

荷兰银行构建可扩展的元数据驱动的数据摄取框架
source link: https://www.jdon.com/63142
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

荷兰银行构建可扩展的元数据驱动的数据摄取框架
数据摄取是一个异构系统,具有多个来源,具有数据格式、调度和数据验证要求。现代数据堆栈正试图在孤岛中解决这个问题。组织最终必须捆绑一切以使其工作。ABN AMRO荷兰银行 分享了它如何构建元数据驱动的数据摄取平台以保持沿袭、质量和调度的案例研究。
数据工程师的典型任务是获取数据、验证数据,如果需要,应用聚合等转换,或将数据与其他来源组合,最后将数据存储到最终位置,例如存储文件夹或数据库。当您在自动活动流中捕获所有这些任务时,您将获得一个摄取框架,允许您处理许多文件,而无需手动检查、移动和摄取每个文件。此外,拥有可重用的可扩展框架使您能够有效地处理所有数据需求。
元数据在构建任何可扩展的摄取框架中都起着关键作用,在这篇博客中,我将深入探讨此类框架的概念,提供一些构建元数据驱动的数据摄取框架的实际示例和关键要点,旨在提供在处理大量数据时如何利用元数据值得深思。
在这篇博客中,我故意不谈论工具。可扩展、元数据驱动的数据摄取框架的概念是独立于工具的,您对工具的选择取决于许多项目或组织特定的元素,例如成本、合同、战略和经验。
它是如何开始的
我们的开发团队需要构建一个应用程序来满足组织的业务和技术数据沿袭要求。例如,业务数据沿袭显示了通过在组织中使用应用程序的数据消耗、使用目的、与此使用相关的风险,以及所有这些元素与不同组织方面(如法规、政策和组织结构)的联系。
技术数据沿袭显示数据如何从任何源应用程序流向其所有消费应用程序以及沿途应用的所有数据转换。您可以想象,要构建这样的应用程序,您需要集成许多数据源,例如有关组织中运行的应用程序的数据、它们生成的数据集、这些数据集的消费应用程序、处理相关应用程序的 IT 团队,以及与(提供和消费)应用程序中数据的使用和转换相关的所有信息。
考虑到我们可以预期的资源数量、它们的更新时间表(大部分是每天),以及在不久的将来可能会有更多资源的公告,我们立即知道我们需要构建一个能够胜任的数据处理框架处理所有这些不同数据集带来的所有数据需求。我们设计了一个元数据驱动的数据摄取框架,它是一个灵活且高度可扩展的框架,用于自动化您的数据工程活动。
元数据在数据摄取框架中的作用
数据摄取框架中的元数据包含描述处理数据文件时要执行的步骤的信息。将元数据引入您的数据处理框架有很多好处:
- 可扩展性:轻松增加或减少流经系统的数据量,并轻松向框架添加、修改或删除功能。即插即用!
- 可重用性:由于通用设计,功能很容易被其他来源甚至其他应用程序重用。
- 可维护性:只需维护一组代码,您可以将其应用于所有(或部分)源。
- 减少开发时间:通过编写通用工作流,所需的自定义代码量急剧减少。这样可以节省很多时间!
摄取框架和示例流程的蓝图
图 1 显示了摄取框架的示例蓝图。在此示例中,经过验证并在需要时将转换后的数据提取到 SQLDB、NoSQL DB (Graph) 中,或者两者都提取,或者不提取。该框架能够应用三种类型的验证;
- 快照验证(确保接收文件的日期是最新日期);
- 行数异常(对文件中记录数量的完整性检查);
- 数据类型验证(确保列的数据类型是预期的数据类型)。
实际上,您可能需要应用更多的验证或质量检查。但是,并非所有检查都适用于所有来源。某些来源可能有资格进行更多(或更少)的验证检查,具体取决于文件特定的功能,如敏感性、治理等。
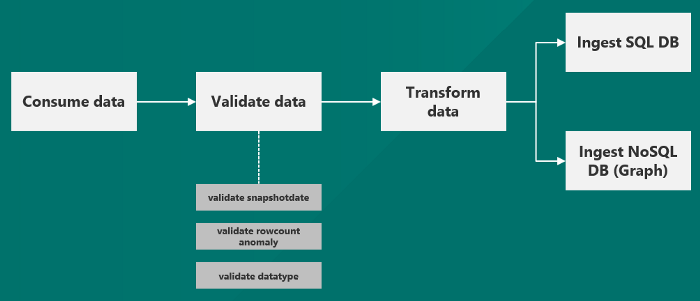
图 1:数据摄取框架示例。图片由 Ilse Epskamp 提供。
让我们介绍一些我们想用框架处理的数据文件。这些文件的要求如下:

图 2:文件的示例数据要求。Ilse Epskamp 的表。
您会看到,只有四个文件,您已经拥有许多需要应用的框架特性的可能组合。有些文件需要多次验证检查,而另一些则只需要一次。一些文件有转换要求,而另一些则没有。一个只在图表中摄取,一个只在 SQL 中,一个在两者中,一个是没有的。
您可以想象,为每个源编写自定义流程不仅需要花费大量时间,而且还会导致大量重复代码,因为即使并非所有源都需要完全相同的处理方式,但在应用功能方面存在很多重叠。您希望拥有一个可扩展的处理框架,使您可以动态地仅选择要应用于源的功能,而无需手动编写所有工作流程。
可扩展摄取框架的三大支柱
可扩展的摄取框架建立在 3 个支柱之上:
- 数据(主体);
- 元数据(指令);
- 代码(执行引擎)。
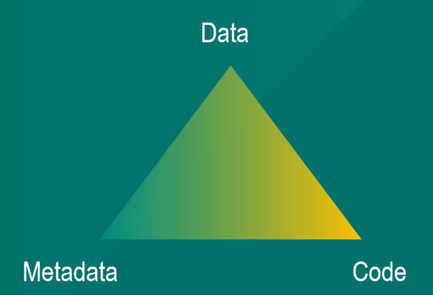
数据、元数据和代码驱动任何可扩展的摄取框架。图片由 Ilse Epskamp 提供。
实际示例:使用和不使用元数据的数据类型验证
让我们在故事中添加一些代码。我们将对两个示例数据集应用数据类型验证,一次不使用元数据,一次使用元数据,以演示元数据在代码中的作用。假设我们有两个文件;Employee 文件和 Accounts 文件。

样本数据员工和客户。图片由 Ilse Epskamp 提供。
对于员工文件,我们要验证 ID 列是否为数据类型integer。对于 Accounts 文件,我们要验证 ACTIVE 列是否为boolean类型。只有这样我们才能接受这些文件。我们可以为这两个文件编写自定义验证。这可能看起来像这样:
if file=="employees":
isInteger=False
if(df.schema("ID").datatype.typeName=="integer"):
isInteger=True
result=isIntegerif file=="accounts":
isBoolean=False
if(df.schema("ACTIVE").datatype.typeName=="boolean"):
isBoolean=True
result=isBoolean
|
这会很好。但是,假设您每天加载 100 个文件,并且您希望对其中的一半应用此验证检查。或者假设您想检查同一个文件的多个列。想想您需要编写的自定义工作流程的数量!为每个场景编写自定义工作流不可扩展且难以维护。让我们再做一次,但现在使用元数据。
首先,我们为这两个来源定义元数据。在此示例中,每个源都有一个专用的 JSON 文件*,其中包含所有相关的元数据键值对。具体来说,我们添加了一个用于验证检查的部分,我们在其中启用特定列的数据类型验证,并具有特定的预期结果。
*在此示例中,提取的元数据使用 JSON 文件配置。或者,您可以使用适合您的应用程序的任何格式或工具。
employees.json:
"filename": "employees",
"validation": {
"validateColumnDataType": {
"enabled": true,
"colname": "ID"
"datatype": "integer"
}
}
|
accounts.json:
"filename": "accounts",
"validation": {
"validateColumnDataType": {
"enabled": true,
"colname": "ACTIVE"
"datatype": "boolean"
}
}
|
现在我们准备好了元数据。下一步是编写一个通用函数,我们可以在处理数据文件时调用它。
def validate_col_datatype(data,col,type): passed=False if(data.schema(col).datatype.typeName==type): passed=True return pass |
剩下的就是添加一些代码来读取元数据并在源启用时执行验证功能。
md=read_metadata(filename)run validation if enabled if md["validation"]["validateColumnDataType"]["enabled"]: colname = md["validation"]["validateColumnDataType"]["colname"] datatype = md ["validation"]["validateColumnDataType"]["datatype"] result = validate_col_datatype(data,colname,datatype) |
如果要在多个列上运行此数据类型验证,只需将其他部分添加到元数据配置文件中。如果您不需要对源应用验证检查,则将 enabled 设置为false,该源的检查将被忽略。
使用此模式时,您需要考虑如何处理结果。如果验证失败,您是要发出警告并继续,还是要中断流程?您想自动通知开发团队或利益相关者组吗?设计您的工作流程策略对于利用此类框架可以提供的好处非常重要。
附加的功能
您可以想出更多可以包含在框架中的功能。例如:
- 更多的验证和质量检查。例如,您可以验证文件大小、文件类型、文件来源、值格式……
- SCD型。在每个元数据配置中指定是否要使用 SCD1 或 SCD2 将数据存储在数据库中,因此是否要在数据库中建立和保留历史数据 (SCD2) 或不 (SCD1)。以这样一种方式设计您的摄取逻辑,如果启用 SCD1,则数据库中的数据将被覆盖,如果启用 SCD2,则保留历史记录。数据库中的所有记录都应具有反映其版本、开始日期、结束日期和上次更新日期的自定义属性。对于 SQL 数据库,您可以考虑使用存储过程来更新记录版本,或者根据您的数据库类型使用任何可用的开箱即用功能。或者,在您的摄取逻辑中,您可以动态处理记录版本。
元数据配置文件蓝图
下面是示例员工文件的元数据配置文件的示例,其中包含通用文件详细信息以及用于验证、转换和摄取的部分。
"description": "This is the metadatafile for Employees data.",
"sourcename": "HRSYSTEM",
"tablename": "all_employees",
"cardinality": "1-to-1",
"primary_key": "EMPLOYEE_ID",
"daily_delivery": true,
"file_delimiter": ";",
"validation"": {
"validate_snapshotdate" : true,
"validate_rowcount_anomaly" : false,
"validate_col_datatype": {
"enabled": true,
"colname": "EMPLOYEE_ID"
"datatype": "integer"
}
},
"transformations": {
"preprocessing_description": "Join with file XYZ.",
"preprocessing_flag": true,
"preprocessing_logic": "join_HRSYSTEM_all_employees_with_XYZ()"
},
"ingestion": {
"sqldb": {
"ingestion_enabled": true,
"ingestion_environment": "dtap",
"scd_type": "2",
"sql_tablename": "employees"
},
"csmsdb": {
"ingestion_enabled": true,
"ingestion_environment": "dtap",
"scd_type": "1",
"vertex_label": "EMPLOYEES",
"is_mapping_file": false
}
}
|
经验
在设计和构建元数据驱动的数据摄取框架时,我建议至少考虑以下几点:
1.不要偷工减料
我们都知道在紧迫的时间表内修复错误或编写解决方案时可能会遇到的工作压力。由于许多原因,可能很容易将注意力集中在手头的问题上而不查看通用实现。但是,请花一点额外的精力来使您的工作流程通用且可重用。你以后一定会从中受益的!
2.想想你的命名约定
您的框架应该能够动态查找各种资源,从存储帐户及其目录和文件到数据库及其表名。考虑一下并定义一个标准。
3. 框架监控
自动化很棒,但要保持控制。找到一种方法来掌握框架中正在发生的一切。例如,我们在框架之上构建了一个监控层,将每个决策和每个结果记录到一个集中的事件日志中,我们用它来构建运营报告。
4. 保持需求驱动
一旦开始,您会想到许多可能有用的功能。保持需求驱动,以确保您添加到框架中的任何功能都直接为您的客户或您的开发团队做出贡献。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK