

[笔记] Order-Preserving Key Compression for In-Memory Search Trees
source link: https://fuzhe1989.github.io/2022/09/09/order-perserving-key-compression-for-in-memory-search-trees/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
原文:Order-Preserving Key Compression for In-Memory Search Trees
TL;DR
本文提出了一种针对字符串的分段编码框架 HOPE(High-speed Order-Preserving Encoder),在构建初始字典之后,可以流式编码任意字符串。且,重点来了,编码之间仍然保持原有字符串的顺序。这样 HOPE 的适用范围就不仅仅是静态的压缩已有数据了,它还能直接与各种树结构结合,直接用编码后的值作为 key。这样的好处有:
- 对于 B-tree 等,更短的 key 意味着更大的 fanout。
- 对于 Trie 等,更短的 key 意味着更低的高度。
- 节省空间有助于在内存中维护更多数据(如 cache 等)。
- 节省空间有助于提升 cache 性能。
令我大开眼界。直觉这篇 paper 比较实用。
Background
现代的内存查找树大致可以分为三类:
- B-tree/B+tree 家族,如 Bw-tree。
- Trie 和各种 radix,如 ART。
- 混合型,如 Masstree。
用在这些树结构上时,通用压缩算法,如 LZ77、Snappy、LZ4 等的问题是需要解压之后才能使用,单次开销大。
传统的整值字典编码有三个问题:
- 可以保持编码值顺序不变的字典编码算法,在处理新增字典值时开销大。
- 字典值的查询本身通常也会用到一些树型结构,相比直接用原始值查询并没有优势。
- 如果值的 NDV 比较大,字典会越来越大,最终抵消掉空间上的收益。
文章还讨论了基于频率的保序编码,如 DB2 BLU 以及 padding encoding,但我没太看懂。看描述意思前者也还是字典,只不过不同值的编码长度不同。后者在前者基础上做了补 0。这类方法主要用于列存编码中,不太适合内存查找树这种不停有新数据进来的场景,问题应该也是在字典的维护成本上。
之前没了解过这两种编码,不知道我理解得对不对。
像 Huffman 这样的墒编码会产生变长编码,之前在列存中的问题是解码太慢,但在内存查找树中这就不是问题了:查询和过滤都只针对编码值,不需要解码为原始值。
Compression Model
The String Axis Model
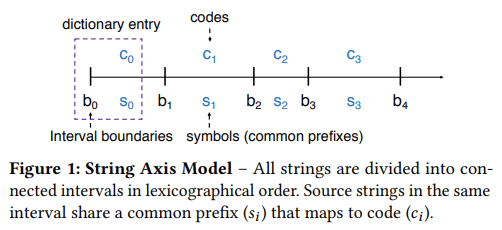
为了能实现用固定的字典编码任意字符串,HOPE 提出了如下模型:
- 将所有字符串按字典序排列在一个数轴上。
- 将数轴划分为若干个区间,每个区间的所有字符串会有一个最长共同前缀 Si。
- 使用某种编码算法为每个区间赋予一个编码值,这也同时是 Si 的编码值。
- 编码字符串时,根据它落在的区间,将前缀 Si 替换为对应的编码值。
- 重复步骤 4,直到字符串变成空串。
通过编码区间,HOPE 因此可以用固定大小的字典匹配任意字符串。但为了能保证编码过程收敛,需要保证每个 Si 不能为空,因此每个区间都要保证有一个非空的共同前缀。

以上就是 HOPE 定义的区间的完备性。
注意,不同区间可以有相同的前缀,但它们的编码值不同。
接下来,问题就是如何让编码保持顺序了。这就需要我们在步骤 3 使用一种保序的编码方式。
Exploiting Entropy
跳过其中出现的所有公式……反正都看不太懂
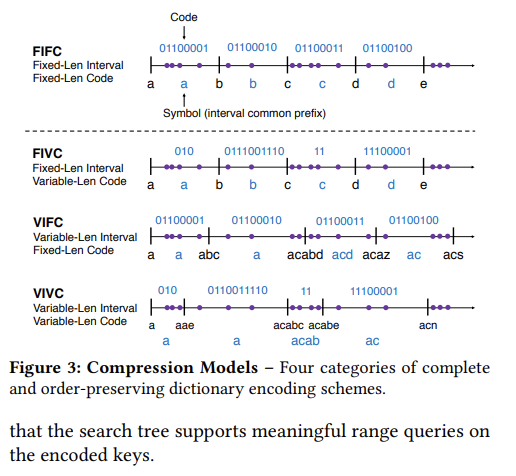
作者提出了四种类型的编码:
- FIFC,定长区间+定长编码,如 ASCII,作者表示不讨论。
- FIVC,定长区间+变长编码,典型如 Hu-Tucker 编码。Huffman 或算术编码也算,但它们不保序。
- VIFC,变长区间+定长编码,典型如 ALM。优点是解码快。要注意的是因为区间是变长的,Code(ab) != Code(a)+Code(b),但 HOPE 的场景不需要这种性质。
- VIVC,变长区间+变长编码,这是理论上压缩率最优的类型,但之前少有人研究。但这种方式下编码和解码速度都会受变长的影响。
Compression Schemes
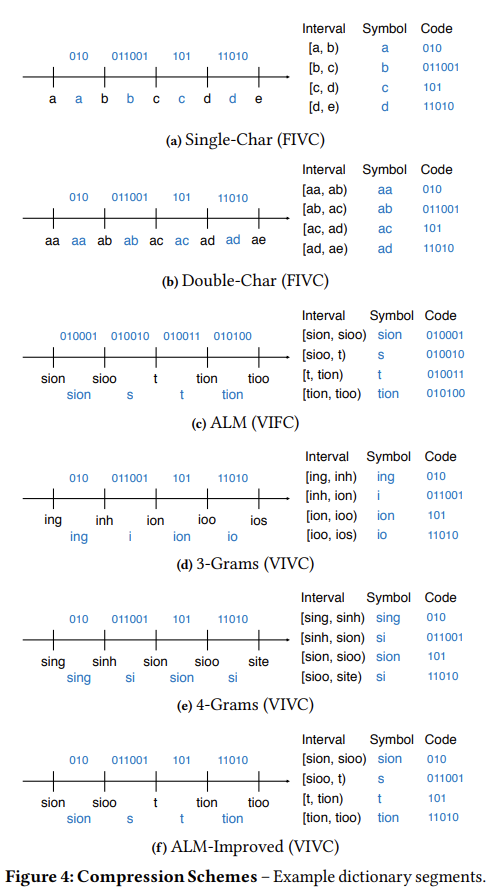
文章选择了 6 种编码方式:
- Single-Char,FIVC,元素长度为 1,使用 Hu-Tucker 编码。
- Double-Char,FIVC,元素长度为 2,使用 Hu-Tucker 编码。注意考虑到长度只有 1 的字符串,元素里需要有 b∅ 这样的占位符。
- ALM,VIFC,它的特点是会根据 len(s) × freq(s) 判断 s 是否放进字典中。当所有满足条件的 s
大概知道个意思,具体细节还得看对应 paper。
- 3-Grams,VIVC,所有区间都用长度为 3 的字符串隔开,仍然用 Hu-Tucker 编码(看起来 VC 都是用 Hu-Tucker 编码)。
- 4-Grams,VIVC,区间边界长度为 4。
- ALM-Improved,VIVC。相比 ALM 改进两点:
- 使用 Hu-Tucker 生成变长编码。
- ALM 会统计所有长度、所有位置的子串的频率,构建速度慢,内存占用高。ALM-Improved 则只统计每个采样字符串的所有前缀子串。
Overview
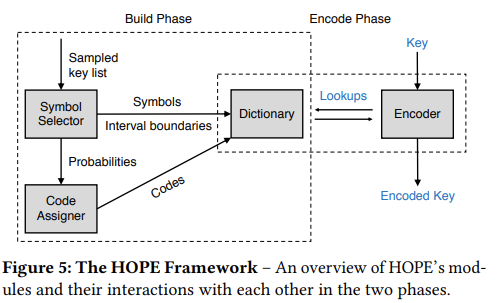
HOPE 分为以下组件:
- Symbol Selector(负责划分区间和取前缀)
- Code Assigner(负责赋予编码)
- Dictionary(构建字典)
- Encoder(使用字典编码字符串)
其中字典大小对于 VI 模式是可配的。
Implementation
Symbol Selector
ALM 和 ALM-Improved 的 Symbol Selector 需要额外一步来保证每个采样的值不能是另一个值的前缀,否则这两个值会落入相同区间,如 sig 和 sigmod。方法是总是将前缀串对应的频率加到它最长的延长串上。
对于 VI 编码,Symbol Selector 还会用对应的 symbol(共同前缀)长度为其对应的频率加权。
Code Assigner
Hu-Tucker 编码和 Huffman 非常像,也是统计出每个元素的频率,然后每次取出两个频率最低的拼在一起放回,依次直到所有元素组成一棵树,再沿着树的路径用 01 为每个叶子节点赋值。
与 Huffman 的区别在于,Hu-Tucker 每次必须取两个相邻的、频率之和最低的元素,放回时也保证顺序。
Dictionary
字典中只需要保存每个区间的左边界。
HOPE 中实现了三种不同的字典结构。
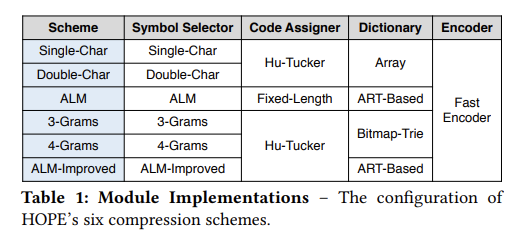
Single-Char 和 Double-Char 直接使用了数组。
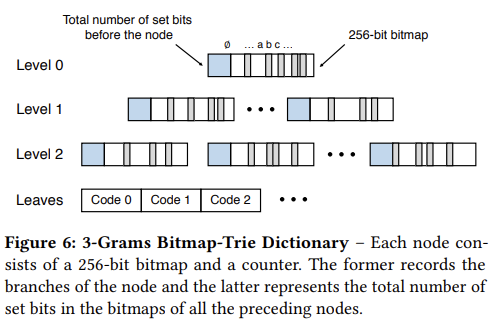
3-Grams 和 4-Grams 使用了一种 bitmap-tree,有点类似于 Trie,用一个 bitmap 来保存具体的子节点是否存在。因此 bitmap 长度为 256。每个节点保存 (n, bitmap),n 是它之前所有节点中的 1 的个数。所有节点保存在一个大数组中。这样一个节点的字符 l 对应的节点在数组中的下标就是 n + popcount(bitmap, l)。现代 CPU 都直接有 popcount 的指令,因此这种寻址方式非常快。
最后,ALM 和 ALM-Improved 使用 ART 来保存字典。
没看过 ART paper,这段略过。
Encoder
编码过程就是不停地判断字符串落在哪个区间,然后将前缀替换为编码,反复直到字符串变空。
为了加速编码的拼接,HOPE 用若干个 uint64 来保存结果,每当有新编码接入时:
- 左移当前结果以留出空间。这步可能需要分裂原编码结果。
- 用按位或写入新编码。
当批量编码时,HOPE 将值分成若干个固定数量的组,对每个组每次取共同前缀,只编码一次。当组内元素数量为 2 时,称为 pair-encoding。
后面的 evaluation 部分略。看完感觉 3-Grams 和 4-Grams 真是好编码。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK