

k8s-Pod调度 - 顶风少年
source link: https://www.cnblogs.com/zumengjie/p/16617978.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Deployment全自动调度
NodeSelector定向调度
NodeAffinity亲和性
PodAffinity-Pod亲和性与互斥性
污点和容忍度
DaemonSet
Job
CronJob
Deployment升级策略
Deployment回滚
Deployment暂停和恢复
DeamonSet的更新策略
Pod的扩缩容
Deployment全自动调度
声明Deployment后,通过筛选标签对匹配的pod做副本控制。Deployment会创建一个RS和replicas个pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3 #副本数
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
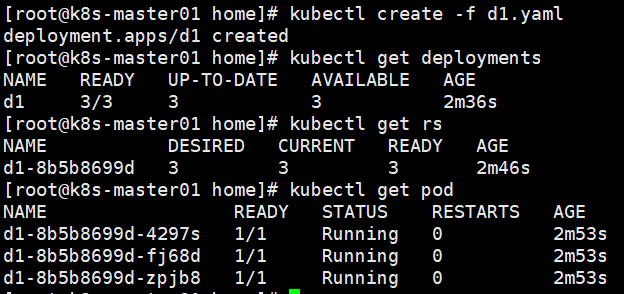
删除pod后会自动创建新的。
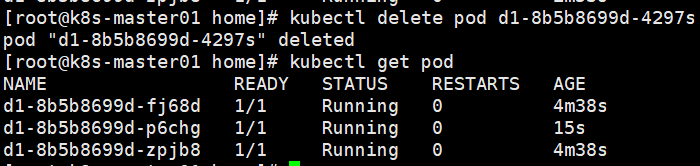
删除Deployment后会关联删除RS和Pod,无法单独删除RS。
NodeSelector定向调度
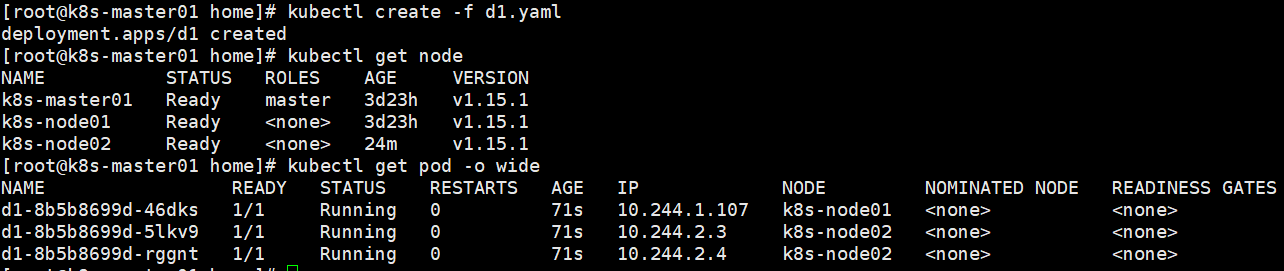
从调度策略上来说,这三个pod由系统全自动完成调度,他们各自运行在哪个node节点,完全由master的scheduler经过一系列算法计算得出,用户无法干预调度过程和结果。1个被调度到了node1两个被调度到了node2。
在实际情况下,也可能需要将pod调度到指定节点上,可以通过给node打标签,和pod的nodeselector属性匹配,来达到定向调度的目的。
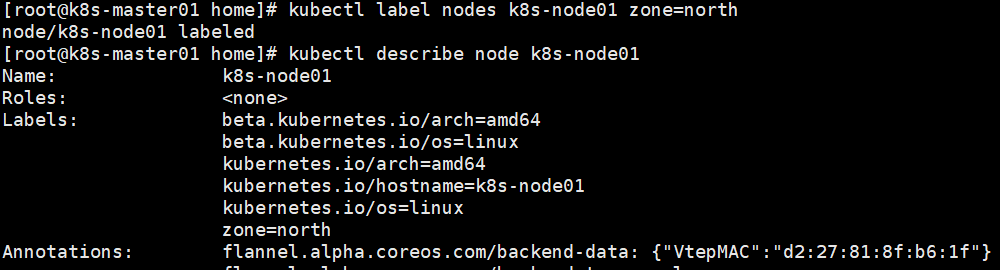
给node添加标签:kubectl label nodes nodename key=value
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
nodeSelector:
zone: north

pod全部调度到了node01上。注意如果pod使用了nodeselector但是没有匹配的node,则pod不会被创建。
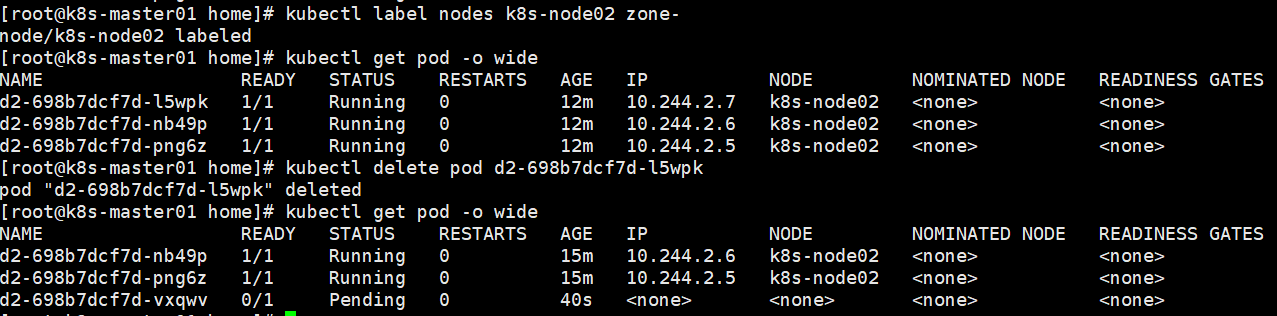
删除node标签:kubectl label nodes nodename key-
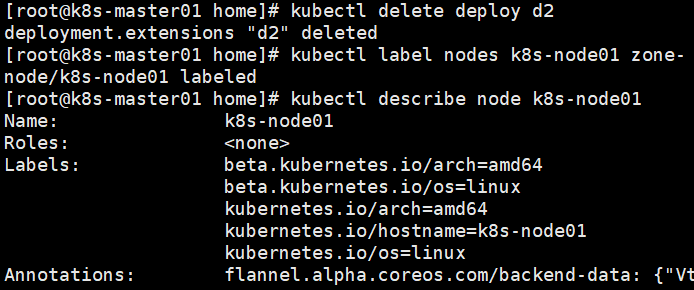
创建deployment后发现pod一直在被创建中。
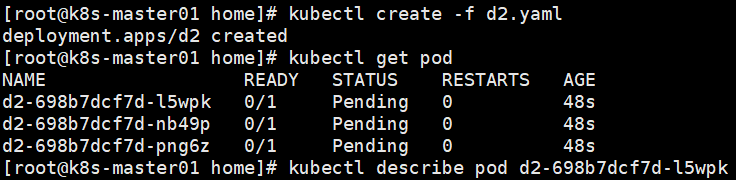
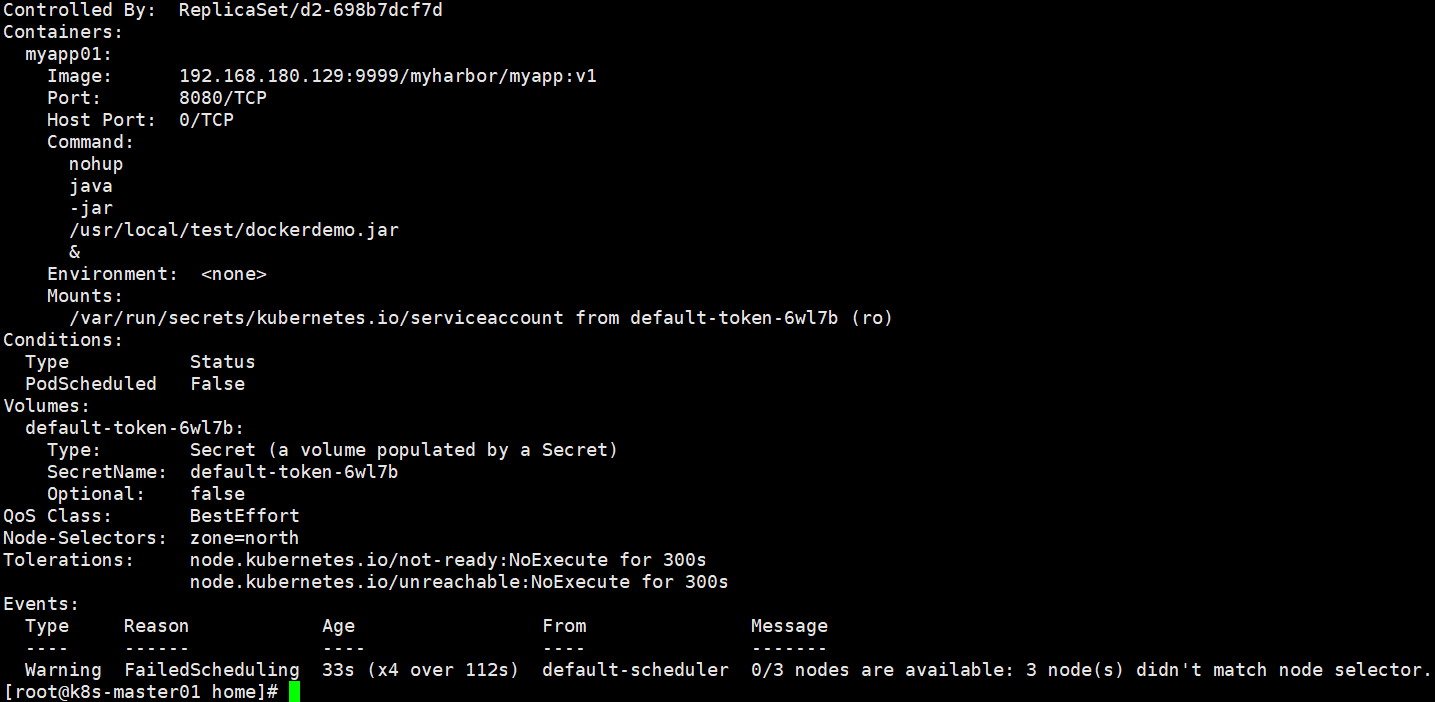
通过查看其中一个pod发现错误信息

给node添加上对应标签后,pod又自动创建了。
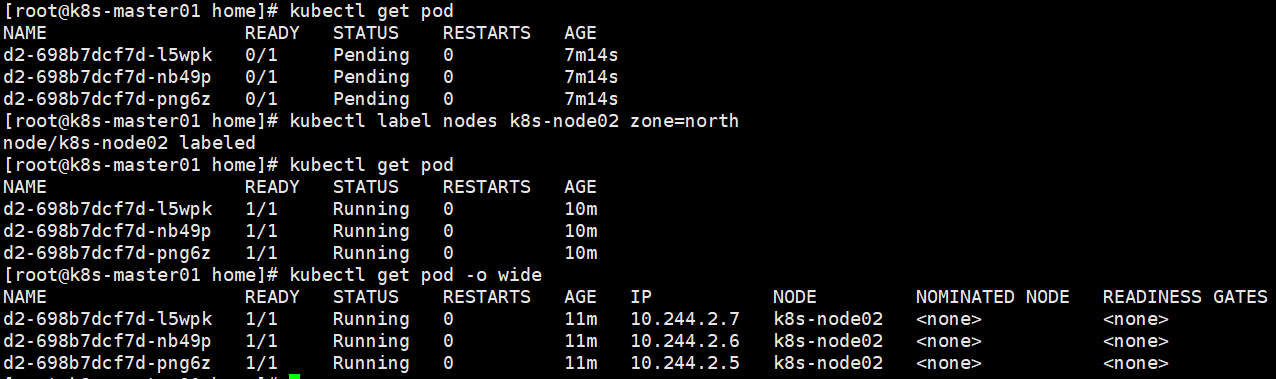
在pod创建后,删除node标签,pod正常运行。

但是如果pod被删除后,RS重新创建pod会失败。
如果同时给多个node打上匹配的标签,则也会调度到不同的pod上。

NodeAffinity亲和性
requiredDuringSchedulingIgnoredDuringExecution
表示pod必须部署到满足条件的节点上,如果没有满足条件的节点,就不停重试。其中IgnoreDuringExecution表示pod部署之后运行的时候,如果节点标签发生了变化,不再满足pod指定的条件,pod也会继续运行。
kubectl label node k8s-node02 disktype=ssd
kubectl get node --show-labels
在k8s02上打上disktype=ssd标签,然后pod选择策略指定label中包含 disktype=ssd,三个节点都调度到了k8s-node02

apiVersion: apps/v1
kind: Deployment
metadata:
name: d3
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In # In: label的值在某个列表中 NotIn:label的值不在某个列表中 Exists:某个label存在 DoesNotExist:某个label不存在 Gt:label的值大于某个值(字符串比较) Lt:label的值小于某个值(字符串比较)
values:
- ssd

如果operator修改为 NotIn则3个pod都会调度到k8s-node01上。

preferredDuringSchedulingIgnoredDuringExecution
表示优先部署到满足条件的节点上,如果没有满足条件的节点,就忽略这些条件,按照正常逻辑部署。
删除掉node02上的disktype标签后,没有满足affiinity的但是还是被调度到了。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d4
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: NotIn # In: label的值在某个列表中 NotIn:label的值不在某个列表中 Exists:某个label存在 DoesNotExist:某个label不存在 Gt:label的值大于某个值(字符串比较) Lt:label的值小于某个值(字符串比较)
values:
- ssd
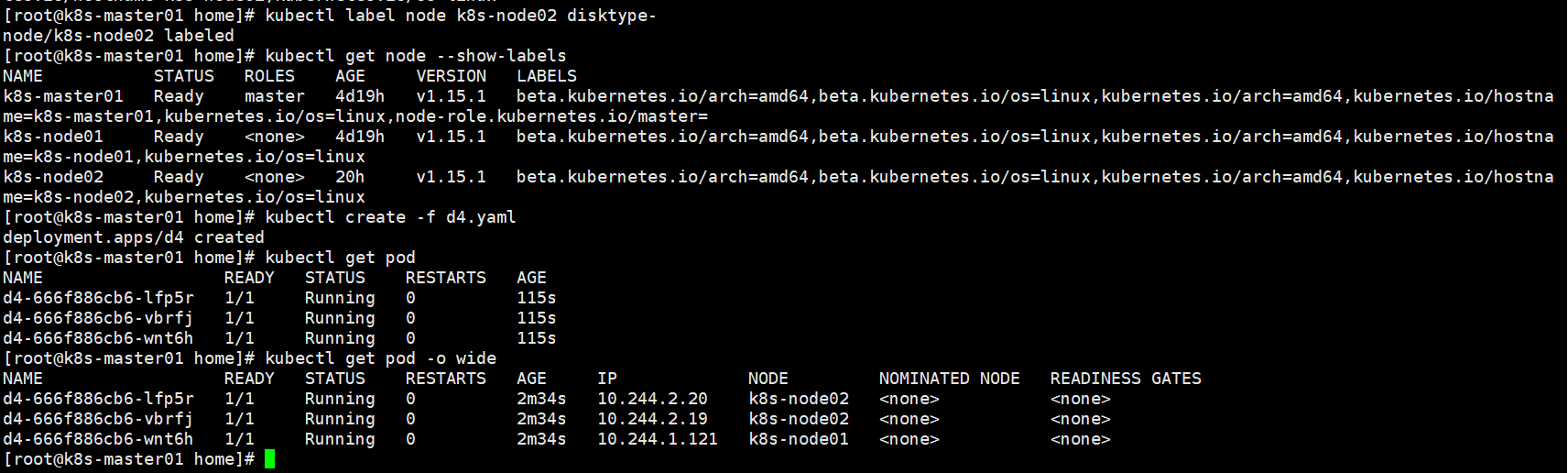
权重的值在1-100之间,看这个结果,越大权重越大。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d5
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In # In: label的值在某个列表中 NotIn:label的值不在某个列表中 Exists:某个label存在 DoesNotExist:某个label不存在 Gt:label的值大于某个值(字符串比较) Lt:label的值小于某个值(字符串比较)
values:
- ssd1
- weight: 100
preference:
matchExpressions:
- key: disktype
operator: In # In: label的值在某个列表中 NotIn:label的值不在某个列表中 Exists:某个label存在 DoesNotExist:某个label不存在 Gt:label的值大于某个值(字符串比较) Lt:label的值小于某个值(字符串比较)
values:
- ssd2
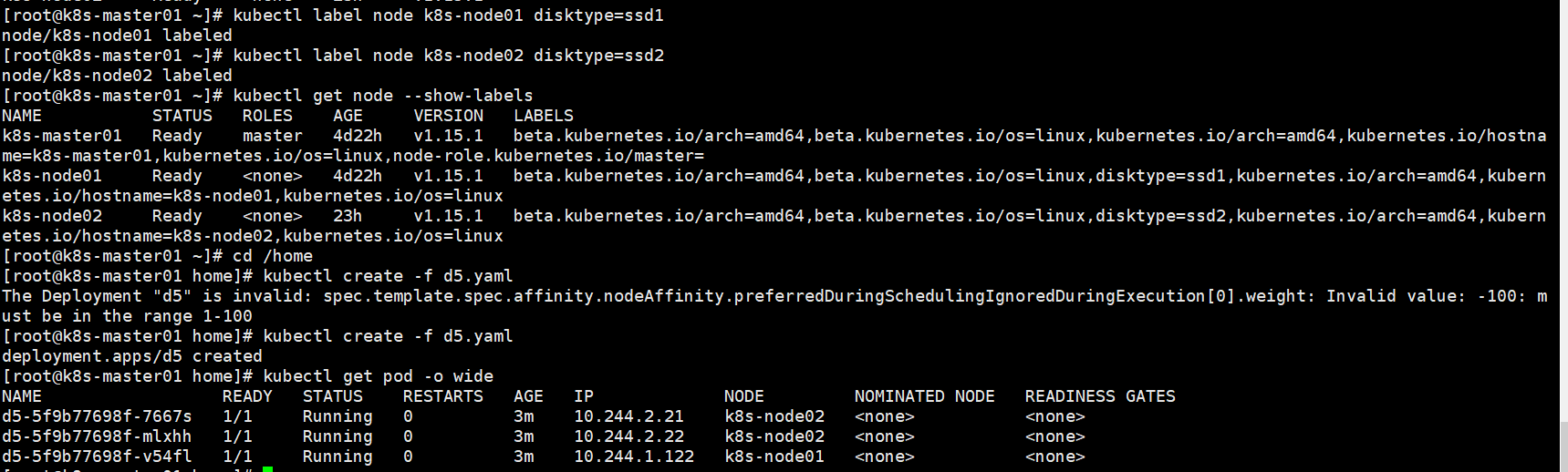
如果你同时指定了 nodeSelector 和 nodeAffinity,两者 必须都要满足, 才能将 Pod 调度到候选节点上。
如果你指定了多个与 nodeAffinity 类型关联的 nodeSelectorTerms, 只要其中一个 nodeSelectorTerms 满足的话,Pod 就可以被调度到节点上。
如果你指定了多个与同一 nodeSelectorTerms 关联的 matchExpressions, 则只有当所有 matchExpressions 都满足时 Pod 才可以被调度到节点上。
PodAffinity-Pod亲和性与互斥性
创建一个测试节点,一个pod被分到了node01。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d6
spec:
selector:
matchLabels:
security: s1 #Deployment会控制label相同的pod
replicas: 1
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
security: s1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]

podAffinity
亲和性,会尽力与具有指定标签的pod调度到同一个node上。下边例子,app:v1与security:s1亲和
apiVersion: apps/v1
kind: Deployment
metadata:
name: d7
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In # In: label的值在某个列表中 NotIn:label的值不在某个列表中 Exists:某个label存在 DoesNotExist:某个label不存在 Gt:label的值大于某个值(字符串比较) Lt:label的值小于某个值(字符串比较)
values:
- s1
topologyKey: kubernetes.io/hostname

podAntiAffinity
互斥性,对具有指定标签的pod有互斥性,拒绝放到一个node上。下边例子,app:v2与security:s1互斥
apiVersion: apps/v1
kind: Deployment
metadata:
name: d8
spec:
selector:
matchLabels:
app: v2 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v2
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In # In: label的值在某个列表中 NotIn:label的值不在某个列表中 Exists:某个label存在 DoesNotExist:某个label不存在 Gt:label的值大于某个值(字符串比较) Lt:label的值小于某个值(字符串比较)
values:
- s1
topologyKey: kubernetes.io/hostname

污点和容忍度
给node01添加污点 taint0=taint00:NoSchedule 给node02添加污点 taint2-taint22:NoSchedule
kubectl taint nodes k8s-node01 taint0=taint00:NoSchedule
kubectl taint nodes k8s-node02 taint2=taint22:NoSchedule

[root@k8s-master01 ~]# kubectl describe node k8s-node01
Name: k8s-node01
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
disktype=ssd1
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-node01
kubernetes.io/os=linux
Annotations: flannel.alpha.coreos.com/backend-data: {"VtepMAC":"16:30:be:e9:46:bb"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 192.168.180.130
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sat, 20 Aug 2022 22:07:32 +0800
Taints: taint0=taint00:NoSchedule
Unschedulable: false
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 25 Aug 2022 15:38:42 +0800 Thu, 25 Aug 2022 15:38:42 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure False Fri, 26 Aug 2022 10:52:04 +0800 Sat, 20 Aug 2022 22:07:32 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Fri, 26 Aug 2022 10:52:04 +0800 Sat, 20 Aug 2022 22:07:32 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Fri, 26 Aug 2022 10:52:04 +0800 Sat, 20 Aug 2022 22:07:32 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Fri, 26 Aug 2022 10:52:04 +0800 Sat, 20 Aug 2022 22:07:42 +0800 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 192.168.180.130
Hostname: k8s-node01
Capacity:
cpu: 1
ephemeral-storage: 17394Mi
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 995676Ki
pods: 110
Allocatable:
cpu: 1
ephemeral-storage: 16415037823
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 893276Ki
pods: 110
System Info:
Machine ID: f914368afc1643a4a6fda29f9b7d4da1
System UUID: ABE14D56-5112-0934-DFE1-70325811365B
Boot ID: c064f3ee-6080-40a7-8273-ee9b605a0adb
Kernel Version: 3.10.0-1160.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://20.10.17
Kubelet Version: v1.15.1
Kube-Proxy Version: v1.15.1
PodCIDR: 10.244.1.0/24
Non-terminated Pods: (2 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system kube-flannel-ds-amd64-jsn6j 100m (10%) 100m (10%) 50Mi (5%) 50Mi (5%) 5d12h
kube-system kube-proxy-l89l8 0 (0%) 0 (0%) 0 (0%) 0 (0%) 5d12h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 100m (10%) 100m (10%)
memory 50Mi (5%) 50Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
Events: <none>
[root@k8s-master01 ~]# kubectl describe node k8s-node02
Name: k8s-node02
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
disktype=ssd2
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-node02
kubernetes.io/os=linux
Annotations: flannel.alpha.coreos.com/backend-data: {"VtepMAC":"b2:58:6a:57:86:15"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 192.168.180.131
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Wed, 24 Aug 2022 20:50:34 +0800
Taints: taint2=taint22:NoSchedule
Unschedulable: false
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Thu, 25 Aug 2022 15:38:43 +0800 Thu, 25 Aug 2022 15:38:43 +0800 FlannelIsUp Flannel is running on this node
MemoryPressure False Fri, 26 Aug 2022 10:55:57 +0800 Wed, 24 Aug 2022 20:50:34 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Fri, 26 Aug 2022 10:55:57 +0800 Wed, 24 Aug 2022 20:50:34 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Fri, 26 Aug 2022 10:55:57 +0800 Wed, 24 Aug 2022 20:50:34 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Fri, 26 Aug 2022 10:55:57 +0800 Wed, 24 Aug 2022 20:50:44 +0800 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 192.168.180.131
Hostname: k8s-node02
Capacity:
cpu: 1
ephemeral-storage: 17394Mi
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 995676Ki
pods: 110
Allocatable:
cpu: 1
ephemeral-storage: 16415037823
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 893276Ki
pods: 110
System Info:
Machine ID: f914368afc1643a4a6fda29f9b7d4da1
System UUID: CBA34D56-4220-5A92-0FEB-563F66061138
Boot ID: 376e5260-63e9-46e2-bf34-2991cecc5526
Kernel Version: 3.10.0-1160.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://20.10.17
Kubelet Version: v1.15.1
Kube-Proxy Version: v1.15.1
PodCIDR: 10.244.2.0/24
Non-terminated Pods: (2 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system kube-flannel-ds-amd64-8k8ww 100m (10%) 100m (10%) 50Mi (5%) 50Mi (5%) 38h
kube-system kube-proxy-t825f 0 (0%) 0 (0%) 0 (0%) 0 (0%) 38h
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 100m (10%) 100m (10%)
memory 50Mi (5%) 50Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
Events: <none>
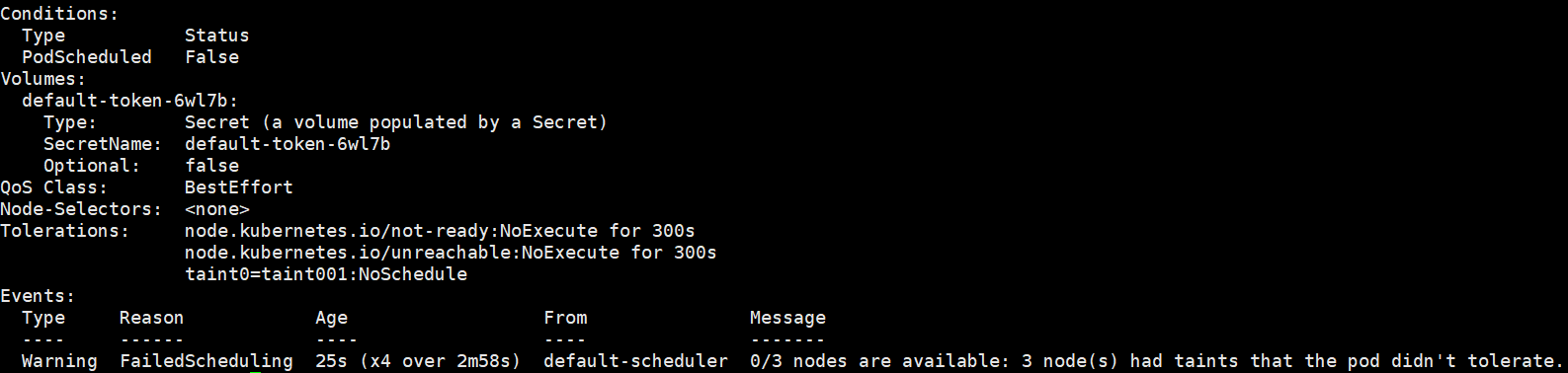
启动一个普通的pod,发现这个pod一直是Pending状态,查看事件 nodes are available: 3 node(s) had taints that the pod didn't tolerate.两个node节点都有污染标记,都不能被pod容忍。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d6
spec:
selector:
matchLabels:
security: s1 #Deployment会控制label相同的pod
replicas: 1
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
security: s1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
[root@k8s-master01 home]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
d6-5cfddfb4fd-ffblh 0/1 Pending 0 2m <none> <none> <none> <none>
[root@k8s-master01 home]# kubectl describe pod d6-5cfddfb4fd-ffblh
Name: d6-5cfddfb4fd-ffblh
Namespace: default
Priority: 0
Node: <none>
Labels: pod-template-hash=5cfddfb4fd
security=s1
Annotations: <none>
Status: Pending
IP:
Controlled By: ReplicaSet/d6-5cfddfb4fd
Containers:
myapp01:
Image: 192.168.180.129:9999/myharbor/myapp:v1
Port: 8080/TCP
Host Port: 0/TCP
Command:
nohup
java
-jar
/usr/local/test/dockerdemo.jar
&
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-6wl7b (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
default-token-6wl7b:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-6wl7b
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 76s (x2 over 2m21s) default-scheduler 0/3 nodes are available: 3 node(s) had taints that the pod didn't tolerate.
创建一个可以容忍taint0=taint00:NoSchedule的pod,node01上有这个污点,所以pod都调度到了node01
apiVersion: apps/v1
kind: Deployment
metadata:
name: d9
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
tolerations:
- key: taint0
operator: Equal
value: taint00
effect: NoSchedule

operator:Equal
那么key和value都需要匹配node的taint,下面这个例子,value没有匹配则调度失败。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d9
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
tolerations:
- key: taint0
operator: Equal
value: taint001
effect: NoSchedule

operator:Exists
则表示不匹配value。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d9
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
tolerations:
- key: taint0
operator: Exists
effect: NoSchedule

删除node污点
kubectl taint nodes k8s-node01 taint0=taint00:NoSchedule-
kubectl taint nodes k8s-node02 taint2=taint22:NoSchedule-
PreferNoSchedule
更改污点类型为node污点类型,pod的容忍类型也修改为PreferNoSchedule虽然没有一个node可以匹配,但是还是可以成功调度。

apiVersion: apps/v1
kind: Deployment
metadata:
name: d9
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
tolerations:
- key: taint33
operator: Exists
effect: PreferNoSchedule

NoExecute
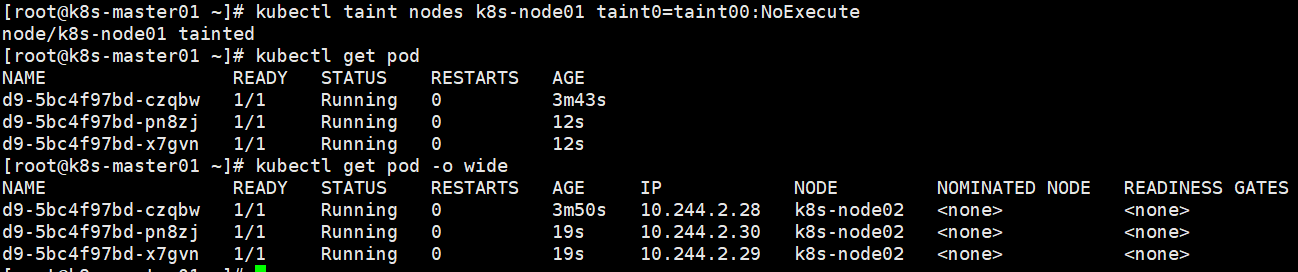
驱逐节点,看下面的情况,先创建三个pod,两个被分配到了node01。

apiVersion: apps/v1
kind: Deployment
metadata:
name: d9
spec:
selector:
matchLabels:
app: v1 #Deployment会控制label相同的pod
replicas: 3
template: # pod 的模板,Deployment通过这个模板创建pod
metadata:
labels:
app: v1
#name: poddemo1 #不能在设置pod名称了,多个副本的情况下不能重名,会由自动生成
spec:
#restartPolicy: Always #deployment需要控制副本数量,所以重启策略必须是Always,默认也是Always,所以可以不写。
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
tolerations:
- key: taint33
operator: Exists
effect: NoExecute
tolerationSeconds: 60
现在两个node都没有设置任何的污点,然后将node01的污点类型修改为NoExecute,发现三个pod都被驱逐出了node01,调度到了node02下,因为node02没有任何的污点。tolerationSeconds是在node01上还能待的时间单位秒。
DaemonSet
DaemonSet确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet支持NodeSelector,NodeAffinity来指定满足条件的Node范围进行调度,也支持Taints和Tolerations。
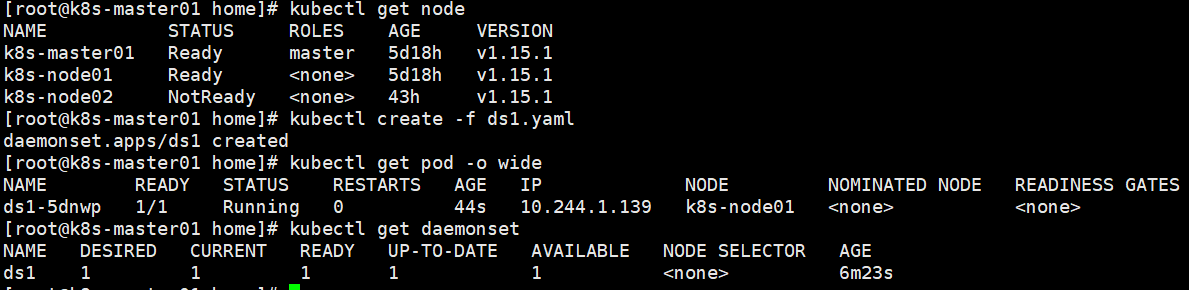
以下案例只有先启动了一个node,创建daemonSet后,在node01创建了一个pod。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds1
spec:
selector:
matchLabels:
app: v1
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
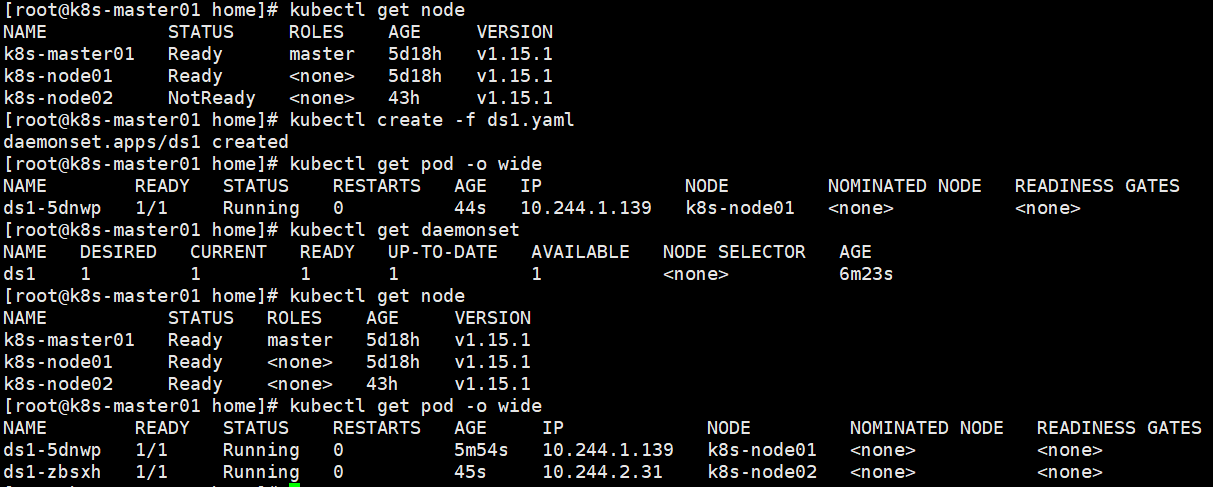
再次启动node02,无需做任何操作,node02上会自动调度一个pod。
The Job "j2" is invalid: spec.template.spec.restartPolicy: Unsupported value: "Always": supported values: "OnFailure", "Never"
restartPolicy不能设置为Always
单次Job
通常只启动一个 Pod,除非该 Pod 失败。当 Pod 成功终止时,立即视 Job 为完成状态。
apiVersion: batch/v1
kind: Job
metadata:
name: j1
spec:
template:
spec:
containers:
- name: myapp01
image: ubuntu:14.04
command: ['/bin/echo','aaabbbbbbbbbbaa']
restartPolicy: Never
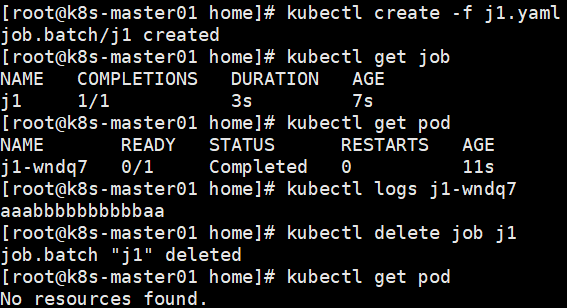
删除job会关联删除pod
多次Job
completions指定了job会创建几个pod,也就是会运行几次,是并行操作。
apiVersion: batch/v1
kind: Job
metadata:
name: j2
spec:
template:
spec:
containers:
- name: myapp01
image: ubuntu:14.04
command: ['/bin/echo','aaabbbbbbbbbbaa']
restartPolicy: Never
completions: 2

并行Job
parallelism最大并行数。completions最小完成数。
apiVersion: batch/v1
kind: Job
metadata:
name: j3
spec:
template:
spec:
containers:
- name: myapp01
image: ubuntu:14.04
command: ['/bin/echo','aaabbbbbbbbbbaa']
restartPolicy: Never
completions: 2 #成功运行的Pod个数,如果不设置,默认和parallelism
parallelism: 2 #并行运行的pod个数,parallelism默认值是1,completions默认值也是1
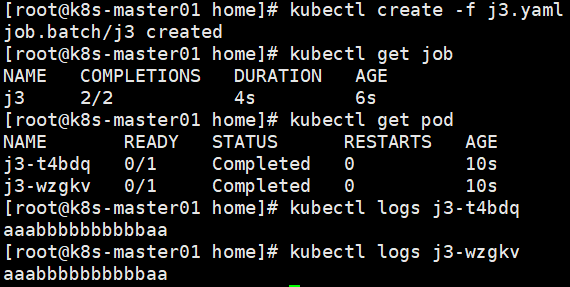
CronJob
CronJob 创建基于时隔重复调度的 Jobs CronJob 用于执行周期性的动作,例如备份、报告生成等。 这些任务中的每一个都应该配置为周期性重复的(例如:每天/每周/每月一次); 你可以定义任务开始执行的时间间隔。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cj1
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
containers:
- name: myapp01
image: ubuntu:14.04
command: ['/bin/echo','aaabbbbbbbbbbaa']
restartPolicy: Never
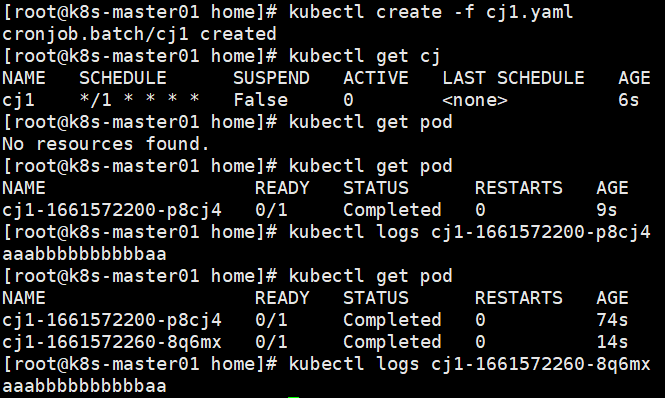
Pod升级策略
RollingUpdate
这是默认的更新方式。设置spec.strategy.type=RollingUpdate,表示Deployment会以滚动更新的方式逐个更新pod,同时可以设置spec.strategy.rollingUpdate下的两个参数maxUnavailable和maxSurge来控制滚动更新过程。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 #用于指定Deployment在更新过程中不可用状态的Pod数量的上限,可以是百分比
maxUnavailable: 1 #用于指定Deploymnet在更新Pod的过程中Pod总数量超过预期副本数量的最大值,可以是百分比
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
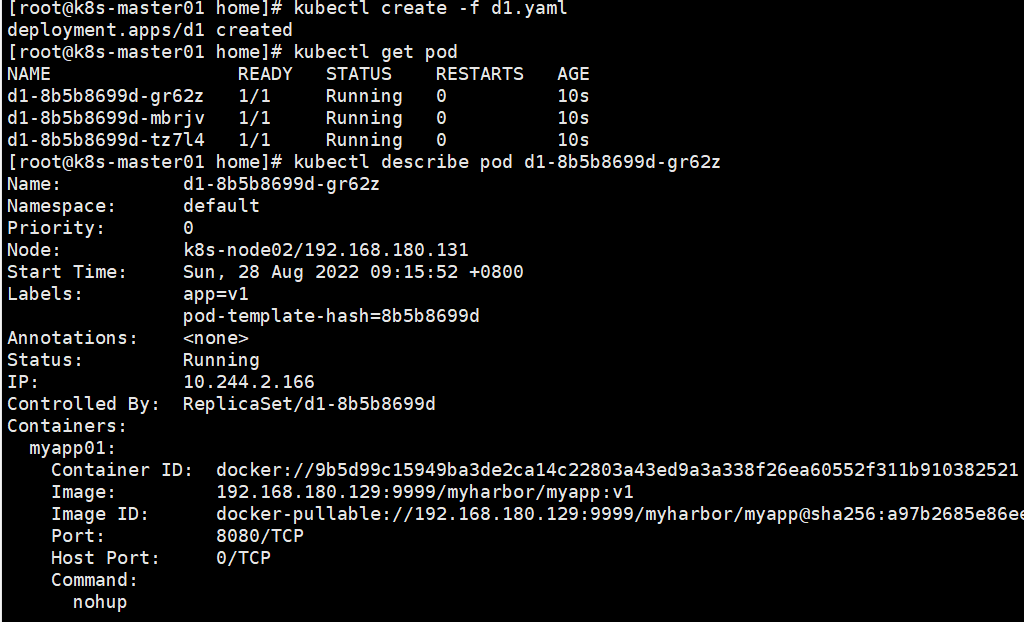
现在pod镜像需要被更新为192.168.180.129:9999/myharbor/myapp:v2通过命令更新。
kubectl set image deployment d1 myapp01=192.168.180.129:9999/myharbor/myapp:v2
[root@k8s-master01 home]# kubectl set image deployment d1 myapp01=192.168.180.129:9999/myharbor/myapp:v2
deployment.extensions/d1 image updated
[root@k8s-master01 home]# kubectl rollout status deployment d1
deployment "d1" successfully rolled out
[root@k8s-master01 home]# kubectl get pod
NAME READY STATUS RESTARTS AGE
d1-7c86978c57-cfvsj 1/1 Running 0 51s
d1-7c86978c57-dn748 1/1 Running 0 55s
d1-7c86978c57-mhtdp 1/1 Running 0 48s
[root@k8s-master01 home]# kubectl describe pod d1-7c86978c57-cfvsj
Name: d1-7c86978c57-cfvsj
Namespace: default
Priority: 0
Node: k8s-node02/192.168.180.131
Start Time: Sun, 28 Aug 2022 09:21:10 +0800
Labels: app=v1
pod-template-hash=7c86978c57
Annotations: <none>
Status: Running
IP: 10.244.2.168
Controlled By: ReplicaSet/d1-7c86978c57
Containers:
myapp01:
Container ID: docker://ffc089051facd31a242d199e21ca0d3d423cbcdadfbeaa49dd7b993330124f8d
Image: 192.168.180.129:9999/myharbor/myapp:v2
Image ID: docker-pullable://192.168.180.129:9999/myharbor/myapp@sha256:a97b2685e86ee13eaa0cb625e832fb195d39c0ccc8ef4bc7611aab6cac319e34
Port: 8080/TCP
Host Port: 0/TCP
Command:
nohup
java
-jar
/usr/local/test/dockerdemo.jar
&
State: Running
Started: Sun, 28 Aug 2022 09:21:12 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-6wl7b (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-6wl7b:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-6wl7b
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 86s default-scheduler Successfully assigned default/d1-7c86978c57-cfvsj to k8s-node02
Normal Pulling 84s kubelet, k8s-node02 Pulling image "192.168.180.129:9999/myharbor/myapp:v2"
Normal Pulled 84s kubelet, k8s-node02 Successfully pulled image "192.168.180.129:9999/myharbor/myapp:v2"
Normal Created 84s kubelet, k8s-node02 Created container myapp01
Normal Started 84s kubelet, k8s-node02 Started container myapp01
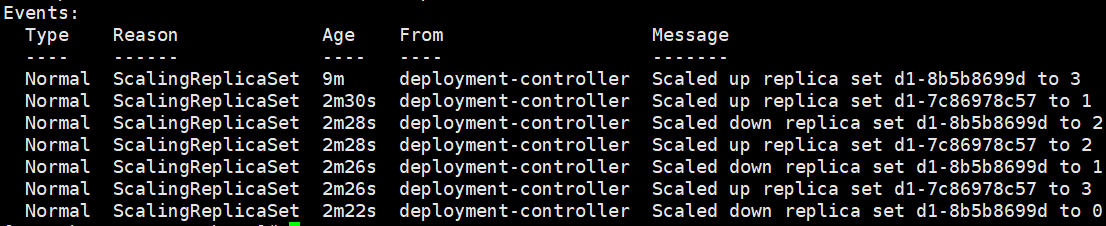
kubectl describe deploy d1 查看deployment是如何升级的pod。
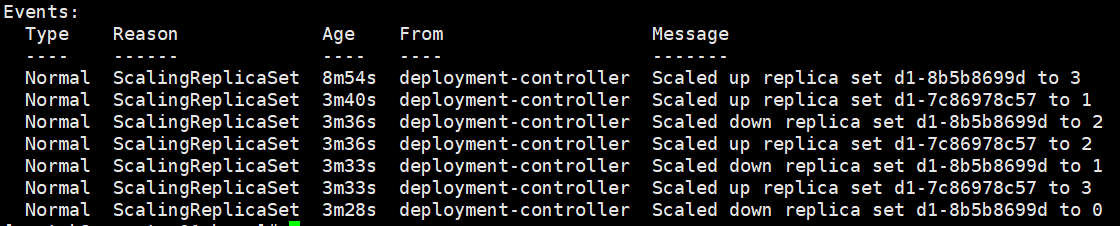
9d创建了3个pod
57创建了1个pod
9d缩减到2个pod
57扩容到2个pod
9d缩减到1个pod
57扩容到3个pod
9d缩减到0个pod
最后的结果是1个deployment2个replicaSet3个pod。
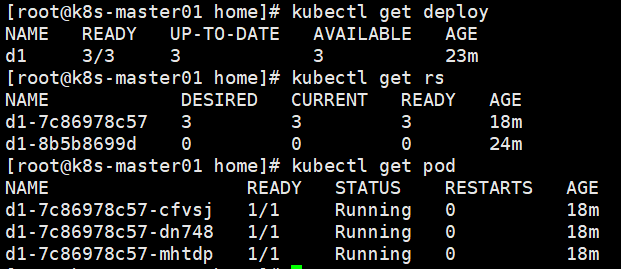
Recreate
设置spec.strategy.type=Recreate,表示Deployment在更新pod时,会先杀掉所有正在运行的pod,然后创建新的pod。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1
replicas: 3
strategy:
type: Recreate
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
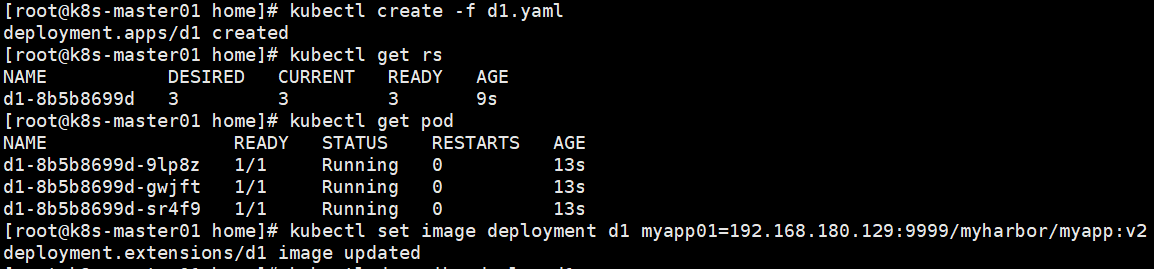

9d直接将pod缩减到0个然后57创建了3个。
Deployment回滚
如果在Deployment升级过程中出现意外,比如写错新镜像的名称而导致升级失败,就需要回退到升级之前的旧版本,这时就需要使用到Deployment的回滚功能了。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1
replicas: 3
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]

现在没有myapp:v3这个镜像,查看Deployment部署过程。
kubectl rollout status deployment d1

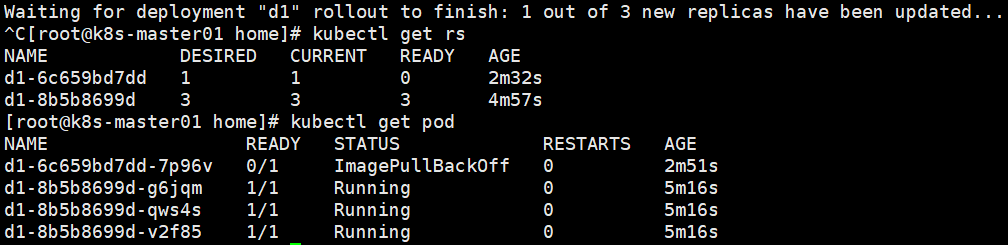
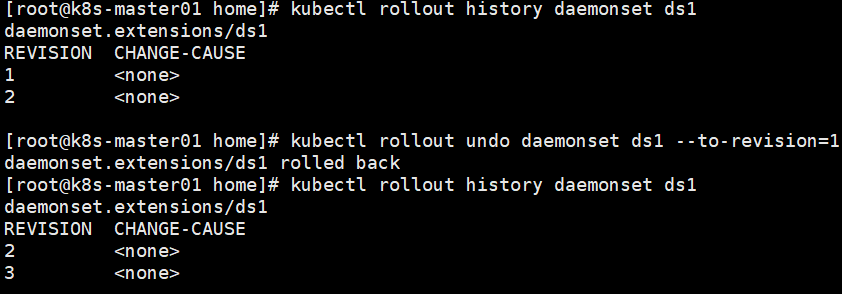
发现新的rs在创建pod时被卡在镜像拉去过程中。为了解决这个问题,我们需要回滚到之前稳定版本的Deployment。首先查看Deployment部署记录。
kubectl rollout history deployment d1

查看Deployment特定的版本信息。
kubectl rollout history deployment d1 --revision=1
[root@k8s-master01 ~]# kubectl rollout history deployment d1 --revision=1
deployment.extensions/d1 with revision #1
Pod Template:
Labels: app=v1
pod-template-hash=8b5b8699d
Containers:
myapp01:
Image: 192.168.180.129:9999/myharbor/myapp:v1
Port: 8080/TCP
Host Port: 0/TCP
Command:
nohup
java
-jar
/usr/local/test/dockerdemo.jar
&
Environment: <none>
Mounts: <none>
Volumes: <none>
[root@k8s-master01 ~]# kubectl rollout history deployment d1 --revision=2
deployment.extensions/d1 with revision #2
Pod Template:
Labels: app=v1
pod-template-hash=6c659bd7dd
Containers:
myapp01:
Image: 192.168.180.129:9999/myharbor/myapp:v3
Port: 8080/TCP
Host Port: 0/TCP
Command:
nohup
java
-jar
/usr/local/test/dockerdemo.jar
&
Environment: <none>
Mounts: <none>
Volumes: <none>
现在我们回滚到上一个版本,或者回滚到指定的版本。
回滚到上个版本:kubectl rollout undo deployment
回滚到指定版本:kubectl rollout undo deployment d1 --to-revision=1


Deployment暂停和恢复
对于一次复杂的Deployment配置修改,为了避免频繁触发Deployment的更新操作,可以先暂停Deployment的更新操作,然后进行配置修改,再恢复Depolyment。注意,在恢复暂停的Deployment前,无法回滚该Deployment。
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1
replicas: 3
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
kubectl rollout pause deployment d1

查看Deployment更新记录,发现并没有触发新的Deployment部署操作。

kubectl rollout resume deploy d1
可以看到恢复后重新创建了一个新的rs,并且Depolyment也有了更新记录
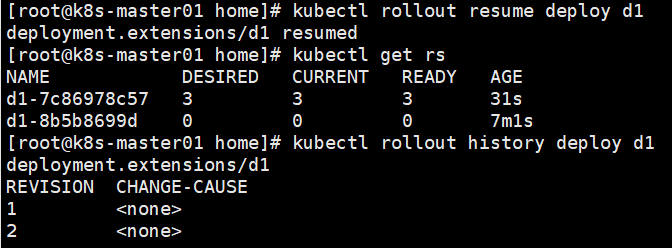
kubectl describe deploy d1 查看更新信息
DeamonSet的更新策略
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds1
spec:
selector:
matchLabels:
app: v1
updateStrategy:
type: OnDelete
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]

OnDelete
在创建好新的DaemonSet配置后,新的pod并不会被自动创建,直到用户手动删除旧的pod才会触发新建操作。
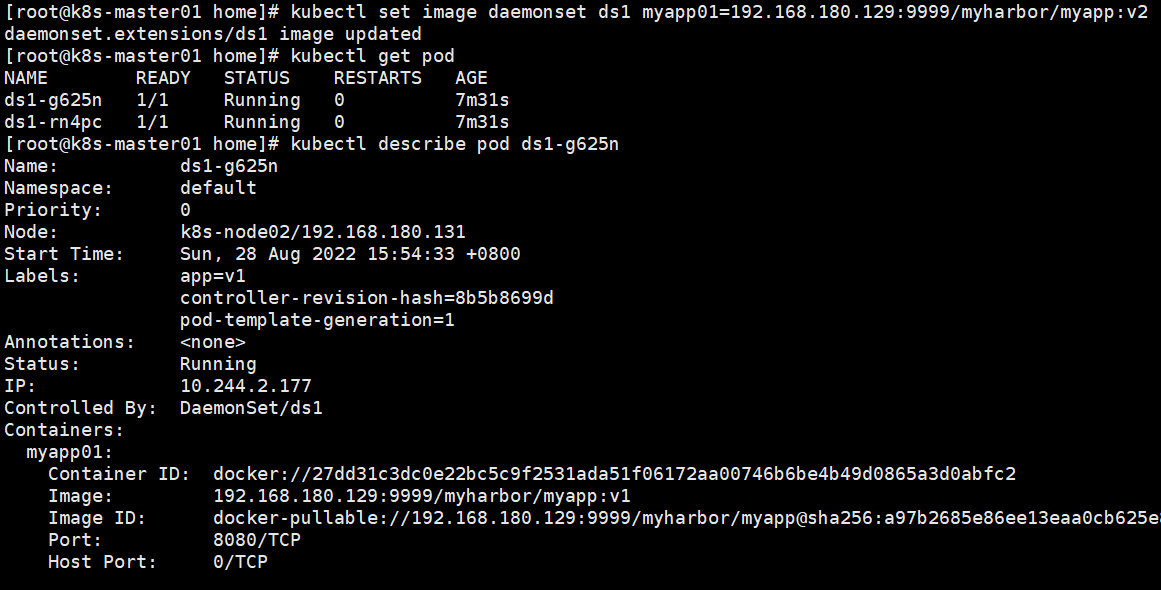
手动删除其中一个pod,它才会触发更新操作
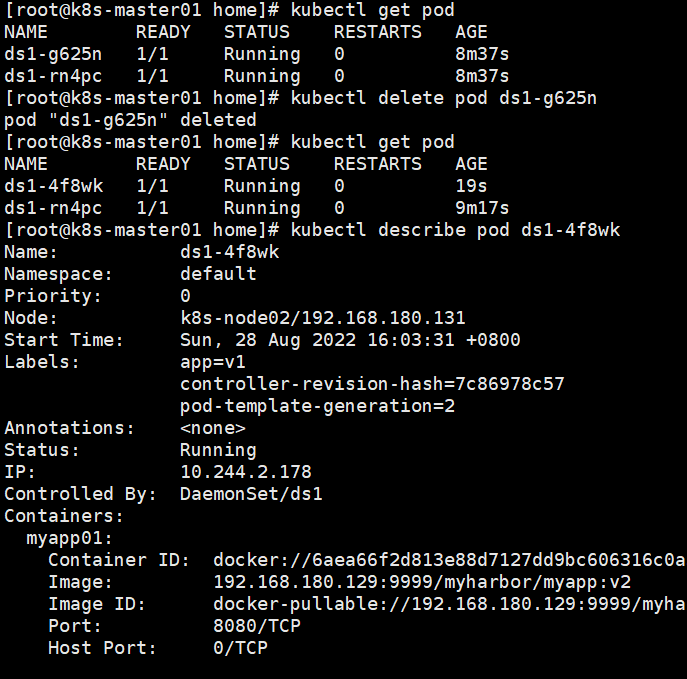
另外一个pod还是v1版本
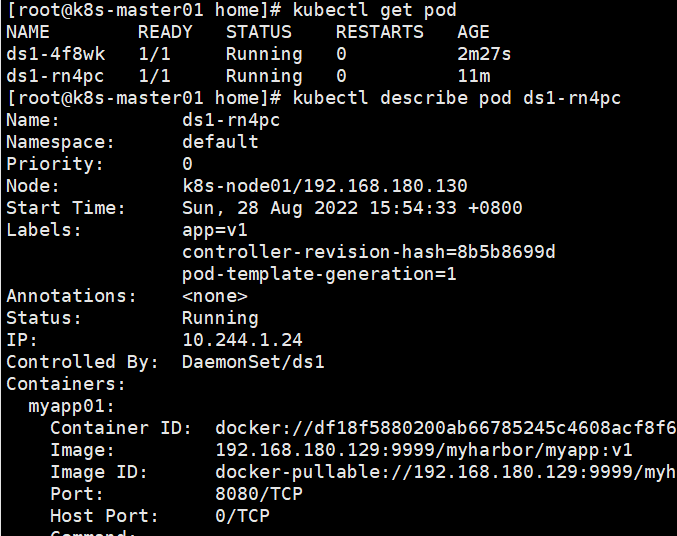
RollingUpdate
旧版本的pod将自动被杀掉,然后自动部署新版本的pod,整过过程与普通的Deployment滚动升级一样是可控的。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds1
spec:
selector:
matchLabels:
app: v1
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
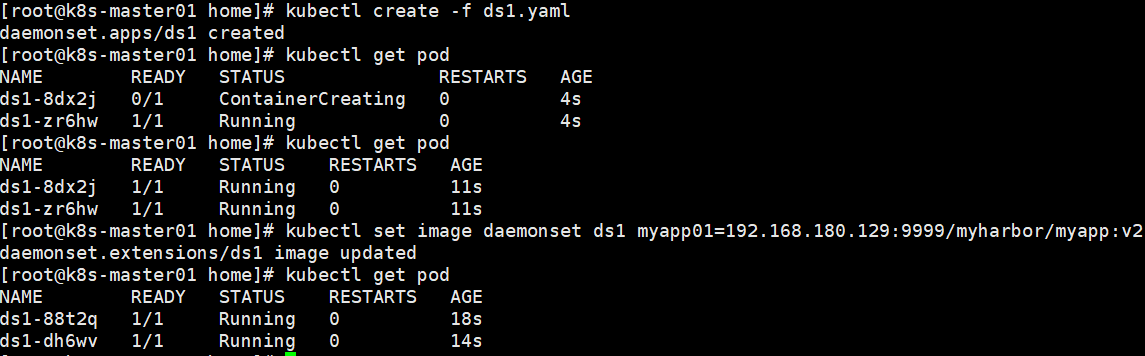
回滚与Deployment操作相同。
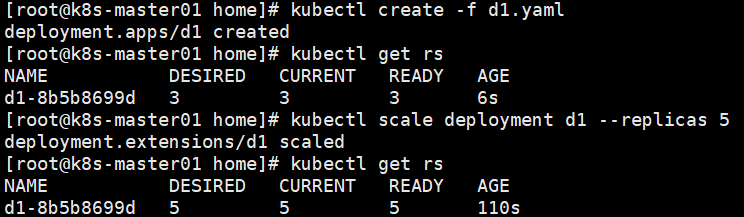
Pod的扩缩容
k8s对pod的扩缩容操作提供了手动和自动两种模式,对Deployment或RCC进行pod副本数量设置,即可一键完成。
手动扩缩容
通过Deployment将3个副本变成5个,如果副本数少于replicas则是缩容
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1
replicas: 3
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
kubectl scale deployment d1 --replicas 5
HPA自动扩缩容
关于HPA的概念参考官方文档
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
apiVersion: apps/v1
kind: Deployment
metadata:
name: d1
spec:
selector:
matchLabels:
app: v1
replicas: 1
template:
metadata:
labels:
app: v1
spec:
containers:
- name: myapp01
image: 192.168.180.129:9999/myharbor/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: tomcatport
containerPort: 8080
command: ["nohup","java","-jar","/usr/local/test/dockerdemo.jar","&"]
resources:
requests:
cpu: 50m
memory: 50Mi
Metrics-Server安装
参考这篇博客,安装时需要注意自己的k8s版本 https://blog.51cto.com/lingxudong/2545242
基于CPU扩容缩容
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa1
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: d1
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 20
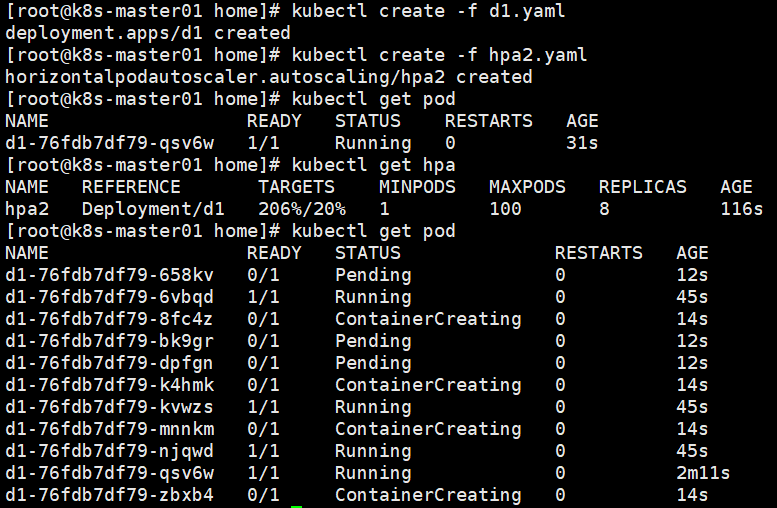
基于内存扩容
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa2
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: d1
minReplicas: 1
maxReplicas: 100
metrics:
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageUtilization: 20
Recommend
-
31
Pod详解 Pod介绍 Pod 是k8s的重要概念,要掌握 每个Pod都有一个特殊的被称为“根容器”的Pause容器 Pause容器对应的镜像属于k8s平台的一部分,除了Pause容器还包含一个或多个紧密相关的业务容器
-
53
在 Kubernetes 中,为了保证业务不中断或业务SLA不降级,需要将应用进行集群化部署。通过 PodDisruptionBudget 控制器可以设置应用POD集群处于运行状态最低个数,也可以设置应用POD集群处于运行状态的最低百...
-
15
简介 Scheduler 是 Kubernetes 的调度器,主要任务是把定义的Pod分配到集群的节点上,听起来非常简单,但要考虑需要方面的问题: 公平:如何保证每个节点都能被分配到资源 资源高效利用:集群所有资源最...
-
12
目录: Pod的调度 Pod的扩容和缩容 Pod的滚动升级 一、Pod的调度 Pod只是容器的载体,通常需要通过RC、Deployment、DaemonSet、Job等对象来完成Pod的调度和自动控制功能。 1、R...
-
7
aliyun kubernetes观后记: 有了容器,为什么要用Pod呢? 在操作系统中,一个程序的运行实际上由多个线程组成,这多个线程共享进程的资源,相互协作,完成程序的工作,这也是操作系统中进程组的概念。
-
9
feininan3天前原文链接:https://www.cnblogs.com/chopper-poet/p/15328054.html...
-
6
nginx或者其它负载均衡软件都有一个能力,就是当客户请求一个网页时,第一次访问的是A服务器,第二次也就会让你访问A服务器,而在k8s里,也有这种机制和能力。 k8s的Session affinity Service同样也支持Session affinity(粘性会话)...
-
3
博客内容来源于 刘欣老师的课程,刘欣老师的公众号 码农翻身 博客内容来源于 Java虚拟机规范(JavaSE7) 博客内容的源码 https://gitee.com/zumengjie/litejvm 阅读此博客请配合源码食用。 ClassLoader ClassLoader就是根据类...
-
7
一.系统环境 服务器版本 docker软件版本 Kubernetes(k8s)集群版本 CPU架构 CentOS Linux release 7.4.1708 (Core) Docker version...
-
10
一、scheduler调度器 1、kube-scheduler简介 k8s实践(10) -- Kubernetes集群运...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK