

能听懂口音的开源语音系统来了:OpenAI出品,支持99种语言,英文识别能力直逼人类
source link: https://www.qbitai.com/2022/09/38116.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
能听懂口音的开源语音系统来了:OpenAI出品,支持99种语言,英文识别能力直逼人类

最大特点是它使用的超大规模训练集:
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
逼近人类水平的语音识别系统来了?
没错,OpenAI新开源了一个名为「Whisper」的新语音识别系统,据称在英文语音识别方面拥有接近人类水平的鲁棒性和准确性!
不仅如此,对于不同口音、专业术语的识别效果也是杠杠的!
一经发布就在推特上收获4800+点赞,1000+转发。
网友们纷纷对它意料之外的强大功能表示惊讶。
不仅是英文,有人用法国诗人波德莱尔的《恶之花》进行了语音测试,得到的文本几乎与原文一致。

OpenAI联合创始人&首席科学家Ilya Sutskever就表示:
终于有一个靠谱的语音识别系统能听懂我的口音了。

前任特斯拉人工智能总监Andrej Karpathy甚至转发评论:OpenAI正处于最好的状态中。

话不多说,让我们看看这个被“好评如潮”的语音系统究竟是怎么回事。
逼近人类水平的语音识别系统
首先,Whisper最大特点是它使用的超大规模训练集:
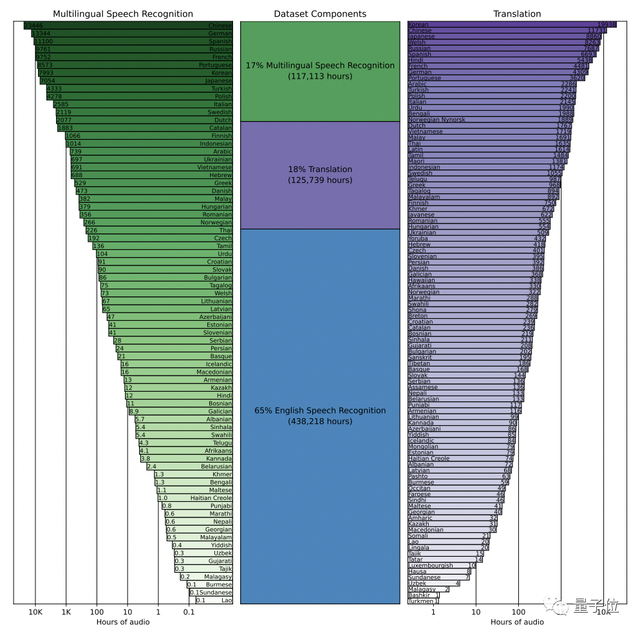
它使用从网络上收集的68万小时的多语言、多任务监督数据进行训练。
这导致数据集的内容非常多元化,涵盖了许多不同环境、不同录音设备下、不同语言的音频。
具体而言,65%(438218小时)是英语音频和匹配的英语文本,大约18%(125739小时)是非英语音频和英语文本,而最后17%(117113小时)则是非英语音频和相应的文本。
其中,非英语部分共包含98种不同语言。
不过,虽然音频质量的多样性可以帮助提高训练模型的鲁棒性,但转录文本质量的多样性并不是同样有益的。
初步检查显示,原始数据集中有大量不合格的、现有自动语音识别(ASR)系统生成的转录文本。
而以往的研究表明,在人工和机器混合生成的数据集上进行训练,会显著损害翻译系统的性能。
为了解决这个问题,研究团队开发了几种自动过滤方法来识别和删除低质量的数据源。
但值得一提的是,没有说话内容的片段会被留下,作为语音活动检测的训练数据。
其次,Whisper体系结构是一种简单的端到端方法,具体来说就是Transformer的编码器-解码器格式。
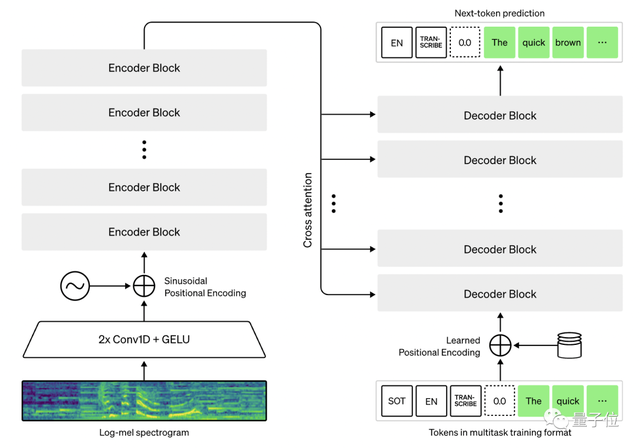
输入音频被分成30秒的片段,再转换成log-Mel谱图,然后传入编码器。
解码器被训练来预测相应的文本标题,并混合特殊标记,指示单一模型执行诸如语言识别、多语言语音转录和英语语音翻译等任务。

除此之外,研究人员还为Whisper设置了5种不同的型号,以下是各模型大致的内存需求和相对速度,使用者可以自行选择。
但需要注意的是,只有“large”型号支持多语言,前4个模型都只支持英语。

不过不需要担心,与其他模型相比,英文语音识别正是Whisper的核心竞争力。
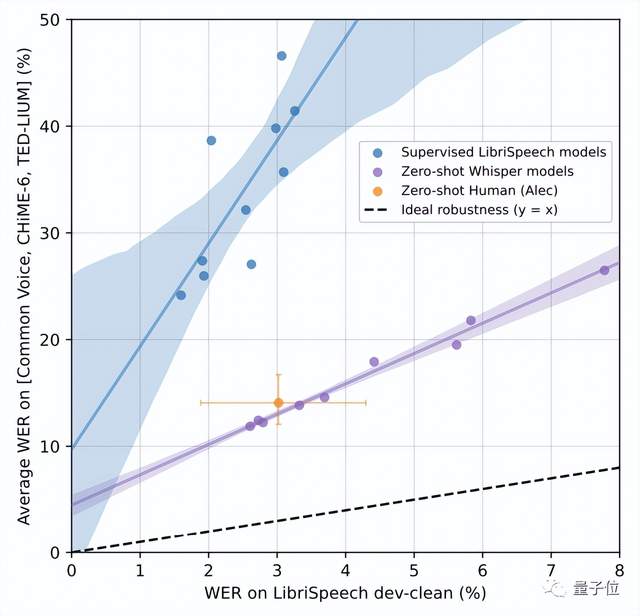
实验结果证明,Whisper在Librispeech test-clean测试的错误率达到2.7%。
虽然这一数值与Wav2vec 2.0一样,但在零样本性能上,Whisper明显更稳健,平均误差减少了55%。
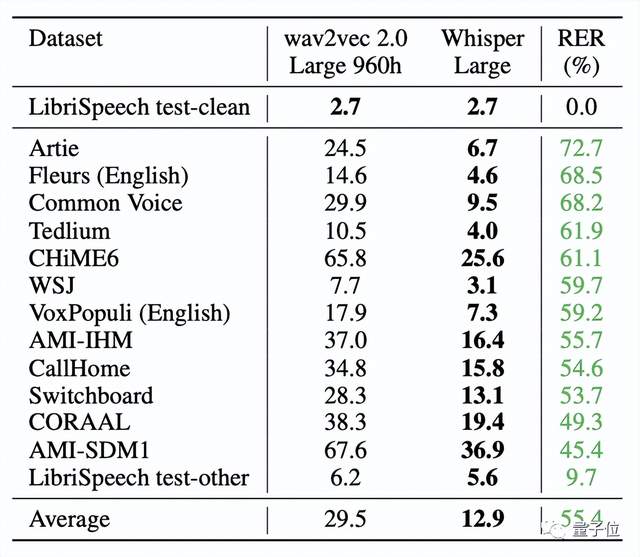
甚至零样本Whisper模型还缩小了与人类鲁棒性之间的差距。
可以看出,与人类Alec相比,LibriSpeech模型的错误率大约是人类的两倍,而Whisper模型的鲁棒性边界则包括Alec95%的置信区间。
Whisper的研究团队来自OpenAI,共同一作有两位:Alec Radford、Jong Wook Kim。

Alec Radford,OpenAI的机器学习研究员,也是indico.io的联合创始人。

Jong Wook Kim,在纽约大学获得了音乐技术专业的博士学位,研究方向包括多模态深度学习和音乐理解,目前是OpenAI的研究人员。

值得一提的是,研究团队指出,虽然目前Whisper还没有实时功能,但它的运行速度和内存大小表明,在这一基础上搭建实时语音识别和翻译功能是可行的。
他们希望Whisper的高精度和易用性,将允许开发人员将语音接口添加到更广泛的应用程序中。
论文和GitHub链接附在文末,感兴趣的小伙伴们可以自取~
论文链接:
https://cdn.openai.com/papers/whisper.pdf
GitHub链接:
https://github.com/openai/whisper#approach
参考链接:
[1]https://colab.research.google.com/github/openai/whisper/blob/master/notebooks/LibriSpeech.ipynb
[2]https://techcrunch.com/2022/09/21/openai-open-sources-whisper-a-multilingual-speech-recognition-system/?guccounter
[3]https://news.ycombinator.com/item?id=32927360
[4]https://twitter.com/alecrad
[5]https://jongwook.kim/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK