

善用 yield return 省時省 CPU 省 RAM,打造高效率程式
source link: https://blog.darkthread.net/blog/yield-return/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
善用 yield return 省時省 CPU 省 RAM,打造高效率程式-黑暗執行緒
雖然有學過 IEnumerable 跟 yield return,遇到需要傳回集合或陣列的場合,我慣用的寫法還是一次將資料整理好,傳回 IList<T> 或 T[],很少想到用 IEnumerable 跟 yield return。大部分情況,兩種做法差異不大,但前陣子研究數百萬個檔案之 NTFS 空間利用率問題時,讓我對於 yield return 的優點有強烈體悟,這篇文章會用兩個簡單實驗展示 yield return 的威力,看它如何幫我們能節省等待時間、CPU 資源跟記憶體。
(如果你對 IEnumerable、yield return 寫法跟原理不熟,推薦幾篇文章:C# yield return: How It Work ? by 安德魯的部落格、Understanding C# foreach Internals and Custom Iterators with yield by Mark Michaelis, MSDN Magazine)
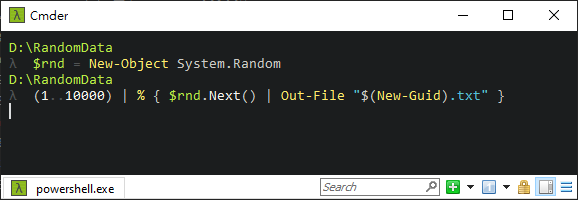
我先用以下 PowerShell 產生一萬個 .txt 檔當實驗材料,以 GUID 為檔名,內容寫入亂數。
$rnd = New-Object System.Random
(1..10000) | % { $rnd.Next() | Out-File "$(New-Guid).txt" }
假設我有個無聊的需求,要在這一萬個檔案中找出亂數值整除 1000 的資料,把它寫成函式string[] FilterRandomDataTest(string path)。最直覺的無腦寫法會像這樣:
string[] FilterRandomDataTest(string path)
{
return Directory.GetFiles(path)
.Where(o=> File.ReadAllText(o).TrimEnd(Environment.NewLine.ToCharArray()).EndsWith("000"))
.ToArray();
}
加上計時及結果顯示邏輯,實測一下:(註:我用 subst R: \\localhost\d$ 以網路磁碟機方式存取檔案,模擬較高的結果產生成本)
var stTime = DateTime.Now;
Log("Dump All Start");
// 用 foreach 列出所有結果
foreach (var file in FilterRandomDataTest("R:\\RandomData"))
{
Log(file);
}
Log("End");
stTime = DateTime.Now;
Log("Show First 3 Start");
// 只讀前三筆,這次用 LINQ 寫
FilterRandomDataTest("R:\\RandomData").Take(3).ToList().ForEach(file => Log(file));
Log("End");
Console.ReadLine();
void Log(string message)
{
Console.WriteLine($"{(DateTime.Now - stTime).TotalMilliseconds/1000:000.00}s {message}");
}
string[] FilterRandomDataTest(string path)
{
return Directory.GetFiles(path)
.Where(o=> File.ReadAllText(o).TrimEnd(Environment.NewLine.ToCharArray()).EndsWith("000"))
.ToArray();
}
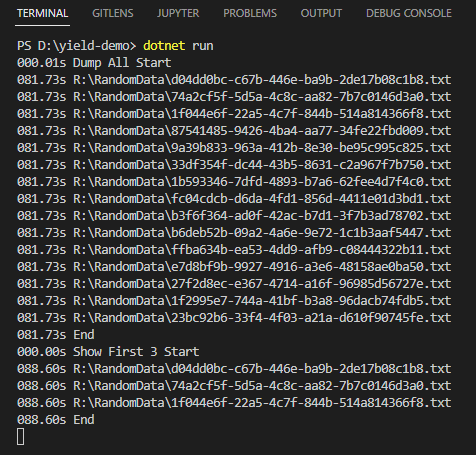
這是我過去常用的寫法,FilterRandomDataTest() 會讀完一萬個檔案再一次傳回 15 筆資料,故會等 81s 再一次顯示。而 LINQ 只取前三筆,一樣要花 88 秒:
接著讓我們把它改寫成 yield return 版本:
IEnumerable<string> FilterRandomDataTest(string path)
{
foreach (var file in Directory.GetFiles(path)) {
if (File.ReadAllText(file)
.TrimEnd(Environment.NewLine.ToCharArray()).EndsWith("000"))
yield return file;
}
}
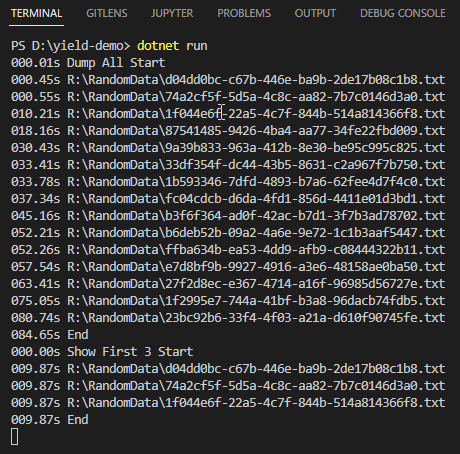
yield return 版本顯示 15 筆一樣要花 84 秒,但最大差別是 0.45s 時便出現第一筆,0.55s 顯示第二筆,一找到符合內容就即時傳回結果,不需要空等 80 秒;而 LINQ 取前三筆的測試差異更明顯,取足三筆後程式就結束,只花不到 10 秒,省了 70 秒。
由此證明,yield return 提供更好的即時性,若只需要部分結果,還可省去處理無用資料的時間跟資源。
由不需產生整個陣列或 IList 的原理,我們也不難設計一個實驗證明 yield return 能節省記憶體。
以下程式會產生 10 萬筆 Guid,GetGuidStrings() 會回傳這 10 萬筆 Guid 轉成的 string[],我們用 GC.GetTotalMemory() 觀察程式耗用記憶體大小:
var guidPool = Enumerable.Range(0, 100000).Select(i => Guid.NewGuid()).ToList();
ShowMemSize();
Console.WriteLine(GetGuidStrings().Count());
ShowMemSize();
Console.WriteLine(GetGuidStrings().First());
ShowMemSize();
Console.ReadLine();
string[] GetGuidStrings()
{
return guidPool.Select(o => o.ToString()).ToArray();
}
void ShowMemSize()
{
var memSz = GC.GetTotalMemory(false) / 1024 / 1024;
Console.WriteLine($"Mem Size = {memSz}MB");
}
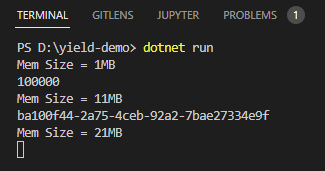
實測 string[] 寫法,統計筆數或 LINQ First() 都各耗用 10MB 記憶體(記憶體大小由 1MB 上升到 11MB,再增加到 21MB)。
yield return 版,改傳回 IEnumerable<string> 並以 yield return 傳回結果:
IEnumerable<string> GetGuidStrings()
{
foreach(var guid in guidPool)
yield return guid.ToString();
}
記憶體用量從頭到尾都是 1MB,因每次只處理一筆,不需要建立陣列放 10 萬個字串,耗用記憶體幾可忽略。
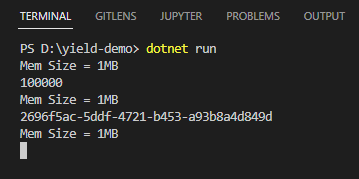
由以上實驗,展現了 yield return 的優勢:
- 有結果立即回傳,提供更好的即時性 (這是要串接成生產線模式的必要條件)
- 只需部分結果時,省去處理無用資料的成本
- 不需耗用記憶體儲存全部結果
遇到結果筆數龐大或產生資料成本偏高的情境,善用這些優勢,將能打造出更有效率的系統。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK