

Python 和 Node.js 实现 Minecraft 聊天记录导出和检索程序
source link: https://i-moe.eu.org/index.html?type=article&filename=minecraft-chat.md
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Python 和 Node.js 实现 Minecraft 聊天记录导出和检索程序
Python 和 Node.js 实现 Minecraft 聊天记录导出和检索程序
标签 技术向
在 Minecraft 中聊天是一件趣事,然而过往的聊天记录,却无法简单地回顾。
我们怎样才能找回过往在 Minecraft 中留下的点点滴滴的回忆呢?
本文中,导出的聊天记录是临时所用的中间格式。
只有在通过本文第二部分的检索程序实现才能够从导出的聊天记录中检索消息。
本文中的数据检索相关功能主要是由 欠陥電気 𝑹𝒂𝒅𝒊𝒐𝑵𝒐𝒊𝒔𝒆 开发和完善。
- Minecraft 客户端日志
- Node.js
- Python 3
小提示:Minecraft 日志存放于
.minecraft/logs(若开启版本隔离,则是.minecraft/<版本>/logs)
简单分析日志格式
随便打开任何一个带有聊天记录的日志,定位到日志中带有聊天记录的行:
[20:00:00] [INFO]: <baiyuanneko> hi
容易发现格式如下:
[当天时间(不包含当天日期)] [无关信息][]: <消息发送者> 消息内容
我们下一步要进行的是聊天日志的导出,因此必要的信息是消息发送时间、发送者和消息内容。
只考虑这一行聊天记录:
- 消息发送者通过正则表达式匹配尖括号可以得到
- 消息发送时间通过正则表达式匹配第一个方括号可以得到,但是只是当天内的时间却不包含当天日期,不过容易发现当天日期可以通过读取日志的文件名变相获取。
- 消息内容的获取方式很多,可以将方括号、尖括号、冒号全部去除,剩下的就是具体内容;也可以读取尖括号之后的内容来得到消息内容。
最后我们只剩下需要解决的问题就是:
- 显然,日志中不是每一行都包含聊天记录,那么如何过滤只得到聊天记录行?
这个问题比想象中简单,因为经过大量观察和实验可以发现,只要一行中包含尖括号(即通过正则表达式匹配到了尖括号),我们基本可以断言这一行就是包含聊天记录的行。
小提示:实际上还有一个例外,就是有时命令的帮助文本中也会出现尖括号,不过一方面,命令的帮助文本的出现概率通常远小于聊天记录的内容数量,从而你可以事后或在处理过程中手动筛选,如果你去做了就会发现,这个工作量肯定会比你想象中小很多,另一方面本身你会发现很难简单地判断出聊天记录行和帮助文本行的区别。所以手动筛选应该已经是比较好的解决方案(如果你有更好的,欢迎告诉我,我会更正)。
开始实现聊天记录导出
本部分的代码使用 Node.js 完成。
简单的步骤分解
- 遍历一个文件夹(假设为
source文件夹)中的所有日志文件(此处可以使用fs.readdirsync()实现) - 逐一对每个日志文件逐行地读取(如果日志放在压缩包中,则先解压)(此处使用
fs.readFileSync()结合正则表达式/\r?\n/匹配得到包含每一行的内容的数组) - 若某一行包含尖括号,则判定为聊天日志行(把帮助日志筛选出去的步骤可以加在这里)(附:判断尖括号的正则表达式是
/\<(.+?)\>/) - 对于聊天日志行,使用正则表达式匹配尖括号,获取消息发送者;使用正则表达式匹配第一个方括号,获取消息当天发送时间,然后结合当前日志的文件名获取当天日期,组合后使用
new Date()获取具体时间对象,最后使用Date.parse()获取完整的消息发送的时间戳。最后将行中的方括号、尖括号、冒号全部去除,得到聊天的具体内容。最后组合成一个 JSON 对象大致如下:
{
"Sender": "baiyuanneko",
"Time": 1661414501000,
"Content": "Hi"
}
- 将此对象加入到一个数组当中保存起来(可以使用数组的
push方法) - 导出到文件(可以使用
fs.writeFileSync(JSON.parse())实现)
另外还有一点要注意:部分版本的游戏日志在导出时会出现乱码情况,这是因为这些版本的日志是以 GBK 编码格式保存的,如果遇到这种情况,解决办法是先判断文件编码,然后如果判断出来是 GBK 编码,则使用iconv-lite库按照 GBK 编码对日志文件进行正确解码。
const Encoding = require("iconv-lite");
if(buffer.toString("utf-8").indexOf("�") !== -1){
return Encoding.decode(buffer,"GB18030");
}else{
return buffer.toString("utf-8");
}
版本隔离:区分不同来源的日志
因为许多情况下,每个玩家都有许多个不同的游戏版本,并且开启了版本隔离,此时游戏的日志会散落在不同的文件夹中。
因此我们需要区分不同来源的日志,此时在Sender、Time和Content字段之外,我们需要额外增加Source 字段来记录聊天消息的来源。
这里简述一种简单的解决方法。
首先,改变日志来源的文件夹的目录结构。
如果不区分不同来源的话,我们的日志来源的文件夹的目录结构如下:
source/2022-01-01-1.log
source/2022-01-01-2.log
source/2022-01-02-1.log
那么区分之后,我们的日志来源的文件夹的目录结构应该如下。(假设有两个不同来源的日志,1.12.2和1.14.4)
source/1.12.2/2022-01-01-1.log
source/1.12.2/2022-01-02-1.log
source/1.12.2/2022-01-02-2.log
source/1.14.4/2022-01-01-1.log
source/1.14.4/2022-01-02-1.log
这样在遍历日志文件这一步之前,我们先要遍历文件夹名,然后才能遍历文件夹中的日志文件,并填充Source 字段。
最终导出的格式
一个数组内包含了消息对象,消息对象由Sender、Time、Content 和 Source 字段构成。
注意这是一个临时使用的中间格式,我们还需要通过本文第二部分的检索程序实现才能够从导出的聊天记录中检索消息
[
{
"Sender": "张三",
"Time": 1661414501000,
"Content": "how are you",
"Source": "1.12.2"
},
{
"Sender": "李四",
"Time": 1661414508000,
"Content": "i'm fine, thank you, and you?",
"Source": "1.12.2"
}
]
具体实现我放在了https://github.com/baiyuanneko/Converter。
从数据导出到数据检索
特别感谢 欠陥電気 𝑹𝒂𝒅𝒊𝒐𝑵𝒐𝒊𝒔𝒆 对此章节中功能的实现!
备注:本部分的代码均使用 Python 完成。
实质上,我们在上一步中导出的聊天记录只是一种临时使用的中间格式,因此我们需要实现一个检索程序,才能从导出的聊天日志中检索消息。
- 按条件检索。可以按照消息内容是否包含特定关键词、按消息发送者筛选(可以选多个)、按消息来源筛选(可以选多个)进行消息的检索。
- 在检索到结果后,能够定位相应消息的上下文。
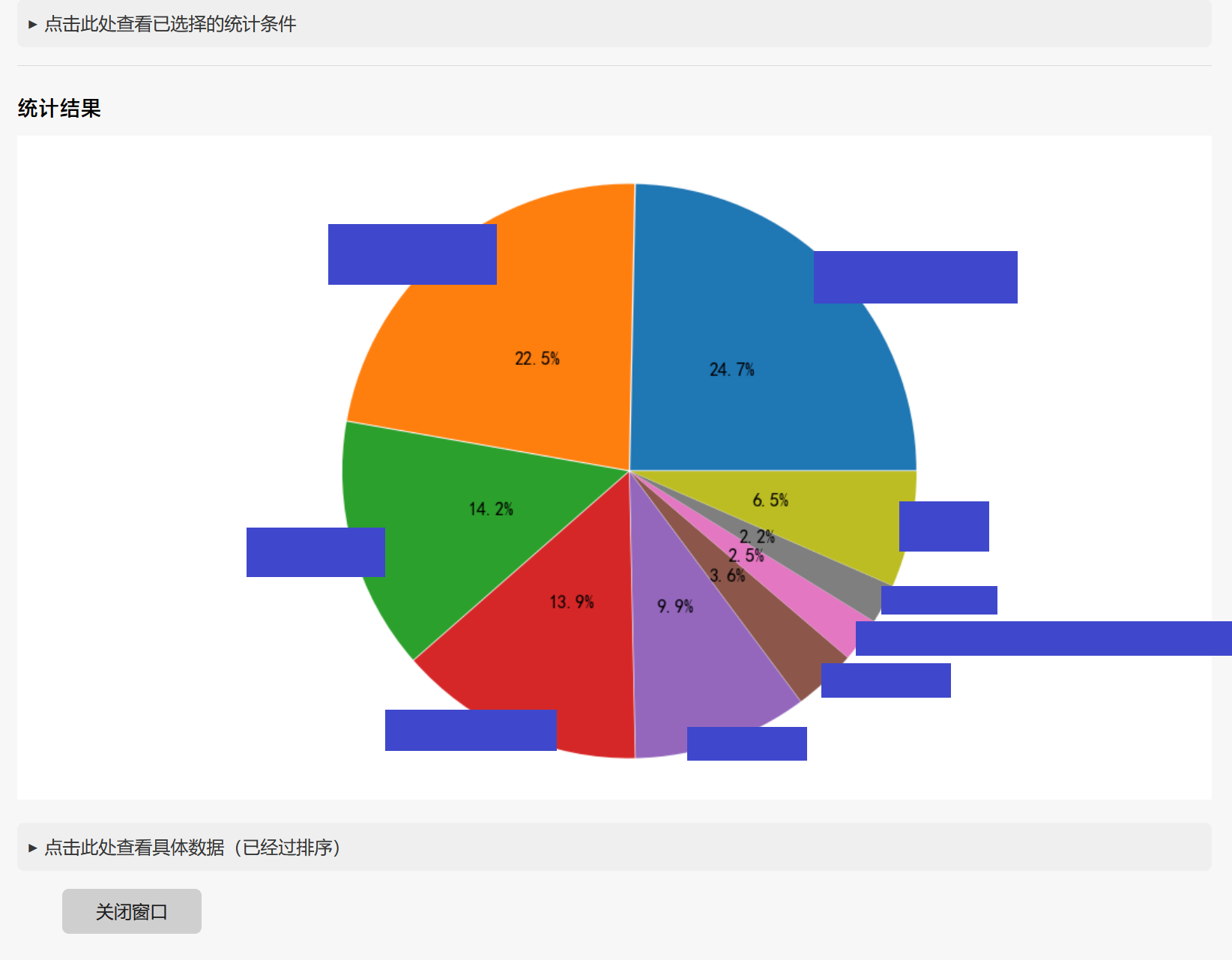
- 统计同一来源,不同发送者的占比,或者同一发送者,不同来源的占比
- 对于占比统计功能能够绘制饼图
一些功能的简单实现思路
按条件检索聊天记录
这个功能比较简单,遍历所有消息对象然后看是否满足所有筛选条件即可。
筛选条件一般有:
- 发送者名称
- 消息包含关键词
- 日期和时间范围
统计功能与饼图绘制
统计功能本身比较简单也容易理解,所以就用一个例子带过:比如统计谁发送的消息数量最多。其实就是遍历这些消息对象,统计每位发送者发送了多少条消息。
接下来主要说一说如何实现饼图绘制。这个功能是对统计功能的延伸。使用 matplotlib中的pyplot功能可以绘制饼图。
这里采用的具体的实现方法是,对pyplot.pie()采用给定sizes和labels的方式让其绘制饼图。
sizes指的是饼图中每一个部分的大小。以统计“谁发送的消息数量比较多”为例,我们可以将消息数量作为sizes传入。labels指的是饼图中每一个部分代指的内容。注意这个顺序要和传入的sizes的顺序一致。
这里注意一个问题:在发送者数量比较多的情况下,我们不可能把每一个发送者的占比全都完整的显示在饼图上,根据我自己的经验,一般来说能完整显示的是8个人,之后的发送者合并在第9个(即“其它”)栏目中。而根据常识,我们完整显示在饼图上的那几个发送者要是发言排名最前的几名发送者而不是随便的几个发送者,所以在绘制前应当记得先对数据进行排序,并将之后的发送者的数据进行合并。
定位上下文功能
第一步:获取被定位上下文的消息是哪一条消息。
因为目前我们没有为每个消息分配不同的唯一 ID,因此我们想要得知被定位上下文的消息是哪一条消息,可以通过与给定的消息的所有参数进行比对来进行。
这里我们假设不会出现消息发送者、消息内容、消息发送时间和消息来源完全一致的消息对象(事实上也不太可能,除非导出时本身就出现了消息重复)。因此,我们接受消息发送者、消息内容、消息发送时间和消息来源作为参数,这就是一条消息的全部参数。遍历所有消息对象,并找到这些参数完全相同的消息,我们一般就认为这条消息就是被查看上下文的那条消息。
第二步:获取该消息的上下文。
找到消息在数组中的位置之后,向前向后各检索一定量的条目,最终将这些消息返回。
注意:因为导入的时候就是按照上下文的顺序导入的,所以这里对数组向前向后地检索条目一般没有顺序问题。
一些没有实现的功能
除此之外还有一些暂且没有实现的功能,比如词频统计(词云)等等。也许还可以添加一些更有创意的功能,比如现在是有一些开源的自然语言分析的 Python 库,可以对消息内容中包含的情绪进行一个分析,那么就可以了解自己在 Minecraft 中聊天的心情等等。
具体实现是在 https://github.com/MSKNET/MinecraftChatLogFilter。这是一个使用 Flask 框架的应用,按照步骤操作可以启动一个本地服务器,通过浏览器访问后可以实现聊天日志和检索、统计功能。

统计不同发送者占比
按条件检索消息
除特别声明外,本博客上的内容属于公有领域,这意味着你可以不受限制地使用和加工它们。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK