

FLINK 基于1.15.2的Java开发-实时流计算商品销售热榜
source link: https://blog.csdn.net/lifetragedy/article/details/127141005
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

每一个商品被卖出去一条就以以下格式通过kafka发送过来,只对status=101的productId进行统计:
假设每过60s有上述内容被发送过来,那么flink应该会形成以下这样的一个排行榜在Redis内并且随着kafka传送过来的数据变化面实时变化着这个排行榜:
为什么a1001是2而不是3?因为只统计statusCode为101的商品
进入开发前需要解决的问题
时间窗口的问题;
每60秒一统计,这就是标准的流式计算了。我们假设每隔60秒进入的数据都是不同的,第一次60秒可能进入10条数据,那么这10条数据的“排行榜”情况和下一个60秒内进入的数据会有差别,因此每个“时间窗口”进入的数据都不一样,我们的统计就是根据这个“时间窗口”内的数据进行计算的,因此才叫实时处理。
它和传统的做法的区别在于如下根本区别。
传统的做法:
假设目前mysql内有100万条记录,取出最近60s数据虽然可能取出的结果只有10条但是数据量的底有100万,即你表面看到的是取出10条背后是100万条数据参与了计算。那么如果我们说这个时间窗口假设缩短到了每5秒一变化。试想一下前端是一个小程序,有1,000个用户并行打开这个界面,每个连接以每5s时间去生产假设生产内是1亿条记录这么刷一次,每5秒刷一次,你的生产直接会被搞爆。
流式的做法:
我才不管你这个底是1000万还是1个亿,我只取60秒内的数据,可能有10条也可能是1万条,也可能是10万条,对于flink来说,这点数据量so what?一点不care。
所以我们需要先解决这个时间窗口的问题。

排名的问题;
这边我们可以取巧,我们使用了TreeMap里的内置compare,我们覆写这个方法,下面上代码
然后把以上两块内容合并,写入Redis就搞定这件事了,下面给出完整代码
ProductAggregate.java
SumSplitter.java
SumReport2RedisMapper.java
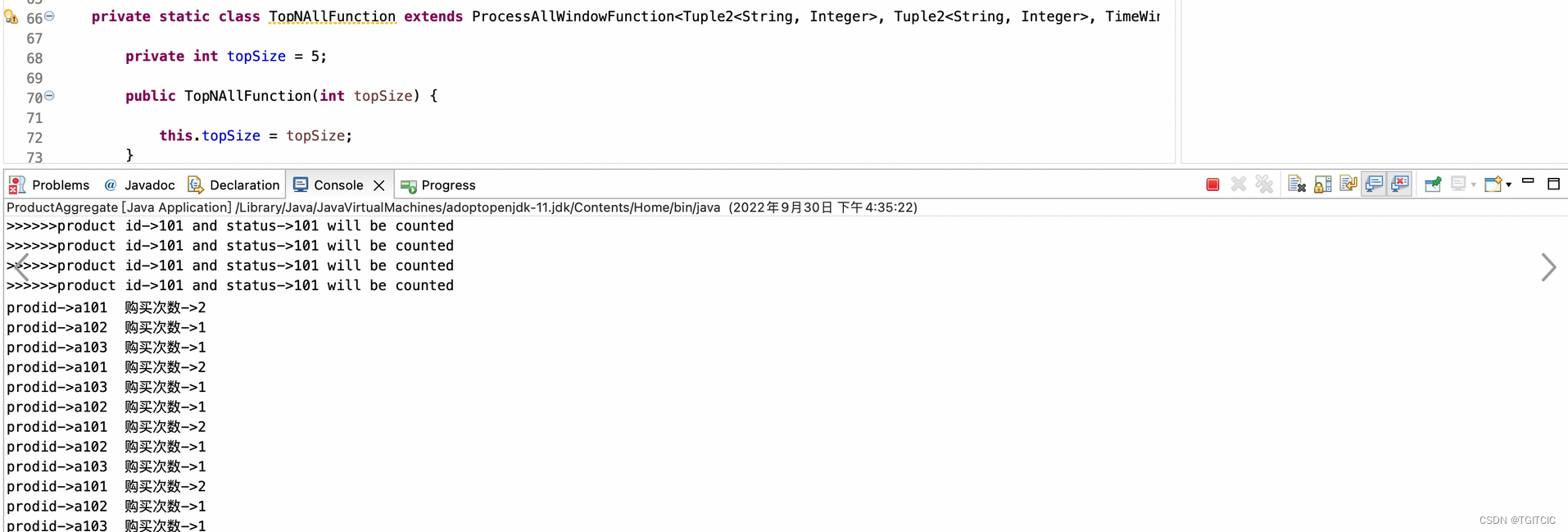
然后我们在kafka处输入如下内容

我们去Redis内可以看到有一个这样的Key生成了,内容如下:

然后页面做个实时查询的。。。不管什么页面也好、做个什么APP也好、做个什么小程序也好,连着这个Redis数据结果,随便刷。。。啊我。。。”洗刷刷洗刷刷,洗刷刷“
Recommend
-
52
一、前言 这篇主要由五个部分来组成: 首先是有赞的实时平台架构。 其次是在调研阶段我们为什么选择了 Flink。在这个部分,主要是 Flink 与 Spark 的 structured streaming 的一些对比和选择 Flink 的原因。...
-
7
1. Flink Table API的整体实现流程主要操作流程如下:// 创建表的执行环境 val tableEnv = ... // 创建一张表,用于读取数据 tableEnv.connect(...).createTemporaryTable("inputTable") // 注册一张表,用于把计算结果输出 tab...
-
15
端到端的实时计算:TiDB + Flink 最佳实践PingCAPSQL at Scale作者简介
-
5
苹果恢复在土耳其区域的商品销售 全线提价25% 2021年11月27日08:50 新浪科技综合 我有话说(0人参与) 收藏本文 ...
-
10
随着有赞实时计算业务场景全部以 Flink SQL 的方式接入,对有赞现有的引擎版本——Flink 1.10 的 SQL 能力提出了越来越多无法满足的需求以及可以优化的功能点。目前有赞的 Flink SQL 是在 Yarn 上运行,但是在公司应用容器化的背景下,可以统一使用公司 K8S...
-
5
苏宁易购经营逐步恢复 去年四季度商品销售规模预计环比增长25.48% 1月28日,苏宁易购发布2021年度业绩预告。公告显示,2021年四季度苏宁易购销售规模预计环比三季度增长25.48%,11月EBITDA 0.8亿元...
-
7
摘要:本文整理自作业帮实时计算负责人张迎在 Flink Forward Asia 2021 的分享。在作业帮实时计算演进过程中,Flink 起到了重要的作用,特别是借助于 FlinkSQL 极大的提高了实时任务的开发效率。这篇文章主要分享 FlinkSQL 在作业帮的使用情况、实...
-
6
基于用户旅程分析提升企业商品销售过程用户体验...
-
9
注册英国亚马逊卖家为什么要注册英国商标,对商品销售有什么作用 ...
-
11
基于云原生的Flink计算平台实践 作者:移动Labs 2022-08-21 07:25:09 最近这几年,大数据领域比如Flink,Spark等计算引擎也纷纷表示对k8s的支持,使得大数据应用从传统的yarn时代转变为云原生时代。本文以Flink和k...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK