

人工智能请创作:“一颗柠檬戴着墨镜在沙滩上休息”
source link: https://www.woshipm.com/ai/5646329.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
人工智能请创作:“一颗柠檬戴着墨镜在沙滩上休息”
在预想中,我们以为AI图像的生成界面是一个简洁的提示词输入框加上图像生成页,然而Midjourney创新性地加入了“群聊”机制,本篇文章就来和大家聊聊Midjourney的使用体验以及AI绘画与人类创作之间的关系,感兴趣的朋友一起来看看吧。

让我们聊聊最近大热的人工智能(AI)艺术创作。
在艾厂的人工智能国际论坛进行的五月底(以至后来的六月),还发生着另外一件颇相关的重要事件——两款主要的人工智能图像生成软件,DALL·E·2和Midjourney,都开始开放测试版的内部邀请。
沙丘的成员也获得了Midjourney的邀请,进入了测试版的discord社群,得以观察到无数图像的生成、筛选与调校,也尝试了自己输入的提示词(prompt)以生成AI图像。
在预想当中,我们以为AI图像的生成界面是一个简洁的提示词输入框加上图像生成页——类似于谷歌图片搜索页面,只是“搜索结果”换成了“生成成果”。
然而实际情况却是,所有Midjourney受邀的测试新人都将加入一个discord社群,这个大社群下又进一步细分出五十个“新人群”。当新人加入的时候,Midjourney的机器人(bot)将会首先自动在“通告群”中发出消息,指定某某新人到第XX号新人群中。
在这一“群聊”的机制中,用户将以适当格式输入提示词——譬如“一颗柠檬戴着墨镜,躺在沙滩上休息,摄影级真实风格”,而机器人将在约一分钟后,在群聊界面里回复依照提示词生成的四张AI图像,并在新消息中提及(@)新人。值得注意的是,这意味着所有用户要求的图像——不管是输入的提示词,还是生成出来的图像,都将对所有人可见。
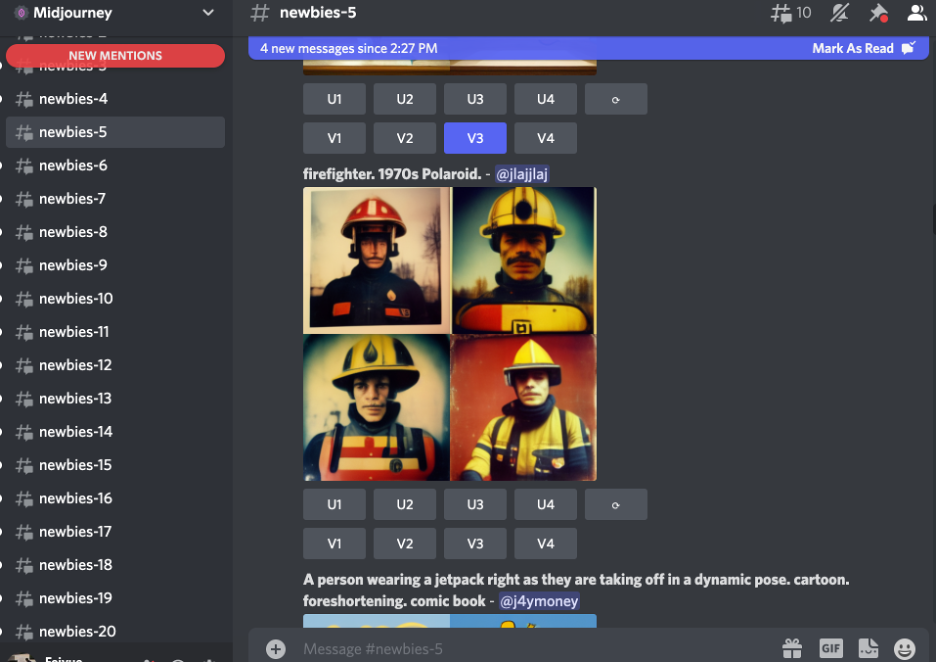
Midjourney的Discord社群的截图。左侧是新人群的不同频道,右侧展示的图像的提示词是“消防员,1970年代拍立得风格”,图像下方的U1代表放大(upscale)第一张图,VI代表对第一张图做出进一步变种(variation),以此类推。
图源:作者。
在这个基础上,用户可以进一步对得到的四张图像做挑选,要求对其中的某一个或某几个做出其他变种(variation),或者放大尺寸、增加分辨率(upscale)。有趣的是,正因为这些所有步骤都处在一个群聊的界面当中,所有用户都可以对其他用户要求的图像做挑选,而机器人会把这些要求一一回应,发布在群聊当中。
我们对Midjourney团队选择的这样的交互/组织形式非常感兴趣。不得不承认,五十个接连不断滚动着新消息的群组十分有冲击力,庞大的信息量和不断增大的积累速率注定没有任何单个的人类大脑能跟得上——这样的机制一开始也让新人有些晕头转向。
但适应以后,我们也大概体会到这种形式的妙处——我们仿佛置身于一个巨大的实验性公共艺术项目当中,这是单点的、以个体用户为中心的界面(譬如谷歌图片的搜索框)所不能比拟的。

同样的提示词:“一颗柠檬戴着墨镜,躺在沙滩上休息,摄影级真实风格。”左侧是Midjourney的生成图像,右侧是DALL·E·2的。
图源:MattVideoProductions。
首先,这种像洪水或雪球一样不断向人滚来和涌来的图像量,或许也正是人工智能艺术想要向我们传达的一个重要特征——没有哪个人类艺术家或者人类艺术家团队,能够如此大量和快速地响应“客户”的要求,并不断产出不同变种,再进一步修改并放大,二十四小时无休无止。
其次,这种群聊的机制也让输入者、观看者和AI机器人的身份变得史无前例地平等,并且边界模糊。这里没有作者和观众的二元对立,署名权也似乎无从说起——一张惊艳的图究竟是谁的作品?是最起初的提示词输入者吗?是AI机器人吗?是Midjourney团队的算法工程师吗?是中途帮忙选择变种或者要求增大尺寸的其他用户吗?这是多方协作、去中心化的过程。
第三,每个用户不断看到其他用户的提示词,也不断看到新的AI生成图,也构成了一个不断向其他人学习怎样更好地、更有创意地输入提示词的研讨会式的场所。另外,当看到其他人要求的图像出现,并从中筛选,本质上也是在帮Midjourney团队义务训练他们的算法。
这些也引出了人类艺术家时期不曾有过的问题,在AI创作的往复沟通中,究竟谁是真正的受益者?架构者、输入者、筛选者、观众、机器之间,究竟谁在训练谁,谁又在向谁学习?

提示词:“一个日本女人坐在榻榻米上,摄影级真实风格。”Midjourney的生成图像。
图源:作者。
事实上,这些问题在艾厂的2022艺术与人工智能国际论坛当中也多有提及。我们认为这是一个很好的机会和时间节点,写下我们自己的想法。
艾厂的论坛以“人工想象力”为主题,由来自艺术、设计、文学、计算机科学和哲学领域的嘉宾对这一话题进行分享和探讨(关于论坛具体信息,点击这里跳转)。沙丘研究所也受邀作为特别观察员参与。不过,就像是上述罗列的那样,我们对此并没有宣言式的观点,而是更想要用问题的形式分享一些我们正在思考的东西。
在尝试了AI图像的内测之后,沙丘的成员以及我们在Media Lab的朋友都由衷发出这样的感叹:这样的技术革命对于图像和创作的影响,或许不会小于一百年前摄影技术对于绘画的冲击。正如本雅明在他著名的作品《机械复制时代的艺术作品》的开头引用了保罗·瓦莱里:
世界正发展着的伟大的技术革新会改变艺术的全部表达技巧,由此必将影响到艺术创作本身,最终或许还会导致以最迷人的方式,改变艺术概念本身。
对于本雅明来说,当时兴起的电影使艺术不再是脱离大众的收藏品,因为其本质本来就是大众的。而如今人工智能艺术平台似乎让每个人都成为了创作者。
另一方面,对图像的重新定义似乎还将进一步重塑我们与世界的本质关系,毕竟视觉是人类感知世界的(最)主要渠道。正如电影中“摄像机”的位置为观者创造了一种全新的观察和共情的方式,人工智能艺术中的人工智能似乎也为我们提供了一种不同于人类创作的思考方式。
一、想象力和创造力是人类独有的吗?
对于很多人来说,“人工”和“想象力”两个词注定是一组矛盾;“人工想象力”也根本就无法存在,没有比较和讨论的余地。“人工”一词指向“人造的”和“人造物(artifacts)”而与之相对,想象力似乎是人与生俱来的,是“自然的”而非被“制造”出来的。
另外,想象力还通常被认为是人类独有的能力,它将我们与其他非人的“物”区分开来——不论是自然中的动植物,有机物和无机物,还是如工具和机器这样多样的人造物。
这种主导性的观点尤其被人类中心主义所推崇,因为人们通过这种独特的创造力获得了主体性。在文艺复兴时期和英雄式的现代主义中,我们都可以看到许多“单独存在的天才(standalone genius)”。
这些艺术家、建筑师、作家广为人知,天才的光环让他们区别于他们创作和生活中的协作者,他们的创作力是神秘的(或可以说是神圣的)——后人研究他们的生平、作品、创作过程和手法,但是他们的想象力和创造力则是先验或超验的,这样的能力宛如神降,仅属自身;这个神秘无穷的黑箱,他人无法刺透,更无法复制。也因这一点,这些天才的创作者作为个体,与同时代的其他人分离了出来,像是”单独存在“的。

提示词:“一只狐猴处在星丛图当中”Midjourney的生成图像。
图源:作者。
然而,不论是以物为导向的存在论(Object-Oriented Ontology),还是后人类主义的艺术、设计、文学实践和哲学研究,都挑战着这种人类中心主义的观点。在论坛中,嘉宾们也从不同方面就这一观念进行了批判和思考。
譬如在许煜的分享中,他通过解读康德,强调“想象”本身就具有“人工”的成分,因为图像形成(image formation)的过程总需要涉及“符号”等人工系统;而乔安娜·泽林斯卡也引用后人类主义学者克莱尔·科尔布鲁克的观点,批判将人类作为唯一的艺术创造者的想法。
这一问题不仅是理解人工想象力的核心,也进一步成为对于人类想象力的反思。乔安娜·泽林斯卡在分享中展示了日本设计师菅野索和山口隆广设计的“无意义的绘画机器人(Senseless Drawing Bot)”所绘制的图像——这些图像既像是孩子的涂鸦,又和杰克逊·波洛克和塞·托姆布雷的艺术有着高度相似的特质。
对于乔安娜·泽林斯卡来说,与其将这一作品看作是对于人类涂鸦的一种模仿,它或许可以被理解为一种对于人类创造性为的重新思考——或许人类的创造力也并非来自人的理智和主体能动性。这些都使得“想象力是自然的而非人工制造的”这一命题变得不再稳定。

菅野索和山口隆广设计的“无意义的绘画机器人(Senseless Drawing Bot)”。
图源:Yohei Yamakami 2011。

塞·托姆布雷“酒神” 系列(2005),艺术评论家阿瑟•丹托(Arthur Danto)称这些画为“酒神式狂欢之作”,只有神才能达到如此酣醉之境。
图源:Rob McKeever/Gagosian Gallery。
二、署名权与自主性归属于谁?
如今,数字素养(digital literacy)几乎成为了新一代人类的必备。AI所生产的机械的、数字复制的图像材料,也给当今几乎耗尽了创造可能性的人类艺术家们提供了新的刺激和原材料。人工想象力既是自主的(autonomous),又是无处不在的(ubiquitous),它的美学令人目眩神迷。
但开发者和艺术家们显然并不止步于将AI艺术视作一个可以不断扩展壮大的灵感库。我们也好奇,如果想象力并非人类独有的,那么人工智能是否能独立进行创作呢?在论坛中,我们看到多位艺术家、设计师分享人工智能作为共同进行创作者产生的作品,但一个仅由人工完成的艺术作品会是什么样的呢?

提示词:“美国郊区住宅,1960年代拼贴广告风。”MIdjourney生成的图像。
图源:作者。
这显然还很困难。人工智能来自于人,现有人工智能的想象与创造也全程由人类像父母呵护一般陪伴着全程。其中最让人工“署名权”成为问题的,在于首先,机器算法学习和训练的库仍由人来指定,而产出物亦由人来最后筛选。它仍需要人类的“处理”,才能被人类的双眼“消化”。
论坛上,刘宇昆讲述,他尝试利用AI学习自己的写作去创作新文本,却发现成果并不惊艳,甚至难以被借用。他只好大幅修改,加入很多自己的段落,最终发表了《五十件与人类合作的AI应该知道的事》(“50 Things Every AI Working with Humans Should Know”)。
同理,算法通过分析推荐而产生的审美,直白且相似度高,有时又很跳脱。即便如此,不少设计师有意识地去收集这些图像,编辑整合成新的图集,作为自己创作的情绪板(moodboard)。
除开我们在文章一开头提到的图像的生产,AI也可以进一步处理已有的图像,在某种风格内进行新的创作。它把图像创作者的风格变为一种滤镜,加在其他图像上。例如在AI艺术网站Dream中输入图像内容,选择“吉卜力风格”,新生成的图像就展现出相似的奇幻动画风格,而转换成超现实主义风格,则会出现类似于达利画作的图像。

左侧:输入提示词“沙丘,吉卜力风格”后的结果;右侧:输入提示词“沙丘,超现实风格”后的结果。
图源:作者。
用户提供命题,而AI作为产出者,生产了新的图像。抑或是用户提供内容,而AI把它放进别人风格的框架里,生产新的图像。那么AI在这个产出过程里的身份是作者还是工具?究竟谁才是这次创作的主语?AI,AI开发者,用户,还是艺术家本人?
这不妨也诱使我们进一步想象:如果没有人对于人工智能进行训练、或对产出物进行筛选,也不仅考虑用AI处理已有的图像,它是否还能够产生某种更为“自主”的作品?
这样的作品或许指向了一种更加不可知的想象力,成果或许也超出了人类的理解和欣赏范围。菲利普•迪克的《仿生人会梦见电子羊吗?》和莱姆的《索拉里斯星》(点击这里跳转)为我们提供了这样的范式:对不可想象之物的想象。
三、人工智能的量产是创作吗?
通过分析搜索到的大量图像数据,AI提取其中已有的艺术风格、物体形状、人物特征并进行整合和产出,全新的图像作品便诞生了。
在我们加入的AI图像内测社群里,新的提示词和新的图像不断产生、受挑选并且迭代、发展,这使我们产生了一种强烈的感觉——与其说这是一种“制作(production)”,毋宁说它是一种伴随着无数变异和选择过程的“繁殖(reproduction)”。
这些图像也模拟出一些现实世界中本不存在的创造物的形象。譬如我们可以在DALL-E、Midjourney或者其他AI图像生成软件中,叠加“扎哈·哈迪德”与“巴黎世家”(zaha hadid + balenciaga)这样各自风格强烈的建筑师和时尚品牌,从而获得一系列既有廓形剪裁,又具有光滑曲度的服装——一个将二者基因强势结合的奇异图像。
这样九张或四张全新图像所构成的“图集(atlas)”恰好使它稳定地建立了一种新的创作话语权,就好像世界上真的有这么一位混血设计师一样。
同理,我们可以混血食物和工具,建筑和艺术,绘画和摄影等等不同领域的词条,创造新的“人造物(artifacts)”。电子时代的图像现实,开始脱离我们的物理现实,自由繁衍。这些无限自主繁衍的新的图像,是人工智能创作的“作品”吗?
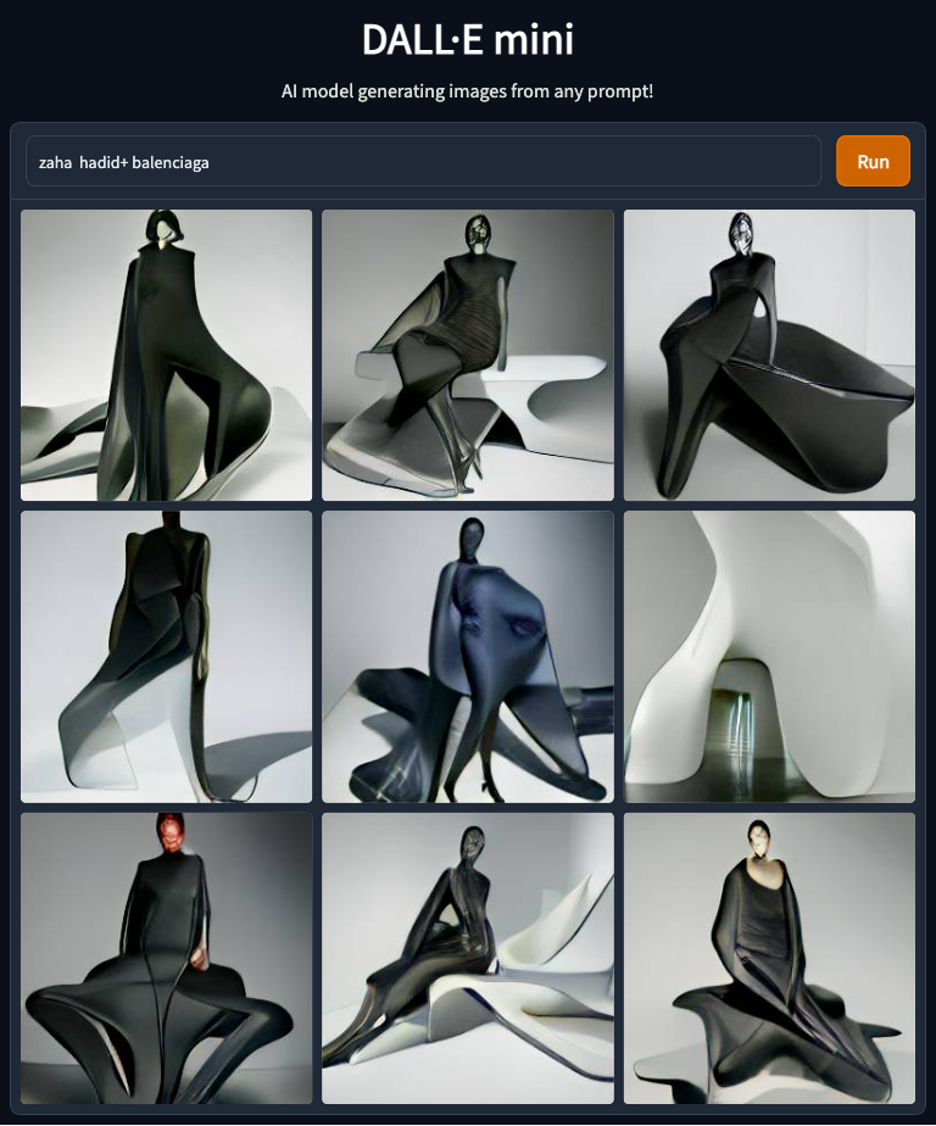
在DALL-E mini中使用“扎哈·哈迪德”与“巴黎世家”产生的九张图像。
来源:huggingface。
确实,从我们传统的对艺术的理解来说,这种创作很容易被视为”再生产(reproduction)”。你可以说,它只是建立在可考的图像基础上,在已经树立强烈风格的作品中,进行了一番重塑和拼贴。
如果我们相信创作的出发点是想象力,是人类创作艺术的初心和本能,那当AI回收利用了一些已有的艺术作品,这种再生产也算是新的想象力吗?这是否只是一种对我们想象力的映射?而在这个问题的反面,如果我们认为AI所做的不是新的,我们又如何辩驳人类的想象物就是新的,而不是多种已有元素的再组合?04人工智能更擅长图像处理而非文字处理吗?
AI创作也许就像是人类创作的镜子,它的创作生命力具有危险的吸引力。
这个镜子上常常还有另一个重要的东西——滤镜。事实上,“Filter”既有过滤器也有滤镜的意思,这两者对AI艺术来说都尤为关键。
在摄影技术当中,我们熟知滤镜的使用——前期阶段,摄影师可以把不同色泽与反射度的偏振镜加在镜头前面,保证作品的光线效果符合预期;后期阶段,摄影师还可以通过诸如Lightroom这样的处理软件,为原片赋予更多不同风格的数字滤镜,诸如强调紫色和黄色的“赛博朋克风”或者降低饱和度且偏黄的“复古风”。

利用AI技术将图像转为夜景效果的滤镜。
图源:Cyanapse’s Photorealistic Image Filters。

电影 Delete My Photos,导演Dmitry Nikiforov使用了图像编辑器Prisma。
图源:Delete My Photos。
通过添加“滤镜”,图像产生了强烈的气氛或感情,它很多时候也是让某一摄影师营造出个人风格,并迅速产生大众辨识度的关键元素。可以说,滤镜的添加已经改变了摄影师的创作方式。不过,在传统的滤镜(再)创作中,风格所带来的氛围和情绪很少可以独立于作品的内容存在,它像是一个主体之外锦上添花的附加物。
这引导我们思考图像滤镜与文本风格的关系。一方面,艺术滤镜在图像前后期处理中已经非常常见。AI对已有图像进行滤镜处理也已经达到了相当成熟的程度——不只是明暗、白平衡和色彩的调整,AI可以对图像当中抽象的线条进行修改,对人和物的形态、笔触的使用都进行再组织。但另一方面,在文本当中似乎还很难运用滤镜。
刘宇昆在分享中也提到,文本似乎很难通过人工智能生成和添加某种“风格滤镜”。或许现有的互联网生态已经完全由图像作为主导,所以对文本的处理不再是资本最青睐的领域,但在此处,我们同样好奇图像与文本之间风格化的内生差异。
就像是图像有“吉卜力风”、“赛博朋克风”、“复古风”这样的说法,不同作家的文本和叙事显然也有其强烈的美学风格。譬如我们会说“莎士比亚式的(Shakespearean)”、“卡夫卡式的(kafkaesque)”或“奥威尔式的(Orwellian)”,但相比于热闹的图像滤镜市场,为某段文本添加风格的AI处理仍然非常少见。
我们或许可以做一些猜想:对于AI开发来说,相比于图像处理当中图像和滤镜的清楚叠加关系,文本的风格似乎不只是文本本身的附加物,而是本身就溶解在文本当中,无法简单剥离出来。卡夫卡式的风格并不完全因为作者喜好用某种特定的词语搭配,或者偏爱某种方言化的表达,而可以说,他营造出的那个世界,以及建立在其叙事上的人物的总体处境,构成了他那种独一无二的风格。
相似地,奥威尔式的风格也不在于其遣词造句的特殊性,而在于他对某种极权主义体制的理解和描摹。如果AI要通过大量学习这样的文本,提取出“卡夫卡式的”或者“奥威尔式的”滤镜,可以方便地将之套用在用户给定的任意文本上,或许困难就在于,如何避免这样的处理停留在肤浅的字句模仿上而显得蹩脚。
但文学也并不是AI创作并未涉足的处女地。在文本当中,诗歌已经是相对成功使用AI和算法的创作。
比较来看,虚构和非虚构的创作都要求作者把剧情或者思考缝合成一个可读的、前后有理的整体,但诗歌似乎可以免去AI对这一步骤的努力。通过拆解和重组一些词句,许多AI创作的诗歌会结合并不常见也并不常常并置在一起的意象,而其中的跳跃空间再度交还给人类阅读者的想象力来完成。这反而能够给人类作者带来别样的启发。
不过,诗歌可能是在文字创作中更接近图像创作方式的一个媒介。我们仍然好奇AI将如何在文学领域中迈进:它是否能够像借助图像重塑我们看世界的方式一样,借助文字重塑我们讲述的方式?通过深度学习,AI是否能改善元素之间链条式的序列感,在讲故事的方面,拥有“莎士比亚式的(Shakespearean)”、“卡夫卡式的(kafkaesque)”或“奥威尔式的(Orwellian)”这样的滤镜?如果说AI毕竟更善于处理图像,那么电影、卡通、漫画或者图像小说的叙事是否会首先由AI掌握?
关于文字和图像之间的关系,另一个值得思索的问题是我们开始创作的方式——我们介绍的几个主要的AI图像生成模型,仍然往往由一段人类输入的文字形式的提示词(prompt)开始,再由AI转换为图像。而这是否是一个最佳的,或者说最符合人性的方式?
我们知道,人类的图像创作很多时候是从一个简单的形态、一种模糊的感觉或者某个记忆中的行为片段开始的,它甚至无法形成清楚的文字描述,但画家、导演等的图像创造,正就从这种奇妙的朦胧中开始了。
前文提到的塞·托姆布雷的作品就常给人带来一种下意识随手涂抹的感觉,他创作的开端接近一种先于语言甚至完整图像的自然的行为。现在的AI图像生成模型仍然把文字作为开端,这似乎也会为日后的艺术创作建构新的主流方式——但这只是一种理解,且非常工程师式的理解,而我们会否因此丧失对某种别样的想象力的想象?
当然,目前也有通过绘制草图来生成图像的AI软件,然而我们更为好奇的是,基于文字和图像的更多元创作方式所能带来的新的作品。
作者:张一然、李雅伦、陈飞樾;公众号:沙丘研究所
本文由 @沙丘研究所 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Pexels,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK