

细说编码与字符集 - "地瓜哥"博客网
source link: https://www.diguage.com/post/dive-into-encoding-and-character-set/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

细说编码与字符集
文章还没写完,提前放出防止出现 404。稍后慢慢更新,敬请期待: 细说编码与字符集 - "地瓜哥"博客网
文章还没写完,提前放出防止出现 404。稍后慢慢更新,敬请期待: 细说编码与字符集 - "地瓜哥"博客网
文章还没写完,提前放出防止出现 404。稍后慢慢更新,敬请期待: 细说编码与字符集 - "地瓜哥"博客网
前段时间要研究 Hessian 编码格式,为了搞清楚 Hessian 对字符串的编码,就顺路查了好多编码和字符集的工作,理清了很多以前模糊的知识点。下面整理一下笔记,也梳理一下自己的思路和理解。
ASCII 码
计算机起源于美国,他们对英语字符与二进制位之间的对应关系做了统一规定,并制定了一套字符编码规则,这套编码规则被称为 American Standard Code for Information Interchange,简称为 ASCII 编码
其实,ASCII 最早起源于电报码。最早的商业应用是贝尔公司的七位电传打字机。后来于 1963 年发布了该标准的第一版。在网络交换中使用的 ASCII 格式是在 1969 年发布的,该格式在 2015 年发展成为互联网标准。点击 RFC 20: ASCII format for network interchange,感受一下 1969 年的古香古色。
ASCII 编码一共定义了128个字符的编码规则,用七位二进制表示(0x00 - 0x7F), 这些字符组成的集合就叫做 ASCII 字符集。完整列表如下:

ASCII 码可以说是现在所有编码的鼻祖。
编码乱战及 Unicode 应运而生
ASCII 编码是为专门英语指定的编码标准,但是却不能编码英语外来词。比如 résumé,其中 é 就不在 ASCII 编码范围内。
随着计算机的发展,各个国家或地区,甚至不同公司都推出了不同的编码标准,比如中国推出了 GB2312、GBK 以及 GB18030;微软推出了 Windows character sets 。
由于不同编码标准是不兼容的,不同的国家有不同的字母,因此,哪怕它们都使用 256 个符号的编码方式,代表的字母却不一样。比如,130 在法语编码中代表了 é,在希伯来语编码中却代表了字母 Gimel (ג),在俄语编码中又会代表另一个符号。
同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。这些问题,如果只是在一个国家或地区内部使用还好。但是,随着互联网的发展,这种编码不兼容的问题将会严重阻碍信息的交流和互联网的发展。
于是,ISO 组织与统一码联盟分别推出了 UCS(Universal Multiple-Octet Coded Character Set) 与 Unicode。后来,两者意识到没有必要用两套字符集,于是进行了一次整合。这样,所有的字符都可以采用同一个字符集,有着相同的编码,可以愉快的进行交流了。
Unicode
Unicode (统一码、万国码、单一码、标准万国码)编码就是为了表达任意语言的任意字符而设计
在这套系统中: 一个字符代表一个 code point,不存在二义性。Unicode 是一个标准,只规定了某个字符应该对应哪一个 code point,但是并没有规定这个字符应该用即为字节来存储。有些关键术语,在这里也做个说明。
码点(Code Point)
码点(Code Point)是分配给每个 Unicode 字符的唯一编号。D瓜哥的理解是给每个字符分配了一个身份证号。
通常会使用十六进制进行表示,表示格式: U+xxxx 或 U+xxxxx。例如, 瓜 的码点是 U+74DC。
组合标记(Combining Mark)

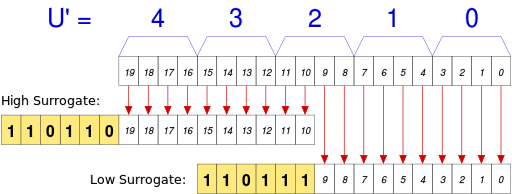
常见字符集之间的转换方法(Unicode、UTF-8、UTF-16、UTF-32 和 GB18030 等)
Unicode ↔ / ⇌ UTF-16
| Unicode | UTF-16 |
|---|---|
| 2 Byte存储,编码后等于 Unicode 值。 |
|
|
TODO:
为啥要这样处理?
从 Unicode 向 UTF-16 转换时,需要减去
0x10000。那么,反向转换时,怎么判断要不要加回去0x10000? 是遇到U+Fxxxx的情况就加0x10000吗? UTF-16 - Wikipedia 有解释,其实不需要判断,只要确定是是两个字符就需要加0x10000?怎么区分是一个字符?还是两个字符?:[U+D800, U+DFFF] 之间的编码没有分配,留给两个字符的编码做前缀使用:[0xD800, 0xDBFF] 用于标注 high surrogate;[0xDC00, 0xDFFF] 用于标注 low surrogate。参考 UTF-16: Code points from U+010000 to U+10FFFF - Wikipedia。
常见术语的解释说明
常见乱码及解释
结合相关标注,指定汉字的正则表达式
TODO: 结合相关标注,指定汉字的正则表达式
中日韩统一表意文字 - Wikipedia — 这里提到很多汉字区块。
vim 编码设置
Java的内部表示
Java originally used UCS-2, and added UTF-16 supplementary character support in J2SE 5.0.
UTF-16 - Wikipedia — 这里说明这个问题了!
Java Properties 文件的编码
MySQL 编码问题
JavaScript 编码
在JavaScript中,所有的string类型(或者被称为DOMString)都是使用UTF-16编码的。
字体的渲染方法(待选)
字体相关信息
根据实验以及看到的一些资料,有一个感觉:UTF-8、UTF-16 以及 UTF-32 相互转换时,需要将字符集编码转化成 code point,然后再根据范围转换为对应的编码。
这块的知识还需要用实验来验证!
Little endian 和 Big endian
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
在 Java 中,使用 byte[] utf16Bytes = string.getBytes(StandardCharsets.UTF_16); 获得的字节数组,头两位都是 FEFF,这和 Java 的采用大头方式的规范是吻合的。
BOM全称Byte Order Mark,字节序标记,除了utf-16之外,utf-8也可以添加bom,它的bom固定为0xEFBBBF,选择编码方式为utf-8 with bom时,生成的文件流中就会出现这个bom。为什么utf-8可以不需要bom呢,因为utf8是变长的,它根据第一个字节信息判断每个字符的长度,不存在正反顺序的问题,我们日常使用的utf-8都是不带bom的。
Java 中的 char对应的是Unicode的基本平面BMP。Java里的char是编译器里定死了的,它对应的就是BMP,也可以认为是utf-16的2字节部分。
如何渲染字体?
首先字体内部是有一个自己的编码号的,用于索引图元(Glyph),但是外界不会知道它。字体内部的各种数据比如 GSUB 和 GPOS 都是用这个索引号编的。
将图元和文字关联起来的东西是 cmap 表,这表的格式十分多,用来支持不同的外部编码:最常用的 UCS-2 外部编码(FontForge 里面称 UnicodeBMP)使用 Format 4,UCS-4 外部编码(FontForge 称 UnicodeFull)使用 Format 8、Format 12 等。
然后是绘图的时候,WINAPI 或者其他的 API 会对文字编码进行转换。我记得 Windows 是默认把其他编码转换成 UTF16LE 的。
Windows 里分为两种类型的编码系统,其实就是两个系统编码函数,用于转换字符串为unicode,一个是 codepage,这个是可以在系统中切换语言选项中进行切换的,代表当前的位于unicode表中的第几页,另一个是UTF-16的小端序,这个是自windows 2000 之后就开始内核(Window NT)内置的一个编码,因为当时没有utf-8,所以选择这个编码作为了内核的内置编码。
对于上层软件来说,需要通过utf 或者 iso 等等上层复合编码转换成系统支持的编码 然后根据charcode 去字体系统里取字形, 每一个字体都提供一个charMap,然后系统中用charcode去里边筛选,找出glyph图元,然后再交给软件渲染
encoding - What are Unicode, UTF-8, and UTF-16? - Stack Overflow
Unicode Chart — 费了很大劲,找了一个比较全的 Unicode Code Point。美中不足的时,没有展示出来 UTF-8、UTF-16 等编码。
Unihan data for U+74DC — 可以直接在这个页面上查找相关文字的编码信息。有一个地方有待改进,就是对 Emoji 表情支持的不好。尝试了一下查找 Emoji 表情,直接提示报错了。
Full Emoji List, v14.0 — 这里有一个 Emoji 表情的完整列表。
Roadmap to the BMP — 从这里也可以看出,除了 BMP,其余还有 SMP、 SIP、 TIP、 TIP 和 SSP。不止部分文章描述的只有 BMP 和 SMP 两个平面。看样子,以后可能还会有其他的什么 Plane。(中间从 4 到 13 的序号是空着的。)
ASCII Table - Openclipart — 感谢他们制作出来的精美 ASCII Table 图表。
看在D瓜哥码字的辛苦上,请友情支持一下,D瓜哥感激不尽,😜
 |  |
欢迎关注D瓜哥的微信公众号,在公众号可以获取我的微信二维码:

公众号的微信号是: jikerizhi。如果图片加载不出来,可以直接通过搜索公众号的微信号来查找D瓜哥的公众号。 |
Recommend
-
36
程序员 - @yantianqi -
-
20
告别 2019,迎接 2020 2019-12-31 个人成长 我的 20...
-
17
2KB: 文档乱码怎么办? 字符编码,字符集的故事薛定谔的喵一个人NB的不是标签浏览网...
-
7
也谈博客网新版亮相 —— 看法与意见 谢益辉 / 2005-07-20 今天时间不多,只是先写下一个比较粗略的提纲文字。 1、时刻要记得社会责任感。 无论如何改版,都不应该忘记一个网站的存在是要对社会负责的。现在的这个网...
-
7
最后一次啰嗦 —— 博客网的技术问题,加油 谢益辉 / 2005-07-27 不知道博客网到底给自己什么样的定位,不要吹什么 “门户”,这种帽子还是别人(比如这千万个用户)给你戴上比较合适,不要自己抓着往自己头上扣。上次和讯 CEO 谢文在...
-
6
博客网已经完蛋,鉴定完毕,烧纸 谢益辉 / 2006-01-13 我 K,博客网的系统现在烂得惨不忍睹了。老方,我也不跟你说什么了,口水也说干了,我想走了。 感谢认真复制粘贴回复用户的客服们,但是博客网这地儿,实在不适合人类...
-
7
从零开始学Mysql - 字符集和编码(上) 上一节我们系统的阐述了关于系统配置的相关细节内容,而这一节我们需要了解关于字符集和编码的内容,字符集和编码的规则其实也算是入门mysql经常遇到的一个坑,基本每个人学习过程必定会遇到数据库存储中文...
-
5
字符集与编码 一个比特(bit)可以是0,或者是1,8个比特(bit),组成一个字节(byte)。全为0时代...
-
7
中文编码字符集新国标发布:收录8.8万汉字 新增1.7万生僻字 2022-07-28 22:58 出处/作者:快科技 整合编辑:佚名 0
-
4
地瓜社区:共享空间营造法 2022年8月1日 出版 地瓜社区起源于2013年的北京花家地地下室改造项目,于2015年正式创立,目前已结出四个“地瓜”。它通过对社区闲置空间的设计、改造和再利用,创造“平等、温暖、好玩、创新”的社区...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK