

Action Space Shaping in Deep Reinforcement Learning 阅读
source link: https://mathpretty.com/15081.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Action Space Shaping in Deep Reinforcement Learning 阅读
摘要本文是对论文《Action Space Shaping in Deep Reinforcement Learning》的解读,这篇论文主要讲解了三种动作空间预处理的方式,分别是(1)Remove Actions,(2)Discretize continuous actions,(3)Convert multi-discrete actions to discrete。通过大量实验给出了不同动作空间预处理对性能的影响。
本文会介绍三种强化学习对动作空间进行预处理的方式,主要基于论文 Action Space Shaping in Deep Reinforcement Learning。之前在视频游戏中,通常会对原始的动作空间进行修改或是减少,但是少有研究去探索不同动作预处理方式对结果带来的影响。于是在这个研究中,通过大量的研究去比较(1)Remove Actions,(2)Discretize continuous actions,(3)Convert multi-discrete actions to discrete,这三种动作变换方式对结果的影响。
Our core research question is "do these transformations support the training of reinforcement learning agents?"
动作空间类型
强化学习的动作空间类型可以分为下面几种情况。
离散动作空间(Discrete)
离散动作空间是最常用的,每个动作都可以使用一个整数表示,例如 {1, 2, 3, ..., N},表示可以从 N 个动作中选择一个。例如 agent 玩 Pong 游戏,那么每次就可以从 {left, right, down, stay} 中选择一个。
多维离散动作空间(MultiDiscrete)
多维离散动作空间(MultiDiscrete)可以看作是离散动作空间(Discrete)的延申。此时动作是一个向量,向量的每一个维度都是一个离散动作空间。实际中有很多就是这种动作空间,例如电脑键盘,向量的维度就是电脑按键的数量,而向量的每一个维度有两个值,对应键是按下还是不按下。
我们对上面电脑按键的例子进行简化,假设现在只有四个按键,分别是「上、下、左、右」。于是此时动作向量长度为 4,可以表达为 {a1, a2, a3, a4},向量的每一个元素可以有两个取值,分别是 0 和 1,0 就是表示不按下,1 就是表示按下。所以如果动作是 [1,0,1,1] 表示「上、左、右」被按下,「下」没有按下。
连续动作空间(Continuous)
动作可以在一定范围内取连续值。例如鼠标移动的方向,速度等。
实际中还可能将上面不同的动作空间结合,比如既有「离散动作」又要「连续动作」。例如同时控制键盘和鼠标,就是一个「多维离散动作空间」 和两个「连续动作空间」的组合。
动作空间的预处理
在使用强化学习来进行游戏的问题中,常用的动作空间预处理方式有下面的三种。
Remove Actions(RA)- 去除多余动作
许多游戏环境的动作空间包含了一些不必要的、甚至对任务训练有害的动作,比如,在训练 Minecraft MineRL 游戏时,动作 "sneak" 和 "backward" 这两个动作对于游戏的进程并不关键,所以常常从动作空间中被删掉(如果不删除 "backward",那么 agent 可能会在 forward 和 backward 之间切换,而没有真正对环境进行探索)。
当然,删掉一个动作并不意味着不执行这个动作,只是这个动作不必要放在算法决策的输出中。相应的,你也可以设置这个动作为 "always on",即总是执行。总结来说,就是不要总是直接使用原始自然语义的动作空间,通过恰当的分离,合并和删除,精简出最必要的动作空间。
减少动作的个数对于强化学习的 exploration 很有效,可以切实提高 sample efficiency。用原文的话来说就是。Reducing the number of actions help with exploration, as there are less actions to try, which in return improves the sample efficiency of the training。但是这个带来的问题就是需要专家经验来设计哪些动作是不需要的。However, this requires domain knowledge of the environment, and it may restrict agent's capabilities.
Discretize Continuous Actions(DC)- 连续动作离散化
有许多环境会包含连续的动作空间,我们可以通过一些方法将其转换为离散的。例如通过分箱/分桶或者自定义离散动作的方式,把一个连续动作离散化。比如,原先的动作空间是 [-1,1] 之间的连续值,可以离散化成 {-1,0,1} 这样的离散空间。例如现在要对相机进行旋转,可以旋转 [-180, 180] 之间的角度。当然也可以离散化为每次旋转一点,{-5, 5}。每次只能旋转小的角度。
部分强化学习算法只能适用于特定的动作空间(例如只能离散或连续),而我们通常认为离散动作空间的决策比较简单,所以会将动作空间一律转化为离散的。
Convert MultiDiscrete Actions to Discrete(CMD)- 多维离散空间转换为离散
通过排列组合的方式列举多维离散动作的所有可能性,从而将多维离散动作转化成离散动作,这个方法在 ViZDoom 和 Minecraft 中比较常见。
还是使用键盘的例子,现在只有四个按键,分别是「上、下、左、右」,每一个按键有「按下」和「松开」两种。那么使用多为离散空间就可以表示为 {a1, a2, a3, a4},其中每一个值取值为 {0,1}。我们可以将其转换为离散的动作,也就是列出所有的动作,一共有 2^4 种。例如:
- 动作一表示,
[0,0,0,0]; - 动作二表示,
[0,0,0,1];
但是可以很明显的看到,使用这种方法会使得动作空间很大。于是通常会结合「去除不必要的动作」,不是所有的动作都进行组合,从而可以减少转换后离散空间的大小。
这种变换的直觉动机在于:通常认为强化学习得到 a single large policy 的难度会比学习 multi small policies 的难度小得多。同时也是因为一些算法不支持多维离散空间。下面是原文的一些表达:This transformation is intuitively motivated by the assumption that it is easier to learn a single large policy than multiple small policies, as well as technical limitations of some of the algorithms.
动作空间预处理整理
下面论文里面的这张图总结了各种经典的游戏环境用到的动作变换技巧。
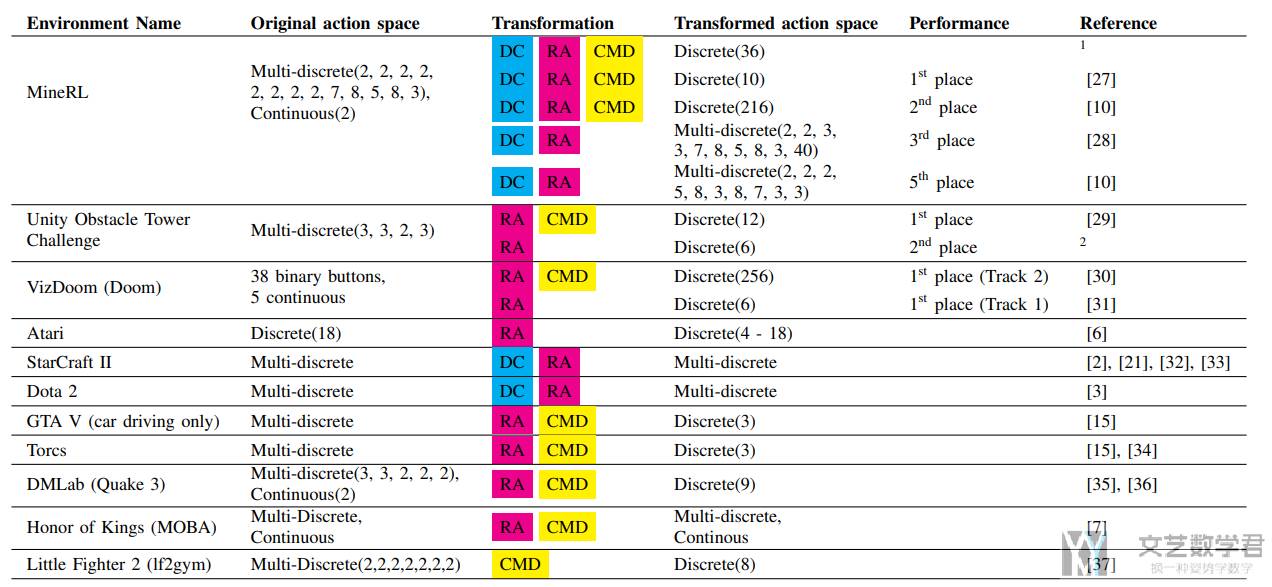
下面我们来看一下实际实验结果。We move on to testing if these transformations are truly
helpful for the learning process. 在原始论文中,作者一共是比较了 6 种环境,下面我们就简单介绍两组实验,分别是在「Atari」和「StarCraft2」上进行的。
Atari 环境
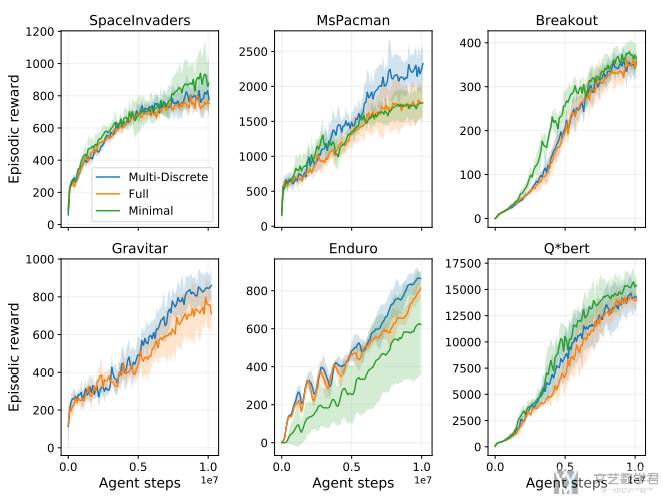
在 Atari 环境下,测试 RA 和 CMD 两种变换在三种动作空间下的效果。Atari 环境的默认动作空间是 Discrete 类型。作者额外增加了三种动作空间,分别是:
Full:包含所有动作空间。以下测试的游戏中,都是18种。Minimal:只包含最少最必要的动作,即RA。Space Invaders和Q*bert有6种,MsPacman和Enduro有9种,Breakout有4种,Gravitar有18种(这个和Full一样)。Multi-discrete:将discrete动作空间变成multi-discrete空间。具体来说是一个二维的向量,分别控制「游戏手柄」和「开火按键」。「游戏手柄」有9个离散的动作,「开火按键」有2个离散的动作。这里从multi-discrete空间变为discrete动作空间,全部的组合就是有2×9=18种可能性,也就是上面Full的动作数量(其实这里动作数量不是很多)。
实验结果如下图所示,可以看到平均而言,不同动作空间差异不是很大。除了 MsPacman,在这个游戏中,多维离散空间的性能会比其他动作空间高出 25%。从这个结果可以看出,RM 可能会降低性能,但是总体而言不会改变太多。
StarCraft2 环境
《星际争霸2》可以算得上是最复杂的 RTS 游戏,对于 RL 算法来说是一个非常具有挑战性的领域。不过这里只选择了《星际争霸2》中四个迷你场景来进行实验,分别是:
- CollectMinerlShards (CMS):一个简单的导航任务。玩家控制两个海军陆战队员,必须尽可能快地收集随机散落的矿物碎片。
- DefeatRoaches (DR):玩家控制着一支海军小队,必须打败一支 Roach 军队。
- CollecMineralsAndGas (CMAG):这个任务的目的是让经济运转起来,尽可能多地收集矿产资源和 vespene 气体(游戏中的一种资源)。
- BuildMarines (BM) :尽可能多地建立海军战队。
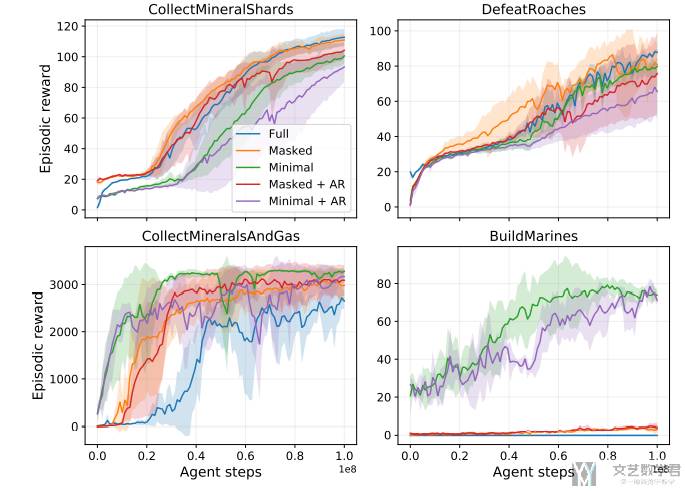
在《星际争霸2》的环境中,除了测试 Full 和 Minimal 两种动作空间,还额外测试了 Masked 和 AR 两种动作空间:
- Masked:在星际争霸游戏中,任何时刻,整个动作空间中只有一小部分子集的动作可以执行。为了防止 AI 在某些时刻选取当前时刻无法执行的动作,需要对动作空间进行 mask。具体操作时,如果选择了当前时刻不可用的动作,就会执行 no-op(no operation,即不操作)。
- AR:星际争霸的很多动作是由 base action+action parameters 构成的。比如,选择移动是 base action,选择移动的坐标 x、y 是对应的 action parameters。这通常由一种 auto-regressive(AR) 的方式解决,具体可以参考 DeepMind 的 AlphaStar。
实验结果如下图所示,可以得出以下的结论:
- Masked 在 BM 和 CMAG 任务中都起到了很重要的作用,而在 CMS 和 DR 中效果不明显。
- RA 在 BM 任务中显著地提高了算法的训练效果。
- AR 在这四个子任务中没有表现出明显的优势,不过在全局游戏智能体(AlphaStar)中还是比较重要的。
关于 Action Space Shaping 总结
- RA 在部分环境上确实会带来一点最终性能的损失(毕竟减小了决策空间),但在大部分环境上,都能有效提升训练收敛速度;而一些比较困难的环境,只有先进行动作空间精简,才能训练得到有意义的 RL 智能体。Removing actions ( RA ) can lower the overall performance (Doom), but it can be an important step to make environments learnable by RL agents (SC2, Obstacle Tower).
- 连续动作空间几乎在所有情况下都比离散动作空间更难学习,离散化在很多情况下都能带来明显的性能提升。Continuous actions are harder to learn than discrete actions (Get-To-Goal) and can also prevent learning all-together (ViZDoom). Discretizing them ( DC ) improves performance notably.
- Multi-Discrete 相比 Discrete 而言,在性能上一般没有太大区别,后者往往实现起来更简单,但在一些高度结构化的动作空间中,Multi-Discrete 会有更好的效果。Discretizing them ( DC ) improves performance notably. As for the MultiDiscrete spaces, we did not find notable difference between results with the MultiDiscrete and Discrete variants. Experiments on the Get-To-Goal task show how MultiDiscrete spaces scale well with an increasing number of actions, while Discrete do not. In all other environments (ViZDoom, Obstacle Tower, Atari) we observe no significant difference between the two.
下面是作者对文章提到的三种动作空间变换的一个总结:
Answering the question presented in the introduction, "do these transformations help RL training", removing actions and discretizing continuous actions can be crucial for the learning process. Converting multi-discrete to discrete action spaces has no clear positive effect and can suffer from poor scaling in cases with large action spaces.
- 作者也给出了一个当面对一个新的环境的时候,如何进行 action space shaping 的步骤:
- 首先只保留有意义(重要)的动作,将连续的动作转换为离散的动作;
- 不要将 multi-discrete 动作转换为 discrete 动作,同时限制动作数量;
- 如果此时 agent 可以收敛,那么尝试添加动作数量来提升性能;
Start by removing all but the necessary actions and discretizing all continuous actions. Avoid turning multi-discrete actions into a single discrete action and limit the number of choices per discrete action. If the agent is able to learn, start adding removed actions for improved performance, if necessary.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK