

New paper: An Open Source Replication of a Winning Recidivism Prediction Model
source link: https://andrewpwheeler.com/2022/11/03/new-paper-an-open-source-replication-of-a-winning-recidivism-prediction-model/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
New paper: An Open Source Replication of a Winning Recidivism Prediction Model
Our paper on the NIJ forecasting competition (Gio Circo is the first author), is now out online first in the International Journal of Offender Therapy and Comparative Criminology (Circo & Wheeler, 2022). (Eventually it will be in special issue on replications and open science organized by Chad Posick, Michael Rocque, and Eric Connolly.)
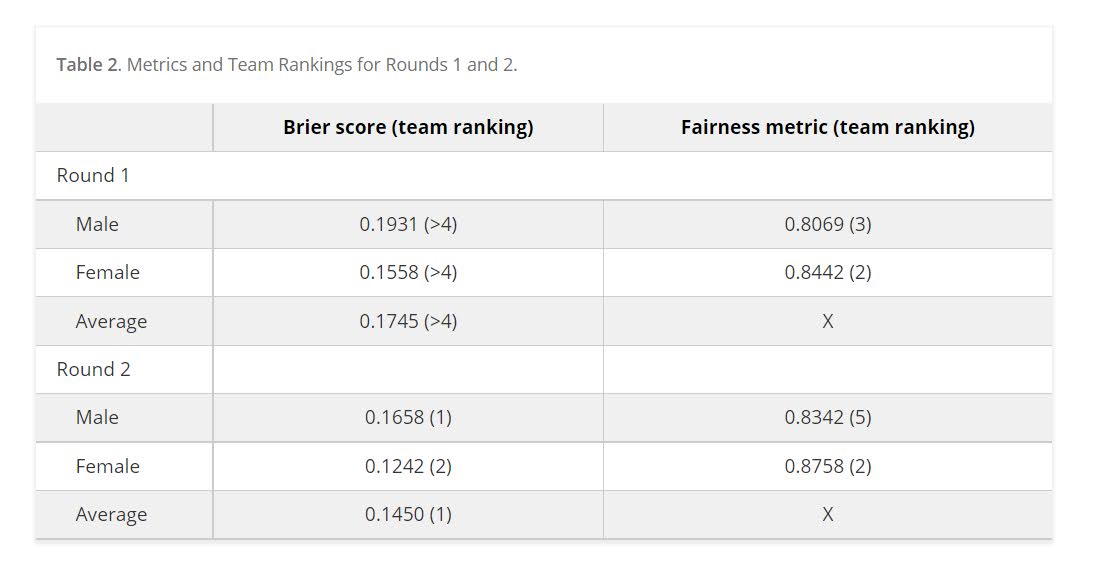
We ended up doing the same type of biasing as did Mohler and Porter (2022) to ensure fairness constraints. Essentially we biased results to say no one was high risk, and this resulted in “fair” predictions. With fairness constraints or penalities you sometimes have to be careful what you wish for. And because not enough students signed up, me and Gio had more winnings distributed to the fairness competition (although we did quite well in round 2 competition even with the biasing).
So while that paper is locked down, we have the NIJ tech paper on CrimRXiv, and our ugly code on github. But you can always email for a copy of the actual published paper as well.
Of course since not an academic anymore, I am not uber focused on potential future work. I would like to learn more about survival type machine learning forecasts and apply it to recidivism data (instead of doing discrete 1,2,3 year predictions). But my experience is the machine learning models need very large datasets, even the 20k rows here are on the fringe where regression are close to equivalent to non-linear and tree based models.
Another potential application is simple models. Cynthia Rudin has quite a bit of recent work on interpretable trees for this (e.g. Liu et al. 2022), and my linked post has examples for simple regression weights. I suspect the simple regression weights will work reasonably well for this data. Likely not well enough to place on the scoreboard of the competition, but well enough in practice they would be totally reasonable to swap out due to the simpler results (Wheeler et al., 2019).
But for this paper, the main takeaway me and Gio want to tell folks is to create a (good) model using open source data is totally within the capabilities of PhD criminal justice researchers and data scientists working for these state agencies.They are quantitaive skills I wish more students within our field would pursue, as it makes it easier for me to hire you as a data scientist!
References
- Circo, G. M., & Wheeler, A. P. (2022). An Open Source Replication of a Winning Recidivism Prediction Model. International Journal of Offender Therapy and Comparative Criminology, Online First.
- Liu, J., Zhong, C., Li, B., Seltzer, M., & Rudin, C. (2022). FasterRisk: Fast and Accurate Interpretable Risk Scores. arXiv preprint.
- Mohler G., Porter M.D. (2021). A note on the multiplicative fairness score in the NIJ recidivism forecasting challenge. Crime Science, 10, 17.
- Wheeler, A. P., Worden, R. E., & Silver, J. R. (2019). The accuracy of the violent offender identification directive tool to predict future gun violence. Criminal Justice and Behavior, 46(5), 770-788.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK