

医疗在线OLAP场景下基于Apache Hudi 模式演变的改造与应用 - leesf
source link: https://www.cnblogs.com/leesf456/p/16950428.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
医疗在线OLAP场景下基于Apache Hudi 模式演变的改造与应用
在 Apache Hudi支持完整的Schema演变的方案中(https://mp.weixin.qq.com/s/rSW864o2YEbHw6oQ4Lsq0Q), 读取方面,只完成了SQL on Spark的支持(Spark3以上,用于离线分析场景),Presto(用于在线OLAP场景)及Apache Hive(Hudi的bundle包)的支持,在正式发布版本中(Hudi 0.12.1, PrestoDB 0.277)还未支持。在当前的医疗场景下,Schema变更发生次数较多,且经常使用Presto读取Hudi数据进行在线OLAP分析,在读到Schema变更过的表时很可能会产生错误结果,造成不可预知的损失,所以必须完善Presto在读取方面对Schema完整演变的支持。
另外用户对使用presto对Hudi读取的实时性要求较高,之前的方案里Presto只支持Hudi的读优化方式读取。读优化的情况下,由于默认的布隆索引有如下行为:
- insert 操作的数据,每次写入提交后能够查询到;
- update,delete操作的数据必须在发生数据合并后才能读取到;
- insert与(update,delete)操作 presto 能够查询到的时间不一致;
- 所以必须增加presto对hudi的快照查询支持。
由于Presto分为两个分支(Trino和PrestoDB),其中PrestoDB的正式版本已经支持快照查询模式,而Trino主线还不存在这个功能,所以优先考虑在PrestoDB上实现,我们基于Trino的方案也在开发中。
计划基于Prestodb的Presto-Hudi模块改造,设计自 RFC-44: Hudi Connector for Presto。单独的Hudi连接器可以抛开当前代码的限制,高效地进行特定优化、添加新功能、集成高级功能并随着上游项目快速发展。
-
read_optimized(读优化):COW表和MOR表的ro表,只读取parquet文件的查询模式
-
snapshot(快照):MOR表的rt表,读取log文件和parquet并计算合并结果的查询模式
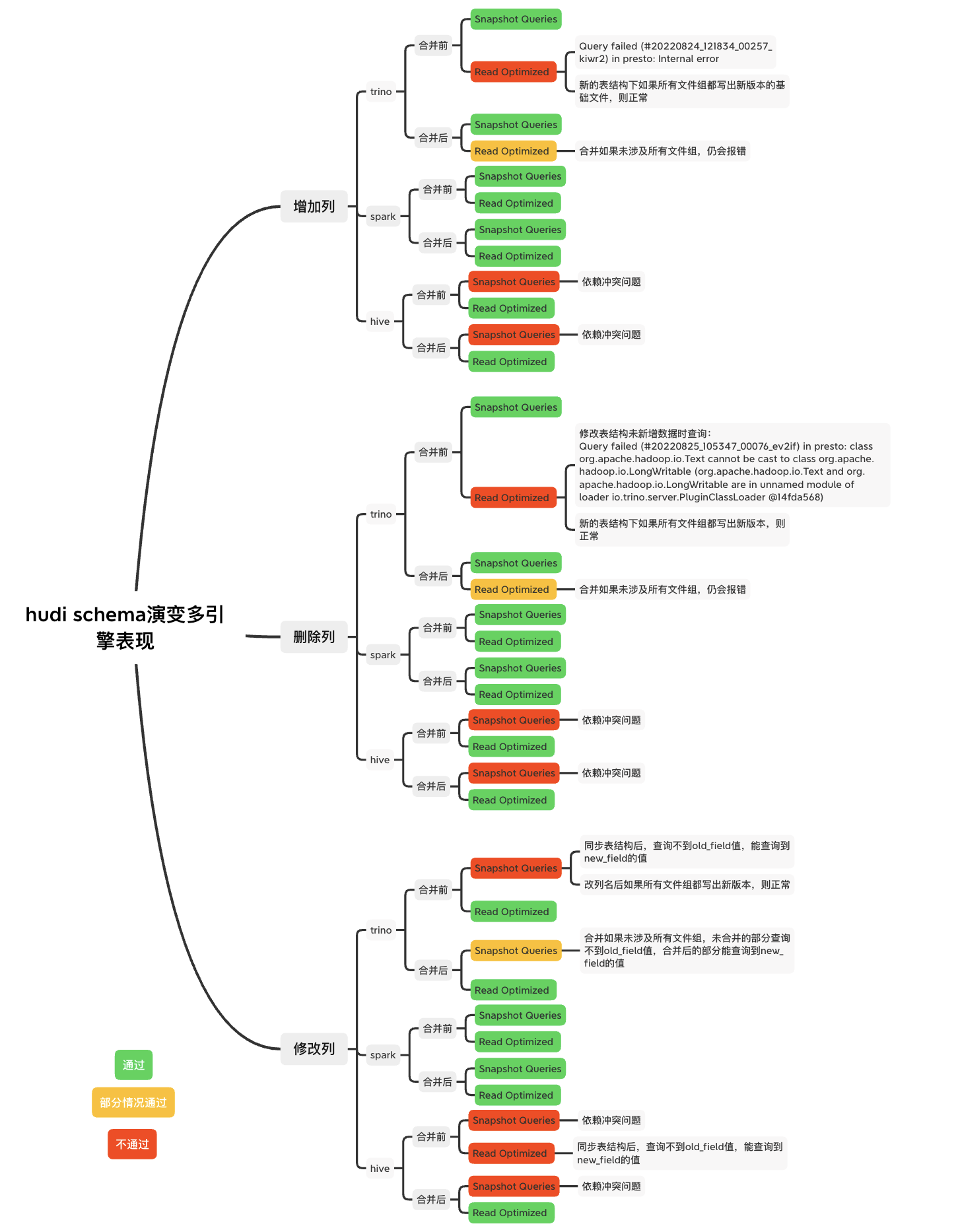
Hudi的Schema演变过程中多种引擎的表现
其中trino是以官方360版本为基础开发的本地版本,部分参考某打开状态的pr,使其支持了快照查询
Hive对Hudi支持的情况
hive使用hudi提供的hudi-hadoop-mr模块的InputFormat接口,支持完整schema的功能在10月28日合入Hudi主线。
Trino对Hudi支持的情况
Trino版本主线分支无法用快照模式查询。Hudi连接器最终于22年9月28日合入主线,仍没有快照查询的功能。本地版本基于trino360主动合入社区中打开状态的pr(Hudi MOR changes),基于hive连接器完成了快照查询能力。
PrestoDB对Hudi支持的情况
PrestoDB版本主线分支支持Hudi连接器,本身没有按列位置获取列值的功能,所以没有串列问题,并且支持快照查询模式。
-
Hudi: 0.12.1
-
Presto: 0.275
该模块的设计如下
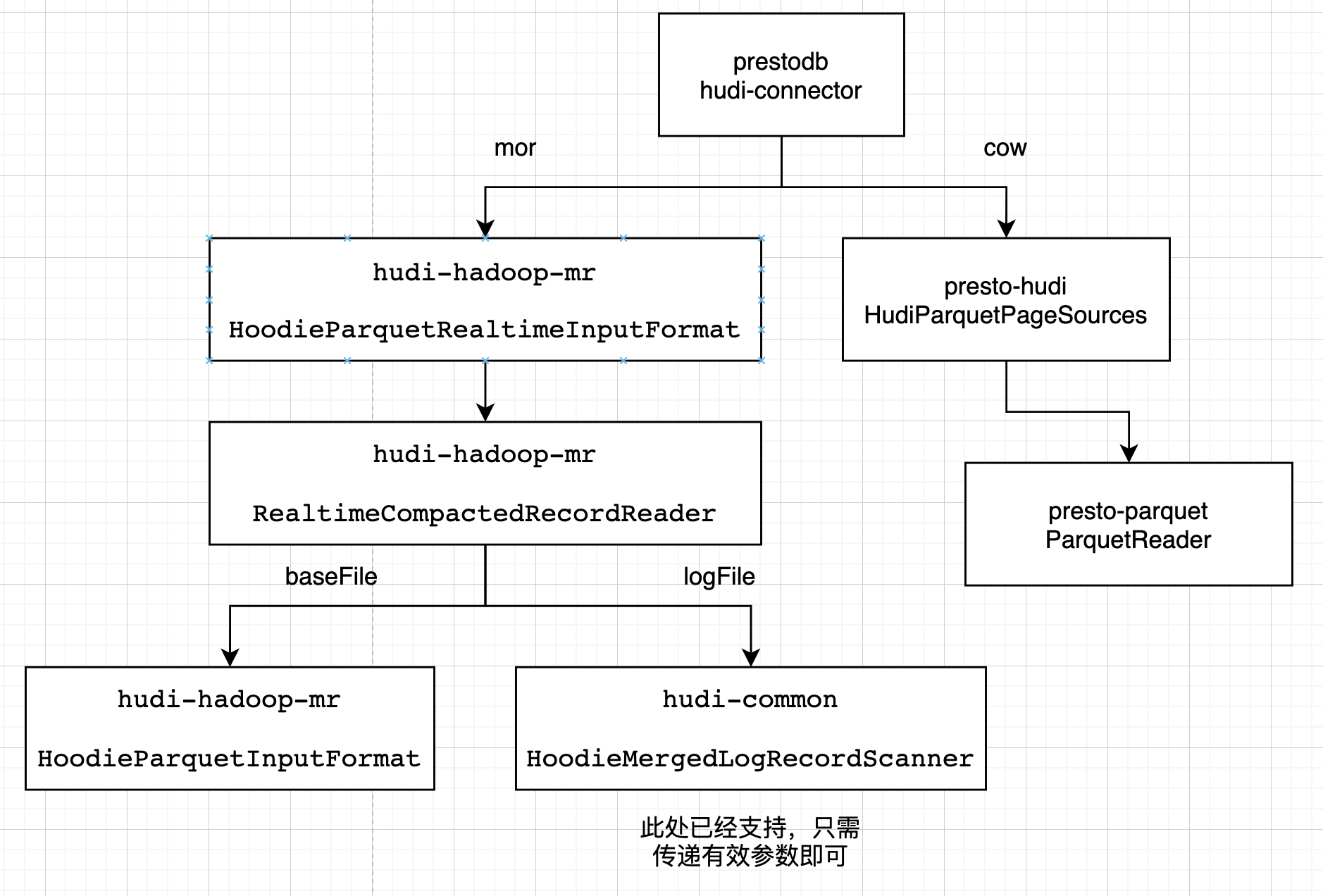
Presto 会使用它自己优化的方式读parquet文件。在presto-hudi的HudiPageSourceProvider -> HudiParquetPageSources -> 最终使用presto-parquet 的 ParquetReader读取
Presto 针对mor表的快照读,会使用hudi提供的huid-hadoop-mr的InputFormat接口。在presto-hudi的HudiPageSourceProvider -> HudiRecordCursors里创建 HoodieParquetRealtimeInputFormat -> 获取RealtimeCompactedRecordReader,基础文件使用HoodieParquetInputFormat的getRecordReader,日志文件使用HoodieMergedLogRecordScanner扫描
读优化的改造
基本思想:在presto-hudi模块的HudiParquetPageSources中,获取文件和查询的 InternalSchema ,merge后与presto里的schema列信息转换,进行查询。
具体步骤:
- 使用TableSchemaResolver的getTableInternalSchemaFromCommitMetadata方法获取最新的完整InternalSchema
- 使用HudiParquetPageSources类的createParquetPageSource方法传入参数regularColumns(List),与完整InternalSchema通过InternalSchemaUtils.pruneInternalSchema方法获取剪枝后的InternalSchema
- 通过FSUtils.getCommitTime方法利用文件名的时间戳获取commitInstantTime,再利用InternalSchemaCache.getInternalSchemaByVersionId方法获取文件的InternalSchema
- 使用InternalSchemaMerger的mergeSchema方法,获取剪枝后的查询InternalSchema和文件InternalSchema进行merge的InternalSchema
- 使用merge后的InternalSchema的列名list,转换为HudiParquetPageSources的requestedSchema,改变HudiParquetPageSources的getDescriptors和getColumnIO等方法逻辑的结果
实现为 https://github.com/prestodb/presto/pull/18557 (打开状态)
快照的改造
基本思想:改造huid-hadoop-mr模块的InputFormat,获取数据和查询的 InternalSchema ,将merge后的schema列信息设置为hive任务所需的属性,进行查询。
具体步骤:
1.基础文件支持完整schema演变,spark-sql的实现此处无法复用,添加转换类,在HoodieParquetInputFormat中使用转换类,根据commit获取文件schema,根据查询schema和文件schema进行merge,将列名和属性设置到job的属性里serdeConstants.LIST_COLUMNS,ColumnProjectionUtils.READ_COLUMN_NAMES_CONF_STR,serdeConstants.LIST_COLUMN_TYPES;
2.日志文件支持完整schema演变,spark-sql的实现此处可以复用。HoodieParquetRealtimeInputFormat的RealtimeCompactedRecordReader中,使用转换类设置reader对象的几个schema属性,使其复用现有的merge数据schema与查询schema的逻辑。
已经存在pr可以达到目标 https://github.com/apache/hudi/pull/6989 (合入master,0.13)
Presto的配置
${presto_home}/etc/catalog/hudi.properties,基本复制hive.properties;主要修改为
connector.name=hudi
Presto的部署
此处分别为基于hudi0.12.1和prestodb的release0.275合入pr后打的包,改动涉及文件不同版本间差异不大,无需关注版本问题
分别将mor表改造涉及的包:
hudi-presto-bundle-0.12.1.jar
以及cow表改造涉及的包:
presto-hudi-0.275.1-SNAPSHOT.jar
放入${presto_home}/etc/catalog/hudi.propertiesplugin/hudi
重启presto服务
开发过程遇到的问题及解决

当前已经实现PrestoDB对Hudi的快照读,以及对schema完整演变的支持,满足了大批量表以MOR的表格式快速写入数据湖,且频繁变更表结构的同时,能够准确实时地进行OLAP分析的功能。但由于Trino社区更加活跃,以前的很多功能基于Trino开发,下一步计划改造Trino,使其完整支持快照读与两种查询模式下的schema完整演变。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK