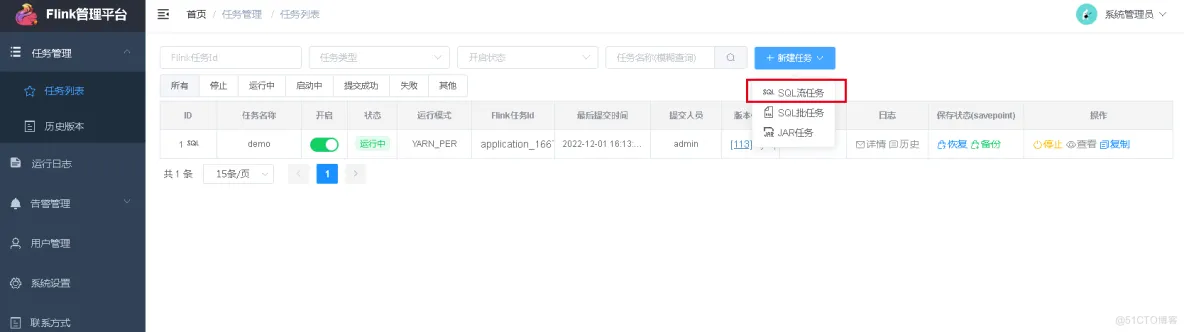
我建的一个,任务属性我是这样填写的:
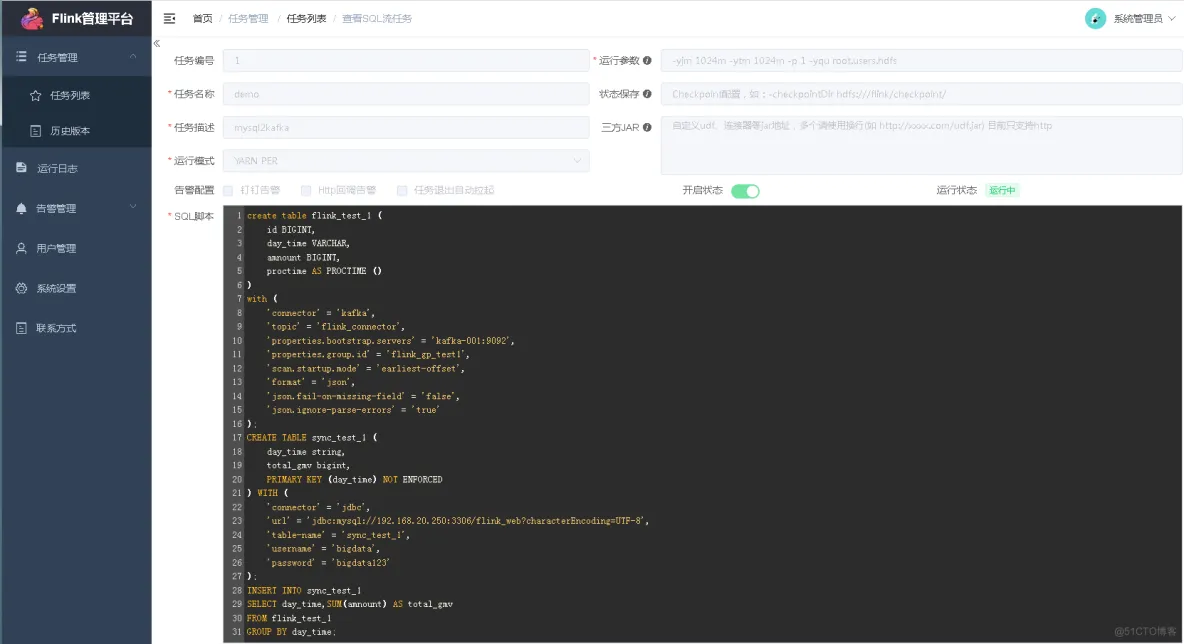
sql脚本内容:
create table flink_test_1 (
id BIGINT,
day_time VARCHAR,
amnount BIGINT,
proctime AS PROCTIME ()
)
with (
'connector' = 'kafka',
'topic' = 'flink_connector',
'properties.bootstrap.servers' = 'kafka-001:9092',
'properties.group.id' = 'flink_gp_test1',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
CREATE TABLE sync_test_1 (
day_time string,
total_gmv bigint,
PRIMARY KEY (day_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.1.1:3306/flink_web?characterEncoding=UTF-8',
'table-name' = 'sync_test_1',
'username' = 'bigdata',
'password' = 'bigdata'
);
INSERT INTO sync_test_1
SELECT day_time,SUM(amnount) AS total_gmv
FROM flink_test_1
GROUP BY day_time;
创建好任务后,启动任务吧。
启动后,可以在yarn的8088端口页面看到起了一个application,名称是新建任务填写的名称加flink@前缀:
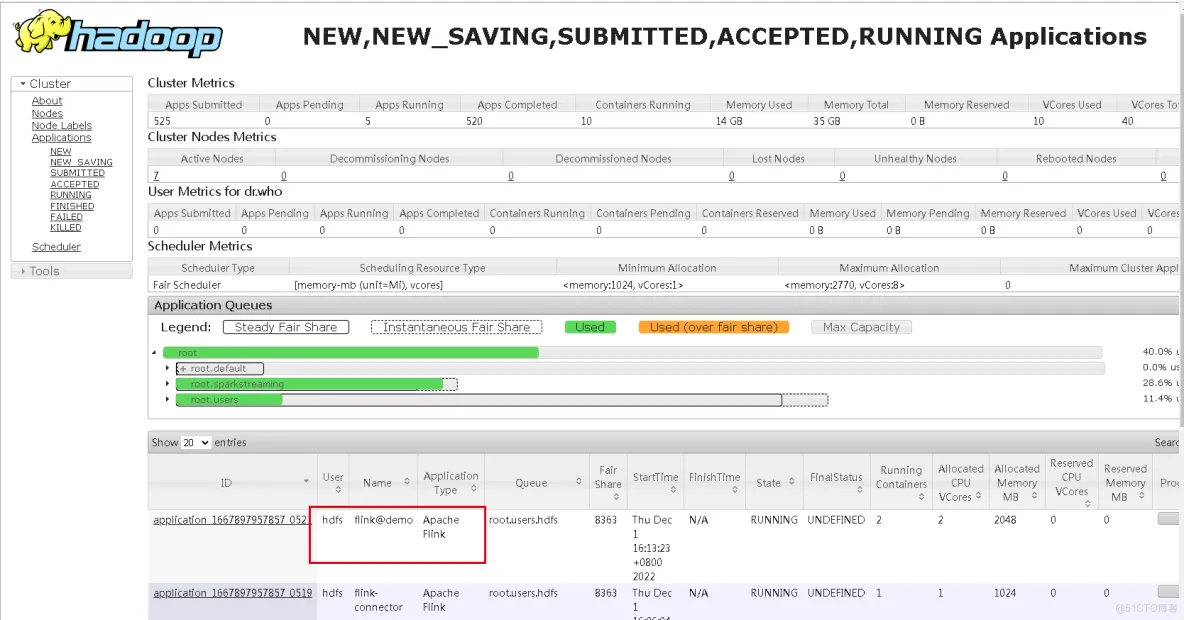
这个任务,我们点进去看,通过管理平台提交的sql任务确实跑起来了,这个页面了解Flink的同学就很熟悉了:
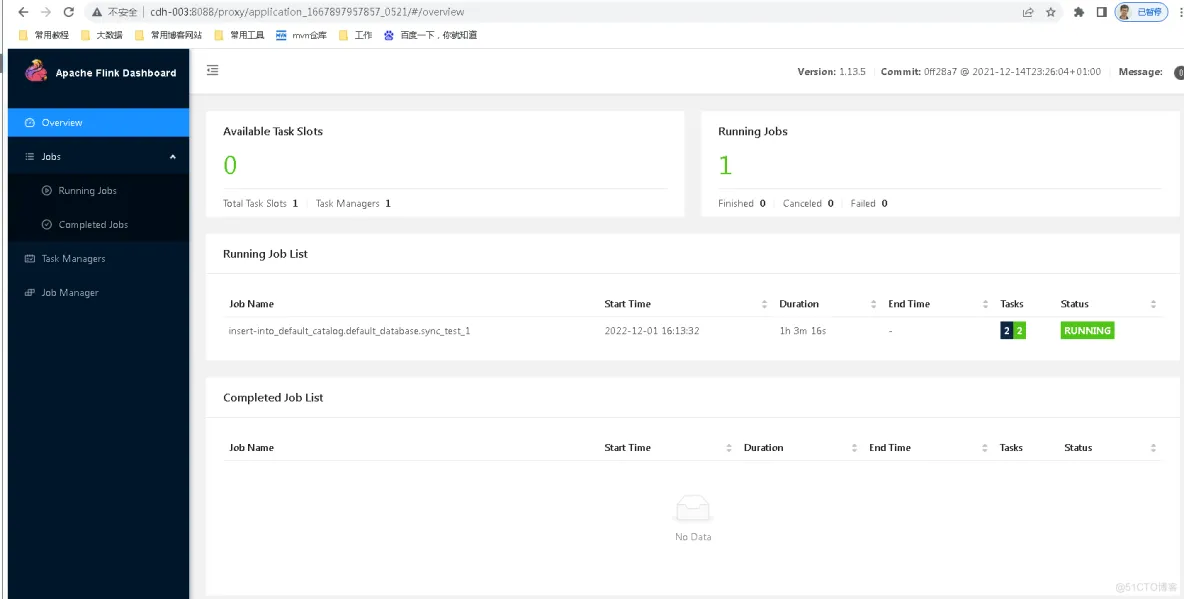
其实,这段sql脚本,我们可以在flink的bin/sql-client.sh进入的那个小松鼠的黑框里面执行的,你们可以试一下。
kafka控制台往主题里面写数据,主题不存在会自动创建:

我们再看看mysql里面:

数据已经进来了。
与Flink SQL的比较
我们可以看到,flink-streaming-platform-web这个工具只是让我们不需要在这个黑框里面写sql了,而是在网页上面写sql,系统会把写的sql进行校验给flink去执行,不管是flink-streaming-platform-web网页也好,还是那个黑框sql控制台,都是客户端,本质上都是flink提供的一些table api去执行任务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK