

MySQL Data Archival With Minimal Disruption
source link: https://www.percona.com/blog/mysql-data-archival-with-minimal-disruption/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
MySQL Data Archival With Minimal Disruption
 We all know that data is important, and some businesses need historical data to be available all the time. The problem is that queries on large tables perform poorly if they are not properly optimized. We get many customer requests in Managed Services to purge/archive large tables, and to achieve it, we use pt-archiver.
We all know that data is important, and some businesses need historical data to be available all the time. The problem is that queries on large tables perform poorly if they are not properly optimized. We get many customer requests in Managed Services to purge/archive large tables, and to achieve it, we use pt-archiver.
Recently, we received a request to archive a large table, and the customer was worried about the downtime and performance issues during the archival.
We proposed a solution to the customer to archive the table using pt-archive. The idea is to archive old data to other tables and keep the latest data on the current table with minimal performance issues. All of the data will remain available and can be queried anytime.

In the blog, I will not explain how to use the pt-archiver, but we will discuss a use case of the pt-archiver.
If you are unfamiliar with pt-archiver, please refer to “Want to archive tables? Use Percona Toolkit’s pt-archive “; it explains how pt-archiver works and various pt-archiver arguments.
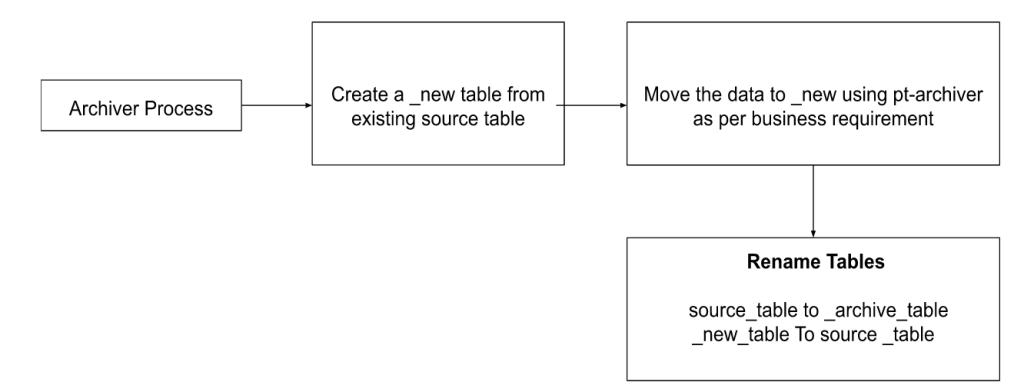
We will test data archival to keep 100 days’ worth of data with a few simple steps for demonstration.
Note: This method uses timestamp datatype to filter the data.
- Create two dummy tables.
- Insert records in the source table.
- Archive the record from the source to the destination table using –where condition per business requirements.
- Rename the tables.
- Add Pt-archiver as a cron.
This diagram better illustrates the process.
Remember —Date and –where the condition in this example is just a reference. Use the archiving condition in pt-archiver as per business requirements.
Let’s create a source table and insert records using mysql_random_data_load:
Create Table: CREATE TABLE `blogpost` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `created_at` timestamp NULL DEFAULT NULL, `updated_at` timestamp NULL DEFAULT NULL, `deleted_at` timestamp NULL DEFAULT NULL, PRIMARY KEY (`id`), KEY `blogpost_created_at_index` (`created_at`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 1 row in set (0.00 sec) |
Let’s create the destination table;
(Using the following table for demonstration purposes only)
create table if not exists blogpost_new like blogpost; Query OK, 0 rows affected (0.02 sec) |
Create the following triggers using pt-online-schema-change
Why triggers?
Any modifications to data in the original tables during the copy will be reflected in the new table because the pt-online-schema-change creates triggers on the original table to update the corresponding rows in the new table.
(For demonstration purposes, I have added triggers created from the pt-online-schema-change test run)
# Event: DELETE delimiter // CREATE TRIGGER `pt_osc_test_blogpost_del` AFTER DELETE ON `test`.`blogpost` FOR EACH ROW BEGIN DECLARE CONTINUE HANDLER FOR 1146 begin end; DELETE IGNORE FROM `test`.`blogpost_new` WHERE `test`.`blogpost_new`.`id` <=> OLD.`id`; END delimiter ; // # Event : UPDATE delimiter // CREATE TRIGGER `pt_osc_test_blogpost_upd` AFTER UPDATE ON `test`.`blogpost` FOR EACH ROW BEGIN DECLARE CONTINUE HANDLER FOR 1146 begin end; DELETE IGNORE FROM `test`.`_blogpost_new` WHERE !(OLD.`id` <=> NEW.`id`) AND `test`.`blogpost_new`.`id` <=> OLD.`id`; REPLACE INTO `test`.`_blogpost_new` (`id`, `created_at`, `updated_at`, `deleted_at`) VALUES (NEW.`id`, NEW.`created_at`, NEW.`updated_at`, NEW.`deleted_at`); END delimiter ; // # Event : INSERT delimiter // CREATE TRIGGER `pt_osc_test_blogpost_ins` AFTER INSERT ON `test`.`blogpost` FOR EACH ROW BEGIN DECLARE CONTINUE HANDLER FOR 1146 begin end; REPLACE INTO `test`.`blogpost_new` (`id`, `created_at`, `updated_at`, `deleted_at`) VALUES (NEW.`id`, NEW.`created_at`, NEW.`updated_at`, NEW.`deleted_at`);END delimiter ; // |
Verify that all triggers have been created.
SELECT * FROM INFORMATION_SCHEMA.TRIGGERS WHERE TRIGGER_SCHEMA='test' and EVENT_OBJECT_TABLE in ('blogpost')\G |
The output should be something like
+--------------------------+ | trigger_name | +--------------------------+ | pt_osc_test_blogpost_ins | | pt_osc_test_blogpost_upd | | pt_osc_test_blogpost_del | +--------------------------+ 3 rows in set (0.01 sec) |
Copy the last 100 days of data using the pt-archiver. Verify with –dry-run,
(Screen session can be used to perform pt-archiver if the table is large in size.)
pt-archiver --source h=localhost,D=test,t=blogpost,i=blogpost_created_at_index \ --dest h=localhost,D=test,t=blogpost_new \ --where "created_at >= date_sub(curdate(), interval 100 day)" --no-delete --no-check-columns \ --limit=10000 --progress=10000 --no-check-charset --dry-run |
The output should be something like this:
SELECT /*!40001 SQL_NO_CACHE */ `id`,`created_at`,`updated_at`,`deleted_at` FROM `test`.`blogpost` FORCE INDEX(`blogpost_created_at_index`) WHERE (created_at >= date_sub(curdate(), interval 100 day)) ORDER BY `created_at` LIMIT 10000 SELECT /*!40001 SQL_NO_CACHE */ `id`,`created_at`,`updated_at`,`deleted_at` FROM `test`.`blogpost` FORCE INDEX(`blogpost_created_at_index`) WHERE (created_at >= date_sub(curdate(), interval 100 day)) AND (((? IS NULL AND `created_at` IS NOT NULL) OR (`created_at` > ?))) ORDER BY `created_at` LIMIT 10000 INSERT INTO `test`.`blogpost_new`(`id`,`created_at`,`updated_at`,`deleted_at`) VALUES (?,?,?,?) |
Let’s execute the pt-archiver:
(Following Pt-archiver will copy 100 days worth of the data to _new table and triggers will up to date the _new table.)
pt-archiver --source h=localhost,D=test,t=blogpost,i=blogpost_created_at_index \ --dest h=localhost,D=test,t=blogpost_new \ --where "created_at >= date_sub(curdate(), interval 100 day)" --no-delete --no-check-columns \ --limit=10000 –replace --progress=10000 --no-check-charset |
The pt-archiver output should be something like this:
TIME ELAPSED COUNT 2022-09-28T23:50:20 0 0 2022-09-28T23:50:44 24 10000 2022-09-28T23:51:08 48 20000 2022-09-28T23:51:25 65 27590 |
Once the pt-archiver finishes, check the condition code of the pt-archiver:
echo $? |
(should be 0)
The next step is to check if the rows have been inserted into a new table and compare it with the original table.
NOTE: The below results are just examples of tests; use the right date or where condition:
select max(created_at) from test.blogpost_new; +---------------------+ | max(created_at) | +---------------------+ | 2022-27-09 02:11:00 | +---------------------+ |
select count(1) from test.blogpost where created_at <= date_sub('2022-27-09', interval 100 day); +----------+ | count(1) | +----------+ | 65366 | +----------+ 1 row in set (0.02 sec) |
select count(1) from test.blogpost_new where created_at >= date_sub('2022-09-26', interval 100 day); +----------+ | count(1) | +----------+ | 23758 | +----------+ 1 row in set (0.01 sec) |
Why rename tables?
The idea is to keep 100 days’ worth of data in the new table and rename it as the source table, and the original table with the _archive prefix will have all the data, including the last 100 days.
RENAME TABLE blogpost TO blogpost_archive, blogpost_new to blogpost; |
It should appear something like this:
+--------------------------------+ | Tables_in_test | +--------------------------------+ | blogpost | | blogpost_archive | +--------------------------------+ |
Drop the triggers created using pt-online-schema-change .
DROP TRIGGER IF EXISTS test.test_blogpost_ins; DROP TRIGGER IF EXISTS test.test_blogpost_upd; DROP TRIGGER IF EXISTS test.test_blogpost_del; |
Once the table rename is completed, copy data from the blogpost table to _archive table.
Let’s add the pt-archiver command to cron to make the process automatic. (It is advisable to create the script, use the below archiver command, and test it.)
pt-archiver --source h=localhost,D=test,t=blogpost,i=blogpost_created_at_index \ --dest h=localhost,D=test,t=blogpost_archive \ --where "created_at >= date_sub(curdate(), interval 100 day)" --no-delete --no-check-columns \ --limit=10000 --progress=10000 –replace b=0,L=yes –bulk-insert --no-check-charset >dev>null 2>1> path/to/logs |
Now it is time to check if the cron was successful.
Check if the rows deleted have been copied to the test.blogpost_archive table, and deleted from the test.blogpost:
SELECT COUNT(1) FROM test.blogpost_archive WHERE created_at <= date_sub('2022-09-02', interval 100 day); |
Verify if the blogpost table has 100 days of data, and the following query should return 0 rows:
SELECT COUNT(1) FROM test.blogpost WHERE created_at <= date_sub('2022-09-02', interval 100 day); |
Hope you found this use case of the pt-archiver helpful when you need to purge/archive large tables!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK