

词嵌入表示参数占比太大?MorphTE方法20倍压缩效果不减
source link: https://www.51cto.com/article/721752.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
词嵌入表示参数占比太大?MorphTE方法20倍压缩效果不减
词嵌入表示作为机器翻译、问答、文本分类等各种自然语言处理任务的基础,它通常会占到模型参数总量的 20%~90%。存储和访问这些嵌入需要大量的空间,这不利于模型在资源有限的设备上部署和应用。针对这一问题,本文提出了 MorphTE 词嵌入压缩方法。MorphTE 结合了张量积操作强大的压缩能力以及语言形态学的先验知识,能够实现词嵌入参数的高倍压缩(超过 20 倍),同时保持模型的性能。

- 论文链接:https://arxiv.org/abs/2210.15379
- 开源代码:https://github.com/bigganbing/Fairseq_MorphTE
本文提出的 MorphTE 词嵌入压缩方法,首先将单词划分成具有语义含义的最小单位——语素,并为每个语素训练低维的向量表示,然后利用张量积实现低维语素向量的量子纠缠态数学表示,从而得到高维的单词表示。
01 单词的语素构成
语言学中,语素是具有特定语义或语法功能的最小单位。对于英语等语言来说,一个单词可以拆分成词根、词缀等更小单位的语素。例如,“unkindly”可以拆分成表示否定的 “un”、具有“友好的” 等含义的 “kind”,以及表示副词的“ly”。对于汉语来说,一个汉字同样可以拆分成偏旁部首等更小单位,如“沐” 可拆分成表示水的 “氵” 和“木”。

语素在蕴含语义的同时,也可以在词之间进行共享,从而联系不同的词。此外,有限数量的语素可以组合出更多的词。
02 纠缠张量形式的词嵌入压缩表示
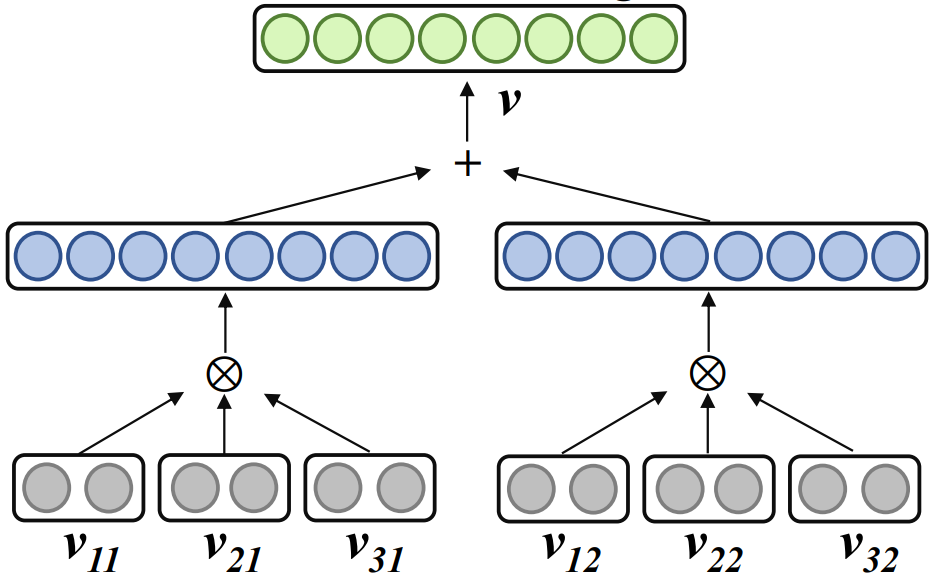
相关工作 Word2ket 通过张量积,表示单个词嵌入为若干低维向量的纠缠张量形式,其公式如下:
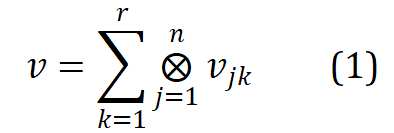
其中、r 为秩、n 为阶,表示张量积。Word2ket 只需要存储和使用这些低维的向量来构建高维的词向量,从而实现参数有效降低。例如,r =2、n=3时,一个维度为 512 的词向量,可以通过两组,每组三个维度为 8 低维向量张量积得到,此时所需参数量从 512 降低至 48。
03 形态学增强的张量化词嵌入压缩表示
通过张量积,Word2ket 能够实现明显的参数压缩,然而其在高倍压缩以及机器翻译等较复杂任务上,通常难以达到压缩前的效果。既然低维向量是组成纠缠张量的基本单位,同时语素是构成单词的基本单位。该研究考虑引入语言学知识,提出了 MorphTE,其训练低维的语素向量,并利用单词所包含的语素向量的张量积来构建相应的词嵌入表示。
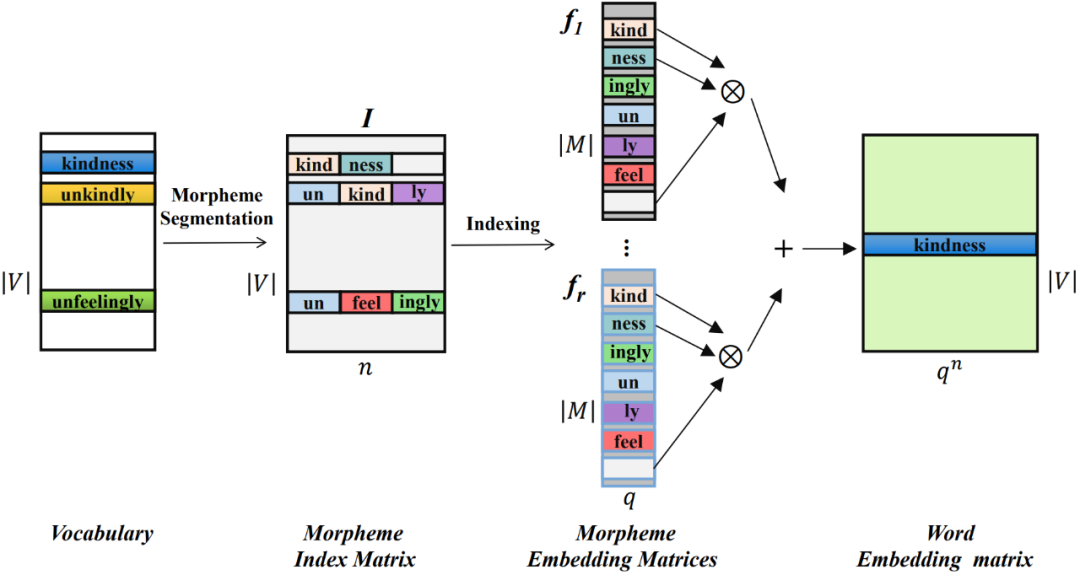
具体而言,先利用语素分割工具对词表 V 中的词进行语素分割,所有词的语素将构成一个语素表 M,语素的数量会明显低于词的数量()。
对于每个词,构建其语素索引向量,该向量指向每个词包含的语素在语素表中的位置。所有词的语素索引向量构成一个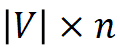 的语素索引矩阵,其中 n 是 MorphTE 的阶数。
的语素索引矩阵,其中 n 是 MorphTE 的阶数。
对于词表中的第 j 个词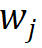 ,利用其语素索引向量
,利用其语素索引向量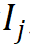 从 r 组参数化的语素嵌入矩阵中索引出相应的语素向量,并通过张量积进行纠缠张量表示得到相应的词嵌入,该过程形式化如下:
从 r 组参数化的语素嵌入矩阵中索引出相应的语素向量,并通过张量积进行纠缠张量表示得到相应的词嵌入,该过程形式化如下:
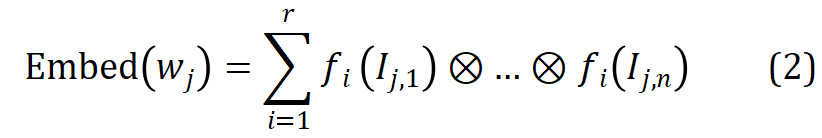
通过以上方式,MophTE 可以在词嵌入表示中注入以语素为基础的语言学先验知识,同时语素向量在不同词之间的共享可以显式地构建词间联系。此外,语素的数量和向量维度都远低于词表的大小和维度,MophTE 从这两个角度都实现了词嵌入参数的压缩。因此,MophTE 能够实现词嵌入表示的高质量压缩。
本文主要在不同语言的翻译、问答等任务上进行了实验,并且和相关的基于分解的词嵌入压缩方法进行了比较。
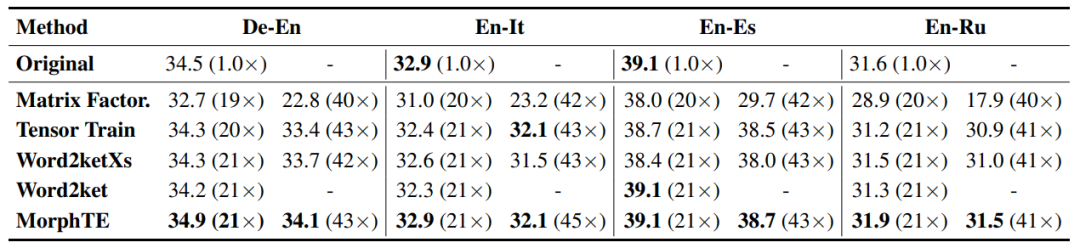
从表格中可以看到,MorphTE 可以适应英语、德语、意大利语等不同语言。在超过 20 倍压缩比的条件下,MorphTE 能够保持原始模型的效果,而其他压缩方法几乎都出现了效果的下降。此外,在超过 40 倍压缩比的条件下,MorphTE 在不同数据集上的效果都要好于其他压缩方法。
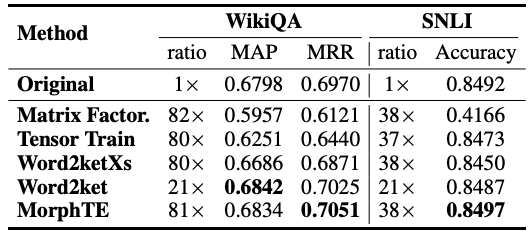
同样地,在 WikiQA 的问答任务、SNLI 的自然语言推理任务上,MorphTE 分别实现了 81 倍和 38 倍的压缩比,同时保持了模型的效果。
MorphTE 结合了先验的形态学语言知识以及张量积强大的压缩能力实现了词嵌入的高质量压缩。在不同语言和任务上的实验表明,MorphTE 能够实现词嵌入参数 20~80 倍的压缩,且不会损害模型的效果。这验证了引入基于语素的语言学知识能够提升词嵌入压缩表示的学习。尽管 MorphTE 当前只建模了语素,它实际上可以被扩展为一个通用的词嵌入压缩增强框架,显式建模原形、词性、大小写等更多先验的语言学知识,进一步提升词嵌入压缩表示。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK