

A Better Way to useMemo and useCallback
source link: https://betterprogramming.pub/a-better-way-to-usememo-and-usecallback-58288a19f91c
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

A Better Way to useMemo and useCallback
An appeal to authority fallacy
Photo by Karsten Würth on Unsplash
To start off, this post isn’t an argument of the facts laid out in When to useMemo and useCallback post by Kent C. Dodds. Instead, it is specifically the argument against the overgeneralized application of it. What is especially crazy to me, I can actually still remember when this article was released. I can’t say that to any other article. Throughout the last 3 years, through different companies, programmers, reviewers, etc, this is the most quoted article I’ve come across. Not by a little, but by a mile!
It’s also usually incorrectly applied.
Before we dig in, I highly recommend reading the original article. It’s a great article with super useful information. It will also be crucial to understand before diving into what the “counter” argument is. It’s not really fair to call it a counterargument. My argument is closer to “this information is good until…”.
Let’s walk through an all-too-common scenario. You’re at work one day, and a meeting just wrapped up. You can’t really jump into your ticket because there’s a meeting coming up. It’s actually an hour away, but you know what, that’s close enough, don’t want to get your head into it just to have to stop immediately after.
A colleague pings you on slack and wants you to help them snap through a pull request they’ve got ready to go. You’re pretty sure they’re just wanting you to hit approve but you decide to take a quick pass through the code and come across a new component that looks something like this:
function List({items}) { const activateItem = () => {
// Do something here
}; return(
{items.map(item =>
<Item onClick={activateItem}>{item.name}</Item>
)}
)
}
As you pass by, you toss a comment on the activateItem function reminding the author to wrap their function in a useCallback. You keep passing along the code and spot another chunk:
function Body() {
const {cats} = useCats();
const catsWithLongFur = cats.filter(cat => cat.hasLongFur); return (<List items={catsWithLongFur} />);
}
Easy spot, you’ll toss on a reminder to the author that they should useMemo the catsWithLongFur filter.
Feedbacks done! But alas, your coworker pings you again. The message reads “I replied to your feedback”.
Oh no.
This scenario has occurred to me on a number of occasions, and almost every time the reply deals with the same disagreement. You get a message from your coworker that both useMemo and useCallback aren’t needed in these instances, because you’re prematurely optimizing. In almost 90% of these cases, the above Kent C. Dodds article will be linked for further reading.
What side are you on? Are they right?
And herein lies the problem with this article. Most of the examples Kenny D uses are very, very simple, but choosing these types of examples also hides an important distinction the author has made. None of his examples ever pass these variables through another React component. You’ll notice both examples are clearly a “leaf” component, one where we are only using semantic HTML, instead of another component. And that’s sensible, this is intended as a simple guide. But it does obfuscate an architectural problem.
Why is that important? Well, to put it lightly, there are really two functions of useMemo or useCallback:
- Optimization
- Referential equality
Optimization
The first reason is optimization. This is a pretty clear-cut example with useMemo. If you are doing an expensive calculation on data that wouldn’t need updating every render, memoizing the data can be incredibly handy.
Take this example:
import { generate } from './utils';
import { useDataOne, useDataTwo } from './stores';function Example() {
const { dataOne } = useDataOne(); // Only queries on component init
const { dataTwo } = useDataTwo(); // Only queries on component init const result = useMemo(() => generate(dataOne, dataTwo), [dataOne, dataTwo]); return (
<div>
{data.map(x => <div>{x.result}</div>
</div>
)
}
I’ve memoized that our call to the generate function above since I know the dependencies of it will be rarely, if ever, changed. If I hadn’t done this, any change to the component would mean that the calculation would rerun.
Now, with that being said, if the above calculation is cheap the memoization may not be worth that overhead. There could also be a case where dataOne or dataTwo must recollect its data every update. If that happened, as a dependency of our useMemo call, it would mean that every render will also cause the generate function to run again, thereby negating the need for memoization. React is quite performant, and having these sorts of memoizations when they are not needed is adding both an unnecessary performance overhead, as well as adding complexity to your code.
And that's what the article above is about. Understanding when optimization is worth it, and making a choice from there. Which is a great bit of advice. But there’s still a second factor we need to consider in making our choice to use these react hooks.
But what isn’t mentioned in the article?
Referential Equality
Let’s first explain what referential equality means in simple terms, and then expand on what that could mean for our components, and patterns to be aware of in the case of larger applications. Referential equality is referring to two objects pointing to the same object in memory. Let’s code out a really simple example.
💡 Through out this blog post when I refer to “object” I’m referring to either an object, array or function. In Javascript, all three of these are “object” types, albeit with special properties. Regardless, they share referential equality mechanics, so can be thought of as the same.
const objA = { test: 'hi' }
const objB = { test: 'hi' }objA === objB // returns false

In our above example, the objA and objB variables are pointing to two different spots in memory. Although from our perspective, they seem like the “same” object, referentially they are two different things, therefore when we try to test their equality, it returns false. If we were to alter objA, objB would not receive that alteration. On the other hand:
const objA = { test: 'hi' }
const objB = objAobjA === objB // returns true
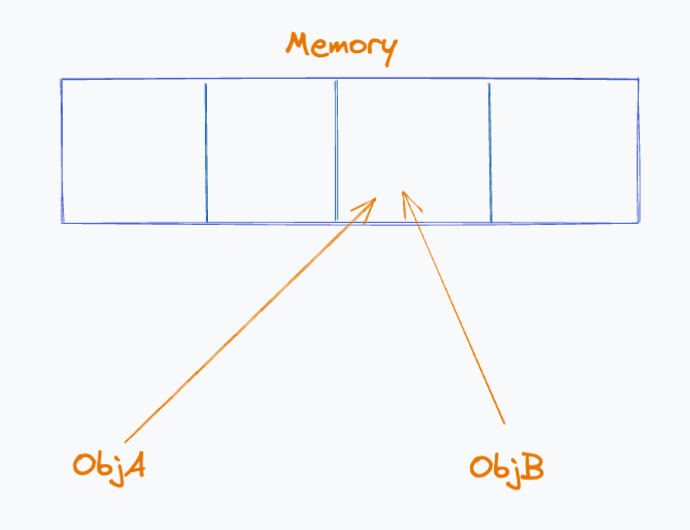
These objects are the same, and alterations to one variable would change the other variable as well. These variables are pointing to the same spot in memory, therefore they are referentially equal. Using this type of equality check is a very simple, and very cheap, way that React, and many other libraries to track changes to state when it comes to objects.
💡 You may wonder if there are other ways to track equality, and there are! These include shallow comparisons and deep comparisons, and are also used in react for different purposes. It should be noted though that these can be slower! Each type of comparison check has it’s pro’s and cons, so it’s best when to use each one!
So what does referential equality mean for us when we’re talking about useMemo? Let's build on our previous example above with a derived calculation:
import { generate } from './utils';
import { useDataOne, useDataTwo } from './stores';function Example() {
const { dataOne } = useDataOne(); // Only queries on component init
const { dataTwo } = useDataTwo(); // Only queries on component init const result = useMemo(() => generate(dataOne, dataTwo), [dataOne, dataTwo]); const secondValue = useMemo(() => data.filter(item => item.isValid), [data]); return (
<div>
{secondValue.map(x => <div>{x.result}</div>
</div>
)
}
So, if you’re new to dependency arrays, I do have another blog post going in depth about the topic. But in the above example, the logic chain follows these steps:
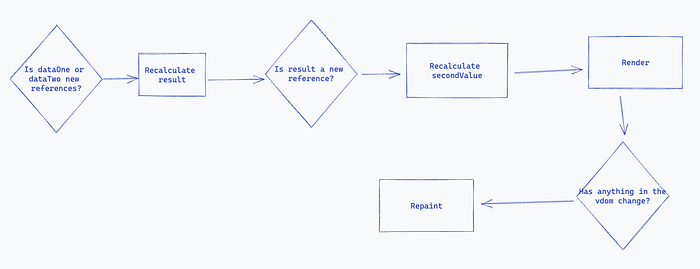
- Is
dataOneordataTwonew references (i.e. are they pointing to the same spot in memory)? If they are, recalculateresultby running thegeneratemethod. - Is
resulta new reference (i.e. did the above case happen). If it is, recalculatesecondValue
In this example, if dataOne was to receive a new reference, then result would be recalculated, followed by secondValue also being recalculated, and this is to be expected.
But if dataOne and dataTwo do not change their reference, we would essentially skip all the way down to the render call, thereby skipping two whole calculations. Now, this isn’t free or guaranteed. We are doing referential checks to make sure that this is indeed something we want to do, as well as maintaining in memory the data needed both for and returned by the memoization. At any time, React can clear the memory that this memoization may be stored in, causing a recalculation. It’s up to you as a developer to determine when this trade-off is worth it. More on this later in the blog.
Here’s the good news. If this is happening within a single component, which often is the case, it can be pretty simple to calculate and pick when to optimize these calculations or be aware of these dependencies. Even better, it’s often best to start without memoizing this and only add memoization when performance becomes an issue.
Unfortunately, things become a bit trickier when we are working across multiple components. Let’s set up some code we’re going to use for this example, it’s only going to consist of two components.
import { generate } from './utils';
import { useDataOne, useDataTwo } from './stores';function Example() {
const { dataOne } = useDataOne(); // Only queries on component init
const { dataTwo } = useDataTwo(); // Only queries on component init const result = generate(dataOne, dataTwo);
const onChange = () => { //doSomething } return (
<List items={data} onChange={onChange} />
)
}const List = ({data}) => {
return (
<ul>
{data.map(item => <li>{item.name}</li>)}
</ul>
)
}
How does data and onChange affect the List component itself, and from a more broad perspective, how does it affect the Developer Experience (DX) for your colleagues moving forward? These can be tied back to our two focus areas, optimization, and referential equality. Let's dive in.
💡 You may be wondering why we haven’t discussed strings, booleans or numbers. These are primitive types that don’t rely on referential equality to determine change, as it’s a very cheap equality check to determine if 7 === 7.
Optimization across multiple components
Regardless of your function/object reference changing, the child component List will always re-render when the parent component Example re-renders in our example above. Maintaining referential equality here has no effect on restricting the rendering of a child. Yet in my experience, this is the most used reason for implementing useMemo and useCallback, or in reverse, the most common reason why we also shouldn’t use it as well.
The only time where useMemo or useCallback stops a re-render for a child component is when the child component is memoized with React.memo (or a PureComponent for us boomers). I apologize, React.memo is another form of memoization (there’s one more if you want to read the memo vs memoize blog post) that we’ll need to discuss just a bit first. Let’s see that in the code:
import { generate } from './utils';
import { useDataOne, useDataTwo } from './stores';function Example() {
const { dataOne } = useDataOne(); // Only queries on component init
const { dataTwo } = useDataTwo(); // Only queries on component init const result = useMemo(generate(dataOne, dataTwo), [dataOne, dataTwo]);
// const onChange = () => { //doSomething } return (
<List items={data} />
)
}// This component only rerenders if the data object reference changes
const List = React.memo(({data}) => {
return (
<ul>
{data.map(item => <li>{item.name}</li>)}
</ul>
)
})
In the above example, the List component will only re-render if the reference for result changes. If we had not used useMemo, the List component would re-render every single render of the Example component, regardless of the React.memo, since result would always be a new reference. We don’t have the time to jump into exactly how the React.memo functionality works (or the similar PureComponent class-based alternative). But my best suggestion here is, don’t use it unless you absolutely know you need to. I think this tweet from Tanner Linsley outlines it best. When given the option, you should optimize the speed of each render, not “unnecessary” renders.
So what does that mean for our usage of useMemo and useCallback? We’ve decided we’re not going to use React.memo, so any optimization won’t stop re-renders. Does that mean we should only use them for optimizing slow calculations?
The answer is no, but with a big asterisk. First, let’s look at the worst-case scenario as to why we don’t want to ignore useCallback and useMemo, and then finally step through a flow I generally follow when deciding what to memo.
Don’t lay landmines
So let’s imagine a very very simple example that can cause this issue, and see if you notice it as we are going. This is going to be very contrived, but the goal is to capture how simple these things can sneak up. In our example we have a DataModal component we’re creating that implements using a generic List component.
function useData() {
return [{name: 'John'}, {name: 'Paul'}, {name: 'Ringo'}, {name: 'George'}]
}function DataModal(props) {
const {data} = useData();
const { metric } = useMetrics(); return (
<div className={styles.modal}>
<List items={data} />
</div>
)
}
And a basic List component
function List(props) {
const { items, onChange } = props; return (
<ul>
{items.map(item => (<li>{item.name}</li>))}
</ul>
)
}
Now, a few months later a different developer gets a feature: map the data passed into a large data set. It’s obviously contrived to keep this simple, but these things happen. Especially in larger applications where architecture decisions can be very spread out over multiple teams. So they decide to do the following
function List(props) {
const { items, onChange } = props;
const { selected, setSelected } = useState(null);
const { urlParam } = useRouter();
const { data } = useBigData();
const dataSet = mapToLargeDataSet(items, data); return (
<ul>
{items.map(item => (<li onClick={onClick}>{item.song}</li>))}
</ul>
)
}
But they quickly realize — “this is an expensive calculation, I’m going to memoize it” and add const dataSet = useMemo(() => mapToLargeDataSet(items, data), [items, data]). But here’s the problem, the items object is always a different object, every single render. Hopefully the developer notices, but now they have to work their way up the chain, finding out what data is changing each render. For a small team, this may seem trivial. But on larger, enterprise teams, this issue may not be on your team, or even worse, you can’t make this alteration now because you are unsure if other teams are dependent on this issue now.
This can happen outside just data memoization too. Imagine we had a side effect on a function passed in
import { subscribeToExternalLibrary, unsubscribeToExternalLibrary} from 'someplace';function Example({onChange}) { useEffect(() => {
window.addEventListener('scroll', onChange);
return () => {
window.removeEventListener('scroll', onChange);
};
}, [onChange]); <button onClick={onChange}>Click me</button>}<Example onChange={() => console.log('hello')} />
In the above example, because we don’t wrap our function in a useCallback, we will actually unsubscribe and resubscribe every single render. Dependent on what the effect is being used for, this can do things like: causing infinite re-renders, reinitializing 3rd party libraries (often breaking them), or just simply adding a performance hit of continuous reconnections.
You may also look at this and think “Well, when this useEffect is added I can update the calling functions to use useCallback”. I really would avoid that line of thinking, as your codebase grows, and as your team grows, this sort of upkeep will become more and more expensive. Even more so, some developers may end up “depending” on this incorrect. We’ve often referred to this in the past as laying landmines.
A developer has either created side effects, or created an opportunity for incorrect side effects in the future. For example, imagine in our Example component above we did not have a scroll effect. Now, if someone used this component without wrapping their onChange in a useCallback, and a different developer decided to add that scroll effect, they’ve now broken some other functionality. Functionality they are not aware of. That’s why we call it laying landmines.
When to useCallback or useMemo
So with the problem laid out in front of us now, we should outline the flow of when should we actually apply useCallback and useMemo appropriately.
Logical flow to applying useCallback
Easiest one to define, let’s break down a flow for when you should useCallback. The flow might look complex at first, but it’s a good set of rules to simply step through.
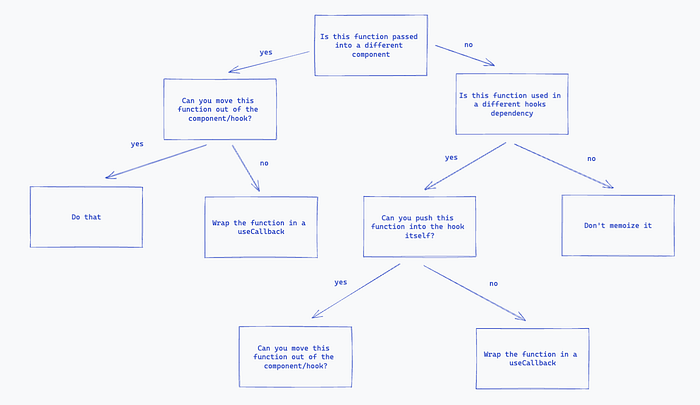
Not a defacto list of useCallback rules, but something to keep in mind
The core goal here should always be to ask yourself can this function be isolated to a separate file or external to the component. If the function must exist in the component, can we isolate the function to the hook that needs it? Basically, can we maintain clean code practices? If these all fail, then we should wrap our function in a useCallback. Unlike what we will see in the useMemo flow, we aren’t worried about performance. This is a common point of confusion for some, but creating a memoized version of a callback has no effect on performance. Its goal is purely for referential equality amongst other components or dependencies.
💡 This is a good time to note that by extracting the function, it will force you to create a more pure function. This makes it easier to follow, easier to test, and easier to reuse.
Logical flow to applying useMemo
Let’s take a walkthrough of a general logical flow, then discuss some key areas. It should be noted, this isn’t some defacto rules to follow. Instead, it should give some insight on the general steps I take prior to memoizing something. It’s always best to keep in mind that if you can handle the issue outside of a memoization, it’s usually worth taking that route. So lets look:
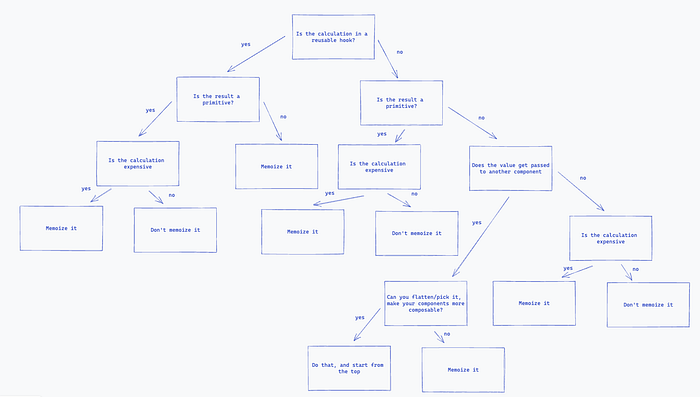
Not a defacto list of useMemo rules, but something to keep in mind
Is the calculation in a reusable hook?
When you are returning data from a hook, you should always be thinking about how other developers are going to consume it. Learning to design APIs with empathy is one of the strongest skills a developer can learn. If your hook is returning a function that is created internally to the hook, it should be wrapped in a useCallback. Similarly, an object should be referentially equal between renders unless something has changed.
Can you flatten/pick it or create more composable components?
A good rule of thumb to follow when you are passing props into another component is to avoid passing objects. There are a number of ways we can do this with better component design, such as:
- Without a doubt, the most likely solution is to make your components more composable. If your components frequently are leaf components (i.e. they don’t accept children), you should rethink your component structure. Creating composable components allows us to push responsibility up the component chain, and makes the flow easier to read, while also creating more reusable components.
- Can you query for the result set within the component list itself? This can be done across a wide range of libraries like react-query or redux.
- If you are mapping over a set of data, that passes each item into a component, can we flatten that data into the component props? This hopefully means we can limit the data to primitives, making referential equality much easier.
- Similarly, if we are mapping over a set of data, similar to 2, we can also fetch each item from a data store using the id passed in. Some people like this approach, and some hate it — but it is an option.
Conclusion: Designing APIs with empathy
One of the biggest challenges when you take an example like Kent C Dodds's article into the real world is that it’s exactly that: a very small example. He had to trim out longer explanations, edge cases, and very important information to make his article straightforward and understandable. Heck, I originally wrote this blog with very large sections trying to write differences between useMemo and React.memo. But these things need to be cut away to make very punch and informative pieces.
And obviously, it worked. This article gets linked to me in some way almost once a month since it’s been published, and for good reason. It’s a fantastic article that gives you some knowledge on the topic. But when you scale it out to a larger web application, you have to understand there is more nuance with that decision. You need to understand how this reflects developers in years to come, and sometimes make a DX choice instead of an optimization choice.
Your goal when designing an API is to Marie Kondo the process. You not only want to create an API that works but applying that API brings joy to developers using them. There’s an incredible balancing act between creating a simple API and giving escape hatches to more complex processes. You want to think about how this may need to be expanded one day, while also ensuring the critical path doesn’t require shortcuts. Finally, one of the goals should be to always create an API that avoids landmines. The real reason we want to handle these cases is that one day, weeks, months, maybe even years down the line, a developer is going to be looking at the clock, head in hand with an issue. The demo is in 1 hour, and they’ve spent days working backward through your code, trying to understand why their page is infinite reloading, and it’ll be because you didn’t want to wrap a function in a useCallback.
Recommend
-
54
【译】什么时候使用 useMemo 和 useCallback 2019-08-19 译文...
-
18
Lets, check react advanced hooks, i.e. UseCallback , UseMemo , UseRef , and UseContext . All these come under React 16.8 version and help t...
-
5
The Difference Between useMemo and useCallback — An In-Depth LookSeptember 24th 2021 5 A useMemo...
-
8
React-Hooks: What is The Difference Between useCallback And useMemo?October 13th 2021 new story8React...
-
8
Charles 🛰 Posted on Feb 7...
-
8
useMemo 把“创建”函数和依赖项数组作为参数传⼊入useMemo,它仅会在某个依赖项改变时才重新计算memoized 值。这种优化有助于避免在每次渲染时都进⾏行行⾼高开销的计算。 importReact, { useState, useMemo } from"react"; export default f...
-
7
IntroductionIf you've struggled to make sense of useMemo and useCallback, you're not alone! I've spoken w...
-
8
When to use the two hooks - useCallback and useMemo? Sep 22, 2022 , by Onkar Hasabe 3 minute read Every...
-
8
本篇文章我们主要了解下 useCallback 和 useMemo 是如何来优化React组件的。 我们解析的源码是 React18.1.0 版本,请注意版本号。React 源码学习的 GitHub 仓库地址:
-
8
How does useMemo and useCallback work ? When render a component, React will process the whole Component code. There might be several computed values and functions that its values only depends on f...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK