

faster ml inference with AWS graviton3 - Infrastructure Solutions blog - Arm Com...
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/machine-learning-inference-on-aws-graviton3
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Machine Learning (ML) is one of the fastest growing segments within cloud and edge infrastructure. Within ML, deep learning inference is expected to grow even faster.
In this blog, we compare the ML inference performance of three Amazon Web Services (AWS) EC2 cloud instance types when running two common FP32 ML models. We will cover the quantized inference (INT8) performance in a future blog.
Workloads
Representative ML workloads are provided by MLCommons in their MLPerf Inference benchmark suite. MLCommons is an open engineering consortium to enable and improve the machine learning industry through benchmarks, metrics, datasets, and best practices.
In this analysis we ran the benchmark models for two widely used ML use-cases, image classification and language processing:
| Area | Task | Model |
| Vision | Image Classification | Resnet50-v1.5 |
| Language | Natural Language Processing | BERT-Large |
Platforms
We ran on three AWS EC2 cloud instance types, covering two generations of Arm Neoverse cores (Arm Neoverse N1 and V1) and the latest Intel Xeon CPU (3rd generation Intel Xeon Scalable Processor).
| AWS Instance Type | CPU | Configuration |
| c6g | Arm Neoverse N1 | 4xlarge (16-vCPU) |
| c7g | Arm Neoverse V1 | 4xlarge (16-vCPU) |
| c6i | 3rd generation Intel Xeon Scalable Processor | 4xlarge (16-vCPU) |
Performance Features of AWS Graviton3 (c7g) vs AWS Graviton2 (c6g)
AWS Graviton3 (c7g) introduces the Arm Neoverse V1 CPU, which brings two major ML-related upgrades compared with the Arm Neoverse N1 in AWS Graviton2 (c6g): (1) BFloat16 support; and (2) wider vector units
BFloat16 support
BFloat16, or BF16, is a 16-bit floating-point storage format, with one sign bit, eight exponent bits, and seven mantissa bits. It has the same number of exponent bits as the industry-standard IEEE 32-bit floating point format but has lower precision.
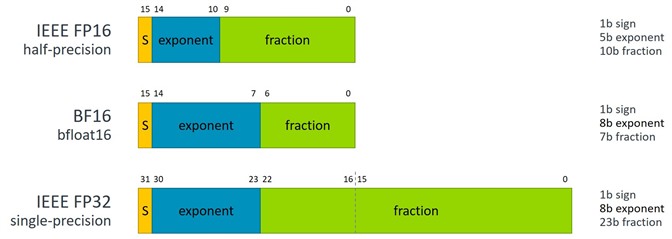
Figure 1: A comparison of BFloat16 with IEEE 754 single- and half-precision.
BF16 is well suited to accelerate deep learning matrix multiplication operations, where multiplications are done using the BF16 floating-point number format and accumulation using 32-bit IEEE floating point.
Arm introduced new BF16 instructions in the 2019 Arm architecture update to improve ML training and inference workload performance. Neoverse V1 is the first Neoverse core to support these BF16 instructions.
Wider vector units
Neoverse V1 also has wider vector units, with two 256-bit SVE units per core compared to two 128-bit NEON units in the case of Neoverse N1.
Software stack
For all platforms, we have used TensorFlow v2.9.1 packages.
TensorFlow software stack on Arm
TensorFlow package on Arm supports two different backends – the Eigen backend (enabled by default) and the faster oneDNN backend.
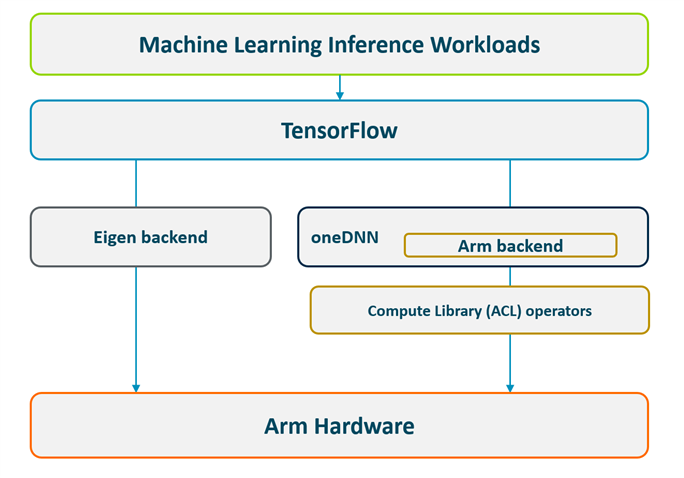
Figure 2: TensorFlow software stack on Arm with two backends (Eigen and oneDNN/ACL).
oneAPI Deep Neural Network Library (oneDNN) is an open-source cross-platform performance library of basic building blocks for deep learning applications. Formerly known as MKL-DNN, the library has been integrated with TensorFlow, PyTorch, and other frameworks. Compute Library (ACL) is an Arm optimized library with over 100 optimized machine learning functions including multiple convolution algorithms. Arm has integrated ACL with oneDNN so that frameworks can run faster on Arm cores.
We have used the TensorFlow v2.9.1 package built by AWS (https://pypi.org/project/tensorflow-cpu-aws/) for this benchmarking. We have set two additional environment variables (1) to enable oneDNN (TF_ENABLE_ONEDNN_OPTS=1) and (2) to use BF16 to accelerate FP32 model inference (ONEDNN_DEFAULT_FPMATH_MODE=BF16).
For future releases (starting version 2.10), AWS, Arm, Linaro and Google are working together to make the TensorFlow package available for Arm via https://pypi.org/project/tensorflow.
TensorFlow software stack on x86
For x86, we have used the official TensorFlow v2.9.1 package (https://pypi.org/project/tensorflow/), in which oneDNN is used by default.
Performance Comparison of AWS Graviton3 (c7g) vs AWS Graviton2 (c6g)
With wider vector units and new BF16 instructions, the Neoverse-V1 in AWS Graviton3 (c7g) further improves the ML performance compared to the Neoverse-N1 in AWS Graviton2 (c6g).
In the graphs below, we see that AWS c7g (with Neoverse-V1) outperforms AWS c6g (with Neoverse-N1) by 2.2x for RESNET-50 and by 2.4x for BERT-Large for real-time inference performance.
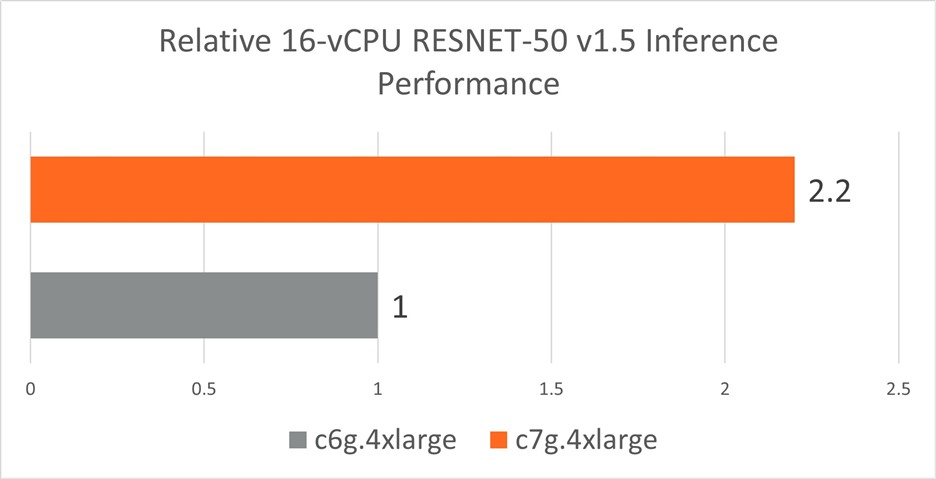
Figure 3: Resnet-50 v1.5 real-time inference performance (Batch Size = 1) achieved by a c7g.4xlarge instance cluster with AWS Graviton3 processors and by a c6g.4xlarge instance cluster with AWS Graviton2 processors. Higher is better.
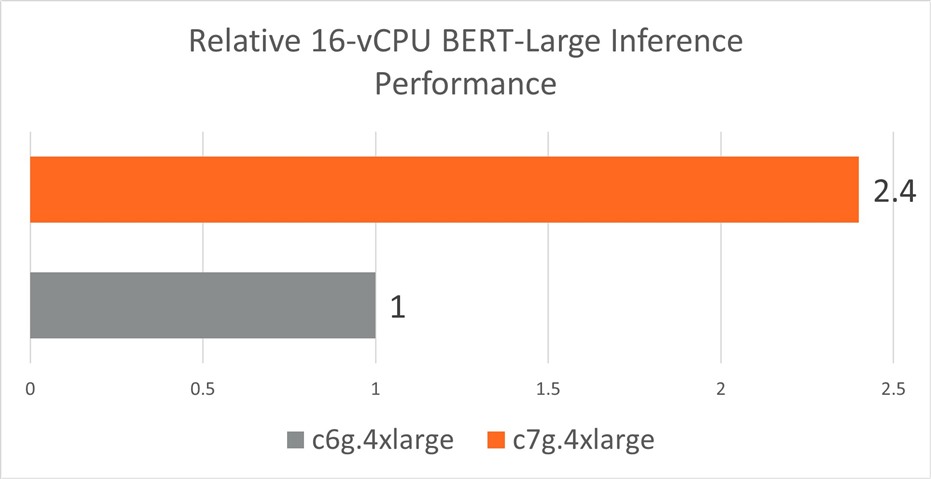
Figure 4: BERT-Large real-time inference performance achieved by a c7g.4xlarge instance cluster with AWS Graviton3 processors and by a c6g.4xlarge instance cluster with AWS Graviton2 processors. Higher is better.
Performance Comparison of AWS Graviton3 (c7g) vs AWS Intel Ice Lake (c6i)
The following charts summarise the performance of AWS Graviton3 (c7g) vs AWS Intel Ice Lake (c6i) platforms.
In summary, AWS c7g (based on Arm Neoverse V1) outperforms c6i (based on Intel Ice Lake x86) by 1.8x for BERT-Large and by 1.3x for RESNET-50 FP32 models. This is mainly due to the availability of BF16 instructions in c7g, which are missing in the current c6i generation.
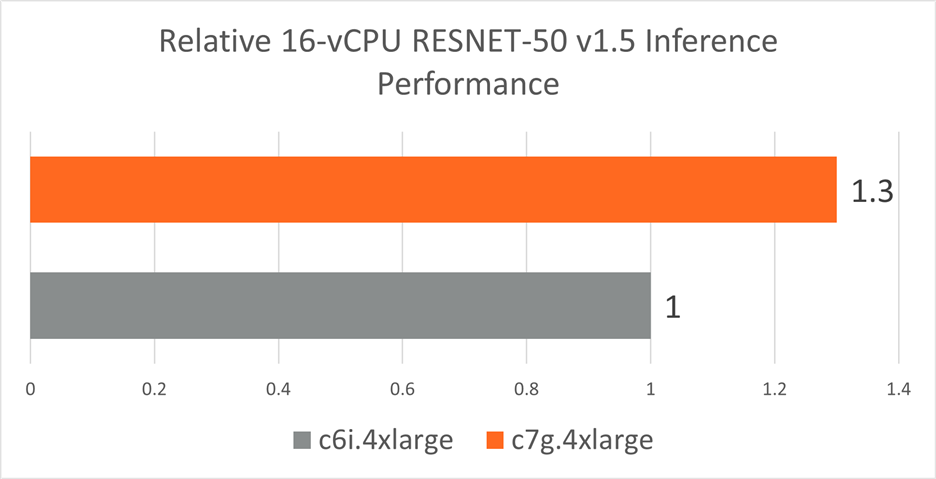
Figure 5: Resnet-50 v1.5 real-time inference performance (Batch Size = 1) achieved by a c7g.4xlarge instance cluster with AWS Graviton3 processors and by a c6i.4xlarge instance cluster with 3rd Gen Intel Xeon Scalable processors. Higher is better.
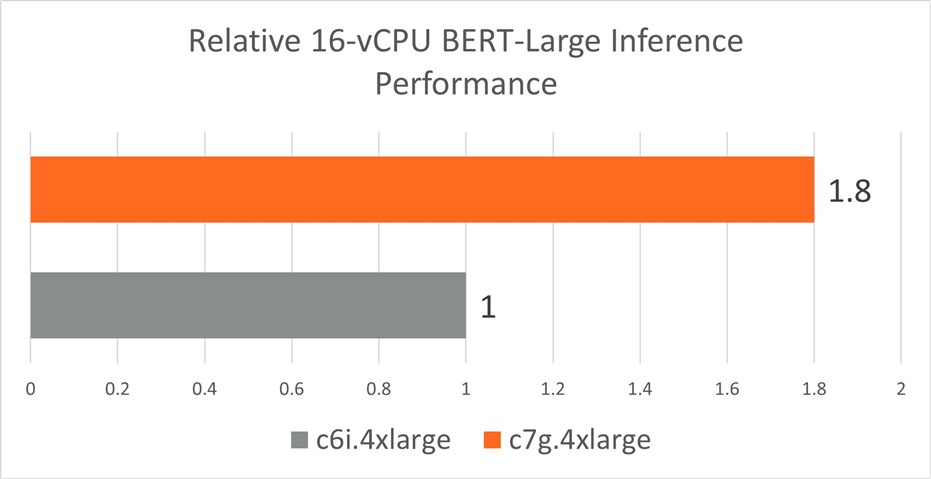
Figure 6: BERT-Large real-time inference performance achieved by a c7g.4xlarge instance cluster with AWS Graviton3 processors and by a c6i.4xlarge instance cluster with 3rd Gen Intel Xeon Scalable processors. Higher is better.
Conclusion
Our MLPerf BERT-large and Resnet50-v1.5 benchmark analysis shows that Amazon EC2 c7g instances (using Arm Neoverse V1 CPU) perform up to 1.8x faster than Amazon EC2 c6i instances (using Intel Ice Lake CPU) and up to 2.4x faster than Amazon EC2 c6g instances (using Arm Neoverse N1 CPU).
This is due to a combination of improved hardware features in Neoverse V1 (new BF16 instructions and wider vector units) and an improved software stack (wherein ACL accelerates FP32 ML operations using BF16). By running FP32 ML model inference on Graviton3-based instances, consumers benefit further from the lower price-per-hour offered compared to x86-architecture instances.
Visit the AWS Graviton Getting Started page for further instructions. For any queries related to your software workloads running on Arm Neoverse platforms, feel free to reach out to us at [email protected].
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK