

AWS Graviton3 delivers leading AES-GCM encryption performance
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/aes-gcm-optimizations-for-armv8-4-on-neoverse-v1-graviton3
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

AWS Graviton3 delivers leading AES-GCM encryption performance

The capabilities of Arm Neoverse platforms and Arm Architectures are continually evolving. This creates opportunities to improve the system efficiency of fundamental algorithms through close collaboration between hardware and software architects. Arm Neoverse platforms are now able to take advantage of the Cryptographic Extensions in Armv8-A to accelerate important cryptographic operations. This blog introduces the Galois/Counter Mode (GCM) of the popular Advanced Encryption Standard (AES) algorithm. And shows how to make the best use of these instructions and expose the full potential of Arm Neoverse platforms.
Galois/Counter mode is a mode of operation of the Advanced Encryption Standard (AES-GCM) [1] block cipher algorithm. It enables high levels of parallelism when compared with the older Cipher Block Chaining mode (AES-CBC). This blog compares the performance of AES-GCM between c6g, c7g (Arm instances), and c6i (3rd Gen Intel Xeon Scalable) provided by Amazon EC2 instances. The blog also introduces two optimizations, loop unrolling and EOR3 instruction to further improve the performance of AES-GCM on Arm cores. The optimizations mentioned in this blog are expected to be effective for other modes in the AES family.
AES-GCM
AES-GCM is an authenticated encryption algorithm that turns an unencrypted plaintext into an encrypted and authenticated ciphertext and can be thought of in two distinct phases. First, blocks in the plaintext are encrypted using the AES-CTR algorithm to create ciphertext. Second, the stream of encrypted blocks is authenticated by building a Galois Hash (GHASH) across the ciphertext.
AES-CTR
AES-CTR encrypts the plaintext into the ciphertext. It is computed across each 16-byte block in the plaintext according to the following algorithm:
- A 4-byte counter, stored in memory big-endian format, is incremented.
- The counter is prepended with a 12-byte constant to create a 16-byte modified counter.
- The modified counter is encrypted with AES using the specified key length (128, 196, or 256-bits) to create a 16-byte encrypted counter.
- The exclusive or (⊕) of the 16-byte encrypted counter and the 16-byte plaintext is taken to produce the ciphertext.
GHASH
The hash used for integrity in AES-GCM is closely related to a cyclic redundancy check (CRC). Like for CRCs, each block to be authenticated contributes a linearly independent part of the resultant hash. Unlike CRCs the method of generating the contribution requires knowledge of the secret hash key. In GHASH the block size is 16 bytes, and the contribution of each block to the resultant hash is calculated by the following two steps:
- The 16-byte block is multiplied, using a 128-bit multiplication in the Galois Field GF(2), by a power of the hash key. This can be described as a 128 polynomial multiplication giving a 256-bit result.
- The 256-bit result is reduced by taking the modulo of the result with respect to a fixed GCM polynomial (P) to give the 16-byte block hash.
This block hash is then added to the hash using a 16-byte exclusive or operation.
Optimizations for AES-GCM on c7g
Loop Unrolling
Arm recommends that the fused loop is unrolled to expose more opportunities for parallel execution to the microarchitecture. The degree to which unrolling is beneficial, known as the unroll factor, depends on the available execution resources of the microarchitecture and the execution latency of paired AESE/AESMC operations. A higher unroll factor increases the complexity of managing architectural resources. And it requires extra code size to handle partial executions of the unrolled loop where the required number of iterations is not a multiple of the unroll factor.
- For a platform with an in-order microarchitecture, Arm recommends an unroll factor of two. This enables pipelining of independent AESE/AESMC pairs without introducing much of the loop unrolling overhead described above. Arm does not recommend unrolling factors above two due to the difficulty of maintaining the architectural register state while also efficiently scheduling code to avoid write-after-read and write-after-write dependencies between registers.
- For a platform with an out-of-order microarchitecture, Arm recommends an unroll factor of four.
- For a platform with an out-of-order microarchitecture, and many fast execution units capable of processing AESE/AESMC instructions, Arm recommends an unroll factor of eight.
The recommendations for out-of-order microarchitectures consider the much greater capabilities of the processor to find hidden instruction level parallelism through register renaming and dynamic execution scheduling. For the c7g platform, Arm recommends an unroll factor of eight to make the best utilization of the considerable execution resources of the microarchitecture.
Use the EOR3 instruction
Arm recommends that implementations of AES-GCM targeting microarchitectures which include the Cryptographic Hashing extensions introduced in Armv8.2-A use the EOR3 instruction.
The EOR3 instruction implements a three way exclusive-or operation. This allows a programmer to replace this chain of instructions:
EOR v0.16b, v1.16b, v2.16b
EOR v0.16b, v0.16b, v3.16b
With the single instruction sequence:
EOR3 v0.16b, v1.16b, v2.16b, v3.16b
This is beneficial both in reducing the code size of the library routine and in reducing the number of operations that must be completed by the processor.
The optimizations mentioned above have been merged to the mainstream of OpenSSL [2].
Performance
Instances and Software for testing
We tested AES-GCM included in OpenSSL on AWS instances. The basic information about the instances and OS kernel version is as follows:
| Instance type | #Cores | #vCPU | Memory (GiB) | Price/per_hour (USD)[3] | OS Kernel | OpenSSL build |
| c7g.16xlarge (Arm) | 64 | 64 | 128 | 1.1426 | 5.13.0-1029-aws |
gcc-10 -mtune=native |
| c6g.16xlarge (Arm) | 64 | 64 | 128 | 1.0882 | ||
| c6i.16xlarge (Intel) | 32 | 64 | 128 | 1.0882 |
To run the tests: openssl speed -multi num_of_threads -evp aes-bits-gcm. We tested AES-GCM with different number of threads: [1,2,4,8,16,32,64], encryption bits: [128,192] and buffer size (bytes): [1024, 8192]. Each test is named aesXXgcm-YY_evp, meaning it adopts XX encryption bits and YY bytes of buffer.
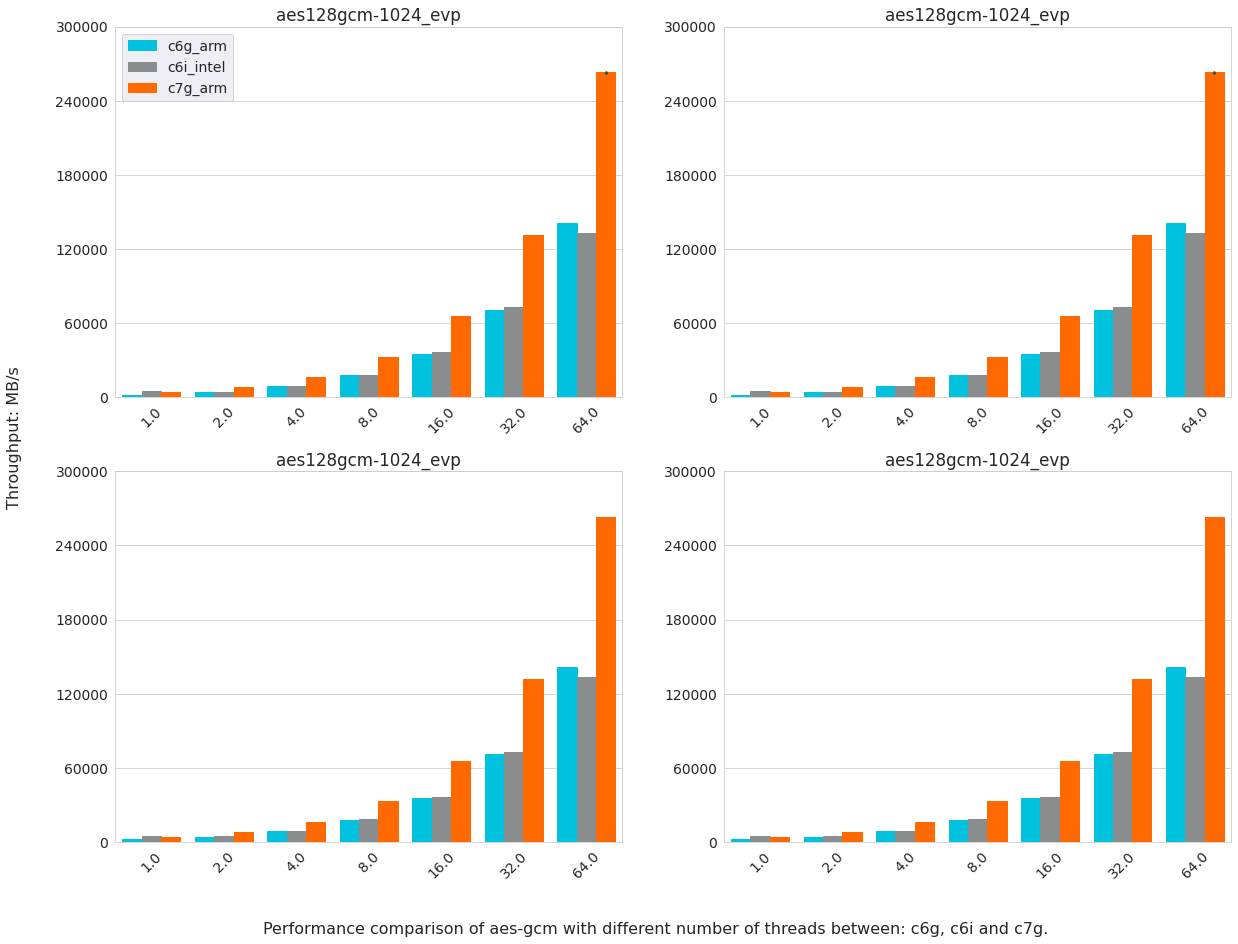
c7g vs c6g vs c6i
The comparison results of AES-GCM between c6i, c6g, and c7g are shown in the figure below. Note that the results on Arm instances have not included any optimizations. The performance result shows the throughput: MB/s.
Overall, the performance of AES-GCM on c7g is around 100% higher than that on c6i. c6i achieves a higher performance when testing with one thread. However, it does not scale well with multiple threads. With hyperthreading on c6i, if one hyperthread executes AVX512 code, the core has to reduce its frequency, which slows down the execution on the sibling hyperthread of the same core. The performance on c6g is slightly lower than c6i, but it catches up with c6i on multi threads.
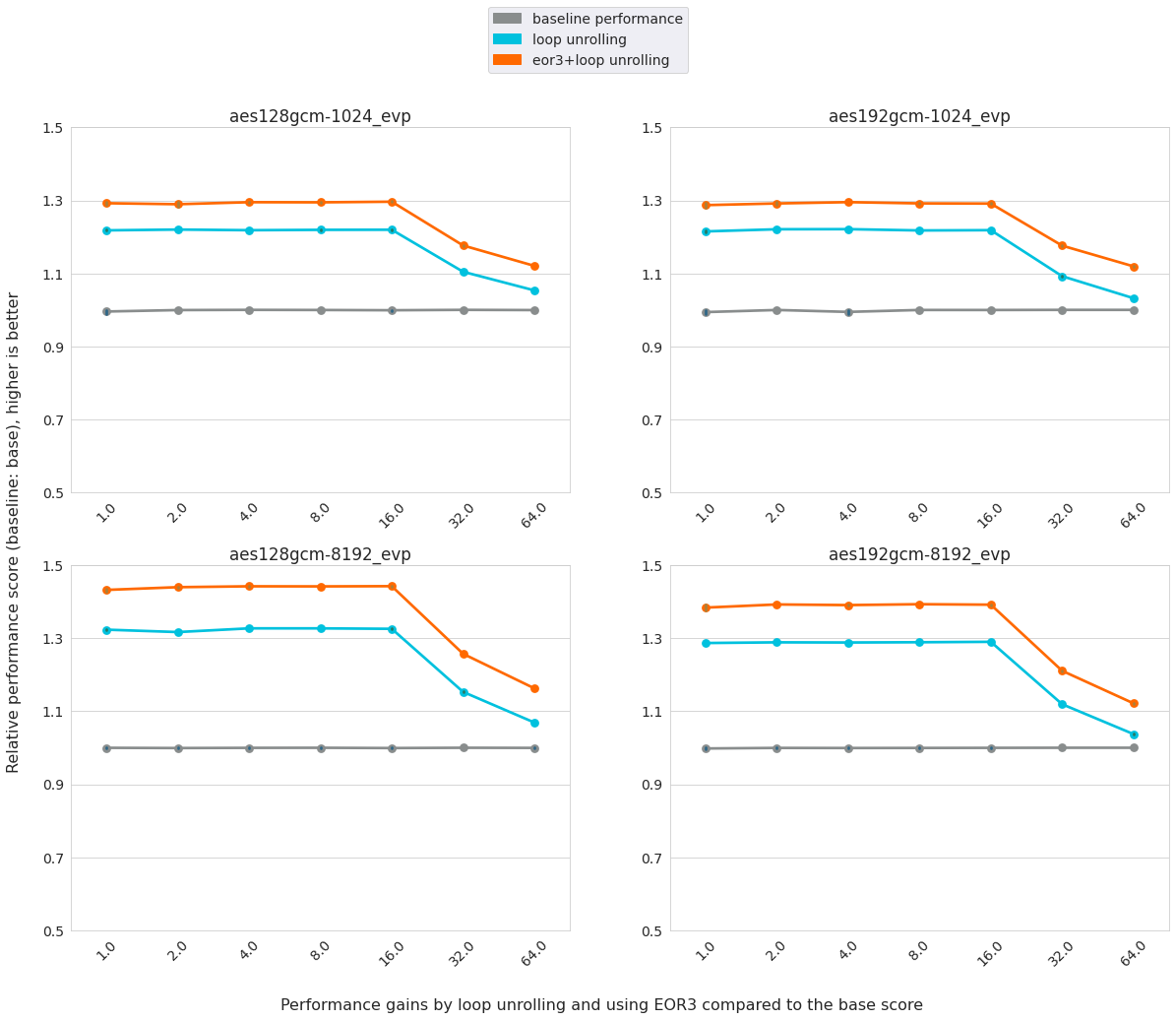
Performance gains by Loop Unrolling and EOR3 on c7g
We evaluated the performance gains on c7g brought by the two optimizations mentioned above: loop unrolling and eor3 plus loop unrolling. Results are presented below. With the size of the buffer increasing from 1024 to 8192, the performance improvement by the optimization also grows. For buffer_1024, loop unrolling improves the performance by ~22% and eor3 achieves another 8% improvement. For buffer_8192, loop unrolling improves the performance by ~34% and eor3 offers another 11% improvement. It must pay attention that the performance gains drop starting from thread_number=16. This is because the performance is limited by the memory bandwidth above 16 cores.
Conclusion
AWS Graviton3 (c7g) shows strong performance uplift on AES-GCM encryption workload, compared to AWS Graviton2 (c6g) and 3rd Gen Intel Xeon Scalable (c6i). With multi threads, the performance of AES-GCM on c7g almost doubles that on c6i. The performance on c6g catches up with c6i on multi threads. Moreover, the new instruction extension (EOR3) and micro-architecture dependent loop unrolling enable further optimizations to AES-GCM on c7g. Based on the evaluation results, an unroll factor of eight make the best utilization of the micro-architecture, which improves the performance up to 33% on c7g. Applying the new instruction EOR3 brings another 10% improvement to the performance. Though not tested, the optimizations mentioned in this blog are expected to be effective for other modes in the AES family.
Reference
[1] https://en.wikipedia.org/wiki/Galois/Counter_Mode
[2] https://github.com/openssl/openssl/commit/954f45ba4c504570206ff5bed811e512cf92dc8e
Recommend
-
12
Introduction The third-party cryptography package in Python provides tools to encrypt byte using a key. The same key that encrypts is used to decrypt, which is why they call it symmetric encryption.
-
11
I recently had the opportunity to encrypt/decrypt stuff using AES, but I didn’t know it inside out well. I couldn’t help but be curious about how it is working, and I realized my mind could only be satisfied by digging deeper into its impleme...
-
7
Authenticated Encryption in .NET with AES-GCM When using symmetric encryption, you should be favoring authenticated encryption, such as AES-GCM (Galois/Counter Mo...
-
8
Deploying AES Encryption On Cryptool 2.1June 1st 2021 new story5
-
5
AWS 要推出 Graviton3 的機種了 AWS 打算要推出 Graviton3 的機種了,目前還在 preview 階段:「
-
11
Introduction While working in security, identity management and data protection fields for a while, I found a very few working examples in the public domain on cross platform encryption based on AES 256 GCM algorithm. This is the sa...
-
10
AWS Releases First Graviton3 Instances May 29, 2022 2 min re...
-
5
What Is AES-256 Encryption? How Does It Work? By Karim Ahmad Published 7 hours ago It's often touted as the mos...
-
11
AWS 推出了 Graviton3 的機種 Amazon EC2 推出了
-
3
In this blog we explore the performance of a Nginx Reverse Proxy (RP) and API Gateway (APIGW) on AWS Graviton3-based instances. We will also refer to these collectively as RP/APIGW. We compared AWS Graviton3-based instances to Intel Xeon 'Ice Lake...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK