
3

多维分析利器Druid
source link: https://blog.51cto.com/key3feng/5682977
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
多维分析利器Druid
精选 原创Druid是一个用于大数据实时查询与分析的分布式列式数据存储系统。为了应对海量数据的实时查询和多维分析,Druid应运而生。 Druid诞生于MetaMarkets公司,而互联网广告分析正是MetaMarkets最重要的业务之一,基于同样的业务需求背景,微博广告也开始尝试将 Druid 作为监控平台后端数据引擎的技术方案之一。
一、Druid特性
Druid的特性如下:
- 支持部分嵌套数据结构的列式存储。
- 进行剪枝的分布式层级查询。
- 通过索引快速过滤。
- 数据的实时摄入和查询。 容
- 错分布式架构确保数据不丢失。
- 水平扩展。
二、Druid架构
1、Druid节点组成
Druid 是一个分布式系统,由多个角色的节点组合而成,每个节点都只关心自己的工作。Druid架构示意图如下。
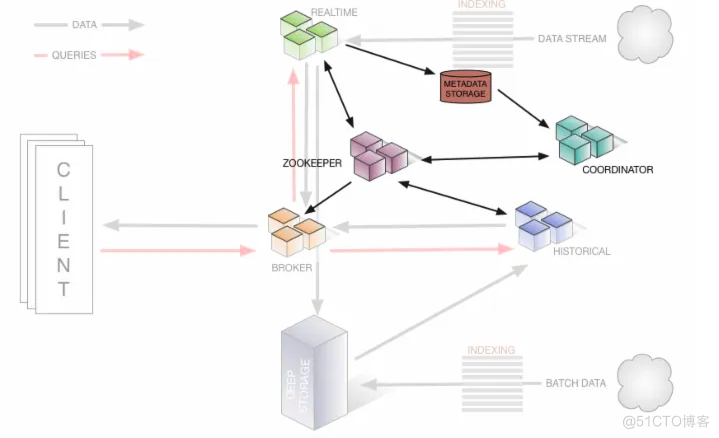
- 实时节点:实时节点提供实时的索引服务,通过这些节点索引的数据可以立即用于查询。实时节点将在一定时间内收集到的数据生成一个 Segment 数据文件,并将这个Segment数据文件发送到历史节点中。通过ZooKeeper监控传输和元数据库来存储被发送的 Segment 数据文件的元数据。发送完成后,实时节点就会丢弃被发送的 Segment数据文件。
- 历史节点:存储和查询历史数据。历史节点不与其他节点直接通信,而是通过与ZooKeeper保持一个长连接,实时观察指定路径下的新Segment数据文件信息。当历史节点注意到 ZooKeeper 指定队列路径下有一个条目时,首先它会检查本地缓存中是否存在该Segment数据文件的元信息,如果本地缓存中不存在新Segment数据文件的元信息,那么历史节点将从ZooKeeper中读取新Segment数据文件的元信息到本地,并根据下载到本地的Segment数据文件的元信息去Deep Storage中拉取Segment数据文件。最后,历史节点会通过ZooKeeper向集群宣布,它将提供该Segment数据文件的查询服务。
- 协调节点:主要负责Segment数据文件的加载、删除,管理Segment数据文件副本和平衡各历史节点的Segment数据文件。协调节点根据配置文件中指定的参数定期运行,每次运行,它都会监测集群状态,并采取相关的动作。协调节点通过 ZooKeeper 来获取集群信息,同时还会保持与存储可用段表和规则表的数据库的连接。协调节点不会直接与历史节点通信,它会根据规则、容量等信息指定历史节点,并在 ZooKeeper 中该历史节点的队列路径下生成关于 Segment 数据文件的临时信息。历史节点看到这些临时信息,就会去拉取Segment数据文件。
- 代理节点:接收客户端的查询请求,并路由请求到实时节点或历史节点。代理节点通过ZooKeeper知道每个Segment数据文件存在于哪个节点上。代理节点还用于聚合每个节点返回的结果,再将聚合后的结果集返回给客户端。代理节点还可以通过配置缓存来存储历史节点查询的结果,提高了相同查询的效率。
- 索引服务节点:索引服务是一个高可用的分布式服务,运行与索引相关的任务。索引服务是一个主/从架构。索引服务由三个组件组成,即运行一个任务的peon组件、管理peon的Middle Manager组件和管理任务分配给Middle Manager的Overlord组件。其中Middle Manager和peon组件必须在同一个节点上。
2、外部依赖
- ZooKeeper集群:用于集群服务的发现和当前数据拓扑的维护。
- Metadata Storage:用于存储数据文件的元数据,但是不存储实际的数据。可以使用MySQL或者PostgreSQL作为Metadata Storage。Metadata Storage一般会存储以下几个表。
- Segments Table:Segment数据文件的元信息表。
- Rule Table:Segment数据文件的存储规则表。
- Config Table:配置表,用于存储运行时的配置对象。
- Task-related Table:索引服务创建并使用到的表。
- Audit Table:审计表,用于存储配置变化的审计历史记录。
- Deep Storage:用于存储Segment数据文件。
3、Segment传输过程
Segment传输过程如下图。
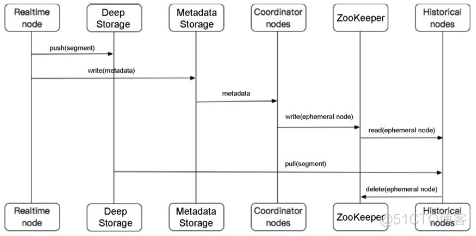
实时数据写入后的Segment传输流程如下:
- 实时节点将在一定时间内收集到的数据生成一个 Segment 数据文件,并发送到 Deep Storage,同时将该Segment数据文件的元信息发送到元数据库中。
- 协调节点从元数据库中获取新的Segment数据文件的元信息,根据规则分配该Segment数据文件存储的历史节点,并将元数据写入在ZooKeeper上创建的一个临时节点中。
- 历史节点从ZooKeeper的临时节点中读取元数据,去Deep Storage中拉取指定的Segment数据文件,并删除在ZooKeeper上创建的临时节点。
4、DataSource
在Druid中,数据是存储在每个DataSource中的,而一个DataSource就相当于MySQL的一个总表。每个DataSource都会包含下面三部分信息。
- Timestamp:存储指标的UTC时间列,可以精确到毫秒。
- Dimension:存储指标的维度列。
- Metric:指标列,用来聚合计算。
5、Segment
DataSource 描述的是数据的逻辑结构,而 Segment 则体现了数据的物理存储方式。Druid通过segmentGranularity参数来设置Segment划分的时间范围,而Druid查询也正是通过指定的时间范围来确认需要查询的Segment数据文件的,减小了查询的数据量,提高了查询的效率。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK