

策略产品经理深入浅出了解机器学习算法原理(上篇)
source link: https://www.woshipm.com/pd/5681999.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
策略产品经理深入浅出了解机器学习算法原理(上篇)
机器学习简单来说就是机器从历史过去的数据、知识中总结出规律经验,用于提升系统的度量能力。本文作者对十大机器学习算法的前三个进行了分析介绍,一起来看一下吧。

今天我们来讲讲关于基础的机器学习算法与对应的适用场景,帮助策略产品建立起来最为基础的“工具方案-问题”的认知思路,帮助大家更好理解十大机器学习算法的思想和理解对应的应用场景。
了解机器学习另一个重要的点是,在和算法工程师沟通过的时候,“知其然更知其所以然”,而不能做“黑盒产品经理”,这种甚至都不能被称之为策略产品,无法为自己的业务指标和业务方向负责。
那么,接下来我们围绕以下几个部分来给大家介绍一下策略产品必知的十大机器学习算法,帮助大家做简单入门,感兴趣还是建议大家阅读专业的机器学习书籍,如果有帮助到大家,辛苦大家帮忙点个喜欢、收藏以及评论一下。
一、机器学习的分类
1. 定义本质
首先,我们在介绍机器学习的分类之前,我们需要了解清楚机器学习的本质是什么,简单来说就是机器从历史过去的数据、知识中总结出来规律经验用于提升系统的度量能力。举个栗子,我们将“好西瓜”开瓜的经验以【数据】形式传递给模型(考虑西瓜蒂、花纹以及敲击的实心声音)给到模型,在面对新瓜,模型就会给我们判定是否为“好瓜”的结论,所以说机器学习就是一门研究“学习算法”的学问。
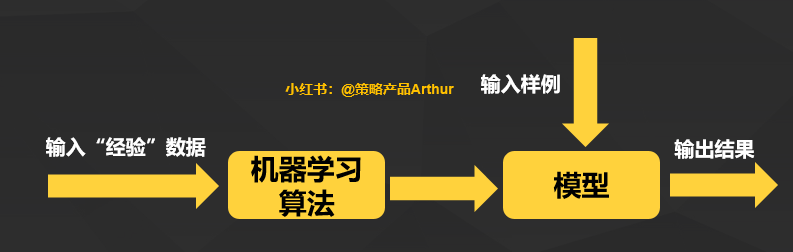
2. 机器学习分类及对应关系
机器学习的算法大致可以分为三类:监督学习算法、无监督学习算法以及强化学习算法。
1)监督学习算法 – Supervised Algorithms
简单来说在监督学习训练过程中,可以由训练数据集学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。
在监督学习当中,需要给算法去提供一些解决方案需要的训练数据,成为所谓的标签和标记;简单说就是要有自变量(X)和因变量(Y),同时可用来分类和回归。那么常见的监督学习算法有:K邻近、线性回归、逻辑回归、支持向量机(SVM)、决策树和随机森林、神经网络。
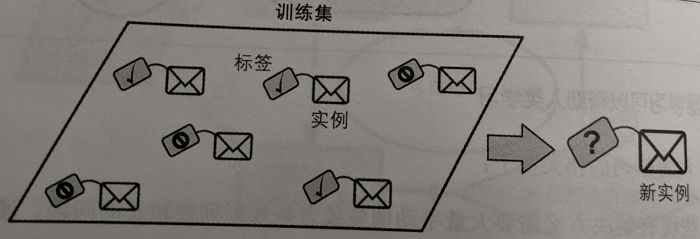
2)无监督学习算法 – Unsupervised Algorithms
无监督学习的训练数据都是不需要经标记,算法会在没有指导的情况下自动学习;训练时候的数据是只有自变量但是没有对应的因变量。
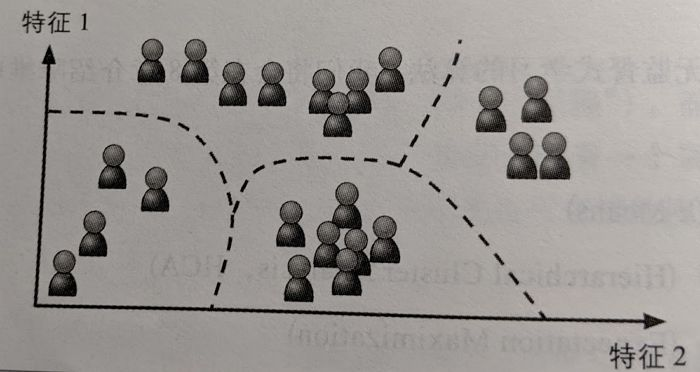
常见的无监督学习:聚类算法(K-meansK均值、最大期望算法)、关联规则学习(Apriori、Eclat)等;例如京东电商平台根据C端用户购物频次、平均客单价、购物的笔单数以及年均消费力等,将这些用户自动“聚类”为几个不同类别,然后在进行人工标记。
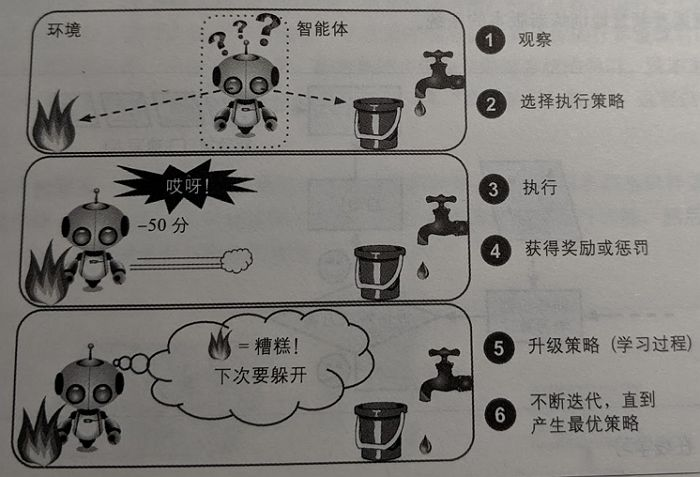
3)强化学习算法 – Reinforcement Algorithms
主要基于决策进行训练,算法根据输出结果(决策)的成功或错误来训练自己,以负面回报的形式获得惩罚。它必须自行学习什么是最好的策略,从而随着时间推移获得最大的回报。
例如我们熟悉的“阿尔法狗Alpha Go”就是在和优秀棋手中不断对弈,通过输赢的对弈起棋局来训练自己如何走下一步是胜率最大的走法,有一部叫做疑犯追踪的美剧也是围绕这个视角来描述的,这也是离我们所谓的人工智能最近的一种算法类型。
二、基本的机器学习算法分类
1. 线性回归-Linear Regression
首先,理解一个概念,回归-Regression和我平时理解的回归-return的概念不一样,这里回归指代的是“推导”的意思。回归算法是相对于分类算法而存在的,和我们想要预测的因变量y的类型相关。
- 如果y是个分类离散变量,例如预测性别男/女,预测用户在推荐位是否点击,预测人外套的颜色红/绿/黄/黑…,那么我们就需要用分类模型的算法训练数据并作出对应的预测;
- 如果y是个连续性变量,例如京东购物用户的年龄(25、40、60)、购物用户的年收入水平(30万/50万/100万/1000万…),用户逛推荐位feeds流的停留时长(5s/10s/15s…)这种的我们就需要用到回归模型的算法去做训练数据的预测;
但是,分类问题其实和回归问题是可以相互转化的,例如上面我们说的在推荐位feeds发生点击行为,如果变成预测C端用户的点击概率,从10%,11%到100%,转化为大于50%则为预测点击,小于50%则为不点击,我们就从回归模型的问题变成了一个分类问题。
线性回归算是机器学习入门型算法,可以用一个简单的二元一次方程来做概述说明,由下图我们可以得到一个y = a+bx 的二元一次方程,给定a、b两个参数的时候,画在坐标轴最终是一条直线;可以看到图中有许多的散点图,我们需要通过一条直线去尽可能的拟合途中的数据点,这就叫一元线性回归。
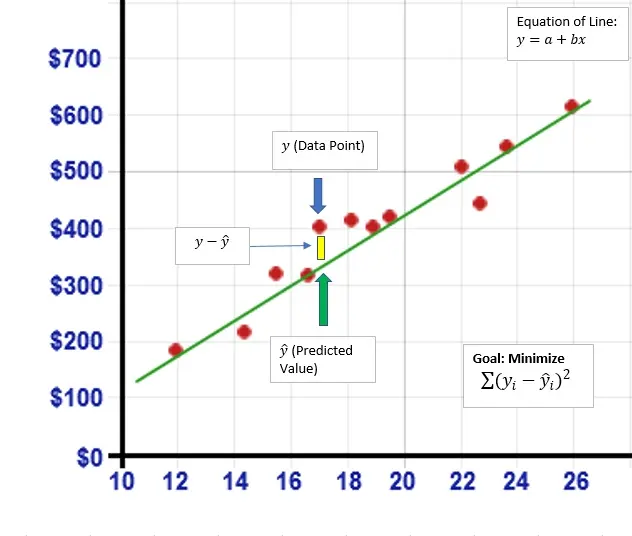
但是,我们也发现上面的所有散点图并不能被一条一元二次方程穿过,就和现实世界的数据一样,我们只能尽可能的找到规律,找到一条最合适的直线;所以,不可避免地发现预测理论值Predicted Value和实际值之间会存在差别,这个也就是我们所说的“误差”,所以我们往往在一元二次回归方程里会带上一个尾巴来来进行误差c,也就是y = a+ bx +c。
因为数据并不是真的落在一条直线上,而是分布再周围,所以我们需要找到一个合适的a和b,来找到一条“合适的曲线”,那么为了求得a和b,我们就需要用到损失函数的概念。
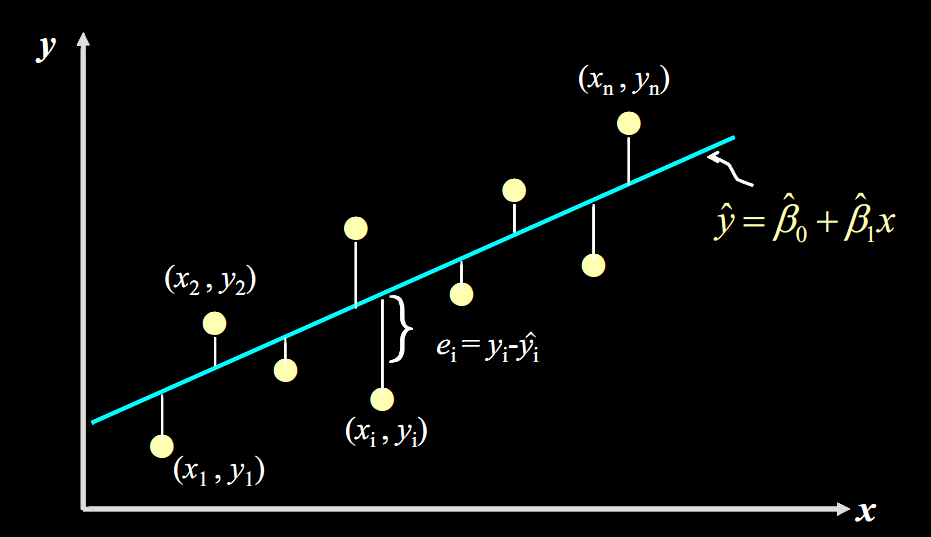
误差说白了就是真实值和预测值之间的差值,也可以理解为距离;我们把上图当中每一个点单独的误差值求出来,计算出对应的值:
![]()
再把每一个点做平方后的累加合,这样就可以完全的量化出来你和曲线上直线对应的点和实际值之间的误差距离,用公式表示如下:
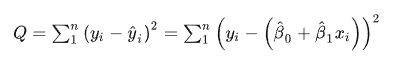
这个公式是残差平方和-SSE(Sum of Squares for Error),在机器学习中它是回归问题当中使用的损失函数,用于衡量回归模型误差的函数,也就是我们要的“直线”的评价拟合成都的标准标准。这个函数的值越小,说明直线越能拟合我们的数据。最后如何求的最佳参数a和b,我们一般需要使用梯度下降法或者最小二乘法求得,后续展开分享,就不再这里赘述了。
2. 逻辑回归-Logistic Regression
前面给大家介绍了逻辑回归常常用来解决分类问题,业界常用来做搜索结果页/推荐信息流当中用户是否点击、金融系统当中判定是否违约客户等等。
记住一句关键的话:分类本质上是用逻辑回归当中的目的和结果,其中间过程还是回归性质。为什么这么说,举个例子,京东推荐系统当中会把用户在推荐位对商品点击的可能性“概率”归一到(0,1),然后给可能性在加一个阈值0.5,比方说点击预测的可能性是0.5以上,预测判定为会被点击,小于0.6则预测为不会被点击。
由此可见,所有实际点值都落在了y = 1 和y = 0上了(纵坐标非0即1),如果用一个单一的一元二次线性方程拟合效果会比较差,只有少数的点才被落在了直线上。
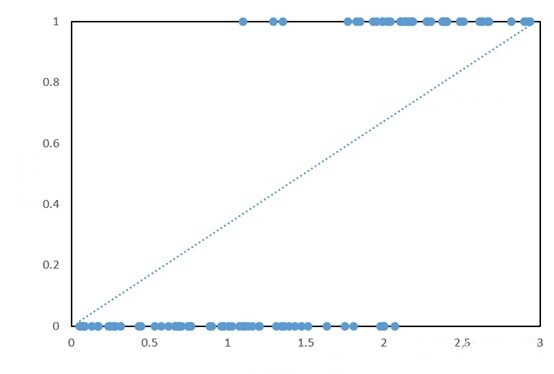
实际上,逻辑回归一般会采用sigmoid的函数去做拟合,sigmoid函数在本身是一个s型曲线函数,在取值范围之间(-∞,+∞)会在y = 0 和y = 1之间会有平滑过渡,用来表示预测的概念,也就是事件发生的“可能性”。
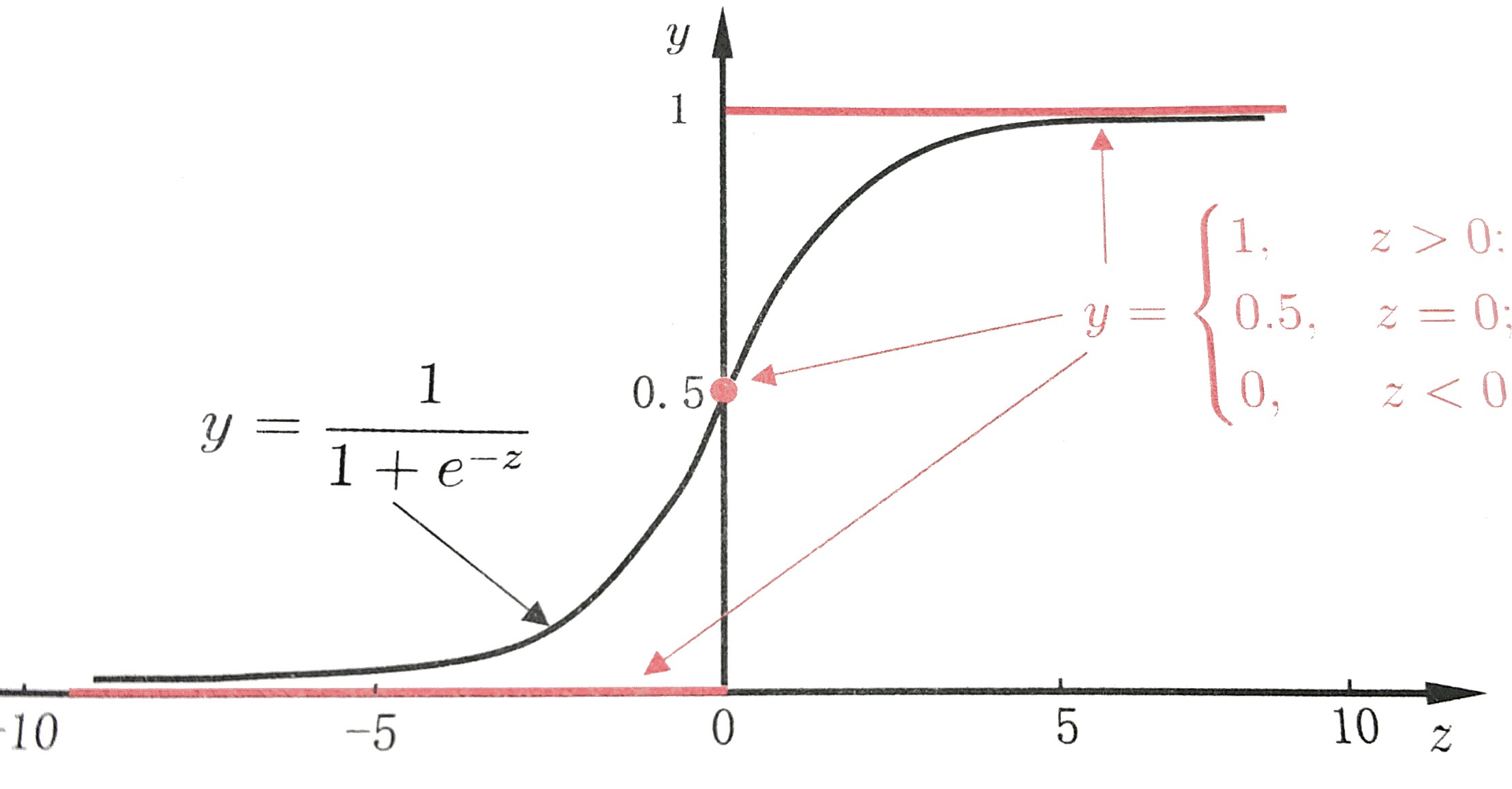
多元一次方程一般的形式为可以表现为如下图,一般可以简写成为矩阵形式Y = Xβ: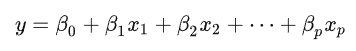

将特征加权求和Xβ带入,领所有预测为正例得概率P(Y = 1),例如在京东推荐系统当中,预测这一次行为时被点击,那么逻辑回归的形式就变成了如下的条件公式预测:
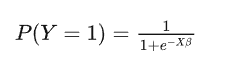
整个逻辑回归的函数就构造完成了,下面就是通过梯度下降法来求解β获得最佳位置参数去构建最佳函数去拟合所有的点,关于梯度下降法我们单独起一篇文章来进行介绍;
3. K邻近算法KNN-KNearestNeighbor
KNN是比较入门级的机器学习分类算法,整体思路比较的简单,核心就是的思维就是中国古代中的“近朱者赤近墨者黑”的思想。其中KNN当中的K指代的就是最近的K个点的个数来预测位置的数据点,其中选择K值就是预测精准度的一个关键性质的因素。
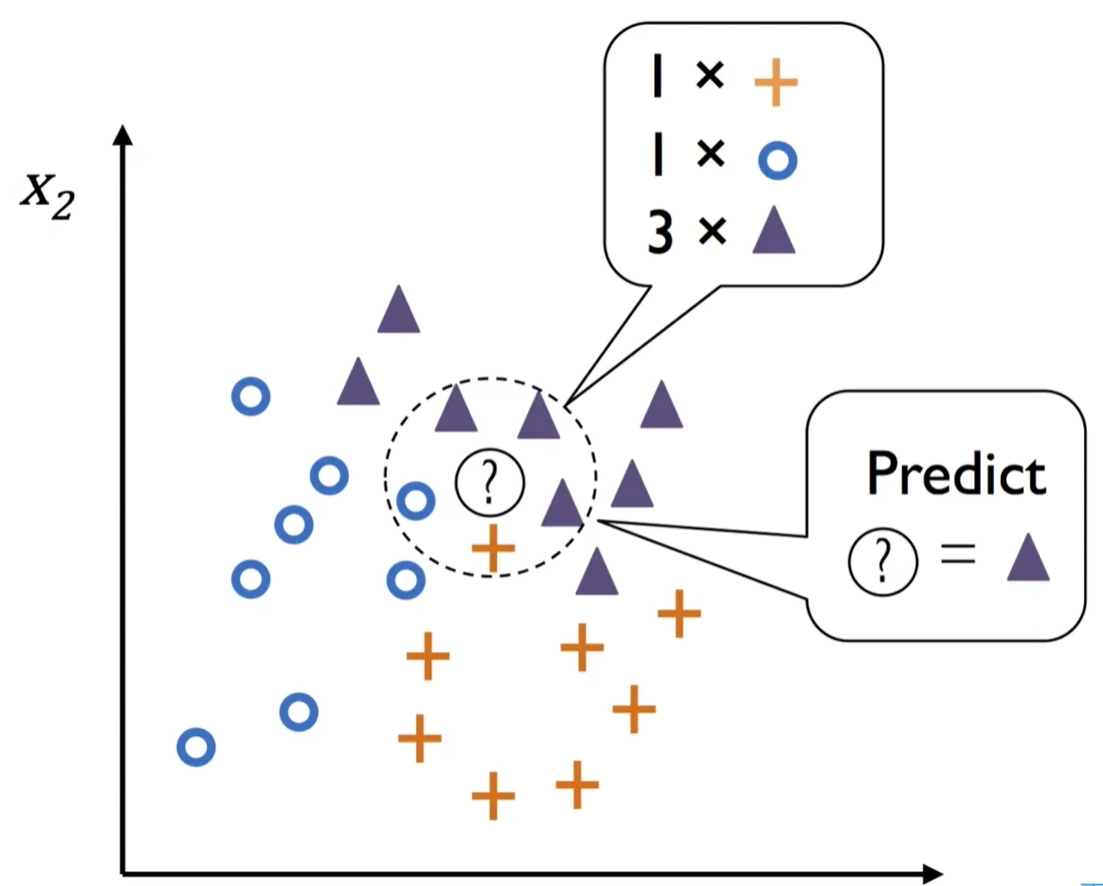
KNN做的就是选出距离目标点Predicted点位距离最近的k个点,看这k个点的大多数颜色是什么形状。这里我们可以通过欧氏距离来度量和计算预测Predicted点位和K个点之间的距离。
- case 1:当我们把K设为1的时候,可以看出来,预测点位距离黄色的“+”最近,那么我们在判定点的类型的时候会把预测点位判定成为“+”
- case 2:当我们把K设为5的时候,可以看出来距离最近的点位有1个“+”,1个“O”,还有3个“△”,那么我们召会将预测Predict的点位会判定成为“△”
结论:由此我们可以知道K的选择不同,对于得到的结果大相径庭,所以选择K值也就成为了KNN算法的关键。
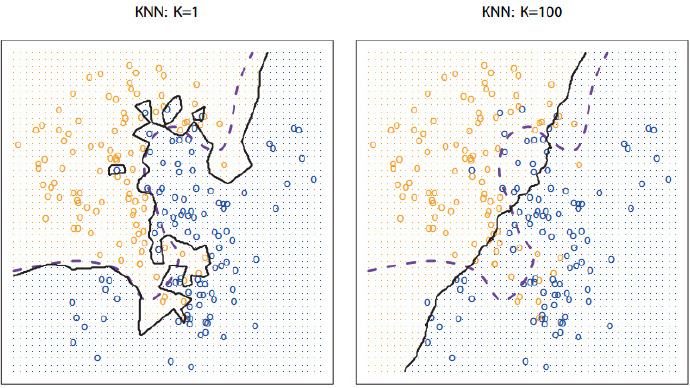
KNN的分类边界是非线性的,K越小越容易过拟合,我们看到到K = 1的时候,这个时候只会根据最近的单个点进行预测,如果最近的一个点是相反的噪点,这个时候就预测出错,这个时候无形之中增加了计算的复杂度,鲁棒稳健性比较差。但是如果K取得比较大(例如K = 100)的时候,这个时候又会欠拟合,模型计算非常简单,并且分类的边界也会比较的平滑。
所以,我们找到合适的K的过程,就是一个不断的调参过程,比较经典合适的方法就是N折交叉验证法,下图展示的是5折交叉验证,讲一直到的样本集合分为5各等分,其中四份作为训练集,1份作为验证集,设定 参数,做出5个等分。
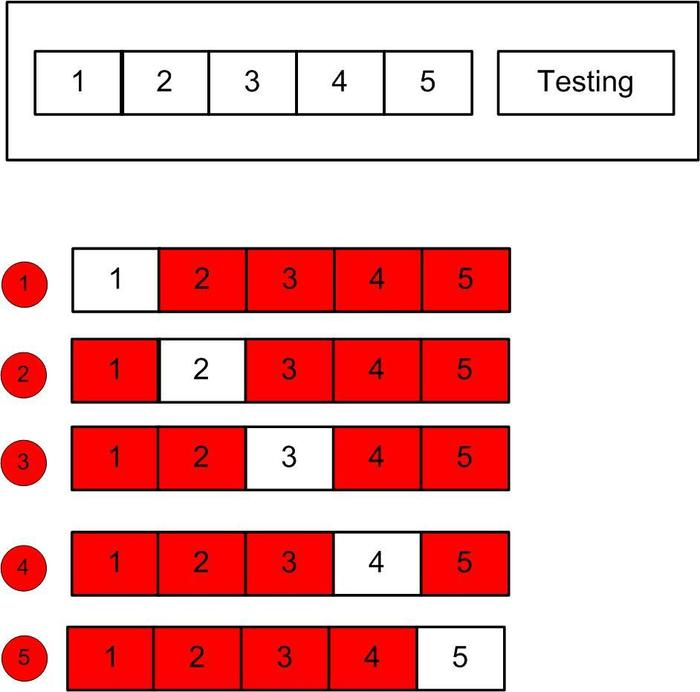
具体来说:
- 第一步:把样本集分成5个小的子集,编号为train1、train2、train3、train4、train5;
- 第二步:先用train1、train2、train3、train4建模,得到model1,并在train5上计算误差error1;
- 第三步:在用train1、train2、train3、train5建模,得到model2,并在train4上计算误差error2;
- 重复以上步骤,建立5个model模型,将5个误差值相加后除以5得到平均误差。
做完交叉验证之后,我们就设置超参数从k=1开始尝试,计算K=1时的平均误差值,每次K增加2,最终能选到产生最小误差值的K(因为随着K变大,误差值会先变小后变大嘛)。
这里有个主意的点,我们一般都对K会取奇数而不取偶数,因为偶数有一定的可能会导致点打平(例如有4个点其中2个黄色“+”,2个“O”),这样就无法判断Predict 点位究竟是属于黄色“+”,还是“O”,所以尽量避免这种问题。
最后还要注意的点就是点位需要做“标准化”,如果不做标准化,可能会因为点位会受到点位影响严重,一般会采用极差法消除两级或者是标准差标准法。
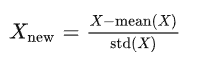
KNN本身是没有训练过程的,也没有模型的参数,所以再验证过程中是和已知的样本点的距离来学习。
KNN的优点就在于原理简单也比较号实现,对于非线性规则分类效果是要更加优于先行分类器;缺点也十分明显:需要存储全部的数据集、而且需要计算每一个预测Predict和已知点的距离比较耗时,并且不太适合于特征空间维度比较高的场景类型。
三、小结回顾
今天我们先简单了解一下机器学习十大算法中的前三个,对于策略产品经理来说,知道其算法原理逻辑思考和应用场景是非常有必要的,策略产品在解决业务场景时候需要抽象化分类思考具体的问题,对症下药看碟夹菜,这样才能实实在在提升自己解决问题的能力。
像是线性回归,我们即用来做线性预测,比方说预测信用卡用户的生命周期,通过收入、年龄以及居住小区等来给用户评级;例如逻辑回归,我们就用来预测推荐系统用户的点击行为,通过用户的画像、在线/离线行为记录来预测用户是否会点击。了解了内核实质,其实就是工具场景的应用了。
本文由 @策略产品Arthur 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
更多精彩内容,请关注人人都是产品经理微信公众号或下载App

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK