

多模态图像合成与编辑这么火,马普所、南洋理工等出了份详细综述
source link: https://www.51cto.com/article/716891.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

多模态图像合成与编辑这么火,马普所、南洋理工等出了份详细综述
近期 OpenAI 发布的 DALLE-2 和谷歌发布的 Imagen 等实现了令人惊叹的文字到图像的生成效果,引发了广泛关注并且衍生出了很多有趣的应用。而文字到图像的生成属于多模态图像合成与编辑领域的一个典型任务。近日,来自马普所和南洋理工等机构的研究人员对多模态图像合成与编辑这一大领域的研究现状和未来发展做了详细的调查和分析。

- 论文地址:https://arxiv.org/pdf/2112.13592.pdf
- 项目地址:https://github.com/fnzhan/MISE

在第一章节,该综述描述了多模态图像合成与编辑任务的意义和整体发展,以及本论文的贡献与总体结构。
在第二章节,根据引导图片合成与编辑的数据模态,该综述论文介绍了比较常用的视觉引导(比如 语义图,关键点图,边缘图),文字引导,语音引导,场景图(scene graph)引导和相应模态数据的处理方法以及统一的表示框架。
在第三章节,根据图像合成与编辑的模型框架,该论文对目前的各种方法进行了分类,包括基于 GAN 的方法,自回归方法,扩散模型方法,和神经辐射场(NeRF)方法。
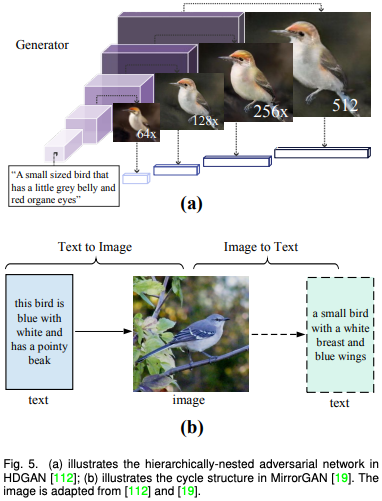
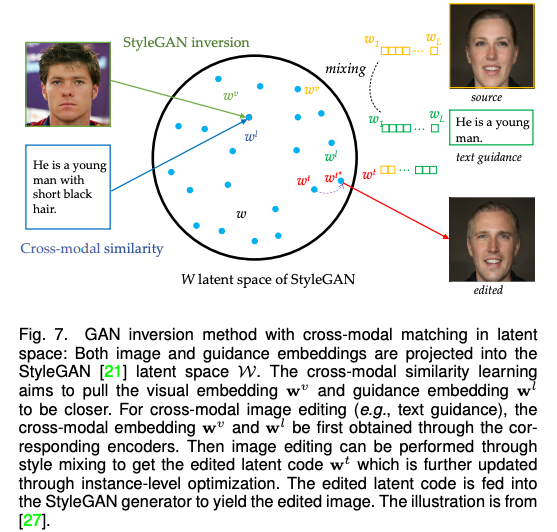
由于基于 GAN 的方法一般使用条件 GAN 和 无条件 GAN 反演,因此该论文将这一类别进一步分为模态内条件(例如语义图,边缘图),跨模态条件(例如文字和语音),和 GAN 反演(统一模态)并进行了详细描述。
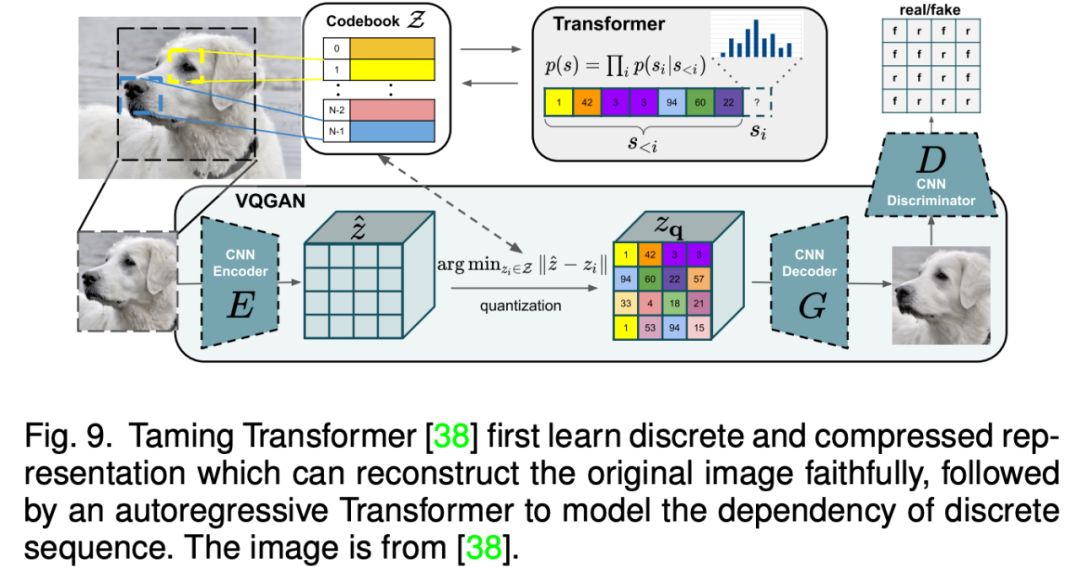
相比于基于 GAN 的方法,自回归模型方法能够更加自然的处理多模态数据,以及利用目前流行的 Transformer 模型。自回归方法一般先学习一个向量量化编码器将图片离散地表示为 token 序列,然后自回归式地建模 token 的分布。由于文本和语音等数据都能表示为 token 并作为自回归建模的条件,因此各种多模态图片合成与编辑任务都能统一到一个框架当中。
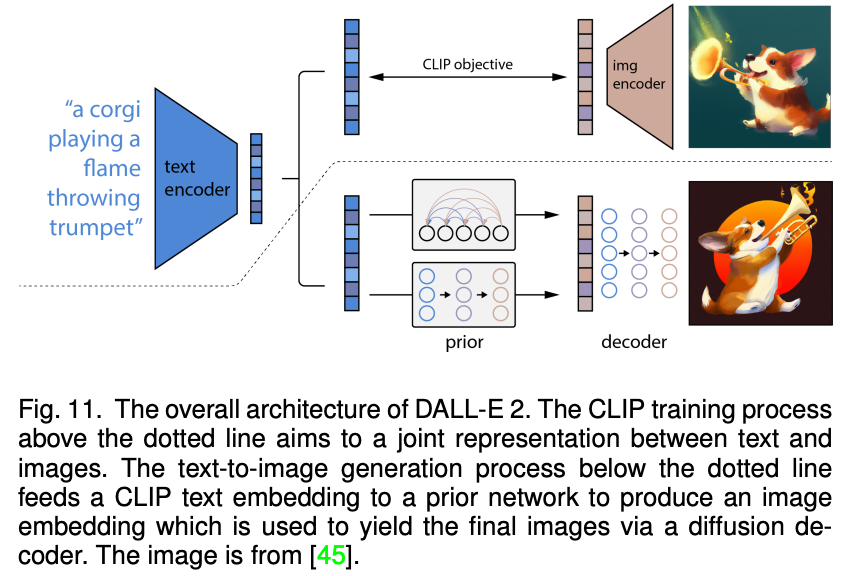
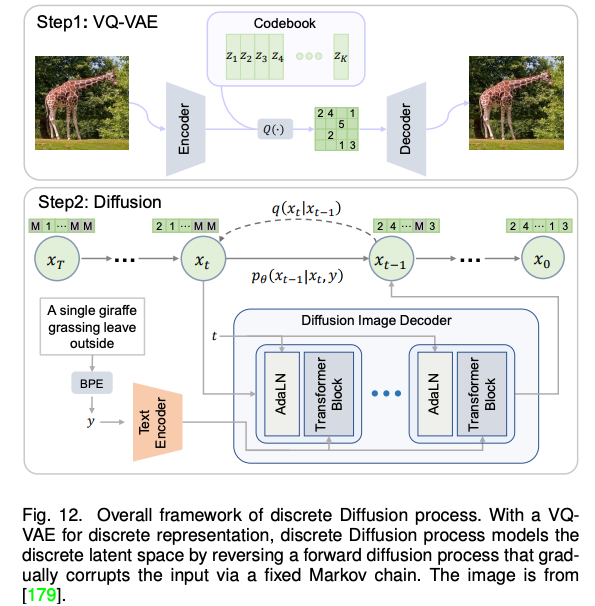
近期,火热的扩散模型也被广泛应用于多模态合成与编辑任务。例如效果惊人的 DALLE-2 和 Imagen 都是基于扩散模型实现的。相比于 GAN,扩散式生成模型拥有一些良好的性质,比如静态的训练目标和易扩展性。该论文依据条件扩散模型和预训练扩散模型对现有方法进行了分类与详细分析。
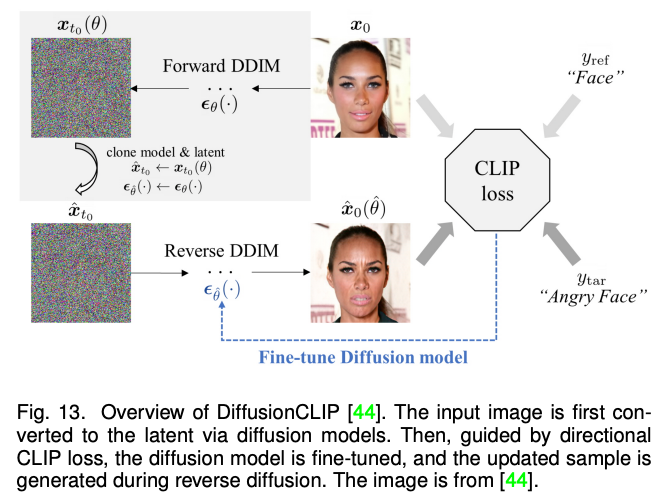
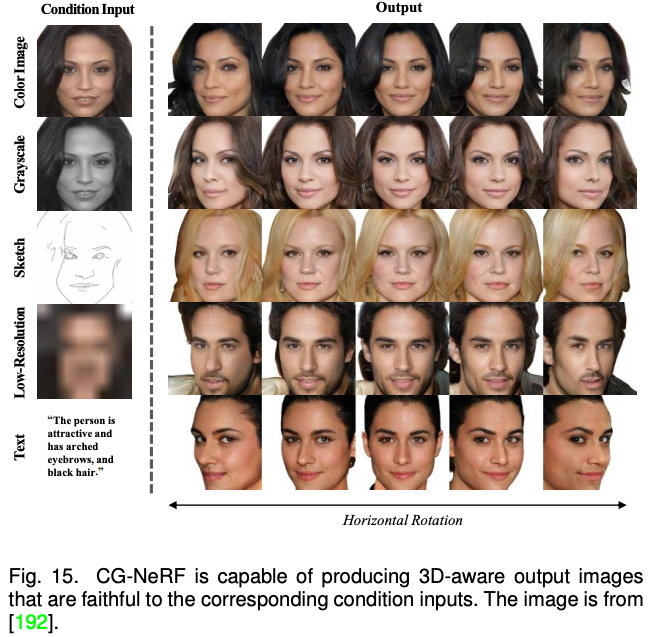
以上方法主要聚焦于 2D 图像的多模态合成与编辑。近期随着神经辐射场(NeRF)的迅速发展,3D 感知的多模态合成与编辑也吸引了越来越多的关注。由于需要考虑多视角一致性,3D 感知的多模态合成与编辑是更具挑战性的任务。本文针对单场景优化 NeRF,生成式 NeRF 和 NeRF 反演的三种方法对现有工作进行了分类与总结。
随后,该综述对以上四种模型方法的进行了比较和讨论。总体而言,相比于 GAN,目前最先进的模型更加偏爱自回归模型和扩散模型。而 NeRF 在多模态合成与编辑任务的应用为这个领域的研究打开了一扇新的窗户。
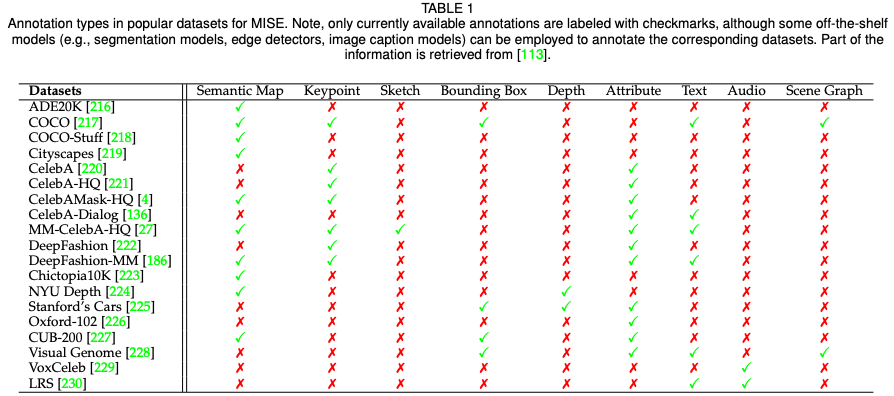
在第四章节,该综述汇集了多模态合成与编辑领域流行的数据集以及相应的模态标注,并且针对各模态典型任务(语义图像合成,文字到图像合成,语音引导图像编辑)对当前方法进行了定量的比较。
在第五章节,该综述对此领域目前的挑战和未来方向进行了探讨和分析,包括大规模的多模态数据集,准确可靠的评估指标,高效的网络架构,以及 3D 感知的发展方向。
在第六和第七章节,该综述分别阐述了此领域潜在的社会影响和总结了文章的内容与贡献。
Recommend
-
74
阿里巴巴与南洋理工大学成立联合研究院 探索AI技术
-
54
阿里“政委”下南洋
-
65
据机器之心了解,德国马克思·普朗克研究所马普智能系统所共有 14 篇论文入选 CVPR 2019,本文简要介绍了其中三篇。 论文 1:Capture, Learning, and Synthesis of 3D Speaking Styles 作者:Daniel Cudeiro...
-
18
6 月 21 日,由北京智源人工智能研究院主办的 2020 北京智源大会正式开幕(直播入口: https://2020.baai.ac.cn ),大会为期四天,各主题论坛和分论坛将围绕如何构建多学科开放协同的创新体系、...
-
11
拉里·特斯勒(Larry Tesler):非模态文本编辑和剪切/复制-粘贴的个人历史RIP: “剪切/复制-粘贴”功能发明人拉里·特斯勒(Larry Tesler)于2020年2月17日去世,终年74岁。我做了50多年的计算机程序员。从一开始,我就被...
-
6
麻省理工科技评论-DeepMind评估AI多模态图像语言转换器在看图理解中对动词的识别力DeepMind评估AI多模态图像语言转换器在看图理解中对动词的识别力对于 AI 系统来说,将语言与视觉联系起来是它需要面对并学会解决的基本问题,例如在进行...
-
5
麻省理工科技评论-29岁马普所中国学者首次证明自生静电可影响液滴运动,打开表面浸润性设计新大门!将改善生活中多种应用场景对液滴运动的控制科技与人文29岁马普所中国学者首次证明自生静电可影响液滴运动,打开表面浸润性设...
-
9
图像文本跨模态细粒度语义对齐-置信度校正机制 AAAI2022 论文介绍:
-
5
AmodalSynthDrive:一个用于自动驾驶的合成非模态感知数据集 作者:自动驾驶专栏 2023-10-11 10:22:55 本文介绍了AmodalSynthDrive:一个用于自动驾驶的合成非模态感知数据集。与人类不同,即使在部分遮挡的情况下...
-
6
把图像视为外语,快手、北大多模态大模型媲美DALLE-3 作者:机器之心 2024-01-30 13:17:00 动态视觉分词统一图文表示,快手与北大合作提出基座模型 LaVIT 刷榜多模态理解与生成任务。
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK