

Reading NeuMan: Neural Human Radiance Field from a Single Video
source link: https://jyzhu.top/Reading-NeuMan-Neural-Human-Radiance-Field-from-a-Single-Video/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
论文地址:https://arxiv.org/abs/2203.12575
作者:Jiang, Wei and Yi, Kwang Moo and Samei, Golnoosh and Tuzel, Oncel and Ranjan, Anurag
发表: ECCV22
开源代码: https://github.com/apple/ml-neuman
人体的渲染和新姿势生成在增强现实的应用中很重要
NeRF的出现让新视角生成任务取得很大进步
但是现有工作都没有实现:根据单段wild视频,生成新的人物和新的场景
image-20220824123146868
What:
读前疑问:
- NeRF和人体SMPL模型是怎么有机统一的🤔
输入是一段wild视频,moving camera的。用现存方法估计人体姿势、人体形状、人体mask(Mask-RCNN)、相机pose、sparse scene model、depth maps
然后训练两个 NeRF 模型,一个用于人体,一个用于由 Mask-RCNN 估计的分割mask引导的背景。 此外,通过将来自多视图重建和单目深度回归的深度估计融合在一起来规范场景 NeRF 模型
关于NeRF:(参考:zhihu)
NeRF是用神经辐射场建模一个场景,好处是可以生成新视角的图像。针对一个静态场景,需要提供大量相机参数已知的图片。基于这些图片训练好的神经网络,即可以从任意角度渲染出图片结果了。
它用MLP,把一个3d场景隐式地编码进神经网络里。输入为3d空间中一个点的坐标\boldx=(x,y,z)和相机视角 \boldd=(θ,ϕ),输出为该点对应的体素的密度opacity,以及颜色\boldc=(r,g,b)。公式就是 f(\boldx,\boldv)=(\boldc,σ)
在具体的实现中, x 首先输入到MLP网络中,并输出 σ 和中间特征,中间特征和 d 再输入到额外的全连接层中并预测颜色。因此,体素密度只和空间位置有关,而颜色则与空间位置以及观察的视角都有关系。基于view dependent 的颜色预测,能够得到不同视角下不同的光照效果。
NeRF 函数得到的是一个3D空间点的颜色和密度信息,但当用一个相机去对这个场景成像时,所得到的2D 图像上的一个像素实际上对应了一条从相机出发的射线上的所有连续空间点。后续就有各种各样高效的方式来进行可微渲染了,本质上都是从这条射线上采样,获得平均的颜色信息。
人体模型:NeRF+SMPL
我主要关注的就是人体模型这部分了。总体来说,做法就是:
首先生成人体NeRF模型,然后用ROMP生成逐帧的人体SMPL模型,然后定义一个canonical的人体模型(主要是去掉姿势这个变量,变成大字型人体),根据像素点在SMPL模型上对应的位置,再对应到canonical模型上,学到人体的外貌。(其实训练中NeRF和SMPL模型是一起学的,没有分得那么开的先后顺序。)
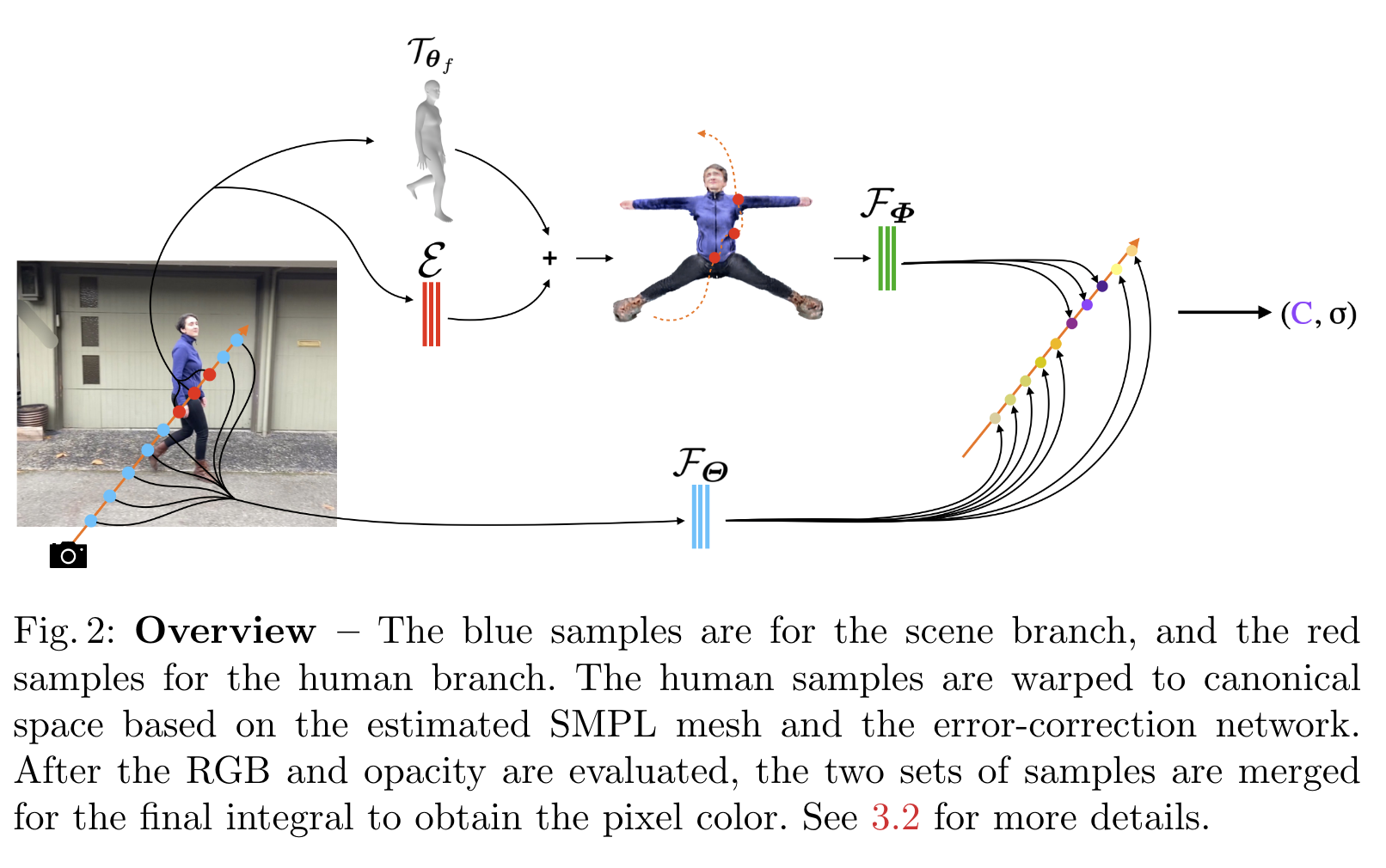
image-20220824180150642
具体来说:
对于某一帧图像,用ROMP估计人体的SMPL模型,但采取了一些改良:
- 利用densepose估计人体的silhouette,以及MMPose估计人体的2D joints;根据这些结果优化SMPL参数
把刚刚得到的SMPL模型warp成一个canonical的大字型人体模型,这个warp变换称为T
怎么把图像中的像素点对应到canonical的大字型人体模型上呢?
首先生成人体NeRF模型
对于空间中的每个点\boldxf=\boldrf(t) (这里的f是第f帧图像),它都可以由一条射线\boldr上对应的像素点渲染而来;那么对这个点直接应用前面的变换T,就得到它在canonical空间中对应的点了,\boldxf′=Tθf(\boldxf)
但是因为SMPL的估计不是很准确,这个变换T也不是很准确,所以这里提出来,通过在训练中同时优化SMPL模型 θf和人体NeRF模型的方式,可以提升效果。
还有,还加了一个MLP改错网络E改正warping的误差。最终结果就是: \boldx~f′=Tθf(\boldxf)+E(\boldxf,f)
此时相机视角也需要校正:对于射线ray上的第i个样本点, \boldd(ti)f′=\boldx^f′(ti)−\boldx^f′(ti−1)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK