

Detecting Rendered Line Breaks In A Text Node In JavaScript
source link: https://www.bennadel.com/blog/4310-detecting-rendered-line-breaks-in-a-text-node-in-javascript.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Detecting Rendered Line Breaks In A Text Node In JavaScript
At work, I've been building a way to generate "placeholder" images using a fragment of the DOM (Document Object Model). And, up until now, I've been using the .measureText() method, available on the Canvas 2D rendering context, to programmatically wrap lines-of-text onto a <canvas> element. But, this approach has proven to be a bit "glitchy" on the edges. As such, I wanted to see if I could find a way to detect the rendered line breaks in a text node of the document, regardless of what the text in the markup looked like. Then, I could more easily render the lines of text to the <canvas> element. It turns out, the Range class in JavaScript (well, in the browser) might be exactly what I need.
Run this demo in my JavaScript Demos project on GitHub.
View this code in my JavaScript Demos project on GitHub.
ASIDE: As a quick note, I'm actually trying to recreate a very tiny fraction of what the
html2canvaslibrary by Niklas von Hertzen already does. But, as stated in his own README, thehtml2canvaslibrary should not be used in a production application. As such, I wanted to try and create something over which I had full control (and responsibility).
A Range object represents some fragment of the page. This can contain a series of nodes; or, part of a text node. What's really cool about the Range object is that it can return a collection of bounding boxes that represent the visual rendering of the items within the range.
I actually looked at the Range object once before when drawing boxes around selected text. I didn't really have a use-case for that exploration at the time; but, performing that experiment 4-years ago allowed me to see a path forward in my current problem.
If I have a text-node in the DOM, and I create a Range for the contents of that text-node, the .getClientRects() method, on the Range, will return the bounding box for each line of text as it is rendered for the user. Now, this doesn't inherently tell me which chunk of text is on which rendered line; but, it gives us a way to do that with a little brute-force magic.
Consider a Range that has a single character in it - the first character in our text-node. This Range will only have a single bounding box. Now, what if we add the second character to that Range and examine the bounding boxes? If there is still a single bounding box, we can deduce that the second character is in the first line of text. But, if we now have two bounding boxes, we can deduce that the second character belongs in the second line of text.
Extending this, if we incrementally expand the contents of a Range, one character at a time, the last added character will always be in the last line of text. And, we can determine the "index" of that last line of text by using the current count of the bounding boxes.
This is definitely brute force and is probably going to be slow on very large chunks of text. But, for a single paragraph on a desktop computer, this brute force approach feels instantaneous.
Let's see this in action. In the following demo, I have a text node with some static text in it. When you click the button, I examine the text node and brute force extract the rendered lines of text and log them to the console. The method of not here is called extractLinesFromTextNode() - this is where we dynamically extend the Range to identify the text wrapping:
As you can see, we're looping over the characters in our text-node, adding each one the Range in sequence. Then, after each character has been added, we look at the current number of bounding boxes in order to determine which line of text contains the just-added character:
var lineIndex = ( range.getClientRects().length - 1 );
At the end of the brute-forcing, we have a two-dimensional array of characters in which the first dimension is this lineIndex value. Then, we simply collapse each character buffer (Array) down into a single String and we have our lines of text:
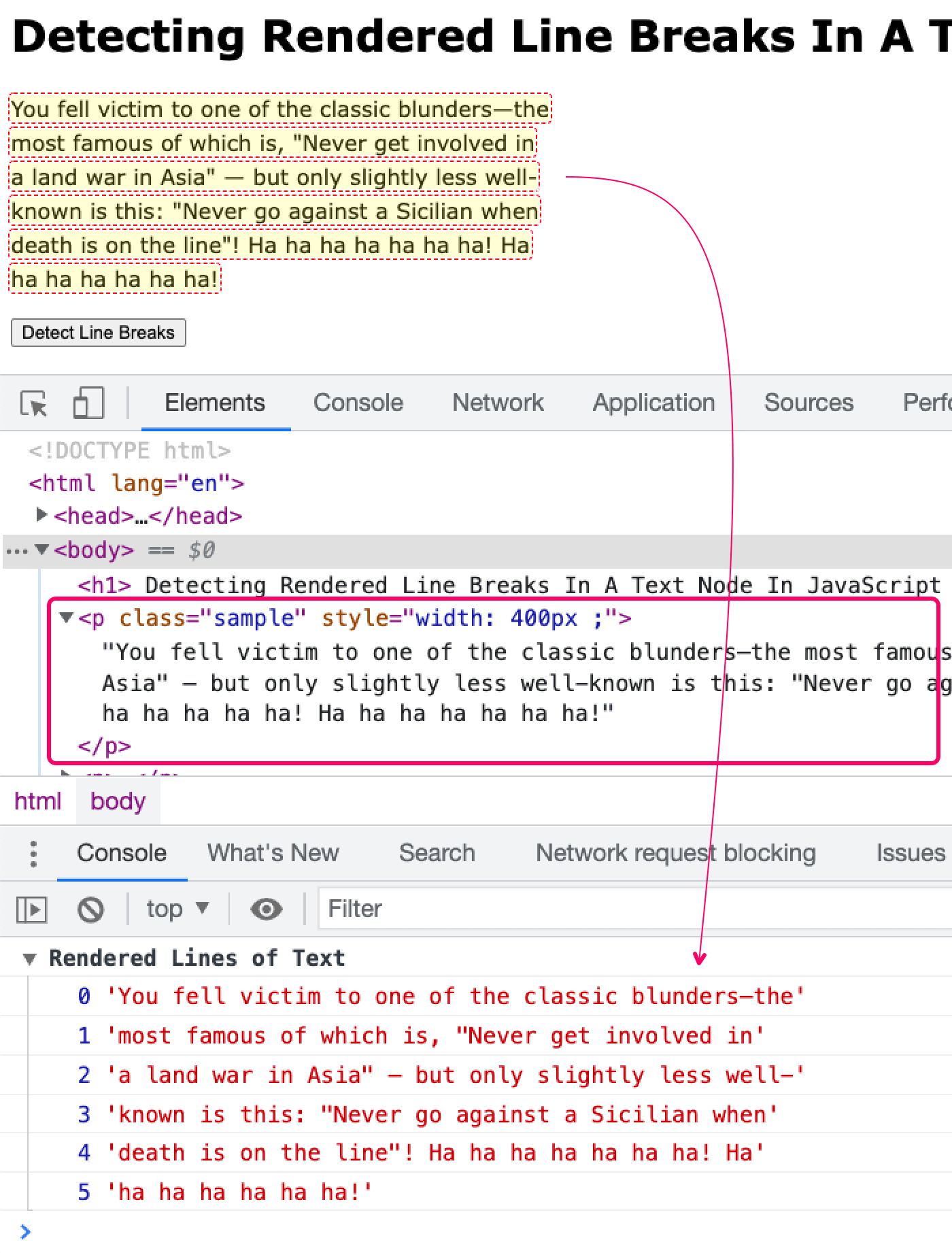
As you can see, we took a text-node from the DOM, which has no inherent line-breaks or text-wrapping, and used the Range object to determine which substrings of that text-node where on which lines (as seen by the user).
This works on my Chrome, Firefox, Edge, and Safari (though, I had to normalize the white-space in the text-content in order for Safari to work consistently with the modern browsers). And, of course, this is for a text node only. Meaning, this approach wasn't designed to work with an Element node that might contain mixed-content (such as formatting elements). But, such a constraint is sufficient for my particular use-case.
Once I have this production, I'd like to follow-up with a more in-depth example of how I'm generating the placeholder images using the <canvas> element. But, I'm hopeful that this approach will make it much easier to render multi-line text to that image.
Want to use code from this post? Check out the license.
Enjoyed This Post? ❤️ Share the Love With Your Friends! ❤️
Tweet This Great article by @BenNadel - Detecting Rendered Line Breaks In A Text Node In JavaScript
Reader Comments
This is nice use case of range.
@Hassam,
Thanks! It would be great if there was something "more native" that would expose this information, though, so it could have better performance. I just assume that calculating the Range values over and over again for each character is relatively slow. But, for my purposes, it seems to be fast enough.
I didn't know about the Range object until now. 🙌
It reminds me of a utility function I created to highlight words on a page where I used document.createTreeWalker to create a TreeWalker object, but I'm thinking the Range object might work too!
@Mario,
I think I played around with the TreeWalker API a number of years ago because I was trying to access Comment nodes in the DOM and jQuery, at least at the time, didn't make it super easy to get at non-Element nodes.
To be honest, I don't have my head wrapped around the full use-cases for Range objects. I know that the Selection API (what the user has highlighted) uses Ranges inside of it; which is where I think I first came to know of this. But, outside of the Selection, this is the first time that I've used it.
Here's a fast-follow to demonstrate how I am intending to use this line-extraction technique in order to help write text to the <canvas> object:
www.bennadel.com/blog/4311-rendering-wrapped-text-to-a-canvas-in-javascript.htm
Essentially, with Canvas, there is no "wrapped text" concept. As such, if you want to render wrapped text to the canvas, you have to break the text apart into individual lines; and then, render each line, in turn, at an increasing Y-offset. Hence my need to break text apart at the runtime line-breaks.
Post A Comment — ❤️ I'd Love To Hear From You! ❤️
Name:
Email:
Website:
Subscribe to comments.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK