

基于PPYOLOv2的⽆⼈柜商品识别模型(复现) - 第六届信也科技杯图像算法⼤赛 - 胡椒的...
source link: https://junyaohu.github.io/2022/09/12/paddle-GoodsDetection-PPYOLOv2-demo/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

参考资料
paddlex
🤗 PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
🏭 PaddleX 经过质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
PP-YOLO系列
ppyolo
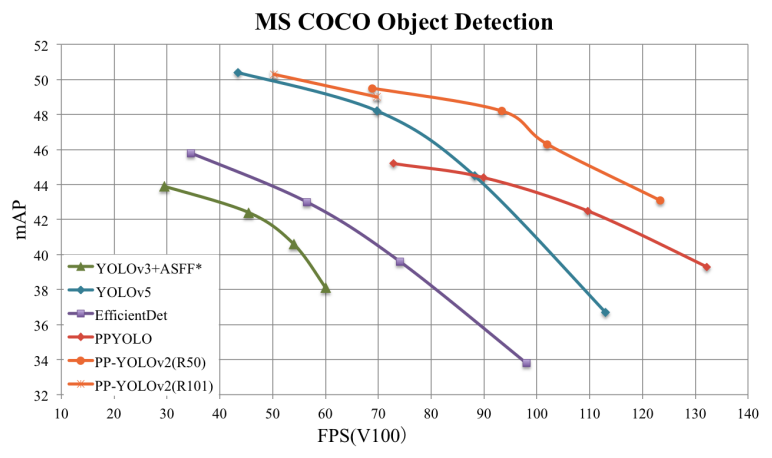
效率:45.2% mAP,速度高达72.9 FPS!FPS和mAP均超越YOLOv4,FPS也远超过EfficientDet!
-
yolov4,5模型是基于yolo3算法改进得来。但PPYOLO并不像yolov4探究各种复杂的backbone和数据增广手段,也不是靠nas暴力搜索得到一个结构。我们在resnet骨干网络系列,数据增广仅靠mixup的条件下,通过合理的tricks组合,不断提升模型性能。
Anchor-based的方法依旧是OD的主流,它的核心在于提出了一个预定义的用于边界回归的框,这个框可以作为一个先验信息辅助回归。它主体包含了两个分支:一个是单阶段的,一个是两阶段的。除此之外,近些年来的Anchor-free的方法越来越受到欢迎,但实际上Anchor-free是一个很早就有的概念,例如YOLO1,DenseBox之类的。它也可以被分成两个不同的分支,基于Anchor-point的方法以及基于Keypoint的方法。
YOLO系列的内容在工业界被广泛使用,截止至这篇论文完成之时,更新到YOLO4。YOLO4提到了巨量的tricks分成bag of freebies和bag of specials分别用于训练阶段和测试阶段。PPYOLO则是在YOLO3的基础上加了一些tricks。
-
一个单阶段的Anchor based的检测模型通常是由一个骨架网络一个neck(通常是FPN),以及一个head(用于分类+定位)组成。PP-YOLO选择了ResNet50-vd-dcn作为骨架网络。
BackBone骨干网络
yolov3使用的是较为大型的darknet53,考虑到resnet更广泛的应用以及多样化的分支,我们选用ResNet50-vd作为整个架构,并将部分卷积层替换成可变形卷积,适当增加了网络复杂度。由于DCN会带来额外的推理时间,我们仅仅在最后一层的3x3卷积替换成DCN卷积
DetectionNeck
这里依然采取的是FPN特征金字塔结构做一个特征融合,类似Yolo3,我们选取最后三个卷积层C3, C4, C5,然后经过FPN结构,将高层级语义信息和低层级信息进行融合。由于FPN我们接触的比较多了这里就不展开讲了
DetectionHead
原始yolo3的检测头是一个非常简单的结构,通过3x3卷积并最后用1x1卷积调整到自己所需要的通道数目。输出通道数为3(K+5),3代表每个层设定的三种尺寸的锚框,K代表类别数目,5又可以分成4+1,分别是目标框的4个参数,以及1个参数来判断框里是否有物体*。
ppyolov3
PP-YOLOv2从飞桨明星检测模型PP-YOLO出发,通过增量消融方式逐步添加有助于精度提升且不增加推理耗时的模块达到进一步提升性能的目的。PPYOLOv2(R50)COCO test数据集mAP从45.9%达到了49.5%,相较v1提升了3.6个百分点,FP32 FPS高达68.9FPS,FP16 FPS高达106.5FPS,超越了YOLOv4甚至YOLOv5!而如果使用RestNet101作为骨架网络,PPYOLOv2(R101)的mAP更高达50.3%,并且比同等精度下的YOLOv5x快15.9%!
智能零售柜商品识别是第六届信也科技杯图像算法大赛的一个项目。该项目可以使得计算机精准地对顾客购买的商品进行智能化、自动化的价格结算。当顾客将自己选购的商品放置在制定区域的时候,一个理想的智能零售结算系统应当能够精准地识别每一个商品,并且能够返回完整地购物清单及顾客应付的实际商品总价格。
项目拟使用的方法: 借鉴原有项目,在使用PaddleX进行模型训练的过程中,检测模型使用PPYolov2。骨干网络采用ResNet50_vd_dcn。数据集总数据量为5422张,共有113类商品,属于多分类问题。
- 本数据集采用VOC格式,符合大多深度学习开发套件对数据集格式的要求,可满足paddlex或PaddleDetection的训练要求。本数据集总数据量为5422张,且所有图片均已标注,共有113类商品。本数据集以对数据集进行划分,其中训练集3796张、验证集1084张、测试集542张。
- 数据和模型来源:第六届信也科技杯图像算法大赛,@Thomas-yanxin
- 归类领域:目标检测
- 保存格式:数据集分为训练数据集、训练商品库。训练数据集包含图片数据及标注信息。图片数据集为密集商品图片,尺寸960x720,格式为jpg。
data/data91732/
├── Annotations(标记)
├── JPEGImages(图片)
├── labels.txt(商品类别,113)
├── test_list.txt(测试集,3796)
├── train_list.txt(训练集,542)
├── val_list.txt(验证集,1084)
└── VOC.zip
- 样本数量:训练集3796张、验证集1084张、测试集542张。
- 类别:113类商品
Recommend
-
57
-
22
AI平台的初衷永远是提高开发效率,加快算法迭代周期。通过产品化AI技术,让运营人员能够更贴近技术,更好地指导赋能业务场景,给客户带来更好的技术体验和产品体验。
-
11
奇安信Ateam文章地址: XXE to 域控 概述 本文...
-
19
基于三维模型的目标识别和分割在杂乱的场景中的应用 Original...
-
10
经典论文复现 | 基于标注策略的实体和关系联合抽取 - 飞桨PaddlePaddle的个人空间 - OSCHINA - 中文开源技术交流社区过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“...
-
5
撰文 | 成诚 2020 年,最轰动的 AI 新闻莫过于 OpenAI 发布的 GPT-3 了。它的1750亿参数量及其在众多NLP任务上超过人类的出众表现让大家坚信:大模型才是未来。但与之带来的问题是,训练超大模型所需的算力、存储已不再是单机就能搞定的了(之前的...
-
23
模型难复现不一定是作者的错,研究发现模型架构要背锅丨CVPR 2022
-
4
实体识别(4) -基于Bert进行商品标题实体识别[很详细] ...
-
3
[TOC] 我们常说的IO,指的是文件的输入和输出。在操作系统层面,IO就是:将文件从磁盘中通过内核空间,将文件拷贝到用户空间里面,涉及三个位置:磁盘、内核空间、用户空间。本...
-
6
GitHub开源130+Stars:手把手教你复现基于PPYOLO系列的目标检测算法-51CTO.COM
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK