

flink-cdc同步mysql数据到hive - 大数据技术派
source link: https://www.cnblogs.com/data-magnifier/p/16699738.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文首发于我的个人博客网站 等待下一个秋-Flink
什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1. 环境准备
-
mysql
-
flink 1.13.5 on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
2. 下载下列依赖包
下面两个地址下载flink的依赖包,放在lib目录下面。
如果你的Flink是其它版本,可以来这里下载。
说明:我hive版本是2.1.1,为啥这里我选择版本号是2.2.0呢,这是官方文档给出的版本对应关系:
| Metastore version | Maven dependency | SQL Client JAR |
|---|---|---|
| 1.0.0 - 1.2.2 | flink-sql-connector-hive-1.2.2 |
Download |
| 2.0.0 - 2.2.0 | flink-sql-connector-hive-2.2.0 |
Download |
| 2.3.0 - 2.3.6 | flink-sql-connector-hive-2.3.6 |
Download |
| 3.0.0 - 3.1.2 | flink-sql-connector-hive-3.1.2 |
Download |
官方文档地址在这里,可以自行查看。
3. 启动flink-sql client
- 先在yarn上面启动一个application,进入flink13.5目录,执行:
bin/yarn-session.sh -d -s 2 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-hive
- 进入flink sql命令行
bin/sql-client.sh embedded -s flink-cdc-hive

4. 操作Hive
1) 首选创建一个catalog
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
这里需要注意:hive-conf-dir是你的hive配置文件地址,里面需要有hive-site.xml这个主要的配置文件,你可以从hive节点复制那几个配置文件到本台机器上面。
此时我们应该做一些常规DDL操作,验证配置是否有问题:
use catalog hive_catalog;
show databases;
随便查询一张表
use test
show tables;
select * from people;
可能会报错:

把hadoop-mapreduce-client-core-3.0.0.jar放到flink的Lib目录下,这是我的,实际要根据你的hadoop版本对应选择。
注意:很关键,把这个jar包放到Lib下面后,需要重启application,然后重新用yarn-session启动一个application,因为我发现好像有缓存,把这个application kill 掉,重启才行:
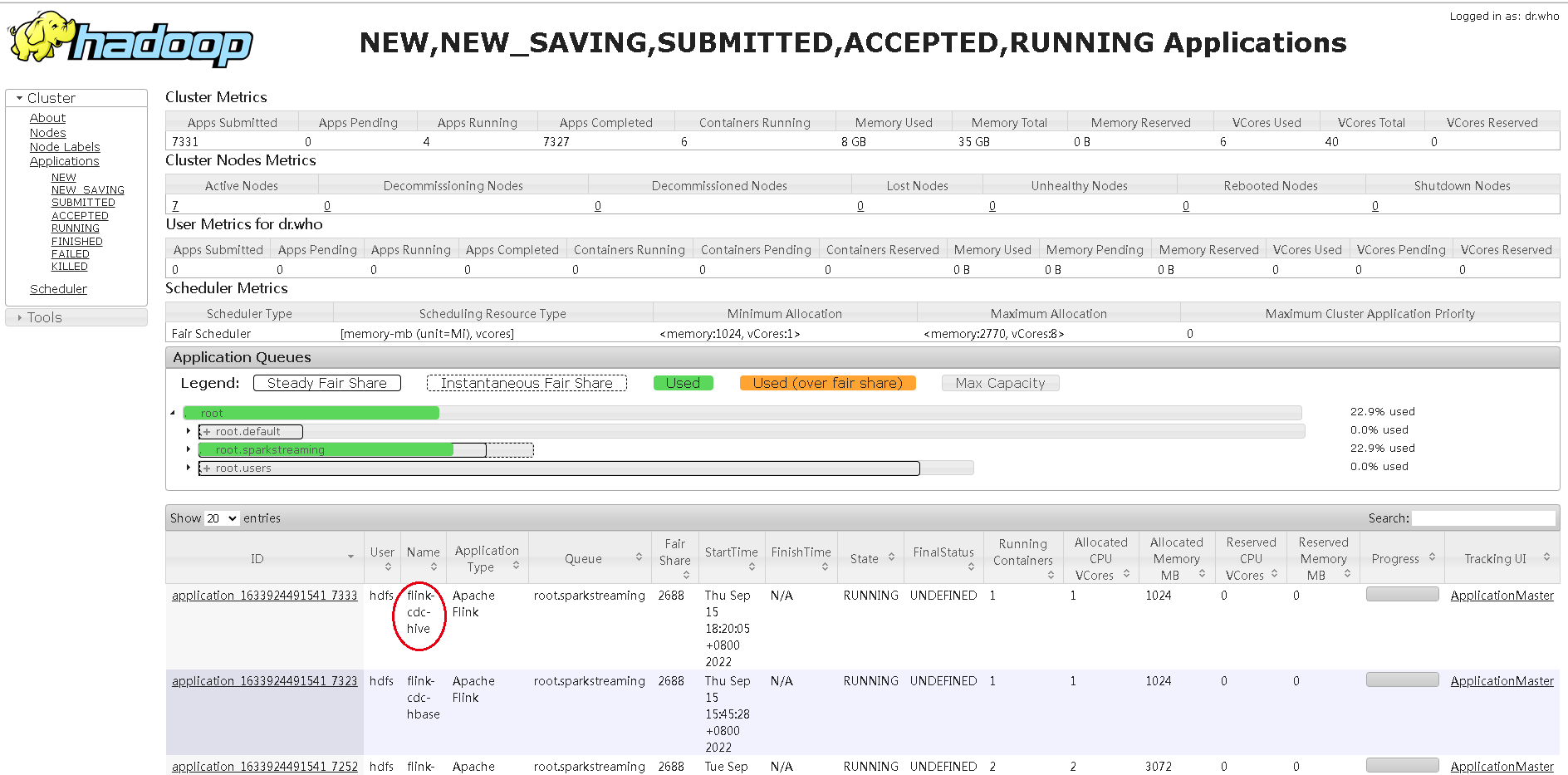
然后,数据可以查询了,查询结果:
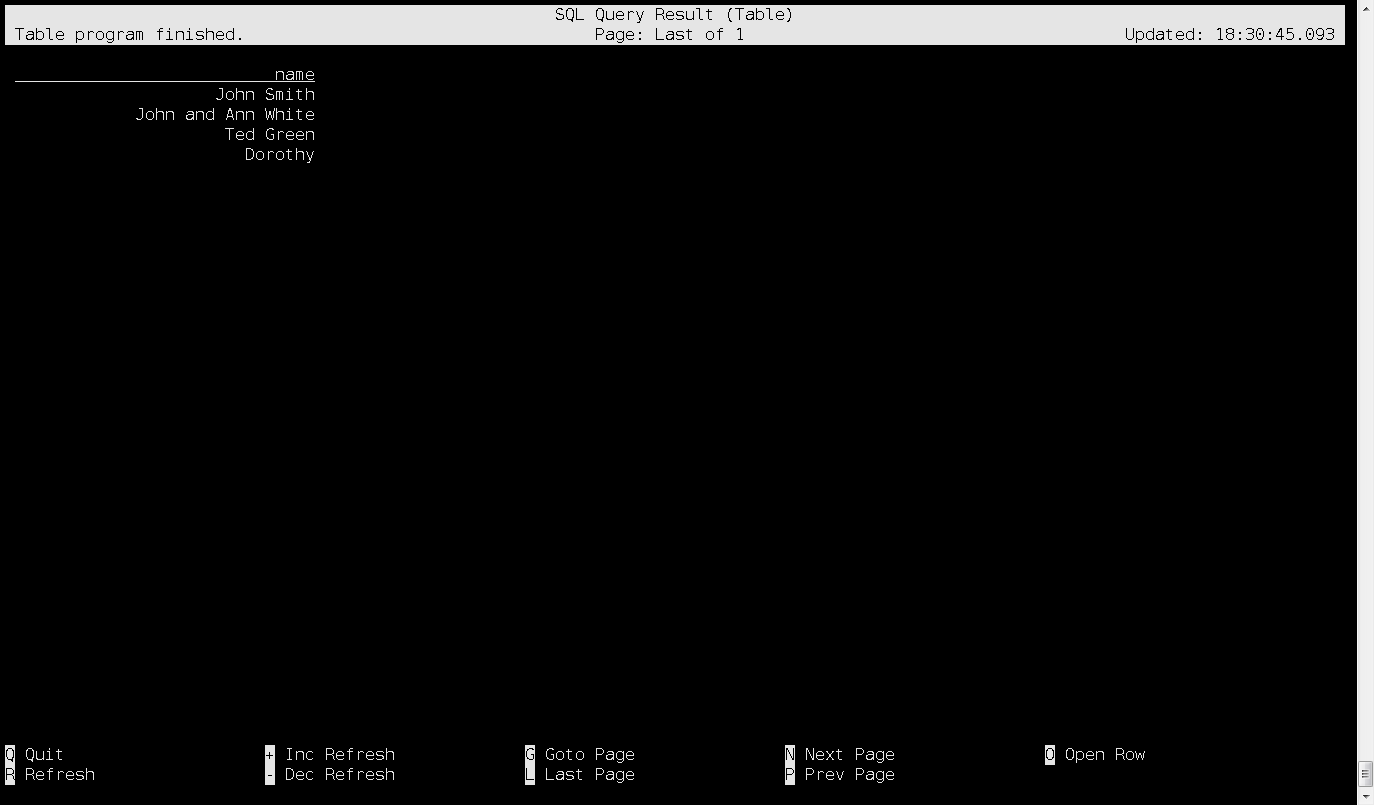
5. mysql数据同步到hive
mysql数据无法直接在flink sql导入hive,需要分成两步:
- mysql数据同步kafka;
- kafka数据同步hive;
至于mysql数据增量同步到kafka,前面有文章分析,这里不在概述;重点介绍kafka数据同步到hive。
1) 建表跟kafka关联绑定:
前面mysql同步到kafka,在flink sql里面建表,connector='upsert-kafka',这里有区别:
CREATE TABLE product_view_mysql_kafka_parser(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) WITH (
'connector' = 'kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = 'kafka-001:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
2) 建一张hive表
创建hive需要指定SET table.sql-dialect=hive;,否则flink sql 命令行无法识别这个建表语法。为什么需要这样,可以看看这个文档Hive 方言。
-- 创建一个catalag用户hive操作
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
use catalog hive_catalog;
-- 可以看到我们的hive里面有哪些数据库
show databases;
use test;
show tables;
上面我们可以现在看看hive里面有哪些数据库,有哪些表;接下来创建一张hive表:
CREATE TABLE product_view_kafka_hive_cdc (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) STORED AS parquet TBLPROPERTIES (
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0S',
'sink.partition-commit.policy.kind'='metastore,success-file',
'auto-compaction'='true',
'compaction.file-size'='128MB'
);
然后做数据同步:
insert into hive_catalog.test.product_view_kafka_hive_cdc
select *
from
default_catalog.default_database.product_view_mysql_kafka_parser;
注意:这里指定表名,我用的是catalog.database.table,这种格式,因为这是两个不同的库,需要明确指定catalog - database - table。
网上还有其它方案,关于mysql实时增量同步到hive:

网上看到一篇写的实时数仓架构方案,觉得还可以:
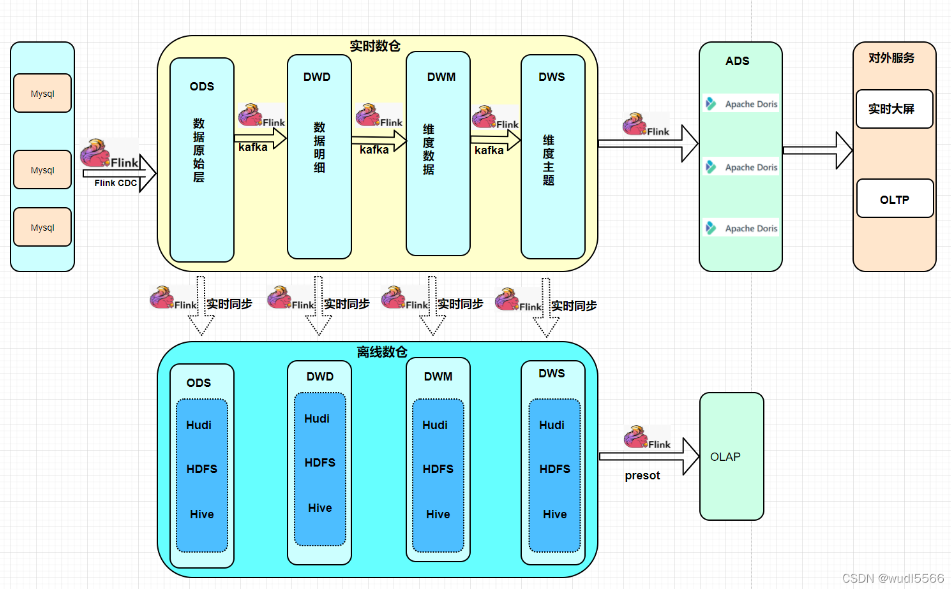
Recommend
-
7
公司的数据存放在HDFS上,但是模型的训练时需要用到这部分数据,于是就有了数据同步的需求。以下是个人整理的数据同步流程,仅适用于公司内部,其他地方由于环境不同可能不可用。
-
6
Flink使用HiveCatalog可以通过批或者流的方式来处理Hive中的表。这就意味着Flink既可以作为Hive的一个批处理引擎,也可以通过流处理的方式来读写Hive中的表,从而为实时数仓的应用和流批一体的落地实践奠定了坚实的基础。本...
-
11
一. 背景 数据准实时复制(CDC)是目前行内实时数据需求大量使用的技术,随着国产化的需求,我们也逐步考虑基于开源产品进行准实时数据同步工具的相关开发,逐步实现对商业产品的替代。我们评估了几种开源产品,canal,debezium,flink CDC等产品。...
-
7
基于Apache Hudi 的CDC数据入湖欢迎关注微信公众号:ApacheHudi作者:李少锋文章目录:一、CDC背景介绍二、CDC数据入湖三、Hudi核心设计四、Hudi未来规划1. CDC背景介绍首先我们介...
-
6
-
8
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监...
-
10
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监...
-
10
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监...
-
5
Flink同步Kafka数据到ClickHouse分布式表 精选 原创 大数据技术派 2022-12-06 14:50...
-
5
从数据库导出数据CDC的几种方式 23-08-24 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK