

腾讯方睿:详解Kubernetes资源拓扑感知调度
source link: https://blog.csdn.net/m0_46700908/article/details/126518766
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

嘉宾 | 方睿
出品 | CSDN云原生
在云原生场景下,为了使CPU利用率更高,以及各容器之间不会由于激烈竞争而引起性能下降,容器的资源分配需要更精细化。
2022年8月11日,中国信通院、腾讯云、FinOps产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第6讲上,腾讯星辰算力平台高级工程师方睿分享了Kubernetes资源拓扑感知调度。

资源竞争与资源感知问题
从CPU的体系结构上来看,现代CPU多采用NUMA架构和方式。
NUMA架构是非对称的,每个NUMA node上会有自己的物理CPU内核,以及每个NUMA node之间也共享L3 Cache。同时,内存也分布在每个NUMA node上的。某些开启了超线程的CPU,一个物理CPU内核在操作系统上会呈现两个逻辑的核。
实际上,CPU内核是分布在NUMA node上,NUMA node内本身就有一些亲和性的元素。

右图中,CPU开始的访问速度是不一样的。
如果程序都跑在同一个NUMA node上,可以更好地去共享一些L3 Cache,L3 Cache的访问速度会很快。如果L3 Cache没有命中,可以到内存中读取数据,访存速度会大大降低。
因此,从CPU体系结构中可以看到,如果采用一些错误的CPU分配方式,可能会导致进程访存速度急剧下降,严重影响应用程序的性能。
在这样的体系结构下,存在云计算中常见的吵闹的邻居问题。当多个容器在节点上共同运行时,由于资源分配的不合理,会对CPU本身的性能造成影响。
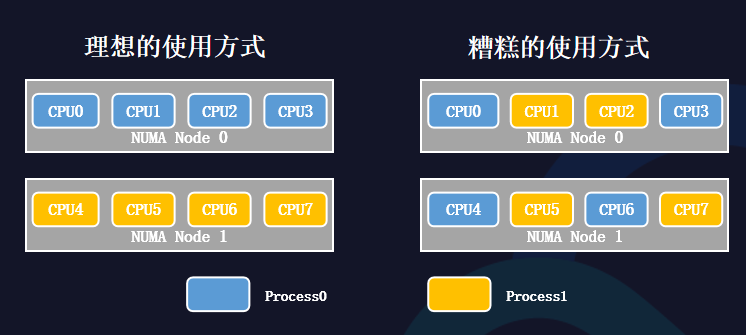
从理想的使用方式来看,如果每个进程都使用各自的CPU内核,并且不会跨NUMA node访问,相互之间不会有太多争抢。
从糟糕的使用方式来看,如果两个进程的CPU内核在分配时,可能会没有遵循NUMA的亲和性,会带来很大的性能问题,体现在三个方面:
-
CPU争抢带来频繁的上下文切换时间;
-
频繁的进程切换导致CPU高速缓存失败;
-
跨NUMA访存会带来更严重的性能瓶颈。
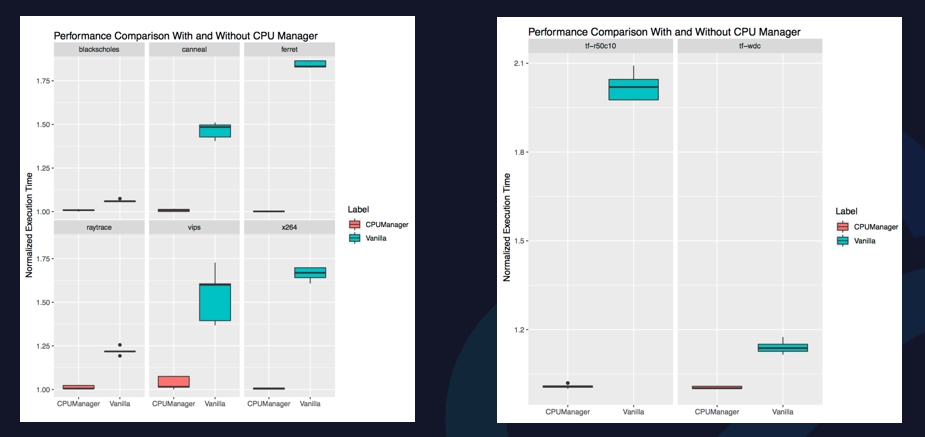
Kubernetes中有CPU Manager的功能,CPU Manager可以做一些CPU核心的分配工作。上图是Kubernetes的一些数据呈现。
-
在Guaranteed和Burstable两种Pod混部测试下,将CPU Manager执行时间做基准,如果是原生Kubernetes的方式在不同测试下,性能有较大波动,最差可能会达到1.8倍左右。
-
在Stand-Alone Workloads的情况下,做CPU的绑定和完全不做CPU绑定,执行时间差别很大。因为剧烈的CPU争抢以及频繁的上下文切换,会导致约1倍的性能差距。

在吵闹的邻居问题下,Kubernetes是如何解决的呢?
CPU Manager是其中的一个解决方法,它被放在Kubelet中,CPUSet将会被CPU Manager分在Default和Exclusive两个池子中。
-
Default主要在两种情况下使用。一种是系统守护进程:kube-reserved、system-reserved,另一种是特殊类型的Pod:Burstable、BestEffort、请求非整数CPU的Guaranteed。
-
Exclusive是完全排他的CPU池,主要在两种情况下使用。一种是Pod:请求整数CPU的Guaranteed,另一种是Topology Manager:满足拓扑管理器定义的要求。
但原生Kubernetes也存在局限性。
-
调度器不感知节点资源拓扑。
Kubernetes中调度器只负责为Pod选择节点,并不感知节点NUMA拓扑结构,Pod的CPU分配交给Kubelet完成。当节点单NUMA node上没有足够的CPU时,Pod启动失败,控制器重建Pod后会陷入死循环。
-
CPUSet分配策略过于单一。
Kubernetes中CPU Manager默认为请求整数CPU的Guaranteed Pod分配独占的CPUSet,但实际上Pod想定制自己的CPU分配策略,可能只是想分配到一个NUMA node内,或是固定CPU甚至是不做绑核。

在混部场景下,也存在离线算力感知问题。
-
当在线与离线任务混部在同一台主机上,在线闲时,离线任务可以充分使用资源,提升主机利用率;在线忙时,离线任务会被在线抢占,等待资源释放。
-
当离线可用算力受在线干扰动态变化时,调度器仅感知节点静态资源(Kubelet采集)。
如果忙时调度过多的离线任务,会导致剧烈的资源争抢,并且每个离线Pod的性能都会下降。
因此,调度器在调度时,需要动态感知离线实时算力。驱逐器也应当在线严重干扰离线时,驱逐离线Pod,保证节点的算力稳定。

Kuberbnetes精细化调度
在原生Kubernetes不能很好地解决资源竞争与资源感知问题时,亟需对资源进行更加精细化的调度。
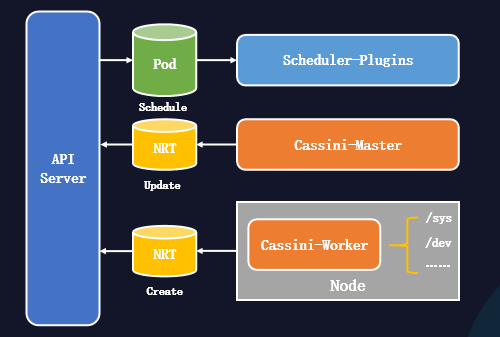
如上图,是精细化调度系统的结构。
-
Cassini-Worker能从节点采集资源拓扑信息并创建NRT对象。
-
Cassini-Master能从外部系统采集节点扩展信息(可选)。
-
Scheduler-Plugins能扩展调度器,为Pod进行资源拓扑分配。
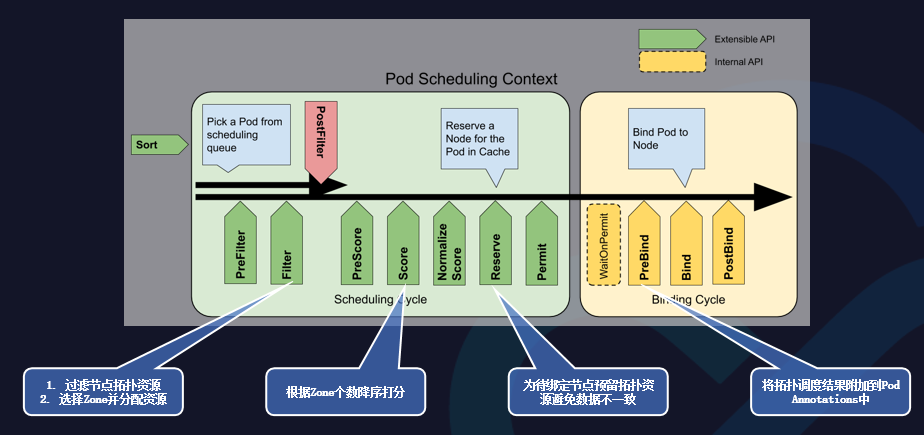
扩展调度器是通过Scheduler-Plugins来实现的,可以在几个插入点做一些插件,保证实现标库资源头部感知调度的功能。
-
在Fitter的插件内,可以过滤节点拓扑资源和选择Zone并分配资源。
-
在Score的插件内,可以根据Zone个数降序打分。
-
在Reserver的插件内,可以为待绑定节点预留拓扑资源避免数据不一致。
-
在PreBind的插件内,可以将拓扑调度结果附加到Pod Annotations中。
在调度算法上,可以从性能和负载均衡两个方面做出考虑,以便更好地选择节点和拓扑。
-
在性能方面,优先选择Pod能绑定在单NUMA node内的节点。如果找不到该节点,可以优先选择在同一个NUMA Socket内的NUMA node
-
在负载均衡方面,优先选择空闲资源更多的NUMA node。

容器CPUSet管理
Kubernetes的精细化调度做出一些拓扑感知,而实际落到节点上,为了更好地实现资源分配,我们设计了一个资源分配系统。
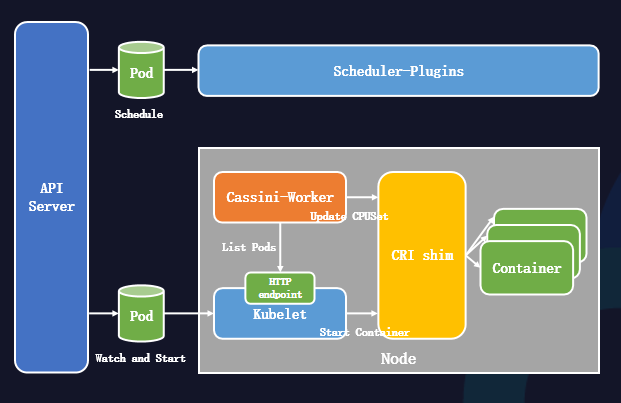
-
首先,节点Kubelet会监听到Pod并准备启动Pod。
-
随后,节点Kubelet调用容器运行时接口启动容器。
-
与此同时,节点Cassini-Worker通过List Kubelet的10250端口获得节点上的所有Pod,再从Pod Annotations中获取调度器的拓扑调度结果。
-
节点Cassini-Worker调用容器运行时接口来更改容器的绑核结果。
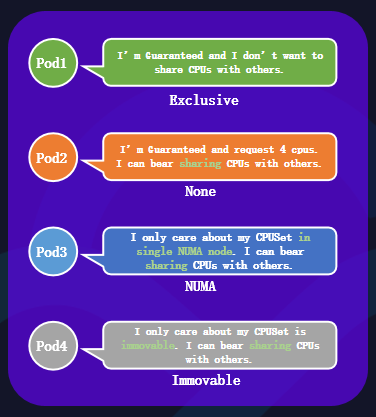
关于容器多级资源QoS分配策略,在CPUSet的策略上,可以划分为四种:
-
Exclusive:它可以独占CPU内核心,其他Pod不可使用,一般是高利用率的容器会采取该策略;
-
None:不做CPU绑核的策略,可以使用节点的Default CPU共享池;
-
NUMA:让CPUSet固定到NUMA node上的共享池内;
-
Immovable:将CPU内核心固定,让其他Pod也可共享。
在CPU内核心选择策略上:
-
首先,按照调度结果获取NUMA node上需分配的核心数;
-
随后,从共享池中选择可分配的CPU内核心;
-
同时,还希望一个Pod尽量不使用在同一个物理核上的逻辑核。

在离线混部场景下的实践
由于离线混部场景中,离线会受到在线的影响,算力是波动的。因此,在离线混部场景下,还会做一些差异化重调度:
-
当在线负载上升时,离线的算力会被压制。因此,离线的Pod需要及时驱逐,以便刚好满足节点离线算力的要求;
-
通过改造Descheduler组件,建立通用的可配置的平台通用驱逐框架,支持Metrics驱逐,以及支持动态调整/配置驱逐策略;
-
建立算力平台通用Metrics;
-
支持业务自定义Metrics驱逐。
在不同混部场景下,容器CPUSet策略也是不同的。
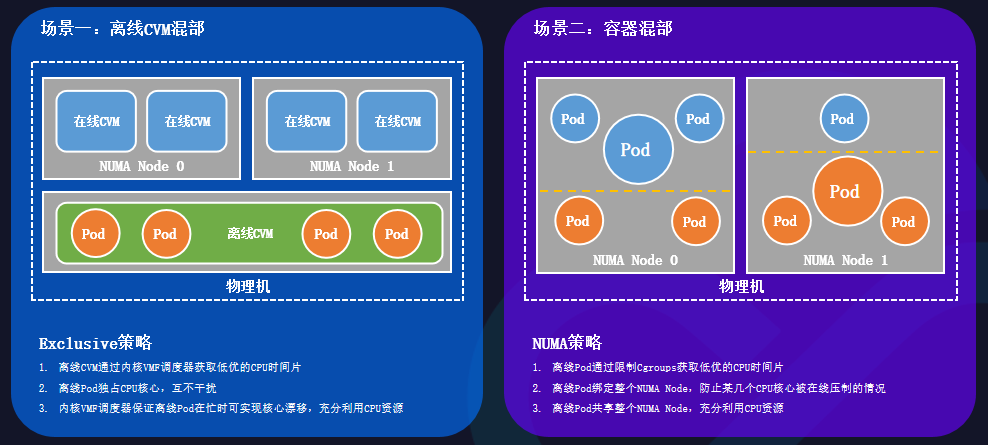
离线CVM混部的场景中,一台物理机的各个NUMA node上都生产了许多在线的CVM,当在线利用率很低时,需要更好地利用资源。
此时需要采取Exclusive策略:
-
离线CVM通过内核VMF调度器获取低优的CPU时间片;
-
离线Pod通过独占CPU内核心的方式,保证互不干扰;
-
内核VMF调度器保证离线Pod在忙时,可实现核心漂移,充分利用CPU资源。
在容器混部的场景中,在线Pod和离线Pod同时部署在同一台物理机上。
此时需要采取NUMA策略:
-
离线Pod通过限制Cgroups,获取低优的CPU时间片;
-
离线Pod绑定整个NUMA node,防止某几个CPU内核心被压制;
-
离线Pod共享整个NUMA node,充分利用CPU资源。

总结
本文围绕Kubernetes的资源拓扑感知调度的主题展开。从CPU体系结构和吵闹的邻居问题切人,随后阐述了原生Kubernetes的不足和混部场景下的算力感知的局限,最后从采集节点拓扑资源、扩展Kubernetes调度器、多级资源QoS分配策略几个方面给出了相应的解决方案。在策略的优化后,资源得到更合理地利用。
未来,Kubernetes精细化调度将会覆盖更多的场景,例如碎片GPU、网络拓扑架构、电力调度。
【原动力×云原生正发声降本增效大讲堂】第一期聚焦在优秀实践方法论、资源与弹性、架构设计;第二期聚焦全场景在离线混部、K8s GPU资源效率提升、K8s资源拓扑感知调度主题,点击『此处』进入活动专题,带你体验云原生降本增效实践案例、了解如何解决企业用云痛点、掌握降本增效关键技能……
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK