

.NET Core + ELK 搭建可视化日志分析平台(下)
source link: https://blog.yuanpei.me/posts/3687594959/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近,我收到一位读者朋友的私信,问我 ELK 为什么没有下篇,道德感极强的我不得不坦诚相告,显然这一篇鸽了。这就是说,鸽子不单单会出现在吴宇森的电影里,只要你试图拖延或者逃避,你一样有鸽子可以放飞。话说回来,新冠疫情已然持续了三年,而这篇文章其实是我在新冠元年写下的。某年某月,彼时彼刻,立春过后紧接着是上元节,阳光已透过玻璃宣示着春天的到来,可在这一墙之隔的里里外外,仿佛是两个气候迥异的世界。记忆里那种每天都和消毒水、口罩打交道的日子,后来就变成了一种习以为常、甚至有一点唏嘘的常态化生活。在这过去的三年里,恍惚中已经发生太多的事情,譬如 ELK 早已变成了 EFK,譬如前女友有了新的男朋友,在一切的物是人非背后,在一切的断壁残垣下面,我想,我还是用这个旧题目来讲一个新的故事罢!
从 Logstash 到 Filebeat
当初准备写这个系列的时候,ELK 还是经典的 Elastaicsearch 、 Logstash 和 Kibana 组合,如下图所示,Logstash 从各种不同的数据源收集数据,通过内置的管道对输入的数据进行加工。最终,这些数据会被存储到 Elastaicsearch 中供 Kibana 完成数据可视化。 即使放到三年后的今天来看,这张图依然是非常经典的一幅图。为什么这么说呢?因为自此以后,可视化日志分析平台的搭建,基本都是围绕这三个方面展开,甚至 Logstash 的继任者 Filebeat、Fluentd、Fluent-Bit 等等无一不沿用了 Logstash 的这套管道设计,足可见其对后来者的影响之深远。不过,作为先驱出现的 Logstash,其本身是采用 Java 语言开发的,其插件则是采用 Ruby 语言开发的,特别是第一点,一直让 Logstash 在性能问题上遭人垢病。在实际使用中,你常常需要在每一台服务器上安装 Logstash ,这意味着它在 CPU 和内存上的占用会比较高。
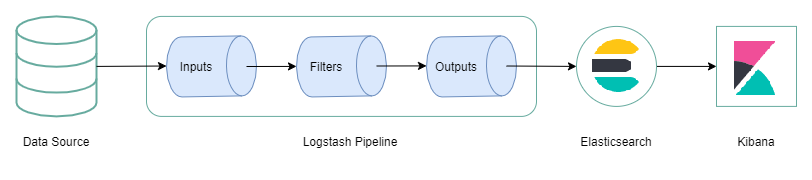
经典的 ELK 全家桶组合
为了解决这个问题,Elastic 官方推出了被称为 Beats 的下一代日志收集方案, 这是一种基于 Go 语言开发、更加轻量级的、资源占用更少的日志收集方案,可以认为是 Logstash 的替代品, 而 Filebeat 正好是其中一种实现。关于这两者的区别,我想,使用下面的比喻或许会更恰当一点, Logstash 就像一个轰鸣声不断的垃圾转运车,虽然可以让你直接把垃圾丢车上拉走,可你不得不忍受一整天的噪音;Filebeat 则像一个拎着扫帚和簸萁的环卫工人,那里有需要就去哪里清扫,不单单效率高而且不会让你感觉扰民,下面是一张来自 Elastic 官方文档 中的示意图:
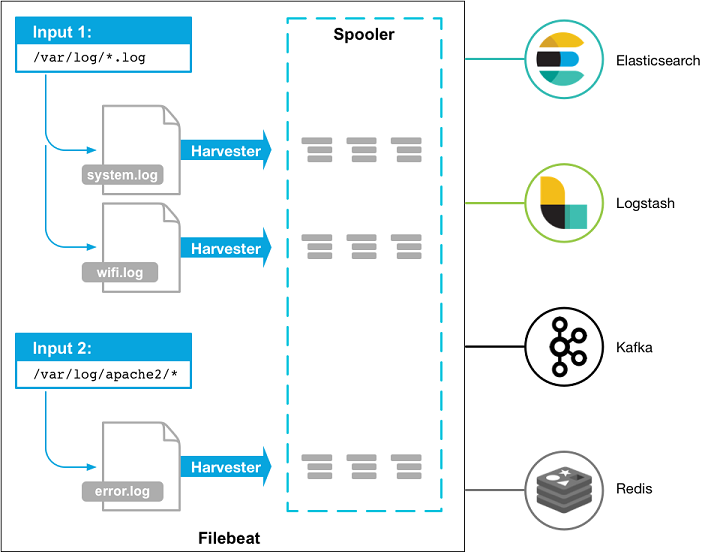
Filebeat 日志收集示意图
从这里我们可以看出, Filebeat 由两个主要的组件 Inputs 和 Harvester 组成。其中, Harvester 是一个负责读取单个文件内容的采集器,它可以打开和关闭一个文件,并将内容发送到指定的输出;Inputs 顾名思义就是输入,对于 Filebeat 而言,其实就是指各种不同类型的日志文件,譬如 Filebeat 可以支持 Kafka、Redis、MQTT、TCP、UDP、Stdin、Syslog 等等的输入。从某种意义上讲,你可以把 Filebeat 理解为一个文件扫描服务。例如,下面的配置表示 Filebeat 将会从一个指定的路径读取日志文件:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/logs/*.log
我们都知道,通常情况下,Docker 会将其日志存储在以下位置:/var/lib/docker/containers/*/*.log,并且其日志格式为 JSON。考虑到 Filebeat 本身就支持 JSON 格式,所以,你还可以通过下面类似的方式来收集 Docker 容器的日志:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/lib/docker/containers/*/*.log
除此以外,我们提到 Filebeat 内置了大量的模块,使其可以支持 Apache、Kakfa、Envoy、MySQL 等等第三方系统的日志采集,通常位于 module.d这个文件夹中。如下图所示,禁用的模块将会以 .disable 结尾:
 Filebeat 中内置的模块一览
Filebeat 中内置的模块一览
接下来,为了使用这些模块。首先,我们要在 filebeat.yml 这个配置文件中增加下列内容,这相当于指定了模块所在的目录:
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
此时,我们进入容器并执行下列命令就可以启用 envoyproxy 这个模块:
./filebeat modules enable envoyproxy
实际上,这个命令的作用就是移除 .disable 这个后缀,同时重新载入配置。同理,如果我们将 enbale换成 disable 则可以禁用一个模块。模块可以理解为官方帮你提前写好了各种 Input 配置,当然,如果光是启用一个模块是没有用的,你还需要对这些模块进行简单的配置,最基础的一点,就是你需要告诉这些模块你的日志文件存储在哪里,以博主这里的 Envoy 为例,我们执行下面的命令:
vi ./modules.d/envoyproxy.yml
此时,我们可以看到下面的内容,我们只需要覆盖 var.paths这个参数即可:
# Module: envoyproxy
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.5/filebeat-module-envoyproxy.html
- module: envoyproxy
# Fileset for native deployment
log:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/logs/request_log.log"]
对于 Filebeat 而言,其最基础的输出是 Logstatsh 和 Elasticsearch,下面是相应的配置,当然,这里给出的都是最最基础的、没有任何套路的配置,如果你还需要密码、证书这些更细节的东西,请以官方文档为准,谢谢。
# 输出日志到 Logstash
output.logstash:
hosts: ["logstash:5044"]
# 输出日志到 Elasticsearch
output.elasticsearch:
hosts: ["192.168.50.162:9200"]
这里,我们以输出到 Elasticsearch 为例,默认情况下,Filebeat 会生成类似于 filebeat-6.3.2-2017.04.26 这样的索引文件,如果你不满足于这个索引名称,你可以在 output.elasticsearch 配置项下设置 index 字段,博主这里依然采用默认配置,如图所示,我们在 Kibana 中可以找到下面的索引:
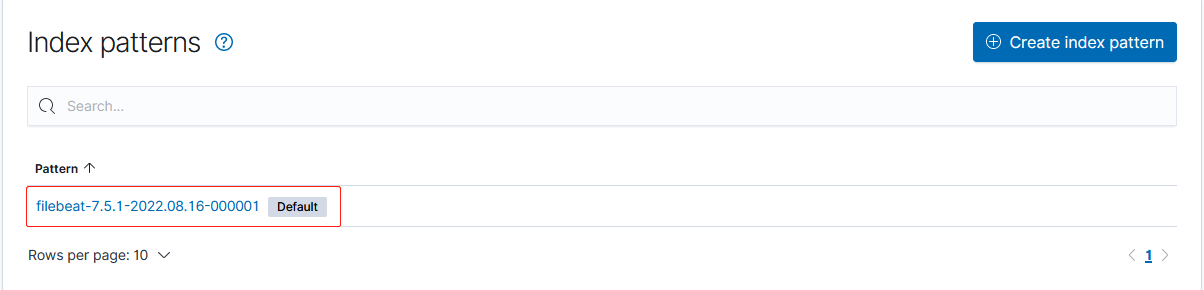
通过 Filebeat 采集到的日志数据-A
更进一步地,我们可以看到每个经过 Envoy 代理的请求日志。这样,我们就达到了通过 Filebeat 收集日志的目的。和你们一样,在看到这个结果前,我已经在心里演练了无数遍的当当当当:
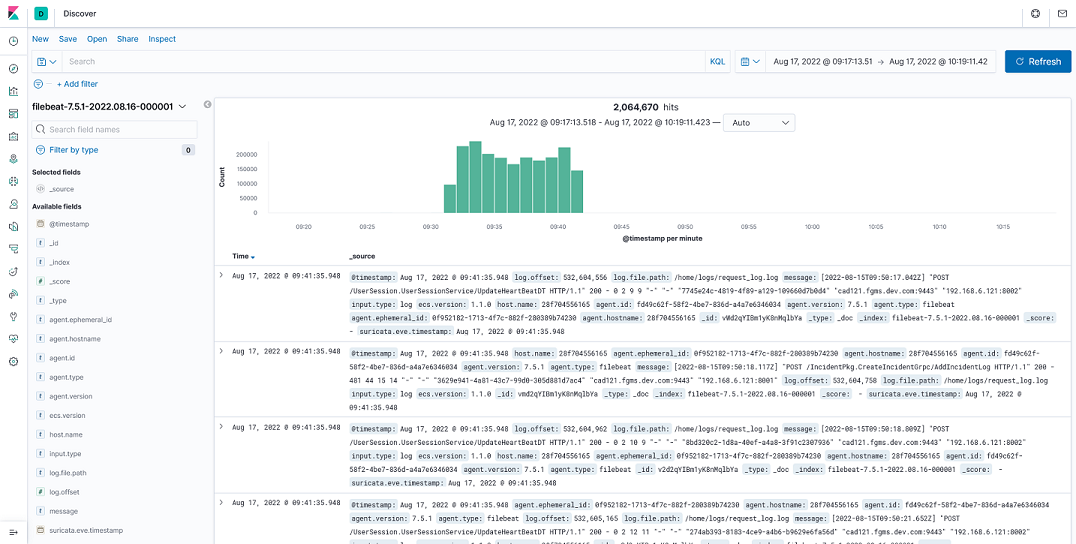
通过 Filebeat 采集到的日志数据-B
坦白地讲,如果所有的日志格式都能做到统一规范,譬如,全部采用 JSON 格式来存储,此时,通过 Filebeat 来收集日志还是挺惬意的一件事情,因为不需要操心日志解析或者说 Grok 这种东西。其实 Logstash 在性能上的瓶颈我还没有触及,真正劝退我的正是这套基于 Ruby 的 DSL,曾经我选择 Hexo 而不是 Jekyll,某种程度上是因为我抵触 Ruby 这门语言。总而言之,你可以自行决定是否跳过 Logstash 这个环节,因为据官方说后来的 Eleasticsearch 已经具备数据加工和过滤的能力,从这个角度看起来, Logstash 并不是唯一的选择,你觉得呢?更详细的代码和配置请参考我的 Github。
从 Filebeat 到 Fluentd
当然,Filebeat 的轻量级是以牺牲了一部分功能为代价的,譬如最典型的缺陷是,它不具备像 Logstash 那样强大的日志解析能力,在 codec 和 filter 这两个方面存在短板,虽然官方内置了大量的模块使其可以支持 Nginx、Envoy、Kafka、Redis 等等日志收集,可实际上,Filebeat 更为普遍的使用场景还是从一个文件里读出日志,然后将其丢给 Logstash 或者 Elasticsearch,这意味着缓冲的压力只会出现在输出这个阶段。所以,你会注意到,现在人们开始考虑把日志转发到 Kafka 或者 Redis,以期达到“削峰”的目的。此时,Filebeat 的轻量级仿佛就成为了一种罪过,人们基于 Filebeat 开发了 Fluntd,一种支持多个输入/输出,插件和功能更为丰富的日志收集工具。
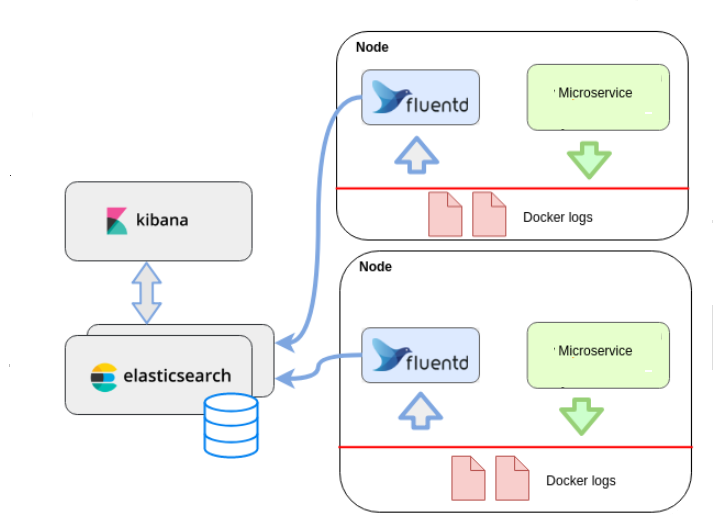
Fluentd 日志收集示意图
不过,身处在一个技术更新换代非常快的时代,“过期”才是这个时代永恒的话题,一如王家卫电影里的那句经典台词:不知道从什么时候开始,在什么东西上都有个日期,秋刀鱼会过期,肉罐头也会过期,连保鲜纸都会过期 ,我开始怀疑,在这个世界上,还有什么东西是不会过期的?我不知道这是不是一种悲哀,因为等到博主打算写这篇文章的时候,Fluentd 已然有了新的挑战者 Fluent-Bit,更神奇的是这两个产品都是来自同一家公司的,难道国外一样喜欢赛马的吗?总而言之,虽然这里的标题是 Fluentd,但我实际上用的是 Fluent-Bit,关于这两者间的关系,官方曾给出过一个对比:

Fluentd 与 Fluent-Bit 的对比
从这张图中,我们可以看出,两者在性能上的差异并不显著,区别只是在实现的语言、插件数量上面,因为 Fluentd 需要依赖 Ruby 环境,我果断选择了放弃,好吧,我承认是因为现在的公司在用 Fluent-Bit,我客观上受到了这一影响。因此,我接下来分享的内容,始终都是以 Fluent-Bit 为准,我将会分享两种容器下的日志收集策略,即 Tail 模式 和 Forward 模式。
Tail 模式
Tail 模式, 这里指 Fluent-Bit 中的一种输入模式,你可以认为它就是 Filebeat 里最经典的基于日志文件的收集模式,如图所示,假设我们我们有多个应用,它们内部已经通过 NLog 或者 Serilog 输出了 JSON 格式的日志文件,此时,我们只需要通过配置 Fluent-Bit 中的输入/输出就可以实现日志的收集:
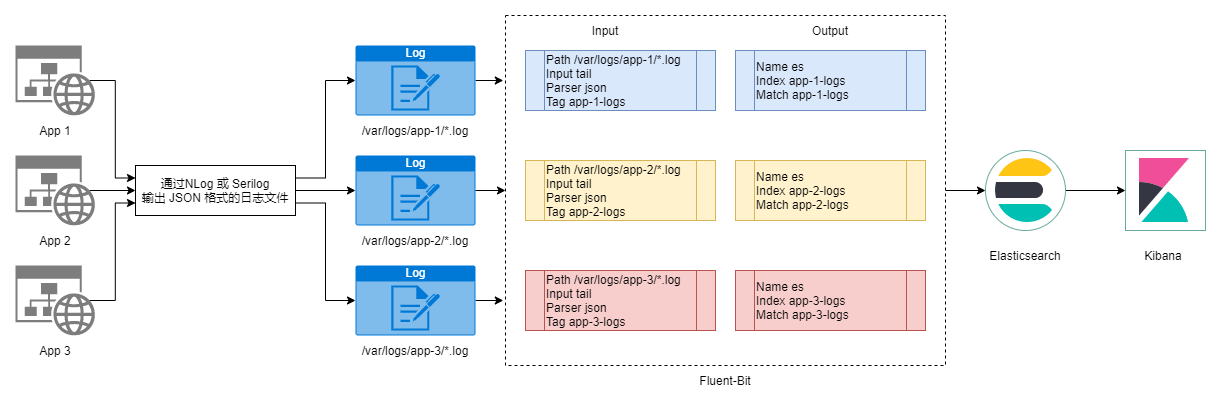
Fluent-Bit 日志收集 - Tail 模式
我们前面提到过, Fluent-Bit 支持多个输入和输出,下面是一个简单的示例,它可以将当前 CPU 的使用情况输出到控制台中,可以注意到,输入和输出是通过标签来进行匹配的:
[INPUT]
Name cpu
Tag cpu_logs
[OUTPUT]
Name stdout
Match cpu_logs
更进一步地,你可以考虑将其输出到 Elasticsearch,为此,我们需要新增加一个 OUTPUT 节点:
[INPUT]
Name cpu
Tag cpu_logs
[OUTPUT]
Name stdout
Match cpu_logs
[OUTPUT]
Name es
Match cpu_logs
Host efk_es
Port 9200
Index cpu_logs
Logstash_Format On
Logstash_Prefix cpu_logs
Logstash_DateFormat %Y-%m
Include_Tag_Key On
此时,如果不出意外的话,你可以在 Kinana 中看到下面的信息,这就是我们通过 Fluent-Bit 采集到的日志信息,这相当于一个简单的热身,目的是帮助大家快速地掌握 Fluent-Bit 配置文件的结构 :
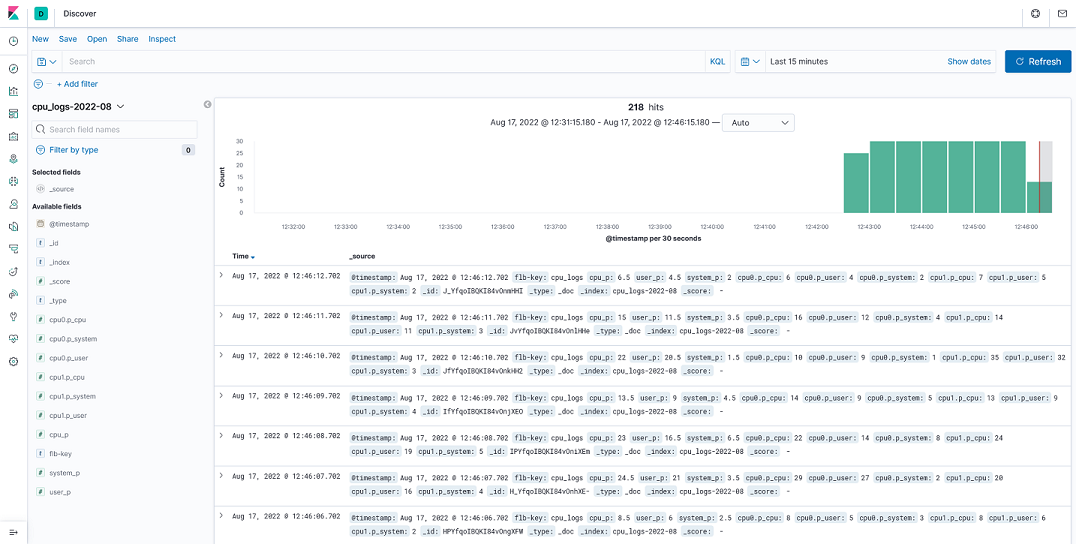
Fluent-Bit 日志收集 - Tail 模式 - 采集 CPU 日志
类似地,对于一般的日志文件,我们可以按下面这种方式来进行配置,它表示从 /var/log/*.log 这个路径采集日志,按 JSON 格式解析并将其输出到 Elasticsearch 中:
[INPUT]
Name tail
Path /var/log/*.log
Path_Key On
Parser json
Tag app_logs
Mem_Buf_Limit 5MB
[OUTPUT]
Name es
Match app_logs
Host efk_es
Port 9200
Index app_logs
Logstash_Format On
Logstash_Prefix app_logs
Logstash_DateFormat %Y.%m
Include_Tag_Key On
需要说明的是,在 Fluent-Bit 中,每个输入或者过滤器的 Parser 是通过全局的 Parser_File 来指定的,该配置项位于 [SERVICE] 节点下:
[SERVICE]
Flush 1
Daemon Off
Log_Level info
Parsers_File parser.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
相对应地,我们需要准备一个 parser.conf 文件,这里我们定义了 json 和 docker 两种解析器,你还可以基于正则表达式定义更多的解析器:
[PARSER]
Name json
Format json
Time_Key time
Time_Format %Y-%m-%d %H:%M:%S %z
[PARSER]
Name docker
Format json
Time_Key time
Time_Format %Y-%m-%d %H:%M:%S.%L
Time_Keep On
一切准备就绪后,你就可以在 Kibana 中看到对应的日志啦,眼尖的朋友会发现这是一个典型的 ASP.NET Core 应用。还是那句话,如果能从日志源头上进行规范化,那么采集日志的时候就会相对轻松一点:
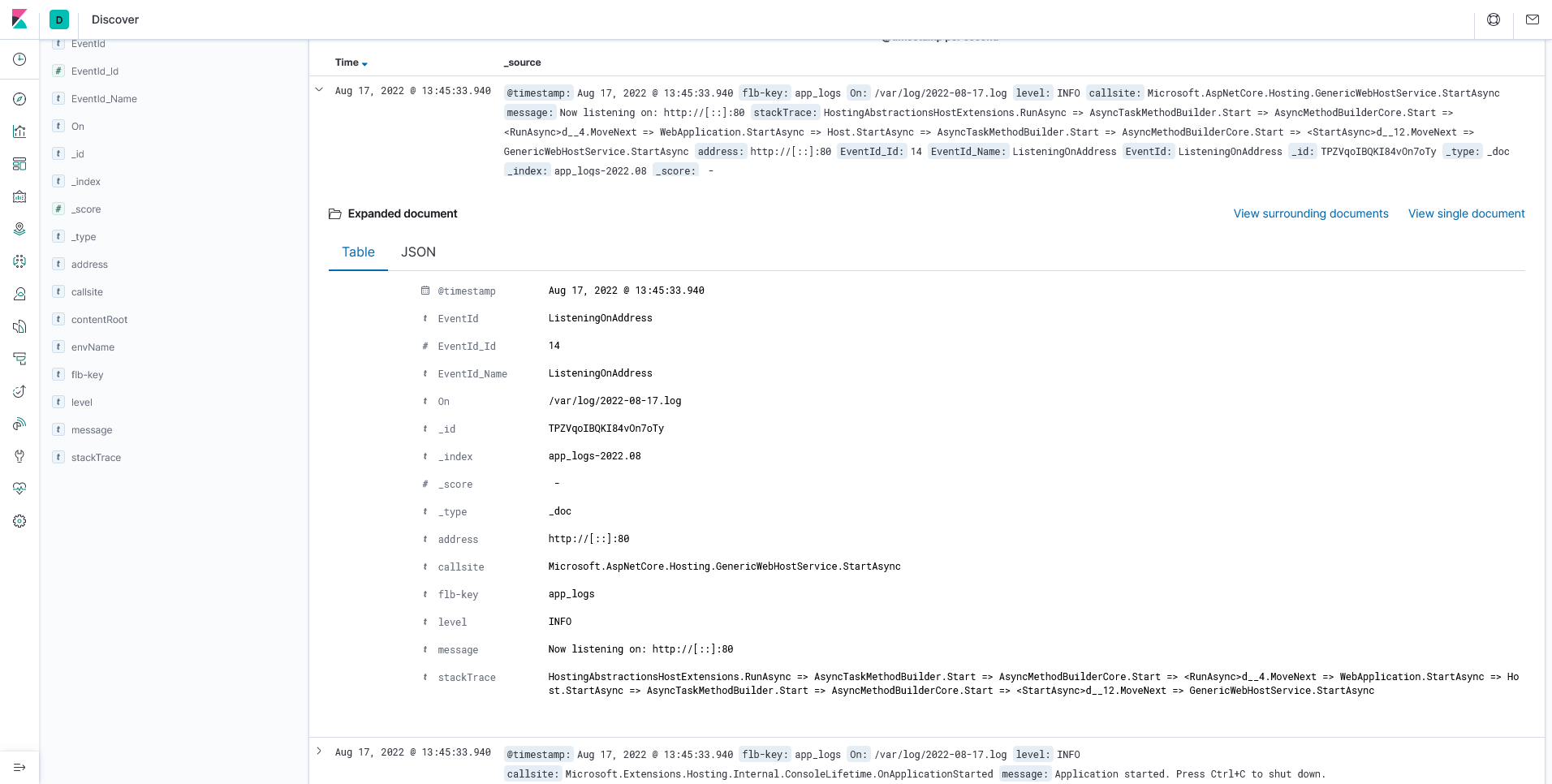
Fluent-Bit 日志收集 - Tail 模式 - 采集应用日志
如果希望了解更多细节,请参考: https://github.com/Regularly-Archive/2022/tree/main/src/ELK/EFK。
Forward 模式
Forward 模式需要借助 Docker 的 logging-driver ,我们前面提到过,Docker 产生的日志文件,默认是存储在 /var/lib/docker/containers/*/*.log 这个路径下,并且这些日志文件是 JSON 格式的,这里面隐含的信息,其实就是 Docker 的 logging-driver,简单来说,正因为 Docker 的 logging-driver 默认值是 json-file,所以,它才会有产生 JSON 格式的日志文件这样一种行为。事实上,除了 json-file 以外,Docker 还支持下面的这些“驱动”:
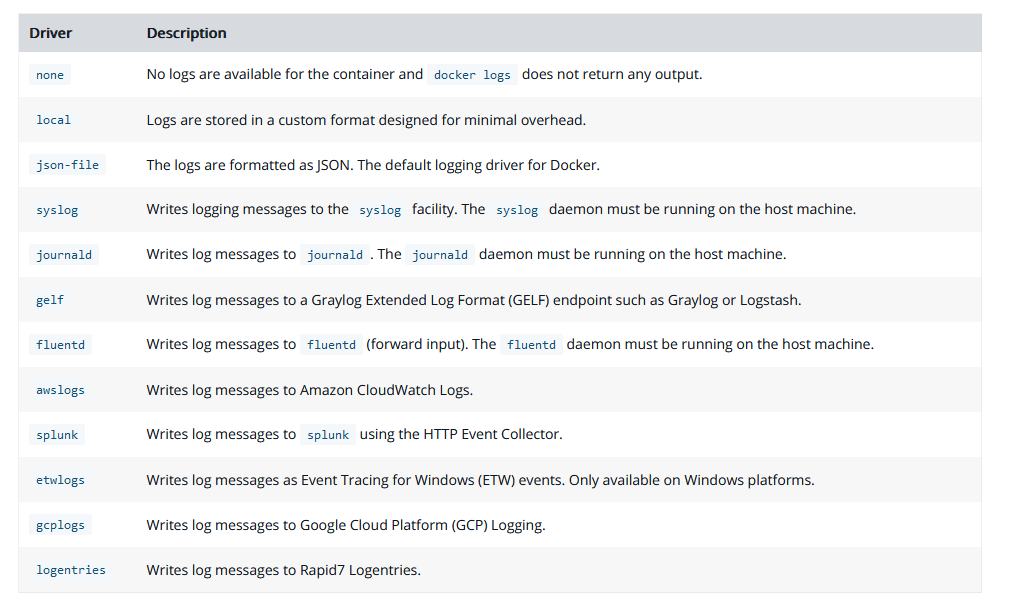
Docker 的 Logging Driver 有哪些?
在这里,我们会发现一个熟悉的身影 Fluentd,所以,如果你问我 Fluentd 相比 Filebeat 还有什么优点,现在我或许会说,它天然地被 Docker 的日志驱动支持着。因为 Fluentd 和 Fluent-Bit 师出同门,所以,后者完全支持前者的协议。此时,我们的日志收集策略就不再是读取日志文件,而是直接通过 Docker 转发到 Fluent-Bit,这种模式就被成为 Forward 模式,它是 Fluent-Bit 中的一种新的输入。
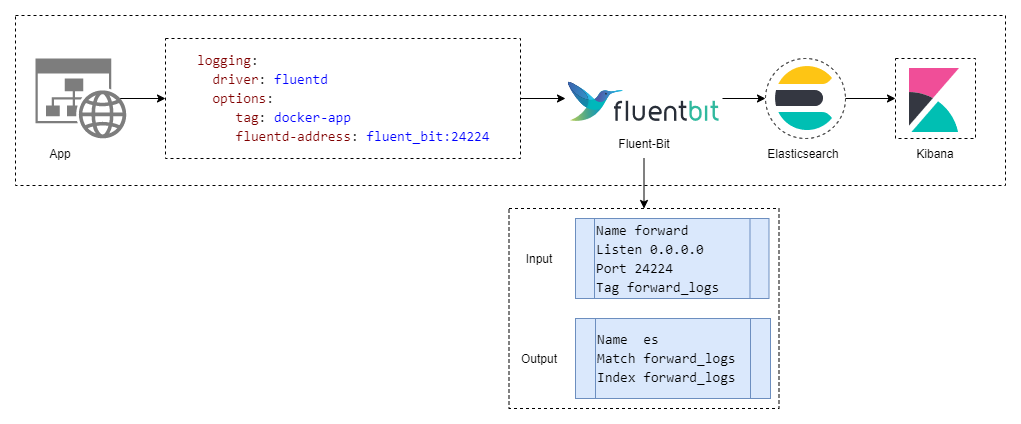
Fluent-Bit 日志收集 - Forward 模式
如图所示,在编排服务的环节,我们将应用的 logging-driver 设置为 fluentd,同时指定 fluentd 或者 fluent-bit 的地址。此时,我们只需要在 Fluent-Bit 的配置文件中处理输入/输出即可完成日志的收集:
version: '3'
service:
fluent_bit:
image: cr.fluentbit.io/fluent/fluent-bit
container_name: efk_flb
volumes:
- ./config/fluent-bit/fluent-bit.conf:/fluent-bit/etc/fluent-bit.conf:rw
- ./config/fluent-bit/parser.conf:/fluent-bit/etc/parser.conf:rw
ports:
- "2020:2020"
- 24224:24224
- 24224:24224/udp
- 5140:5140/udp
app:
build: app/
container_name: efk_app
ports:
- 2333:80
logging:
driver: fluentd
options:
tag: docker-app
fluentd-address: fluent-bit:24224
depends_on:
- fluent_bit
其中 24224 这个端口是 Forward 模式需要用到的一个端口,它是在哪里用到了呢?其实是在 Fluent-Bit 的配置文件 fluent-bit.conf 里面:
[INPUT]
Name forward
Listen 0.0.0.0
Port 24224
buffer_chunk_size 1M
buffer_max_size 5M
tag forward_logs
[OUTPUT]
Name es
Match forward_logs
Host efk_es
Port 9200
Index forward_logs
Logstash_Format On
Logstash_Prefix forward_logs
Logstash_DateFormat %Y.%m
Include_Tag_Key On
简单来说,Fluent-Bit 会接收经由 Docker 转发的日志,我们再将其输出到 Elasticsearch 中,这种情况下我们不用关心应用的日志存储在什么地方,只要是输出到控制台的日志,我们转发到 Fluent-Bit 即可,显而易见,这是一种容器级别的日志收集方案。以前用 Logstash 和 Filebeat 的时候,我曾纠结过这个这个问题,而直到此时此刻,我才真正找到答案。所以,这是否说明,时间和地点更重要,如果晚一点遇见某个人,你是不是会做得稍微好一点?
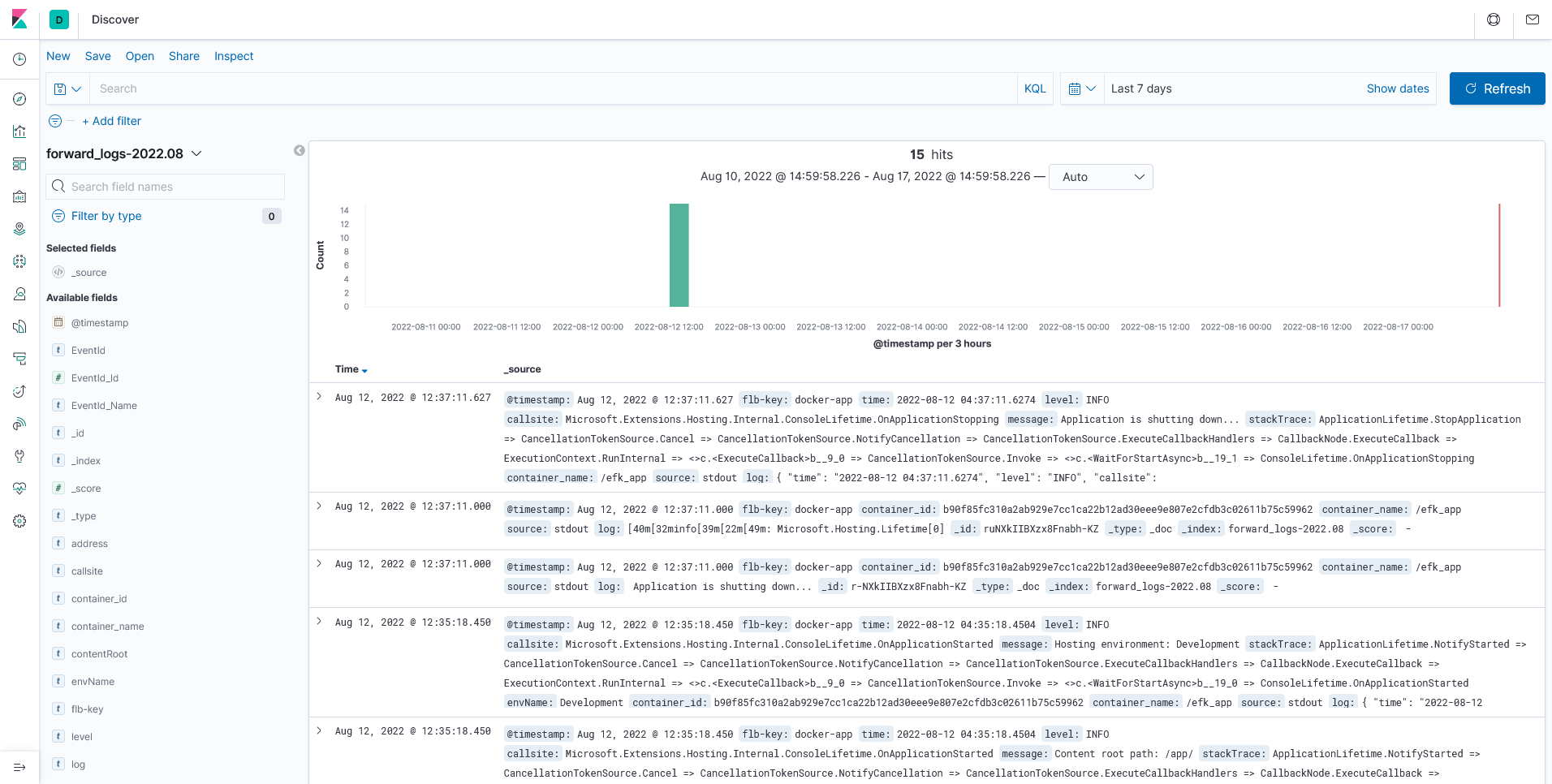
Fluent-Bit 日志收集 - Forward 模式 - 采集应用日志
如果希望了解更多细节,请参考: https://github.com/Regularly-Archive/2022/tree/main/src/ELK/EFK。
准备这篇文章的这几天,有时会在脑海中重复说着一句话,大意是说,你可以怀念过去,可你不能一直都期待别人永远保持最初的样子。对我而言,这篇兴起于新冠元年的系列文章,一切都早已与当时相去甚远,因此,怀着一种物是人非、沧海桑田的心态来写这篇文章,我大抵是有一点从头再来的觉悟在里面。顺着 Logstash -> Filebeat -> Fluent-Bit 这样的脉络一点点探索,这三年间陆陆续续地经历了从 Wndows 到 Linux 再到 Docker 这种平台上的变化,日志收集的关注点更是从单个日志文件扩展到微服务、集群。整体而言,非侵入式的日志收集始终要比侵入式的日志收集要好,在源头上控制日志格式要比通 Grok 或者正则来加工要好。也许。日志收集的工具不止 ELK,可一番探索下来你会发现它们是殊途同归,最难的工作其实是如何组合或者协调这些工具,这篇文章的内容相对琐碎,对于那些我没有写出来的内容,欢迎大家在评论区积极留言、参与讨论,好了,以上就是这篇文章的全部内容啦!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK