

微服务 Zipkin 链路追踪原理(图文详解) - mikechen的互联网架构
source link: https://www.cnblogs.com/mikechenshare/p/16825729.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


一个看起来很简单的应用,可能需要数十或数百个服务来支撑,一个请求就要多次服务调用。
当请求变慢、或者不能使用时,我们是不知道是哪个后台服务引起的。
这时,我们使用 Zipkin 就能解决这个问题。
由于业务访问量的增大,业务复杂度增加,以及微服务架构和容器技术的兴起,要对系统进行各种拆分。
微服务系统拆分后,我们可以使用 Zipkin 链路,来快速定位追踪有故障的服务点。
今天重点讲解 Zipkin 链路追踪的原理与使用 @mikechen
Zipkin 基本概述
Zipkin 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),能够收集服务间调用的时序数据,提供调用链路的追踪。
Zipkin 其主要功能是聚集来自各个异构系统的实时监控数据,在微服务架构下,十分方便地用于服务响应延迟等问题的定位。
Zipkin 每一个调用链路通过一个 trace id 来串联起来,只要你有一个 trace id ,就能够直接定位到这次调用链路,并且可以根据服务名、标签、响应时间等进行查询,过滤那些耗时比较长的链路节点。
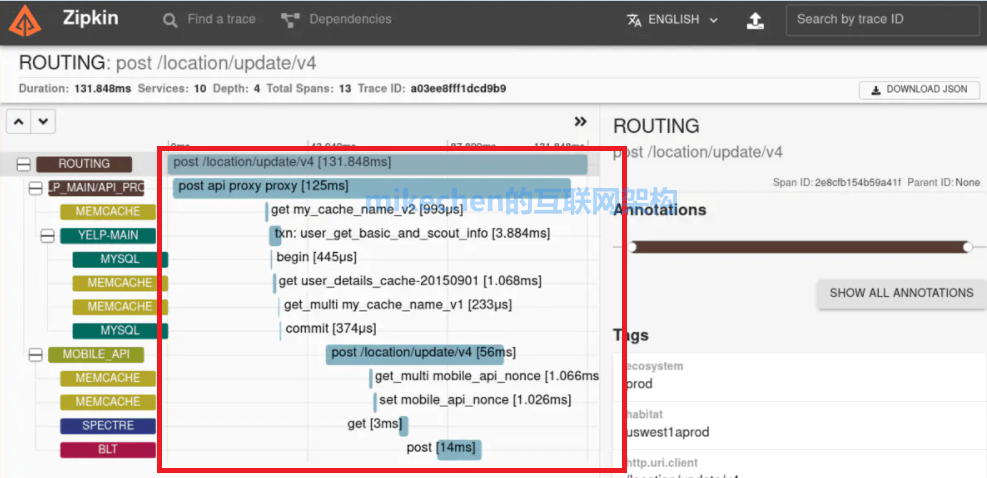
为什么用 Zipkin ?
大型互联网公司为什么需要分布式跟踪系统?
随着业务访问量越来越大。例如:比较典型的是淘宝,淘宝从早期的单体开始往分布式微服务演变,系统也随之进行各种拆分,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑。
一个客户端的请求,例如:一次下订单请求,可能需要多次的服务调用(商品、用户、店铺等系统调用过程),最后才能完成。
当请求变慢、或者不能正常使用时,我们不知道是哪个后台服务引起的,这时,我们就要想办法快速定位服务故障点。
Zipkin 分布式跟踪系统就能非常好地解决该问题,主要解决以下3点问题:
1. 动态展示服务的链路;
2. 分析服务链路的瓶颈并对其进行调优;
3. 快速进行服务链路的故障发现。
这就是 Zipkin 服务跟踪系统存在的目的和意义。
当然了,除了 Zipkin 分布式跟踪系统以外,我们还可以使用其他比较成熟的实现,例如:
- Naver 的 Pinpoint
- Apache 的 HTrace
- 阿里的鹰眼 Tracing
- 京东的 Hydra
- 新浪的 Watchman
- 美团点评的 CAT
- skywalking
- ......
知道了 Zipkin 的使用原因、使用场景和作用,接下来,我们来了解 Zipkin 的原理。
Zipkin 的原理
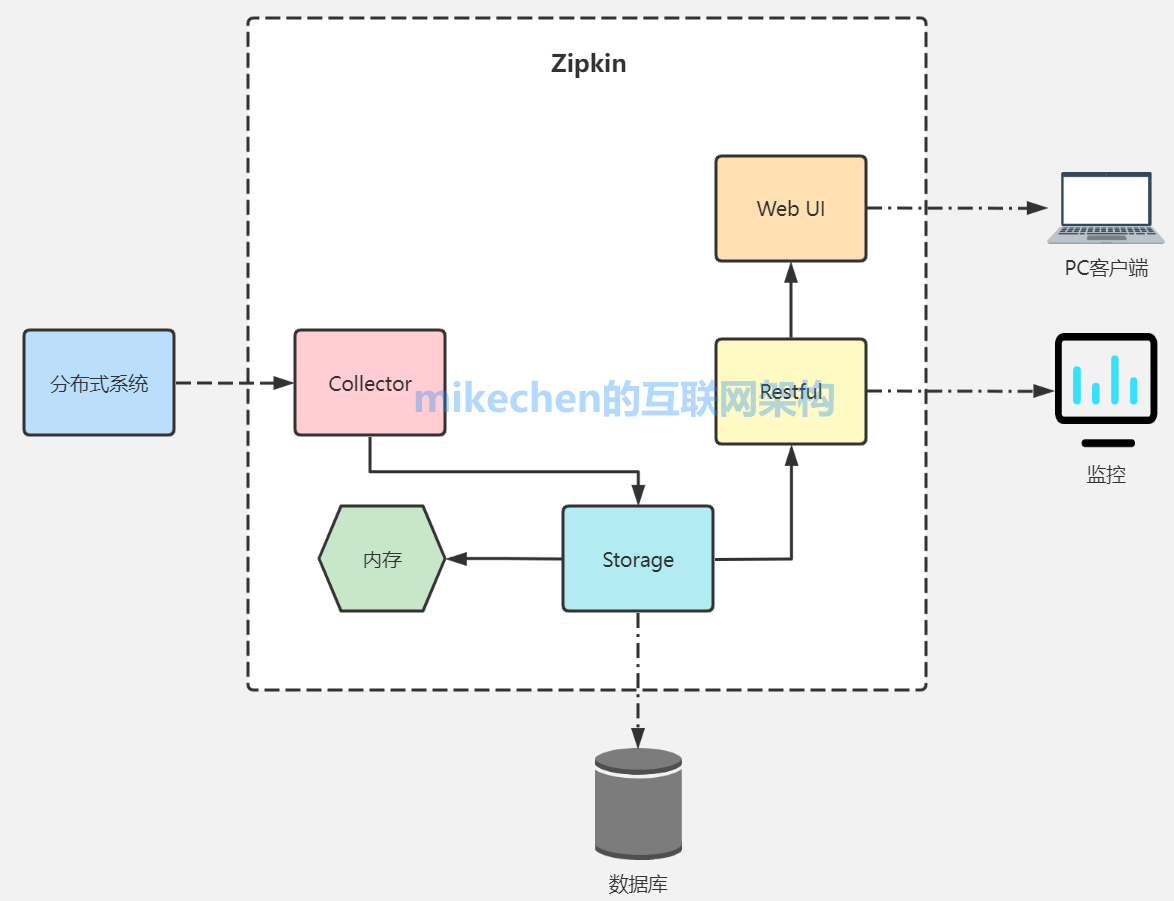
1. ZipKin 架构
ZipKin 可以分为两部分:
- ZipKin Server :用来作为数据的采集存储、数据分析与展示;
- ZipKin Client :基于不同的语言及框架封装的一些列客户端工具,这些工具完成了追踪数据的生成与上报功能。
整体架构如下:
2. Zipkin 核心组件
Zipkin (服务端)包含四个组件,分别是 collector、storage、search、web UI。
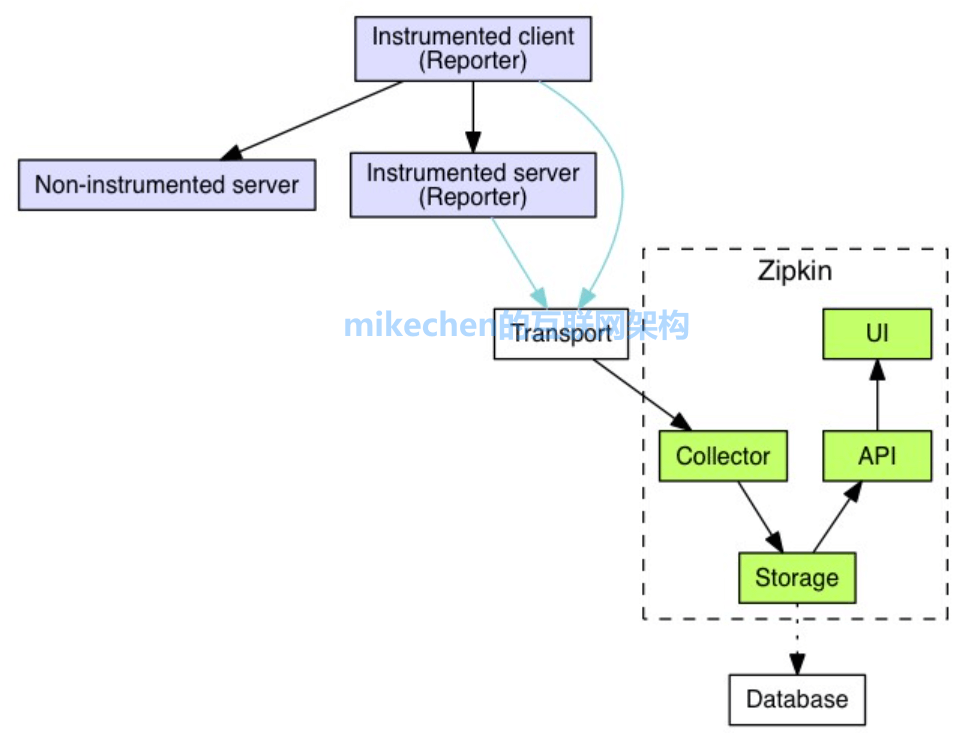
1) collector 信息收集器
collector 接受或者收集各个应用传输的数据。
2) storage 存储组件
zipkin 默认直接将数据存在内存中,此外支持使用 Cassandra、ElasticSearch 和 Mysql 。
3) search 查询进程
它提供了简单的 JSON API 来供外部调用查询。
4) web UI 服务端展示平台
主要是提供简单的 web 界面,用图表将链路信息清晰地展示给开发人员。
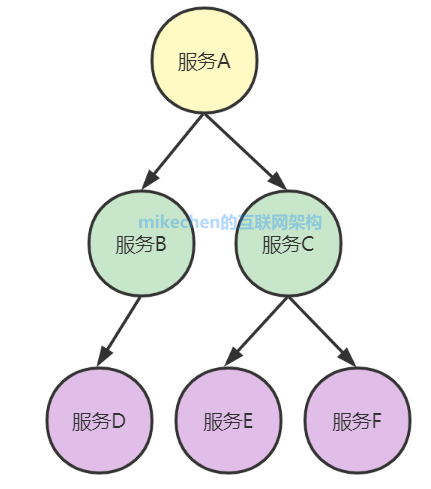
3. Zipkin 核心结构
当用户发起一次调用时,Zipkin 的客户端会在入口处为整条调用链路生成一个全局唯一的 trace id,并为这条链路中的每一次分布式调用生成一个 span id。
一个 trace 由一组 span 组成,可以看成是由 trace 为根节点,span 为若干个子节点的一棵树,如下图所示:
4. Zipkin 的工作流程
一个应用的代码发起 HTTP get 请求,经过 Trace 框架拦截,大致流程如下图所示:
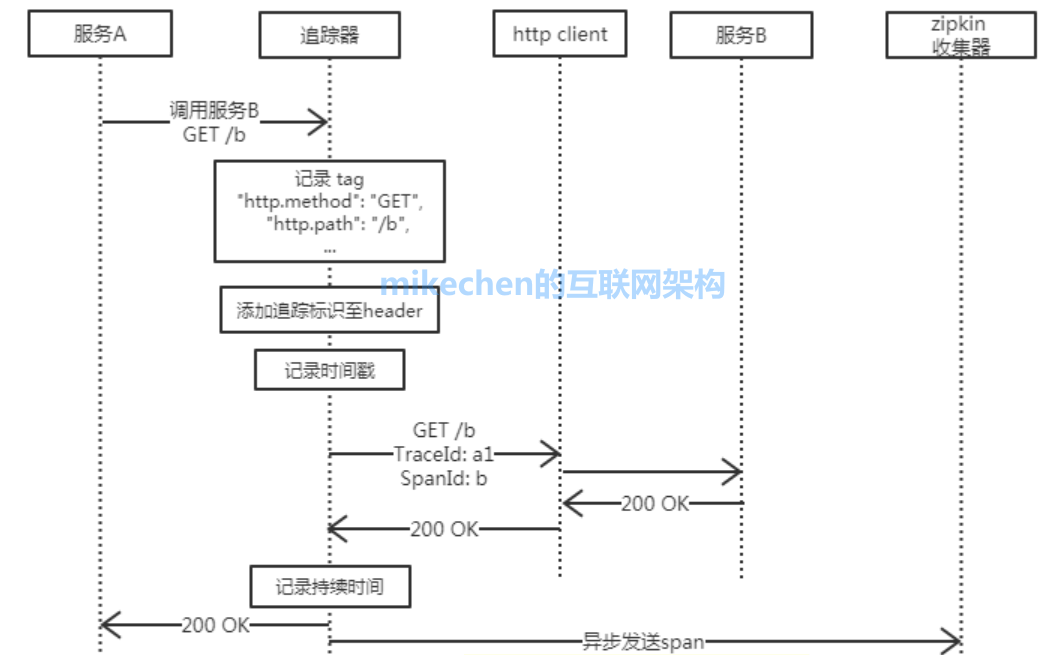
1)把当前调用链的 Trace 信息,添加到 HTTP Header 里面;
2)记录当前调用的时间戳;
3)发送 HTTP 请求,把 trace 相关的 header 信息携带上;
4)调用结束之后,记录当前调用话费的时间;
5)把上面流程产生的信息,汇集成一个 span,再把这个 span 信息上传到 zipkin 的 Collector 模块。
Zipkin 的部署与运行
Zipkin 的 github 地址:https://github.com/apache/incubator-zipkin
Zipkin 支持的存储类型有 inMemory、MySql、Cassandra、以及 ElasticsSearch 几种方式,正式环境推荐使用 Cassandra 和 ElasticSearch。

通过本文,我们知道了 Zipkin 的作用、使用场景、架构、核心组件,以及 Zipkin 的工作流程等,希望对大家掌握微服务有所帮助。
陈睿 | mikechen , 10年+大厂架构经验,「mikechen 的互联网架构」系列文章作者,专注于互联网架构技术。
👇阅读「mikechen 的互联网架构」40W 字技术文章合集👇
Recommend
-
68
分布式链路跟踪介绍 对于一个微服务系统,大多数来自外部的请求都会经过数个服务的互相调用,得到返回的结果,一旦结果回复较慢或者返回了不可用,我们就需要确定是哪个微服务出了问题。于是就有了分布式系统调用跟踪的诞生。
-
7
实现起来超简单的zipkin+sleuth微服务链路跟踪方案说是简单,tm那是找到解决方案之后才简单。可能是我用的SpringCloud版本太新了,自己配zipkin server把我给配吐了。又是版本冲突、又是注册不进去Eureka、又是访问ui报错、又是找不到Ob...
-
7
链路追踪:Sleuth整合ZipKin-51CTO.COM
-
9
MyBatis 是 Java 生态中非常著名的一款 ORM 框架,目前在一线互联网大厂中...
-
7
Java面试经常问到Mybatis一级缓存和二级缓存,今天就给大家重点详解Mybatis一级缓存和...
-
4
-
6
Java并发编程提供了读写锁,主要用于读多写少的场景,今天我就重点来讲解读写锁的底...
-
5
雪花算法简...
-
3
...
-
6
一:Kafka 简介 A...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK