

我们为什么需要「云原生大数据」?
source link: https://www.51cto.com/article/717662.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
我们为什么需要「云原生大数据」?
「云原生大数据 」已经是现在科技领域的热词了,尤其是对于大中型企业的可扩展性和敏捷性开发需求而言。什么是「云原生大数据」呢?首先大数据是我们很熟悉的词汇了,主要讲的是储存、使用、挖掘海量的数据。而因为数据量过大,因此无法在本地单机上运行,而必须在云上进行管理。云原生指的是进一步提升云服务的可扩展性(scalability)和敏捷性(agility),前者指的是处理数据的数量,后者指的是开发的便捷性。因此简单来说, 云原生大数据就是「为了在更大的数据上做更快的开发」的这一类技术与平台 。
很多企业都有这样的需求。以微信为例,它有超过3000个(微)服务,而每天可能要更新部署超过一千次。流服务媒体奈飞(Netflix)有超过600个(微)服务,每天也需要部署高达100多次 [1]。而云原生的重要性就在于把原本只有在本地上才可行的敏捷开发拓展到云上,从而支持海量运算的快速开发,这样也才能保证数据量巨大的应用(比如微信)不需要离线测试和更新。
云原生有很多优点。首先它继承了传统云服务的优点,着重于向外扩展而不是增大资源投放 。举个简单的例子,传统的开发会找一个机器,然后让它专门负责一个任务,而随着任务的拓展给它补充更多的资源(scale up)。但坏处很明显,就是当这个机器出了问题以后整个任务就会下线。而云原生走的是向外扩展的思路(scale out),也就是说它虚拟出多个机器来共同完成任务,而任意一台机器的鼓掌不影响整体的运营。因此它可以很轻易的提升服务的扩展性,比如一个APP从服务1000人到2000人可能只需要加一个虚拟机即可,不容易遇到上限。
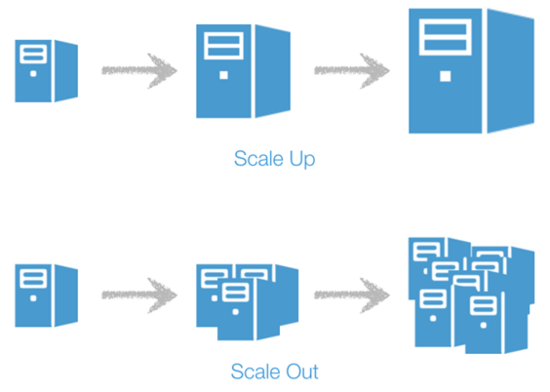
上图:资源扩展(scale up); 下图:云原生所采取的向外扩展(scale out)
其次云原生的另一个特点是着重微服务(microservice)和容器(container)来提高开发便捷性 。简单来说,一个负责的系统可以被拆解为多个独立但可以被组合的模块(微服务),那么开发新的功能就只需要增加新的小模块并与现有的组合。当我们部署这样的新功能时,可以把打包好的功能放到统一的容器里。在这种情况下,我们无需每次重新处理所有的微服务,而可以敏捷的进行替换和升级,简单理解就像是充电电池。我们可以给每个电池单独充电(类比微服务升级),充好电之后(微服务升级好了),即插即用替换现有的微服务即可。比如一款社交软件如何给用户推送内容,可能就是一个微服务,它改变推送策略一般是把这个部分拿出来做升级与AB测试,再逐步在云上替换掉所有用户的推荐系统。因为云原生采用的是向外扩展,这样可以对用户进行独立或者有对比的升级,不会造成任何服务的中断。
而在这些抽象的概念以外,其实原生云大数据从2013年被首次提出已经逐步的被应用到了越来越多的商业案例里 。国外的微软在这个上面做的一直很好,而国内的话腾讯云发起了首个原生大数据的生态,也有很多用原生云大数据赋能产品的案例。
以微信来说,它们正在使用腾讯云的原生云设计来进行数据挖掘和分析。其实不难想象微信的数据量有多大,毕竟月活超过十亿。因此在这样的海量用户场景下,很容易产生庞大的数据量进行分析,尤其是在整合多种用户信息时需要大量时间,往往准备数据就需要数个小时甚至以天来计算,以前的AB 测试的滞后性比较明显。而近水楼台先得月,微信现在用腾讯云的云数据仓库来处理这样的数据,最大的优势就是把数据量的吞吐、储存和挖掘问题转移到了腾讯云,每秒可以吞吐10亿+的数据。而微信的工程师只需要通过业务需求进行具体的分析和开发,避免了把大量的时间放在等待上的问题。所以原生云大数据平台的核心目的就是把储存和开发中因为数据量造成的问题解决,而只把开发和分析问题留给使用者。
作为一套系统完整的解决方案,云原生大数据的重要组件有「大数据的基础引擎」,用来保存、仓储和调用数据,而在数据之上更重要的是「数据开发与治理」,即怎么从数据中挖掘有用的信息。当然再上层还可以集成各种商业可视化面板,从而更简单的进行分析。而在这些系统的统筹下,原生云平台可以支持各种重要的场景和应用。
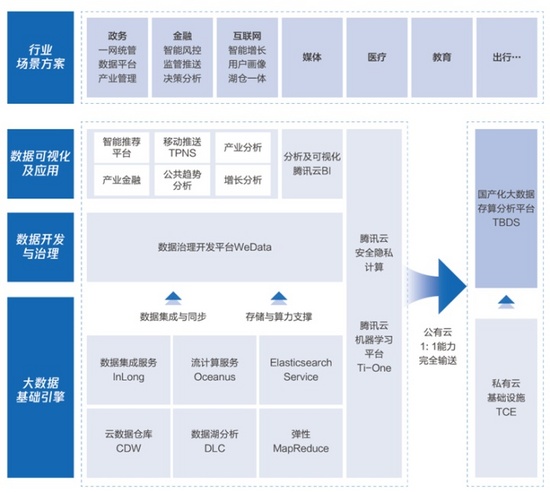
腾讯云大数据架构
我个人认为在这一整套架构中,最重要的部分就是底层的「大数据引擎」和中层的「数据开发与治理」, 非常考察技术。而更难的是怎么有机的把这些技术模块结合起来。
在腾讯云的大数据引擎里,我个人觉得最有意思的是数据湖分析(DLC)和云数据仓库(CDW)。先说数据湖分析DLC。和传统的数据库不同,数据湖(data lake)可以支持更大的数据存储,它不仅可以支持保存关系数据库(relational database),还可以保存半结构化的数据,比如CSV,JSON和XML等,甚至包括非结构性的数据,像是PDF、文档、图片,音视频等。数据湖的出现让我们有了一个统一的地方来储存数据。 简单来说,数据湖的出现避免了各个数据库的孤立问题,为数据整合提供了一站式的地点 。腾讯云的DLC提供数据湖的数据分析因此也提供了:(1)从多个数据库进行联合查询(2)serverless的架构使得使用者无需关注底层架构,可以直接用SQL语句进行处理。数据湖分析的场景非常适合游戏开发和迭代,比如可以进行网络游戏的运营和应力分析,我们可以通过DLC把用户的游戏日志和购买习惯等各种不同格式的数据拿到数据湖中,进行统一分析,从而最大化盈利。其中很有代表性的案例包括B站,可以通过游戏运营日志指标实时分析来为企业获得更大的价值。
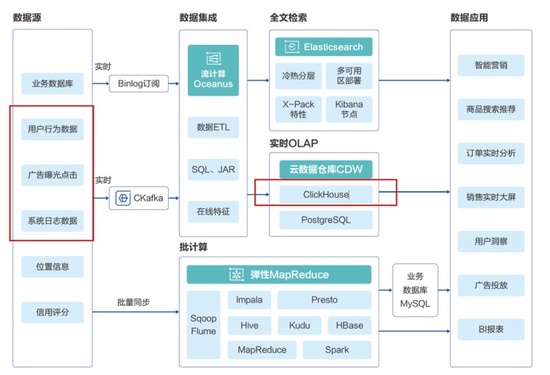
而云数据仓库(CDW)的目标主要是整合大数据(尤其是宽表类数据),从而进行统一分析 。以腾讯的云数据仓库ClickHouse为例,它的主要目的是在短时间内对于复杂的用户特征进行分析,也就是我们常说的”大宽表”。即每个用户可能在网络上产生了个各种特征,比如购买习惯比如搜索习惯的,因此当我们把大量数据的行为整合起来,就会形成一个巨大的表格,不仅长度可能有上亿行,宽度上可能也成千上万(各种行为特征)。因此Clickhouse提供的就是一个开箱即用可扩展的数据整合工具。以下图为例,大部分电商和营销类企业都可以简单的使用Clickhouse进行数据整合,从而筛选符合特征的用户,并把数据喂到下一步的数据应用里进行实时订单分析或者精准营销。
以腾讯云的「数据开发与治理」平台WeData为例 ,它的核心特色就在于云上的敏捷化开发和一体化操作。我们前面讲了云原生大数据的一个重要就是需要敏捷化开发,可以根据数据的反馈即时进行修正和部署,从需求、开发和部署的过程需要非常快速,这也是现在新的概念叫做DataOps。而WeData的重要创新就是支持协同开发,这个可以通多IDE和内置的DAG实现,而多人协作时一个很有用的功能就是数据可视化,这样避免代码层面的冲突。WeData因此在打通下游大数据引擎的前提下,同时支持快速的开发、迭代与部署。
而在数据治理层面,另一个重点是安全性 。WeData在多人协作时可以精细化的控制每个人可以接触到的数据,从而防止有数据泄露的安全问题。敏捷性不代表我们应该在开发中牺牲安全性。
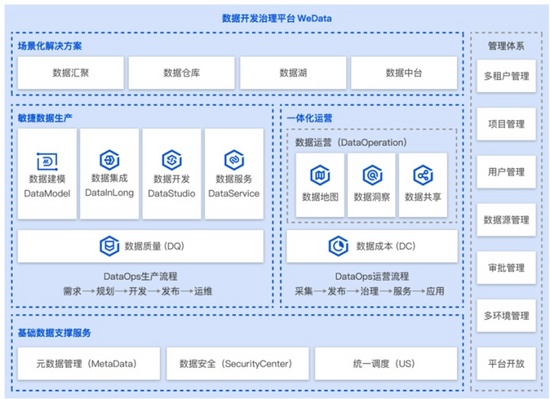
WeData数据开发治理平台
而结合这些引擎和处理系统,云原生大数据确实已经被应用到了我们生活当中 。除了前文提到的知乎、微信、B站等,大部分我们熟悉的行业其实都已经用上了云原生的技术。比如金融行业包括证券和银行,它们利用云服务,比如腾讯云,把多个渠道的用户信息汇总,并在海量的数据里挖掘欺诈与洗钱,或是开设智能的风控与理赔。又或是教育行业,它们会利用原生云完成从个性化学习内容推荐,智能测评与批改,到实时对学员表现进行分析的全链条支持。虽然有些功能对于小企业在本地也可以完成,但云原生的特性就是可以随着用户数的上升弹性扩容,提供一样便捷的数据储存和分析。
因此云原生大数据确实是技术发展上不可阻挡的趋势 。而随着我们每天产生数据量的继续的飞速增加,未来它的使用场景还会进一步拓展。人类现在每年产生的数据已经是前十几年的总和,而随着越来越多的数据产生,我们也会从中有更多对自己和社会的理解,而更好的云服务和技术将会是其中重要的一环。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK